1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
中医舌诊是通过观察舌的各种特征来了解人体的健康状况,从而对各种疾病做出诊断及病情评估,是传统中国医学应用最广、最有价值的诊法之一。近年来,中医舌诊因其简单有效等特点,在国内外得到了越来越多的认可和应用,同时,随着现代科学技术的发展,将图像处理和模式识别等计算机技术与传统中医舌诊相结合,对舌诊的发展和应用具有重要的现实意义和应用价值。传统中医舌诊学朝着计算机化方向发展已经成为必然趋势。本文主要应用纹理分析的方法对一些舌象的分类进行了研究,并首次使用纹理特征对舌图像进行图像分割。 根据对各种疾病的舌图像的大量观察,本文针对不同疾病的舌象特点,比较了多种纹理特征提取方法,确立了每种舌质和苔质的典型特征,应用了一种结合了Gabor滤波和局部二值模式纹理特征提取算法和深度学习算法,并结合纹理特征和颜色特征的进行了舌图像的分割。
2.图片演示



3.视频演示
基于深度学习面向中医诊断的舌象图像分割系统_哔哩哔哩_bilibili
4.舌象的中医指导意义
舌是反映身体内在状态的一面镜子。《内经》曰:“受之内,形之外”。人体内部脏腑的病变可由舌象上的变化得知,是中医诊断学中“见微知著”的具体体现。本文主要研究的是对舌图像按照舌质和不同厚度的苔质进行纹理的分割,而肾病及胃病的舌图像在纹理方面特征比较明显,所以在本章中使用分割后的舌图像针对肾病和胃病进行特征提取。
肾病舌象的纹理特点是舌根部苔质较厚,经临床观察肾病的舌根部苔质多为厚苔或腻苔44],舌苔的变化反映着正邪的消长与病位的深浅,故察舌辨苔可以推断病势的进退,舌苔厚薄变化能比较准确地反映病情轻重及发展趋势的变化[45]。
胃病舌象的纹理特点舌边带状光滑或光滑明高",中医理论认为舌象反映了五脏六腑的生理功能和病理状态,其与胃腑关系尤为密切,素有“舌为胃之镜”之说[46,而舌边带状光滑或光滑明高是胃病的普遍特征之一,是舌诊中重要的胃病判断依据。
特征提取
在本文中,我们使用了两种主要方法进行了舌图像的纹理分割,将纹理按照厚薄的程度不同分为了六类,其中光滑无苔的舌面视为薄厚程度最薄的舌苔,这样在将每一类可以赋予一个舌苔厚薄的指数。在这里,我们简单的将由薄到厚分别定义其薄厚程度指数为1到6,并用候选区域内的像素薄厚指数平均值作为该区域的舌苔厚薄特征。
为了对舌面有一个综合的考虑,在提取肾病的特征的时候,我们将舌面分为几个部分,分区示意图如图a,舌图像最靠近舌根的部分由于拍摄角度和口腔阴影的关系,在分类上容易出现错分,所以为了能够准确提取特征,在进行特征提取的时候要去除。在提取的特征序列N={n,n,n.,nn,}中n,为肾病舌象的病理特征,其他为对比特征。
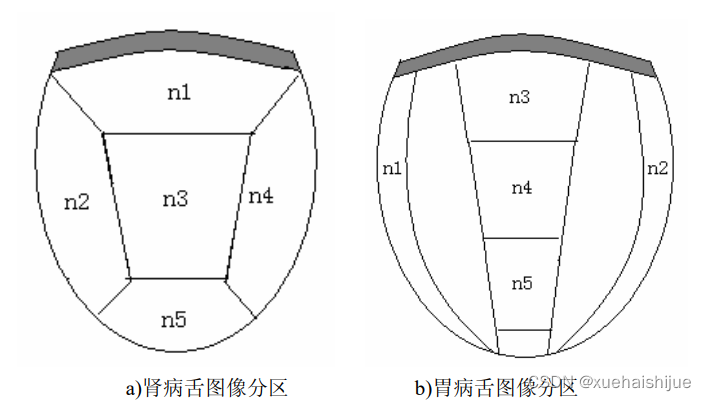
胃病的舌象的纹理特点舌边带状光滑或光滑明高,所以我们将舌面分区时需要综合考虑了这个特征,所以进行舌图像分区的如图。
进行肾病特征检验的时候时使用肾病舌象与健康舌象进行分类实验,进行胃病特征检验的时候用胃病舌象与健康舌象进行分类实验,并在肾病和胃病特征基础上又提出了一种综合胃病和肾病的特征序列,并用该特征序列进行肾病舌象、胃病舌象与健康舌象进行综合分类实验,舌图像分区。
5.核心代码讲解
5.1 fcn.py
下面是封装为类的代码:
import tensorflow as tf
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, Conv2DTranspose, concatenate
class FCNModel(tf.keras.Model):
def __init__(self, input_size=(256, 256, 1), num_classes=2):
super(FCNModel, self).__init__()
self.inputs = Input(input_size)
# 编码器
self.conv1 = Conv2D(32, (3, 3), activation='relu', padding='same')
self.pool1 = MaxPooling2D((2, 2))
self.conv2 = Conv2D(64, (3, 3), activation='relu', padding='same')
self.pool2 = MaxPooling2D((2, 2))
# 解码器
self.deconv1 = Conv2DTranspose(64, (3, 3), strides=(2, 2), padding='same')
self.deconv2 = Conv2DTranspose(32, (3, 3), strides=(2, 2), padding='same')
# 分类器
self.outputs = Conv2D(num_classes, (1, 1), activation='softmax')
def call(self, inputs):
x = self.conv1(inputs)
x = self.pool1(x)
x = self.conv2(x)
x = self.pool2(x)
x = self.deconv1(x)
x = self.deconv2(x)
outputs = self.outputs(x)
return outputs
model = FCNModel()
这个程序文件名为fcn.py,它定义了一个FCN(Fully Convolutional Network)模型。该模型用于图像分割任务,输入大小为256x256的灰度图像,输出为2个类别的分割结果。
该模型的结构如下:
- 输入层:接受大小为256x256x1的输入图像。
- 编码器部分:包括两个卷积层和两个最大池化层。第一个卷积层使用32个3x3的卷积核,激活函数为ReLU,padding方式为same。第一个最大池化层使用2x2的池化核。
- 解码器部分:包括两个转置卷积层。第一个转置卷积层使用64个3x3的卷积核,步长为2x2,padding方式为same。第二个转置卷积层使用32个3x3的卷积核,步长为2x2,padding方式为same。
