文章目录
- 互斥量mutex
- 互斥量基本原理
- 死锁
- 代码实现
- 读写锁
- 基本概念
- 为什么需要读写锁?
- 相关函数
- 读写锁实现
- 生产-消费者模型
- PV操作
- 条件变量函数
- 生产者消费者问题
- 生产-消费者模型实现代码
互斥量mutex
互斥量基本原理
Linux系统编程 —互斥量mutex
互斥量mutex
前文提到,系统中如果存在资源共享,线程间存在竞争,并且没有合理的同步机制的话,会出现数据混乱的现象。为了实现同步机制,Linux中提供了多种方式,其中一种方式为互斥锁mutex(也称之为互斥量)。
互斥量的具体实现方式为:每个线程在对共享资源操作前都尝试先加锁,成功加锁后才可以对共享资源进行读写操作,操作结束后解锁。
互斥量不是为了消除竞争,实际上,资源还是共享的,线程间也还是竞争的,只不过通过这种“锁”机制就将共享资源的访问变成互斥操作,也就是说一个线程操作这个资源时,其它线程无法操作它,从而消除与时间有关的错误。
从互斥量的实现机制我们可以看出,同一时刻,只能有一个线程持有该锁。如果有同时有多个线程持有该锁,那就没有实际意义了。
但是,这种锁机制不是强制的,互斥锁实质上是操作系统提供的一把“建议锁”(又称“协同锁”),建议程序中有多线程访问共享资源的时候使用该机制。
因此,即使有了mutex,其它线程如果不按照这种锁机制来访问共享数据的话,依然会造成数据混乱。所以为了避免这种情况,所有访问该共享资源的线程必须采用相同的锁机制。
主要应用函数:
pthread_mutex_init函数
pthread_mutex_destroy函数
pthread_mutex_lock函数
pthread_mutex_trylock函数
pthread_mutex_unlock函数
以上5个函数的返回值都是:成功返回0,失败返回错误号。
在Linux环境下,类型pthread_mutex_t其本质是一个结构体。但是为了简化理解,应用时可忽略其实现细节,简单当成整数看待。mutex一般以下面方式定义:
pthread_mutex_t mutex;
变量mutex只有两种取值1、0。
pthread_mutex_trylock函数
函数原型:
int pthread_mutex_trylock(pthread_mutex_t *mutex);
函数作用:
对共享资源尝试加锁。它与pthread_mutex_lock函数的区别是,使用lock函数对共享资源进行加锁时,如果加锁不成功,则线程就阻塞;而如果使用trylock,则加锁不成功时不会阻塞当前线程,而是立即返回一个值来描述互斥锁的状况。
死锁
线程试图对同一个互斥量A加锁两次。
线程1拥有A锁,请求获得B锁;线程2拥有B锁,请求获得A锁

代码实现
#include <unistd.h>
#include <pthread.h>
#include <stdio.h>
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
void *thread_main(void *arg)
{
while (1)
{
pthread_mutex_lock(&mutex);
printf("HOUHOU\n");
sleep(rand() % 3);
printf("GUGU\n");
pthread_mutex_unlock(&mutex);
sleep(rand() % 3);
}
}
int main()
{
pthread_t tid;
srand(time(NULL));
pthread_create(&tid, NULL, thread_main, NULL);
while(1)
{
pthread_mutex_lock(&mutex);
printf("houhou\n");
sleep(rand() % 3);
printf("gugugu\n");
pthread_mutex_unlock(&mutex);
sleep(rand() % 3);
}
pthread_join(tid,NULL);
return 0;
}

如果不加互斥锁,则会出现混乱的输出。
printf(“HOUHOU\n”);临界区不加锁,会失去cpu。

读写锁
基本概念
读写锁其实还是一种锁,是给一段临界区代码加锁,但是此加锁是在进行写操作的时候才会互斥,而在进行读的时候是可以共享的进行访问临界区的。

为什么需要读写锁?
