文章目录
- 1. 模型与代码实现
- 1.1. 模型
- 1.2. 代码实现
- 2. Q&A
1. 模型与代码实现
1.1. 模型
- 背景
在分类问题中,模型的输出层是全连接层,每个类别对应一个输出。我们希望模型的输出 y ^ j \hat{y}_j y^j可以视为属于类 j j j的概率,然后选择具有最大输出值的类别作为我们的预测。
softmax函数能够将未规范化的输出变换为非负数并且总和为1,同时让模型保持可导的性质,而且不会改变未规范化的输出之间的大小次序。 - softmax函数
y ^ = s o f t m a x ( o ) \mathbf{\hat{y}}=\mathrm{softmax}(\mathbf{o}) y^=softmax(o)其中 y ^ j = e x p ( o j ) ∑ k e x p ( o k ) \hat{y}_j=\frac{\mathrm{exp}({o_j})}{\sum_{k}\mathrm{exp}({o_k})} y^j=∑kexp(ok)exp(oj) - softmax是一个非线性函数,但softmax回归的输出仍然由输入特征的仿射变换决定,因此,softmax回归是一个线性模型。
- 为了避免将softmax的输出直接送入交叉熵损失造成的数值稳定性问题,将softmax和交叉熵损失结合在一起,具体做法是:不将softmax概率传递到损失函数中, 而是在交叉熵损失函数中传递未规范化的输出,并同时计算softmax及其对数。因此定义交叉熵损失函数时也进行了softmax运算。
1.2. 代码实现
import torch
from torchvision.datasets import FashionMNIST
from torchvision import transforms
from torch.utils.data import DataLoader
from torch import nn
from tensorboardX import SummaryWriter
# 全局参数设置
batch_size = 256
num_workers = 0
num_epochs = 10
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
writer = SummaryWriter()
# 加载数据集
root = "./dataset"
transform = transforms.Compose([transforms.ToTensor()])
mnist_train = FashionMNIST(
root=root,
train=True,
transform=transform,
download=True
)
mnist_test = FashionMNIST(
root=root,
train=False,
transform=transform,
download=True
)
dataloader_train = DataLoader(
mnist_train,
batch_size,
shuffle=True,
num_workers=num_workers
)
dataloader_test = DataLoader(
mnist_test,
batch_size,
shuffle=False,
num_workers=num_workers
)
# 定义神经网络
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10)).to(device)
# 初始化模型参数
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, mean=0, std=0.01)
nn.init.constant_(m.bias, val=0)
net.apply(init_weights)
# 定义损失函数
criterion = nn.CrossEntropyLoss(reduction='none')
# 定义优化器
optimizer = torch.optim.SGD(net.parameters(), lr=0.1)
class Accumulator:
"""在n个变量上累加"""
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
def accuracy(y_hat, y):
"""计算预测正确的数量"""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
for epoch in range(num_epochs):
# 训练模型
net.train()
train_metrics = Accumulator(3) # 训练损失总和、训练准确度总和、样本数
for X, y in dataloader_train:
X, y = X.to(device), y.to(device)
y_hat = net(X)
loss = criterion(y_hat, y)
optimizer.zero_grad()
loss.mean().backward()
optimizer.step()
train_metrics.add(float(loss.sum()), accuracy(y_hat, y), y.numel())
train_loss = train_metrics[0] / train_metrics[2]
train_acc = train_metrics[1] / train_metrics[2]
# 测试模型
net.eval()
with torch.no_grad():
test_metrics = Accumulator(2) # 测试准确度总和、样本数
for X, y in dataloader_test:
X, y = X.to(device), y.to(device)
y_hat = net(X)
loss = criterion(y_hat, y)
test_metrics.add(accuracy(y_hat, y), y.numel())
test_acc = test_metrics[0] / test_metrics[1]
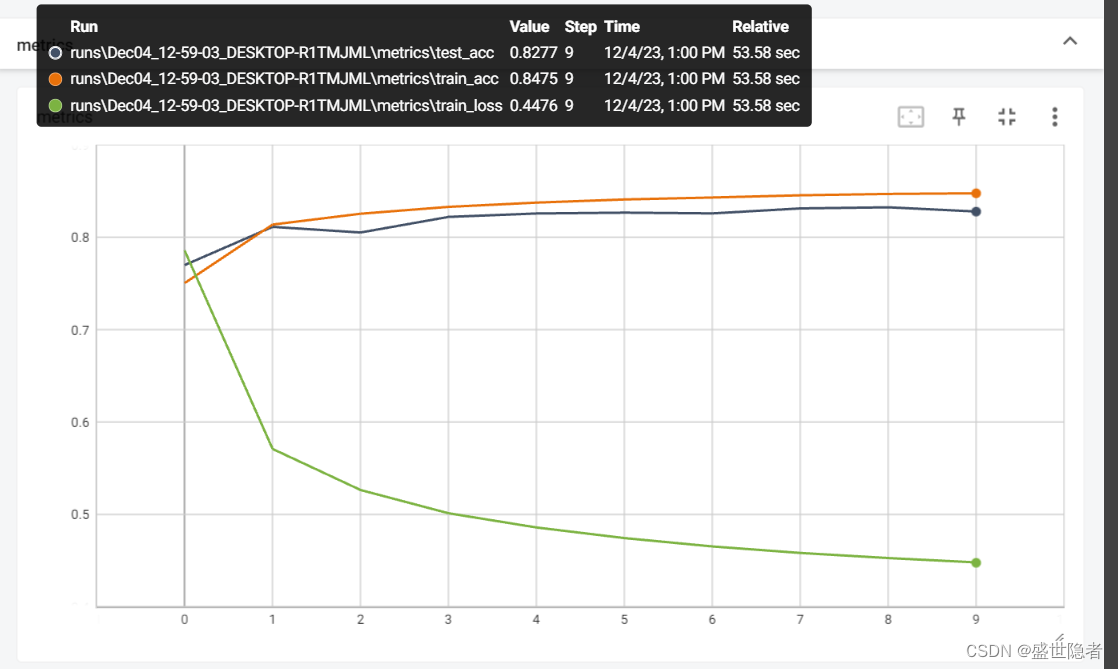
writer.add_scalars("metrics", {
'train_loss': train_loss,
'train_acc': train_acc,
'test_acc': test_acc
},
epoch)
writer.close()
输出结果:
2. Q&A
- 运行过程中出现以下警告:
UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at …\torch\csrc\utils\tensor_numpy.cpp:180.)
return torch.from_numpy(parsed.astype(m[2], copy=False)).view(*s)
该警告的大致意思是给定的NumPy数组不可写,并且PyTorch不支持不可写的张量。这意味着你可以使用张量写入底层(假定不可写)NumPy数组。在将数组转换为张量之前,可能需要复制数组以保护其数据或使其可写。在本程序的其余部分,此类警告将被抑制。因此需要修改C:\Users\%UserName%\anaconda3\envs\%conda_env_name%\lib\site-packages\torchvision\datasets\mnist.py的第498行,将return torch.from_numpy(parsed.astype(m[2], copy=False)).view(*s)中的False改成True。




![[足式机器人]Part2 Dr. CAN学习笔记-Ch0-1矩阵的导数运算](https://img-blog.csdnimg.cn/direct/c7499731c8c04e97a668d03762c8104c.png)