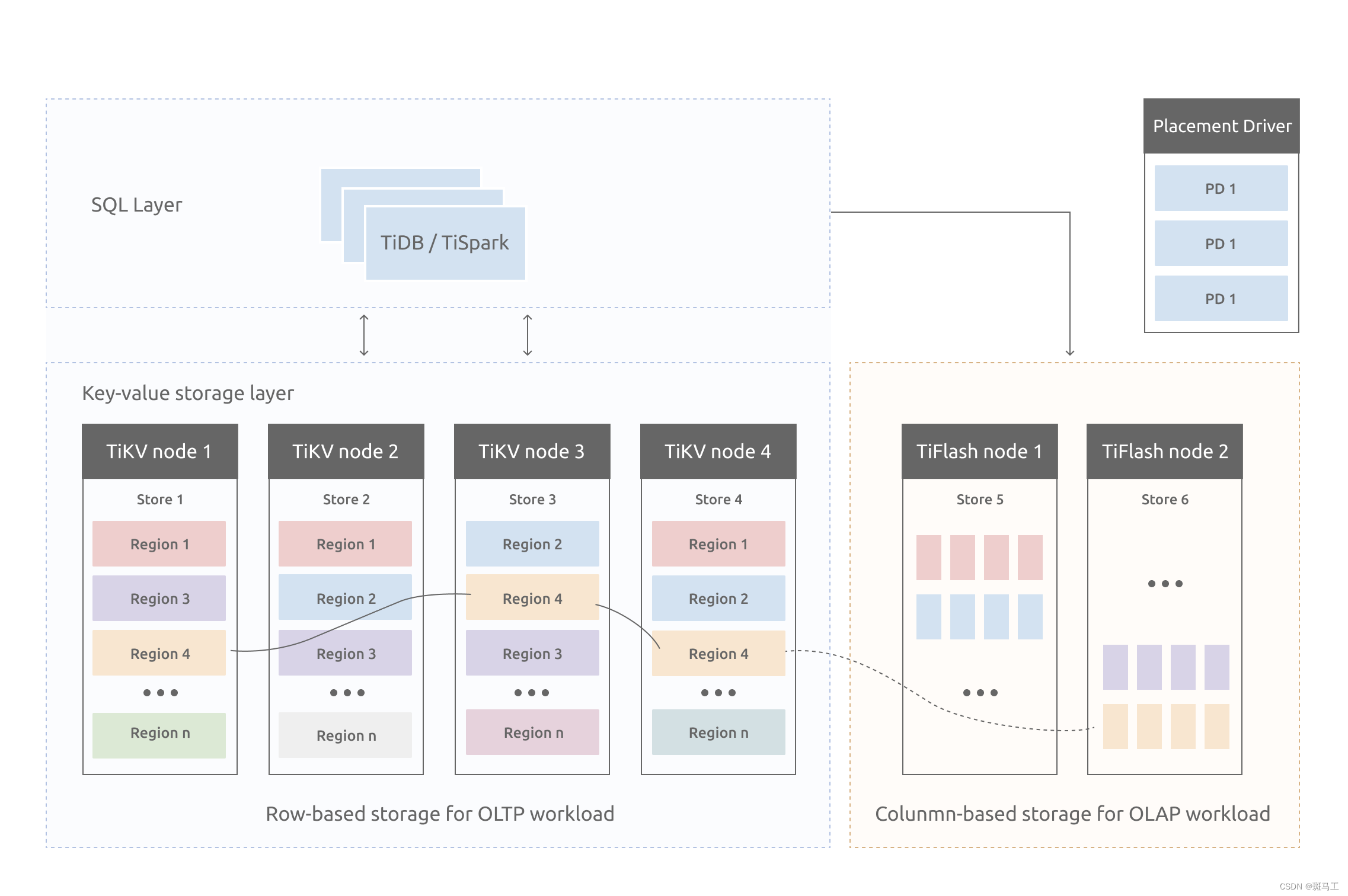
写爬虫很难?在我看来,写爬虫需要具备一定的编程基础和网络知识,但并不需要非常高深的技术。在学习爬虫的过程中,我发现最重要的是掌握好两个点:一是如何分析网页结构,二是如何处理数据。对于第一个点,我们需要了解HTML、CSS、JavaScript等前端知识,以及使用开发者工具等工具进行网页分析;对于第二个点,我们需要了解正则表达式、XPath、BeautifulSoup等数据处理工具。此外,还需要注意反爬虫机制和法律法规等方面的问题。总之,学习爬虫需要耐心和实践,不断尝试和总结,相信只要坚持下去,一定能够取得不错的成果。

爬取动态网页通常涉及到处理JavaScript,因为许多网站使用JavaScript来加载和显示内容。在这种情况下,仅使用基本的HTTP请求(如Scrapy或Requests库)可能无法获取到完整的页面内容。为了解决这个问题,你可以使用Selenium库,它允许你控制一个实际的浏览器,从而可以执行JavaScript并获取动态加载的内容。
同时,为了避免被目标网站封禁,你可以使用爬虫ip。以下是一个简单的示例,展示如何使用Selenium和爬虫ip爬取动态网页:
1、安装Selenium库:
pip install selenium
2、下载对应的浏览器驱动(如ChromeDriver),并将其添加到系统路径中。
3、编写爬虫代码:
from selenium import webdriver
# 提取ip(http://jshk.com.cn/mb/reg.asp?kefu=xjy)
# 设置爬虫ip
proxy = 'your_proxy_server:port'
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument(f'--proxy-server=http://{proxy}')
# 启动浏览器
driver = webdriver.Chrome(options=chrome_options)
# 访问目标网站
url = 'https://example.com'
driver.get(url)
# 获取页面内容
content = driver.page_source
# 在这里,你可以使用BeautifulSoup或其他库来解析页面内容
# 关闭浏览器
driver.quit()
在这个示例中,你需要将your_proxy_server:port替换为你的爬虫ip服务器地址和端口。如果你的爬虫ip服务器需要认证,可以使用以下格式:
chrome_options.add_argument(f'--proxy-server=http://user:password@{proxy}')
其中,user和password是你的爬虫ip服务器的用户名和密码。
请注意,Selenium相对较慢,因为它需要启动并控制一个实际的浏览器。在实际应用中,你可能需要考虑性能优化,如使用无头浏览器(headless browser)或其他方法来提高爬虫速度。
根据上面的一些建议,其实想要抓取动态网页只要理解透彻上面几个注意点,想要高效率抓取其实没有任何问题。今天的分享就介绍到这里,如果有更多的问题咱们可以评论区留言。