有时候,在多线程中,有一些公共数据修改的机会比较少,而读的机会却是非常多的,此公共数据的操作基本都是读,如果每次操作都给此段代码加锁,太浪费时间了而且也很浪费资源,降低程序的效率,因为读操作不会修改数据,只是做一些查询,所以在读的时候不用给此段代码加锁,可以共享的访问,只有涉及到写的时候,互斥的访问就好了。
相关函数
(1)pthread_rwlock_init()—->初始化函数
功能:初始化读写锁
头文件:#include<pthread.h>
int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock,const pthred_rwlockattr_t *restrict attr);
参数说明:
rwlock:是要进行初始化的
attr:是rwlock的属性
ps:此参数一般不关注,可设为NULL
(2)pthread_rwlock_destroy—->销毁函数
功能:销毁初始化的锁
头文件:#include<pthread.h>
int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
参数说明:
rwlock:是需要进行销毁的锁
(3)加锁和解锁
在进行读操作的时候加的锁:
pthread_rwlock_rdlock(pthread_rwlock_t* rwlock);
在进行写操作的时候加的锁:
pthread_rwlock_wrlock(pthread_rwlock_t* rwlock);
对读/写统一进行解锁:
pthread_rwlock_unlock(pthread_rwlock_t* rwlock);
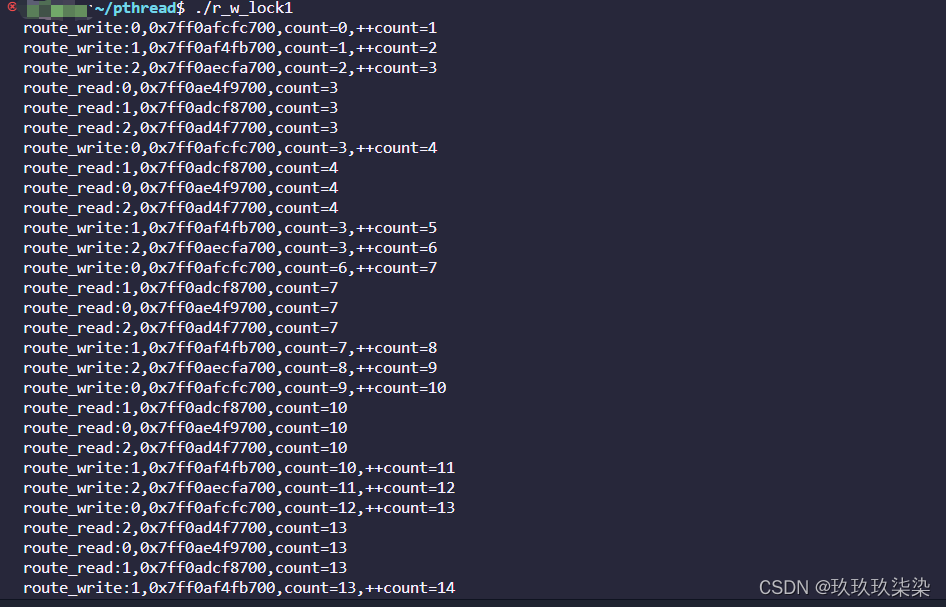
读写锁实现
#include<stdio.h>
#include<unistd.h>
#include<malloc.h>
#include<stdlib.h>
#include<pthread.h>
pthread_rwlock_t rwlock;//声明读写锁
int count;
//写者线程的入口函数
void*route_write(void*arg)
{
int i=*(int*)arg;//i是写者线程的编号
free(arg);
while(1){
int t=count;
//加锁
pthread_rwlock_wrlock(&rwlock);
printf("route_write:%d,%#x,count=%d,++count=%d\n",i,\
pthread_self(),t,++count);
//解锁
pthread_rwlock_unlock(&rwlock);
sleep(1);
}
}
//读者线程的入口函数
void*route_read(void*arg)
{
int i=*(int*)arg;//i是读者线程的编号
free(arg);
while(1){
//加锁
pthread_rwlock_rdlock(&rwlock);
printf("route_read:%d,%#x,count=%d\n",i,pthread_self(),count);
//解锁
pthread_rwlock_unlock(&rwlock);
sleep(1);
}
}
int main()
{
int i=0;
//初始化读写锁
pthread_rwlock_init(&rwlock,NULL);
pthread_t tid[8];
//创建3个写者线程
for(i=0;i<3;i++){
int*p=(int*)malloc(sizeof(int));
*p=i;
pthread_create(&tid[i],NULL,route_write,(void*)p);
}
//创建5个读者线程
for(i=0;i<5;i++){
int*p=(int*)malloc(sizeof(int));
*p=i;
pthread_create(&tid[i+3],NULL,route_read,(void*)p);
