目录
一、关于智能指针
1、引入智能指针
2、RAII
二、详述智能指针
auto_ptr
unique_ptr
循环引用
weak_ptr
定制删除器
三、关于内存泄漏
一、关于智能指针
1、引入智能指针
首先引入一个例子:
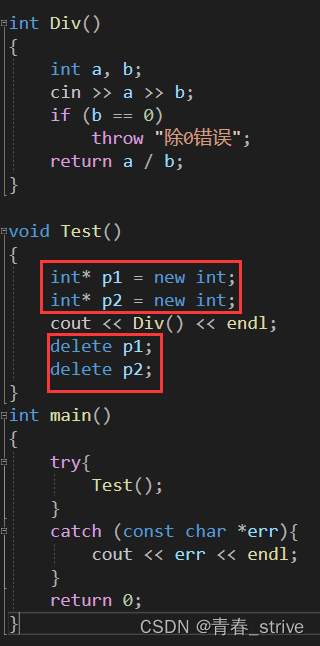
在Test函数中,new了两个对象p1p2,正常来说,new的对象对应delete就可以,但是有了异常处理的情况,如果出现除0错误,则会从直接被main函数中的catch所捕获,跳过了Test函数中的delete,从而造成了内存泄漏的问题
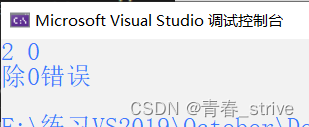
那么为了解决上面的问题,C++就引入了智能指针
2、RAII
RAII是一种利用对象声明周期来控制程序资源的技术
在对象构造时获取资源,接着控制对资源的访问使之在对象的生命周期内始终保持有效,最后在 对象析构的时候释放资源
有两个好处:
①不需要显式地释放资源
②对象所需的资源在其生命期内始终保持有效
下面是用RAII思想delete资源,设计出来的Ptr类
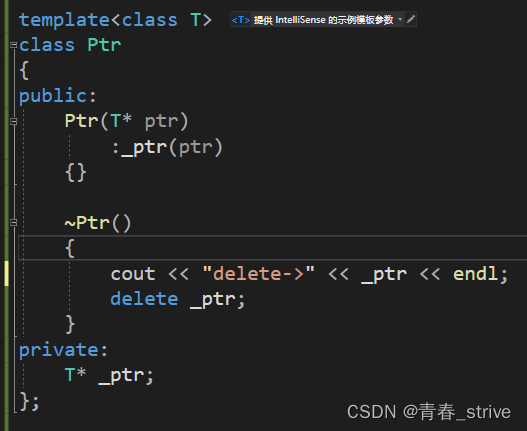
只需在原有例子中改为:
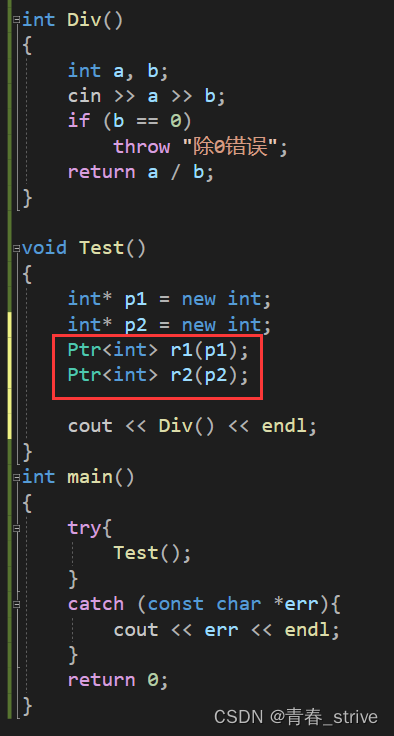
就可以完美解决上述的问题
p1p2构造了r1r2,如果出现除0错误,直接被main函数的catch语句捕获,r1r2声明周期结束,会自动调用析构函数delete:

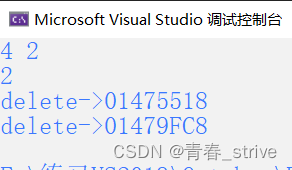
所以无论正常结束还是抛异常结束,r1r2都会调用析构函数释放资源
又因为正常new的对象,可以解引用或使用->,所以我们所写的Ptr类还需要运算符重载*和->:
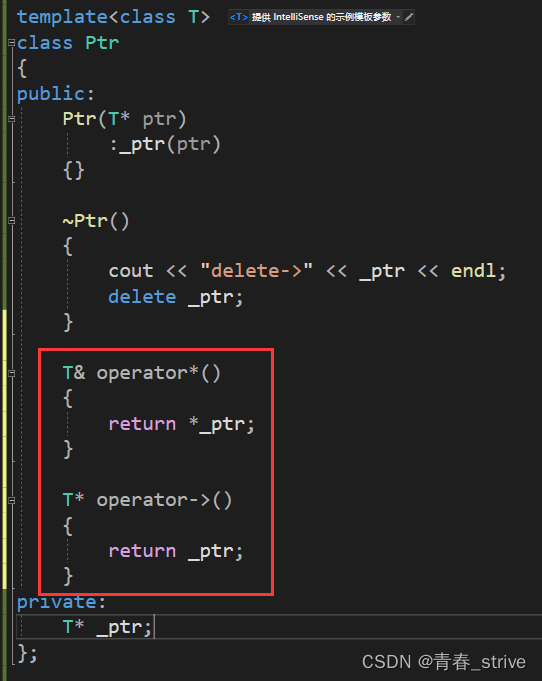
这样就可以像指针一样去使用
二、详述智能指针
智能指针特点:
具有RAII特性
重载operator*和opertaor->,具有像指针一样的行为
由于C++更新迭代速度太慢了,C++11的上一版本就是C++98,中间相隔了13年之久,所以就有C++委员会的大佬组建了boost社区,充当探路者的角色,一些新语法会先在boost社区中应用,如果效果好就会被C++吸收引用