- 分类器部分:使用一个1x1的卷积层,输出通道数为num_classes(这里为2),激活函数为softmax。
最后,通过tf.keras.Model将输入和输出连接起来,构建模型并返回。
5.2 model.py
import tensorflow as tf
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, Conv2DTranspose, concatenate
class UNet(tf.keras.Model):
def __init__(self, input_size=(256, 256, 1)):
super(UNet, self).__init__()
self.inputs = Input(input_size)
self.x1, self.p1 = self.encoder_block(self.inputs, 64)
self.x2, self.p2 = self.encoder_block(self.p1, 128)
self.x3, self.p3 = self.encoder_block(self.p2, 256)
self.x4, self.p4 = self.encoder_block(self.p3, 512)
self.center = self.conv_block(self.p4, 1024)
self.x = self.decoder_block(self.center, self.x4, 512)
self.x = self.decoder_block(self.x, self.x3, 256)
self.x = self.decoder_block(self.x, self.x2, 128)
self.x = self.decoder_block(self.x, self.x1, 64)
self.outputs = Conv2D(1, (1, 1), activation='sigmoid')(self.x)
self.model = tf.keras.Model(inputs=self.inputs, outputs=self.outputs)
def conv_block(self, input_tensor, num_filters):
x = Conv2D(num_filters, (3, 3), activation='relu', padding='same')(input_tensor)
x = Conv2D(num_filters, (3, 3), activation='relu', padding='same')(x)
return x
def encoder_block(self, input_tensor, num_filters):
x = self.conv_block(input_tensor, num_filters)
p = MaxPooling2D((2, 2))(x)
return x, p
def decoder_block(self, input_tensor, concat_tensor, num_filters):
x = Conv2DTranspose(num_filters, (2, 2), strides=(2, 2), padding='same')(input_tensor)
x = concatenate([x, concat_tensor])
x = self.conv_block(x, num_filters)
return x
这个程序文件是一个实现了U-Net模型的Python代码。U-Net是一种用于图像分割的深度学习模型,它由一个编码器和一个解码器组成。编码器用于提取图像的特征,而解码器用于将特征映射恢复到原始图像的尺寸。
该程序文件中定义了几个函数和一个模型函数:
conv_block函数定义了一个卷积块,它包含两个卷积层,使用ReLU激活函数,并使用相同的填充方式。encoder_block函数定义了一个编码器块,它调用了conv_block函数,并在其输出上应用了最大池化操作。decoder_block函数定义了一个解码器块,它使用转置卷积层将输入特征图的尺寸恢复到原始尺寸,并与一个编码器块的输出进行连接,然后再次调用conv_block函数。unet_model函数定义了整个U-Net模型。它接受一个输入尺寸作为参数,并定义了模型的输入层。然后,它通过调用编码器块和解码器块来构建U-Net模型的结构。最后,它定义了模型的输出层,并返回整个模型。
这个程序文件使用了TensorFlow和Keras库来实现U-Net模型。
5.4 ui.py
class TongueDiagnosis:
def __init__(self, model_path):
self.model = tf.keras.models.load_model(model_path)
def preprocess_image(self, image_path):
img = cv2.imread(image_path)
img = cv2.resize(img, (224, 224))
img = img / 255.0
return img
def diagnose_tongue_color(self, r, g, b):
diagnosis = ''
if 0.37 < r <= 0.39 and g < 0.30:
diagnosis = '淡白舌: 主气血两虚、阳虚'
elif 0.48 < r <= 0.6 and g <= 0.28:
diagnosis = '红舌: 主热症'
elif 0.6 < r and g <= 0.28:
diagnosis = '绛红舌: 主热入营血,或阴虚火旺'
elif r <= 0.37 and g >= 0.30:
diagnosis = '青紫舌: 主气血运行不畅'
elif 0.35 <= r < 0.36 and 0.30 <= g <= 0.31:
diagnosis = '薄白苔: 主外感风热或凉燥'
elif 0.34 <= r < 0.3 and 0.28 < g <= 0.34:
diagnosis = '白腻苔: 主湿浊内停或痰饮、食积'
elif 0.37 <= r <= 0.40 and g >= 0.28:
diagnosis = '薄黄苔: 主热势轻浅,多见风热表证或风寒化热入里'
elif 0.40 <= r and g > 0.25:
diagnosis = '黄腻苔: 主湿热蕴结,痰热内蕴,食积热腐,痰饮化热'
else:
diagnosis = '淡红舌: 气血调和征象,常见于正常人或轻病患者'
return diagnosis
def segment_tongue(self, image_path):
img = self.preprocess_image(image_path)
pred_mask = self.model.predict(np.array([img]))
pred_mask = tf.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., tf.newaxis]
return pred_mask[0]
def diagnose_tongue(self, image_path):
mask = self.segment_tongue(image_path)
img = cv2.imread(image_path)
img = cv2.GaussianBlur(img, (3, 3), 0)
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray_img, 60, 255, cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
contours2 = []
for c in contours:
if cv2.contourArea(c) > 800:
contours2.append(c)
output = np.zeros((img.shape[0], img.shape[1]), dtype=np.uint8)
cv2.drawContours(output, contours, -1, (255, 255, 255), 1)
return output, self.diagnose_tongue_color(mask[0], mask[1], mask[2])
def load_dataset(self, image_path):
images = glob.glob(image_path)
anno = images
dataset = tf.data.Dataset.from_tensor_slices((images, anno))
train_count = len(images)
data_train = dataset.take(train_count)
return data_train
这个程序文件名为ui.py,主要功能是实现一个图形用户界面(GUI),用于加载和处理图像数据。程序中使用了TensorFlow和PyQt5库。
程序中定义了一些函数,包括load_dataset()、check_version()、read_jpg()、read_png()、normal_img()、load_images()、set_config()、diagnose_tongue_color()和seg()等。这些函数用于加载和处理图像数据,进行图像分割和诊断舌苔颜色等操作。
程序中还定义了一个Thread_1类,用于创建一个线程来运行seg()函数。
程序中还定义了一个Ui_MainWindow类,用于创建一个图形用户界面。界面包括两个标签、两个文本浏览器和两个按钮。标签用于显示图像,文本浏览器用于显示诊断结果,按钮用于触发图像处理和诊断操作。
整个程序的主要功能是加载图像数据,进行图像分割和诊断舌苔颜色,并将结果显示在界面上。
5.5 without_ui.py
import tensorflow as tf
import cv2
class ImageSegmentation:
def __init__(self, model_path):
self.model = tf.keras.models.load_model(model_path)
def preprocess_image(self, image_path):
image = cv2.imread(image_path)
image = cv2.resize(image, (224, 224))
image = tf.cast(image, tf.float32)
image = image / 127.5 - 1
return image
def segment_image(self, image_path):
image = self.preprocess_image(image_path)
image = tf.expand_dims(image, axis=0)
pred_mask = self.model.predict(image)
pred_mask = tf.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., tf.newaxis]
return pred_mask.numpy()[0]
def postprocess_mask(self, mask):
gray = cv2.cvtColor(mask, cv2.COLOR_BGR2GRAY)
ret, binary = cv2.threshold(gray, 60, 255, cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
contourmax = []
for c in range(len(contours)):