}
//主线程等待新创建的线程
for(i=0;i<8;i++)
pthread_join(tid[i],NULL);
//销毁读写锁
pthread_rwlock_destroy(&rwlock);
return 0;
}
生产-消费者模型
PV操作
明确定义
要理解生产消费者问题,首先应弄清PV操作的含义:PV操作是由P操作原语和V操作原语组成(原语是不可中断的过程),对信号量进行操作,具体定义如下:
P(S):①将信号量S的值减1,即S=S-1;
②如果S ,则该进程继续执行;否则该进程置为等待状态,排入等待队列。
V(S):①将信号量S的值加1,即S=S+1;
②如果S>0,则该进程继续执行;否则释放队列中第一个等待信号量的进程。
这只是书本的定义,对于这部分内容,老师先不要急于解释上面的程序流程,而是应该让学生首先知道P操作与V操作到底有什么作用。
P操作相当于申请资源,而V操作相当于释放资源。所以要学生记住以下几个关键字:
P操作—申请资源—pthread_cond_wait()
V操作—释放资源—pthread_cond_signal()
条件变量函数
#include <pthread.h>
//条件变量的销毁
int pthread_cond_destroy(pthread_cond_t *cond);
//条件变量的初识化
int pthread_cond_init(pthread_cond_t *restrict cond,
const pthread_condattr_t *restrict attr);
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;//静态声明
pthread_cond_t cond =PTHREAD_COND_INITIALIZER;,相当于调用函数pthread_cond_init()初始化,并且参数attr为NULL。
条件变量的操作函数
#include <pthread.h>
//唤醒该条件变量的所有线程
int pthread_cond_broadcast(pthread_cond_t *cond);
//唤醒该条件变量中的一个线程
int pthread_cond_signal(pthread_cond_t *cond);
int pthread_cond_timedwait(pthread_cond_t *restrict cond,
pthread_mutex_t *restrict mutex,
const struct timespec *restrict abstime);
//让该线程在某个条件变量进行等待
int pthread_cond_wait(pthread_cond_t *restrict cond,
pthread_mutex_t *restrict mutex);
条件变量总是需要与互斥量结合使用,互斥量能限制一个线程能够访问共享资源,条件变量是在共享变量状态改变时发出通知。一个线程调用pthread_cond_wait函数则让它在一个条件变量下进行等待,pthead_cond_wait函数进行三个步骤:
释放互斥量
阻塞等待
当被唤醒时,重新获得互斥量并返回
生产者消费者问题
生产者消费者问题(英语:Producer-consumer problem),也称有限缓冲问题(英语:Bounded-buffer problem),是一个多线程同步问题的经典案例。该问题描述了共享固定大小缓冲区的两个线程——即所谓的“生产者”和“消费者”——在实际运行时会发生的问题。生产者的主要作用是生成一定量的数据放到缓冲区中,然后重复此过程。与此同时,消费者也在缓冲区消耗这些数据。该问题的关键就是要保证生产者不会在缓冲区满时加入数据,消费者也不会在缓冲区中空时消耗数据。