boost首先给出了scoped_ptr、shared_ptr和weak_ptr,C++11将这三种智能指针都引入了,只不过将scoped_ptr改名为了unique_ptr
auto_ptr
C++98定义了auto_ptr
auto_ptr在头文件memory中
下面验证一下auto_ptr会自动调用析构函数从而delete资源

可以看出,new了一个Test对象,会自动调用析构函数
而智能指针比较难处理的地方在于:会有浅拷贝的问题:
比如p1指向一段空间,而p2拷贝p1,没有写拷贝构造编译器默认生成的是浅拷贝,会导致p2也指向这段空间,最后析构时会释放两次资源,导致出错
而怎么解决这个问题呢,首先排除深拷贝的方法,因为我们本身就是要使用浅拷贝,深拷贝违背了功能需求
而auto_ptr的解决方案是:将p2与p1的资源做交换,下面调试观察:
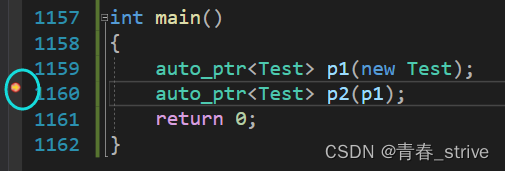
先看没有拷贝前,p1的地址:
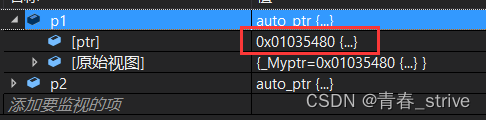
拷贝后p2的地址:

很明显p2的地址变成了刚刚p1的地址,而p1被置空,如果使用者不清楚其中的规则,这样做可能会导致使用者再次使用p1中的指针时发生空指针问题,被拷贝对象出现了悬空问题
所以这里的auto_ptr也是不被大众所接受的一种智能指针
下面是简易的实现一个auto_ptr:
template<class T>
class auto_ptr
{
public:
auto_ptr(T* ptr = nullptr)
:_ptr(ptr)
{}
//拷贝构造后被拷贝的对象置空
auto_ptr(auto_ptr<T>& ap)
:_ptr(ap._ptr)
{
ap._ptr = nullptr;
}
//赋值 ap1 = ap2
auto_ptr<T>& operator=(auto_ptr<T>& ap)
{
//不是自己赋值自己
if (this != &ap)
{
//自己_ptr不为空
if (_ptr)
{
delete _ptr;
}
//ap2的_ptr给ap1,ap2置空
_ptr = ap._ptr;
ap._ptr = nullptr;
}
return *this;
}
~auto_ptr()
{
if (_ptr)
{
delete _ptr;
}
}
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
private:
T* _ptr;
};unique_ptr