要解决该问题,就必须让生产者在缓冲区满时休眠(要么干脆就放弃数据),等到下次消费者消耗缓冲区中的数据的时候,生产者才能被唤醒,开始往缓冲区添加数据。同样,也可以让消费者在缓冲区空时进入休眠,等到生产者往缓冲区添加数据之后,再唤醒消费者。通常采用进程间通信的方法解决该问题。如果解决方法不够完善,则容易出现死锁的情况。出现死锁时,两个线程都会陷入休眠,等待对方唤醒自己。该问题也能被推广到多个生产者和消费者的情形。

生产-消费者模型实现代码
#include <unistd.h>
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
struct msg
{
struct msg* next;
int num;
};
struct msg* head;
struct msg* mp;
pthread_cond_t has_product = PTHREAD_COND_INITIALIZER;
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
void *consumer(void *arg)
{
for(;;)
{
pthread_mutex_lock(&lock);
while(head == NULL)
{
pthread_cond_wait(&has_product,&lock);//pthread_cond_wait() 用于阻塞当前线程,等待别的线程使用 pthread_cond_signal()或pthread_cond_broadcast来唤醒它。
}
//链表不为空,则直接"消费"
mp = head;
head = mp->next;
pthread_mutex_unlock(&lock);
printf("Consume ---%d\n",mp->num);
free(mp);
sleep(rand()%5);
}
}
void *producter(void *arg)
{
for(;;)
{
mp = malloc(sizeof(struct msg));
mp->num = rand() % 1000 + 1;
printf("Product ---%d\n",mp->num);
pthread_mutex_lock(&lock);
mp->next = head;
head = mp;
pthread_mutex_unlock(&lock);
pthread_cond_signal(&has_product);
sleep(rand() % 5);
}
}
int main()
{
pthread_t pid,cid;
srand(time(NULL));
pthread_create(&pid,NULL,consumer,NULL);
pthread_create(&cid,NULL,producter,NULL);
pthread_join(pid,NULL);
pthread_join(cid,NULL);
return 0;
}
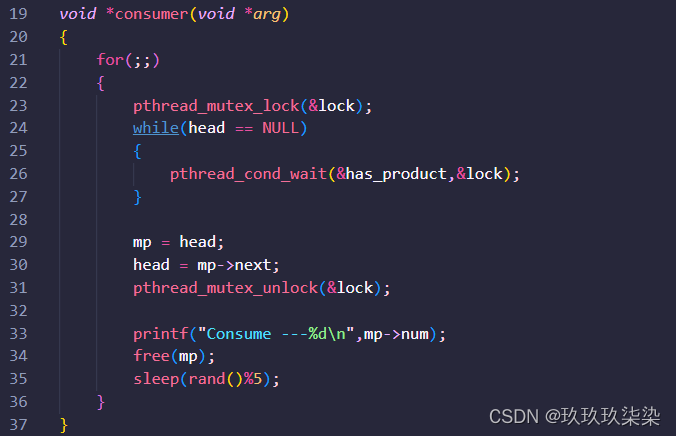
消费者:关于while循环的目的是等待队列中有产品(数据)可供消费。
当线程进入这个循环时,它首先获取互斥锁lock,以确保在检查队列状态时不会被其他线程中断。
然后,它检查队列头指针head是否为空。如果队列为空,说明没有产品可供消费。
在这种情况下,线程调用pthread_cond_wait(&has_product, &lock),它会释放互斥锁lock并等待条件变量has_product的信号。
当其他线程向队列添加产品时,它们会发送信号给has_product,唤醒等待的消费者线程。
一旦有产品可供消费(即队列不再为空),线程会重新获取互斥锁并继续执行后续代码。
为什么使用while:
使用while而不是if的原因是防止虚假唤醒(spurious wakeups)。
虚假唤醒是指在没有明确信号的情况下,线程被唤醒。如果使用if,线程可能在没有产品的情况下被唤醒,然后错误地继续执行后续代码。
while循环会在每次被唤醒后重新检查条件,确保只有在队列非空时才继续执行。
总结:while循环用于等待队列中有产品可供消费,同时避免虚假唤醒的问题。