unique_ptr是C++11提出的
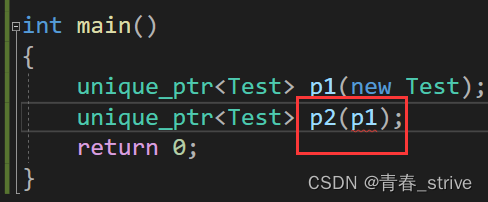
由于auto_ptr的拷贝有问题,所以unique_ptr不允许拷贝,也不允许赋值,如上图所示
为了不允许拷贝,也不允许赋值,C++98和C++11在底层都有各自的解决方案
C++98:底层只声明不实现,并且设为私有(为了防止类外实现)
C++11:直接在拷贝和赋值函数后面加上 = delete,使用了C++11delete新增的用法,指示编译器不生成对应函数的默认版本,称=delete修饰的函数为删除函数。
所以unique_ptr也只适用于不进行拷贝的场景,也不常用
下面是简易的实现一个unique_ptr,其他与auto_ptr类似,就是在赋值和拷贝构造那里加了delete:
template<class T>
class unique_ptr
{
public:
unique_ptr(T* ptr = nullptr)
:_ptr(ptr)
{}
//c++98实现方式
//拷贝、赋值只声明不实现,且设为私有
//private:
//unique_ptr(unique_ptr<T>& ap);
//unique_ptr<T>& operator=(unique_ptr<T>& ap);
//c++11实现方式
//拷贝、赋值都加delete,防止拷贝
unique_ptr(unique_ptr<T>& ap) = delete;
unique_ptr<T>& operator=(unique_ptr<T>& ap) = delete;
~unique_ptr()
{
if (_ptr)
{
delete _ptr;
}
}
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
private:
T* _ptr;
};shared_tr
shared_ptr可以进行拷贝,也是C++11提出的
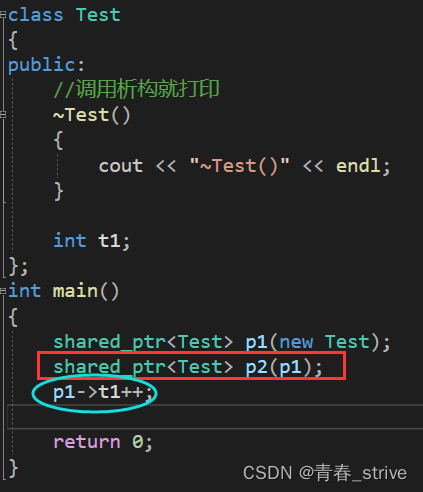
如上图所示,支持拷贝,也支持像指针一样使用
要想实现这种方式,底层使用了引用计数,记录当前几个对象指向这个空间,对象释放时--计数,只有最后一个析构的对象再释放资源
这种引用计数首先排除的实现方式就是增加一个私有成员int _count,这样做无法满足要求,原因是每一个对象都有一个_count,无法实现共享
还有一个方式是创建一个静态成员static int _count(静态成员需要类内声明类外初始化),这样的实现方式,如果是同一种类型的对象可以满足要求,但如果不同类型,却依然是共享一个_count,就会有问题,例如:
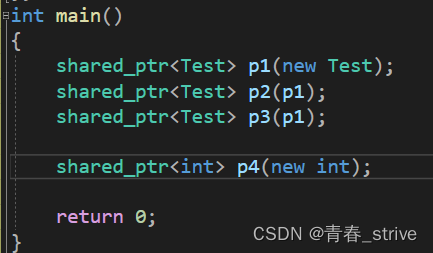
上述情况,我们的p1p2p3是一种类型,p4是另一种类型,满足要求的情况是p1p2p3共享一个_count计数,p4有另一个_count计数 ,因为p1p2p3与p4类型不同,但是上述实现方式却会导致p1p2p3p4只有一个_count计数,所以会出现问题
所以正确的实现方式是:在成员中增加一个int* _pcount,每次有新类型对象会调用构造函数,在构造函数中new一个新的引用计数,完美解决问题
下面是简易实现的shared_ptr的代码:
template<class T>
class shared_ptr
{
public:
//如果有新资源,构造时会创建一个新的_pcount,赋值为1
shared_ptr(T* ptr = nullptr)
:_ptr(ptr)
,_pcount(new int(1))
{}
//拷贝
shared_ptr(const shared_ptr<T>& sp)
:_ptr(sp._ptr)
,_pcount(sp._pcount)
{
(*_pcount)++;
}
//赋值 sp2 = sp1
shared_ptr<T>& operator=(const shared_ptr<T>& sp)
{
//判断不是自己赋值自己,不能用this != &sp
//因为如果前面sp2 = sp1,这时sp1和sp2是一样的
//再赋值sp2 = sp1,就不能用this != &sp判断出来了
if (_ptr != sp._ptr)
{
//被赋值的对象的计数--,为0就提前释放
//表示是最后一个对象,需要释放资源
if (--(*_pcount) == 0)
{
delete _ptr;
delete _pcount;
}
//共同管理新资源
_ptr = sp._ptr;
_pcount = sp._pcount;
(*_pcount)++;
}
return *this;
}
//返回计数个数
int use_count()
{
return *_pcount;
}
//返回指针_ptr,防止weak_ptr构造时私有无法获取
T* get() const
{
return _ptr;
}
~shared_ptr()
{
//计数为0,则delete _ptr、_pcount
if (--(*_pcount) == 0)
{
delete _ptr;
delete _pcount;
}
}
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
private:
T* _ptr;
//引用计数
int* _pcount;
};循环引用
shared_ptr已经可以解决大部分问题了,但是还是会有情况无法解决,即下面所说的循环引用:
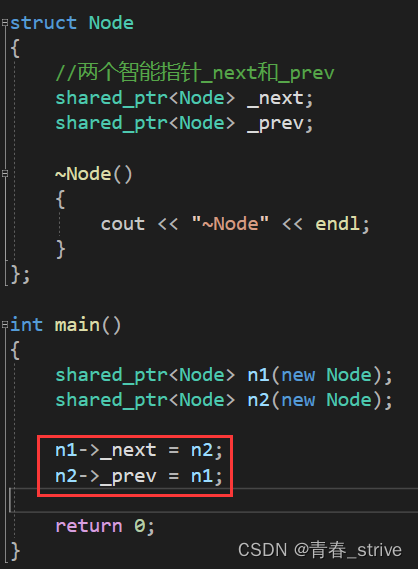
上述情况中,有两个结点Node,分别是n1、n2
n1、n2中都有_next和_prev,而n1、n2在构造时也都会一个计数初始值都为1
而下面的n1->_next = n2,其实是智能指针的赋值,因为n1->_next和n2都是智能指针,所以n1->_next指向n2时n2的计数会+1,变为2
接下来的n2->_prev = n1同理,n1的计数+1也变为2
下面的运行结果可以看到,计数的情况:

可以发现,在main函数结束前,n1n2的计数都为2
main函数结束后,n2先析构,n1后析构,n1n2计数都--,变为1
所以没有执行析构函数(没有打印~Node)
此时变为了下图这样子的情况:
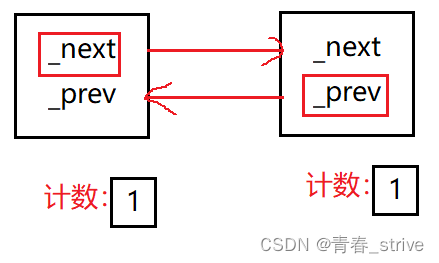
左边结点的_next管着右边的结点内存块,右边结点的_prev管着左边的结点内存快
此时_next释放右边就释放(delete),_prev释放左边就释放()delete
以左边结点的_next为例,_next作为左边结点的成员,只有左边结点被delete时,调用析构函数,_next才会析构,从而把右边结点的计数减为0,释放右边结点
而左边结点什么时候析构,则是由右边结点的_prev决定的,而_next作为右边结点的成员,只有右边结点被delete时,调用析构函数,_prev才会析构
形成了循环引用的问题
总结一下循环引用问题:
即就是右边结点什么时候delete,取决于左边的_next什么时候析构,而_next什么时候析构取决于左边结点什么时候delete
左边结点什么时候delete,又取决于右边的_prev什么时候析构,而右边的_prev什么时候析构取决于右边结点什么时候delete
问题又回来了,右边结点什么时候delete,取决于左边的_next什么时候析构......循环往复
weak_ptr
而为了解决循环引用问题,引入了weak_ptr
但是这里的weak_ptr并不是常规的智能指针,它是辅助性智能指针,它没有RAII,也不支持直接的资源管理
weak_ptr主要用shared_ptr构造,用来解决shared_ptr循环引用的问题
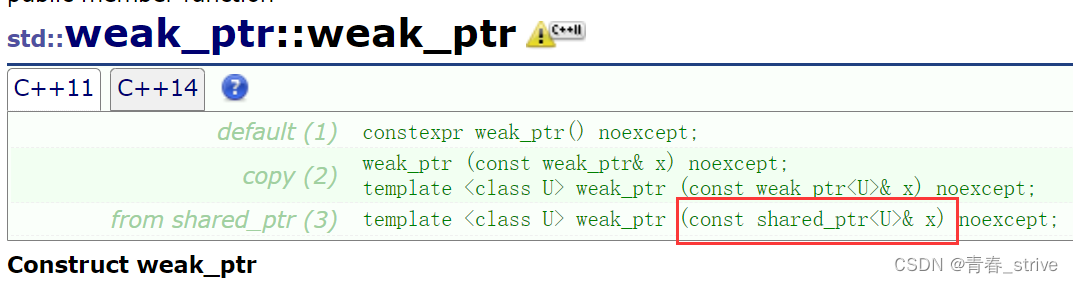
红框的部分即用shared_ptr构造weak_ptr
将上述代码改为: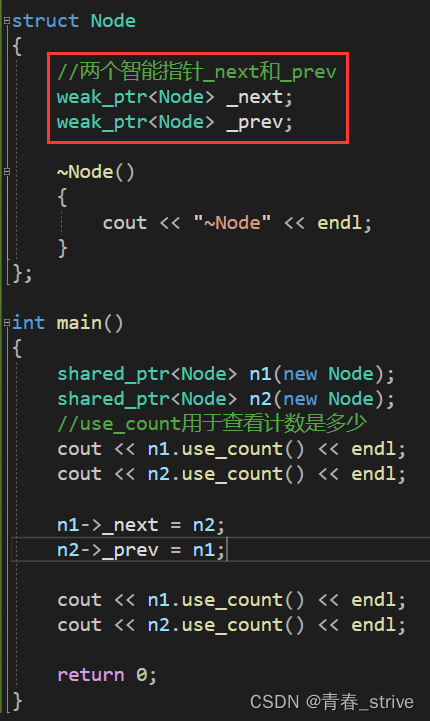
当Node中的_next和_prev是weak_ptr时,不参与资源的释放管理,可以访问和修改资源,但是不增加计数,所以就不会存在循环引用的问题了
此时观察运行结果:
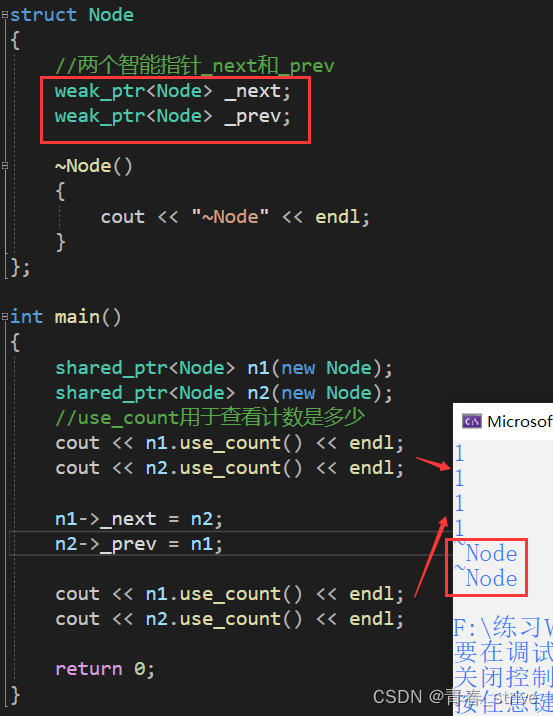
执行完 n1->_next = n2;n2->_prev = n1;后,计数仍为1,所以main函数结束后,n1n2析构,计数--变为0,执行了析构函数,打印了~Node
weak_ptr的简易模拟代码,目的是方便理解:
//辅助型智能指针
template<class T>
class weak_ptr
{
public:
//无参构造
weak_ptr()
:_ptr(nullptr)
{}
//shared_ptr拷贝构造
weak_ptr(const shared_ptr<T>& sp)
:_ptr(sp.get());
{}
//weak_ptr本身拷贝构造
weak_ptr(const weak_ptr<T>& wp)
:_ptr(wp._ptr);
{}
//shared_ptr赋值
weak_ptr<T>& operator=(const shared_ptr<T>& sp)
{
//这里不存在自己给自己赋值的场景,所以不需要判断
_ptr = sp._ptr;
return *this;
}
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
public:
T* _ptr;
};定制删除器
实际中是有可能出现下面这种情况的:
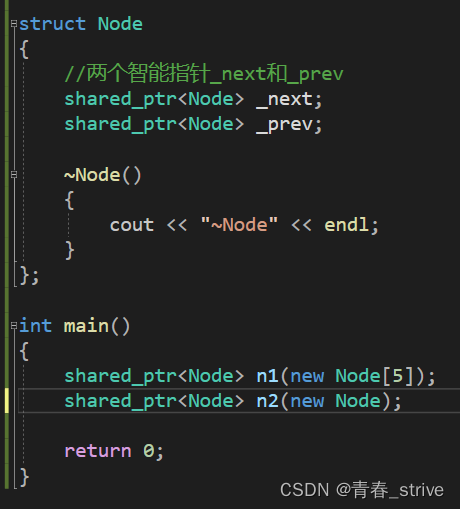
我们普通的shared_ptr的析构函数都是delete,但是如果我们new [],但是却没有配对delete [],少了[],就会出错
我们知道new的底层是malloc,delete的底层是free,我们执行new Node[5],相当于malloc + 5次构造函数,这里的5是从new Node[5]这里的代码中获得的,但是delete []却并没有给次数,不知道需要执行几次析构函数
所以VS的编译器底层在刚刚new的资源的存储位置头部多开了4个字节,用于存储个数,用于告诉编译器需要析构几次
但是我们的指针ptr却仍然指向刚刚的位置,所以实际所开的空间就如下图所示:

所以我们最后执行delete []时,free的并不是ptr的位置,而是ptr减了4个字节的位置,因为我们实际多开辟了四个字节
所以大家就明白了为什么使用delete程序会崩溃,因为delete并不会找头部4个字节所存的次数,即ptr所指向的位置并不是所开空间的起始位置,正确的起始位置应该还要减4个字节,所以释放的位置不对而导致程序崩溃,而delete []则能够往前找4个字节,所以C++语法要求我们new []一定要对应使用delete []
如果是shared_ptr<int> n1(new int[5]);就不会出错,因为只有自定义类型才会调用析构函数,内置类型不需要调用析构函数,因此delete不会出错
所以针对上面的问题,引入了定制删除器的概念
shared_ptr支持定制删除器

unique_ptr也支持定制删除器:

这两个指针支持的方式是有区别的:shared_ptr是在构造函数中支持的,可以在构造时传入对象,而unique_ptr是给的模版参数,传入的是类型
下面先演示shared_ptr的使用方式:
下面的Delete和Free即我们自己实现的定制删除器
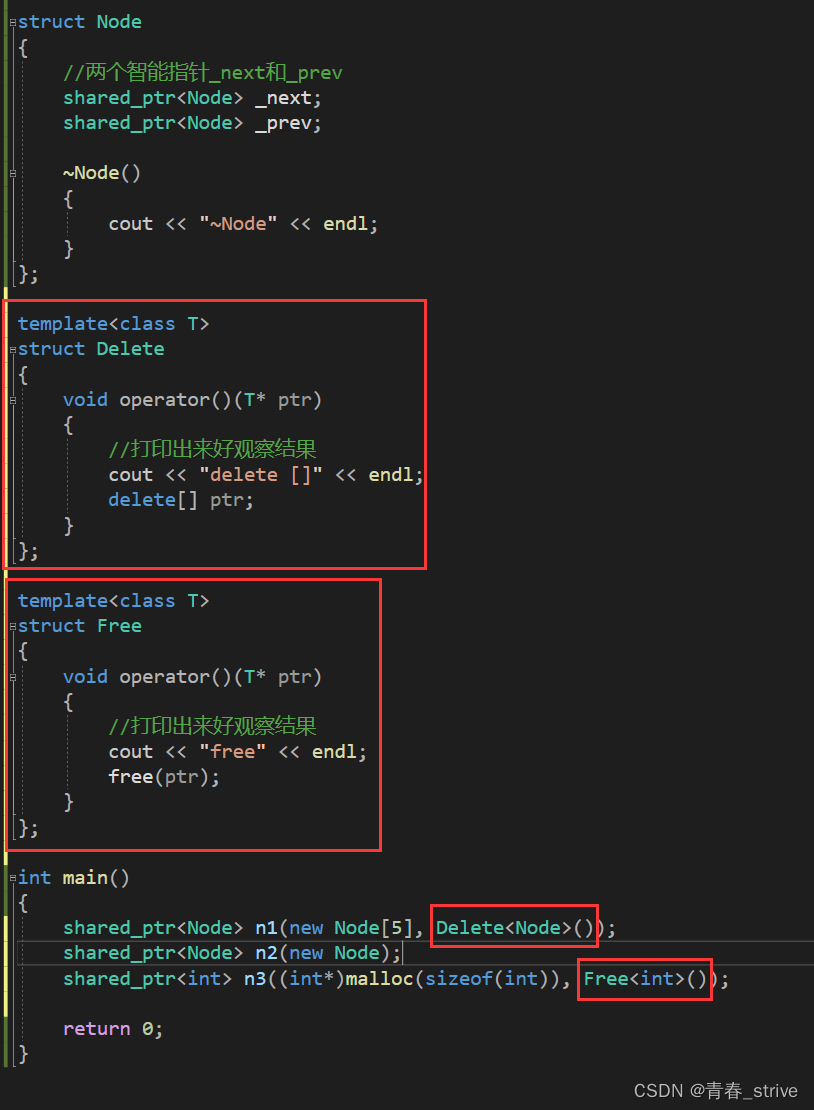
分别给n1n3传入匿名对象
此时运行结果:
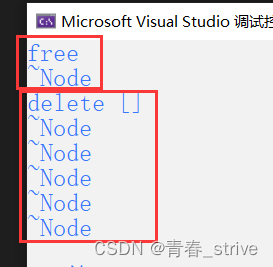
free后调用一次析构;delete []后,调用5次析构
上面这种方式是传入的仿函数的匿名对象
由于shared_ptr传入的是对象,所以也可以用我们前面所学的lambda表达式,lambda也是对象,所以也可以使用
所以main函数中,也可以这样使用:

下面是unique_ptr的使用,即模版的方式使用:
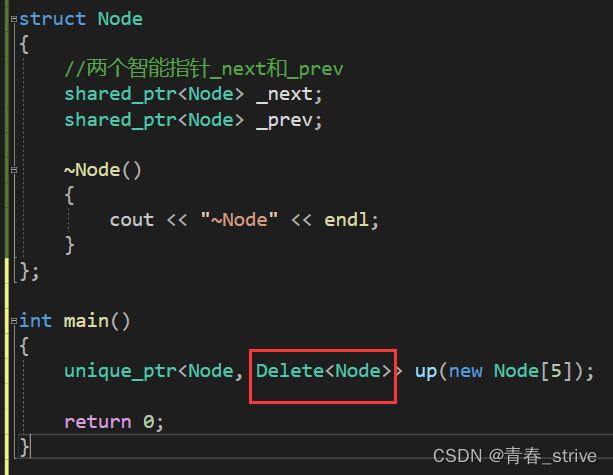
需要注意的是这里的Delete<Node>后面没有括号,因为unique_ptr传入的是类型,不需要加括号,而刚刚的shared_ptr传入的是对象,需要加括号表示匿名对象
而定制删除器我们如果想简易的模拟一下,只能用unique_ptr的方式模拟实现
即多一个模版参数D,我们这里没办法像库里面一样,在构造函数那里实现,因为构造函数那里有一个模版参数D,析构函数无法获得D,并且库里面代码实现的复杂度是远远高于我们自己模拟实现的,所以我们只是模拟实现有助于理解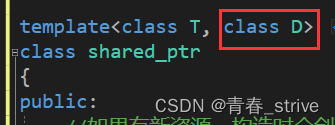
在析构函数中,创建匿名对象,传入_ptr,传入的定制删除器是delete []就delete [],是free就free
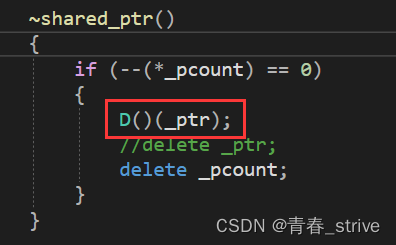
如果是普通的的delete,为了和原来使用方式一样,我们可以写一个默认的删除器,表示不传就默认是delete:

总结几个问题,用于复习智能指针章节的知识:
为什么需要智能指针?
RAII是什么?
智能指针的发展历史?
auto_ptr、unique_ptr、shared_ptr、weak_ptr区别及其使用场景?
模拟实现简易版的智能指针?
什么是循环引用?如何解决?解决的原理?
三、关于内存泄漏
内存泄漏的概念:
内存泄漏指因为疏忽或错误造成程序未能释放已经不再使用的内存的情况。内存泄漏并不是指内存在物理上的消失,而是应用程序分配某段内存后,因为设计错误,失去了对该段内存的控制(即指针丢失了,并不是内存丢失),因而造成了内存的浪费。
例如我们一开始所举的例子,new了一个对象,但是抛异常,直接被main函数的catch语句捕获,导致没有delete,造成内存泄漏,即:
但是进程如果是正常结束的,是会释放内存的,那这么说的话,内存泄漏还有没有危害了呢,当然是有的
内存泄漏的危害:
①僵尸进程有内存泄漏,如果僵尸进程非常多,就会造成资源被占用很多
②长期运行的程序出现内存泄漏,影响很大,如操作系统、后台服务等等,出现内存泄漏会导致响应越来越慢,最终卡死。
如何避免内存泄漏:
1. 工程前期良好的设计规范,养成良好的编码规范,申请的内存空间记着匹配的去释放。
需要注意的是:如果碰上抛异常的情况时,就算注意释放了,还是可能会出问题。
2. 采用RAII思想或者智能指针来管理资源。
3. 公司内部规范使用内部实现的私有内存管理库,自带内存泄漏检测的功能选项。
4. 出问题了使用内存泄漏工具检测。
需要注意的是:一般工具不一定能检测出来,亦或是收费较贵