if cv2.contourArea(contours[c]) < 0.9 * mask.shape[0]*mask.shape[1] and cv2.contourArea(contours[c]) > 0.3 * mask.shape[0]*mask.shape[1]:
contourmax.append(contours[c])
cv2.drawContours(mask, contourmax, -1, (0, 0, 0), -1)
return mask
def apply_mask(self, image_path, output_path):
image = cv2.imread(image_path)
mask = self.segment_image(image_path)
mask = cv2.resize(mask, (image.shape[1], image.shape[0]))
mask = self.postprocess_mask(mask)
stacked = cv2.addWeighted(image, 1, mask, 1, 0)
cv2.imwrite(output_path, stacked)
cv2.imshow('img', stacked)
cv2.waitKey(0)
该程序文件名为without_ui.py,主要功能如下:
- 导入所需的库和模块。
- 定义了load_dataset函数,用于加载数据集。
- 定义了check_version函数,用于检查所需的库的版本。
- 定义了read_jpg和read_png函数,用于读取jpg和png格式的图像文件。
- 定义了normal_img函数,用于对图像进行归一化处理。
- 定义了load_images函数,用于加载图像和annotations,并进行预处理和归一化处理。
- 定义了set_config函数,用于设置数据集的配置,包括多线程数和batch_size。
- 调用check_version函数,检查所需的库的版本。
- 加载指定路径的图像文件。
- 加载数据集。
- 设置数据集的配置。
- 加载训练好的模型。
- 对数据集中的图像进行预测,并将预测结果保存为图片文件。
- 对预测结果进行处理,将预测结果中的指定像素值替换为指定颜色。
- 对处理后的预测结果进行contour操作,找到符合条件的contour。
- 对符合条件的contour进行绘制,并将绘制结果与原始图像叠加。
- 将叠加结果保存为图片文件,并显示在窗口中。
该程序主要用于对图像进行预测和处理,并将处理结果保存为图片文件。
5.6 tools\check_img.py
import cv2
import numpy as np
import os
class ImageCompressor:
def __init__(self, path, train_file):
self.path = path
self.train_file = train_file
def compress_images(self):
result = os.listdir(self.path)
num = 0
if not os.path.exists(self.train_file):
os.mkdir(self.train_file)
for i in result:
try:
image = cv2.imread(self.path + '/' + i)
cv2.imwrite(self.train_file + '/' + 'Compressed' + i, image, [int(cv2.IMWRITE_JPEG_QUALITY), 100])
num += 1
except:
pass
print('数据有效性验证完毕,有效图片数量为 %d' % num)
if num == 0:
print('您的图片命名有中文,建议统一为1(1).jpg/png')
这个程序文件的功能是对指定文件夹中的图片进行降噪和压缩处理。程序首先指定了一个存放图片文件夹的路径,然后获取该路径下的所有文件名。接着,程序创建一个用于存放处理后图片的文件夹,如果该文件夹不存在的话。然后,程序遍历每个文件名,尝试读取图片并进行处理。处理后的图片会以"Compressed"开头的文件名保存到指定的文件夹中。最后,程序会输出有效图片的数量,如果数量为0,则会提示建议统一图片命名为"1(1).jpg/png"。
6.系统整体结构
整体功能和构架概述:
该项目是一个基于深度学习的面向中医诊断的舌象图像分割系统。它包含了多个程序文件,每个文件负责不同的功能。主要的程序文件包括fcn.py、model.py、train.py、ui.py、without_ui.py和tools文件夹中的check_img.py、check_seg.py和url_get.py。
- fcn.py:定义了一个FCN模型,用于图像分割任务。
- model.py:实现了U-Net模型,用于图像分割。
- train.py:用于训练图像分割模型。
- ui.py:实现了一个图形用户界面,用于加载和处理图像数据。
- without_ui.py:用于对图像进行预测和处理,并将处理结果保存为图片文件。
- tools/check_img.py:对指定文件夹中的图片进行降噪和压缩处理。
- tools/check_seg.py:用于检查图像分割结果的准确性。
- tools/url_get.py:用于从指定URL下载图片。
下表总结了每个文件的功能:
| 文件名 | 功能 |
|---|---|
| fcn.py | 定义了一个FCN模型,用于图像分割任务 |
| model.py | 实现了U-Net模型,用于图像分割 |
| train.py | 用于训练图像分割模型 |
| ui.py | 实现了一个图形用户界面,用于加载和处理图像数据 |
| without_ui.py | 对图像进行预测和处理,并将处理结果保存为图片文件 |
| tools/check_img.py | 对指定文件夹中的图片进行降噪和压缩处理 |
| tools/check_seg.py | 用于检查图像分割结果的准确性 |
| tools/url_get.py | 从指定URL下载图片 |
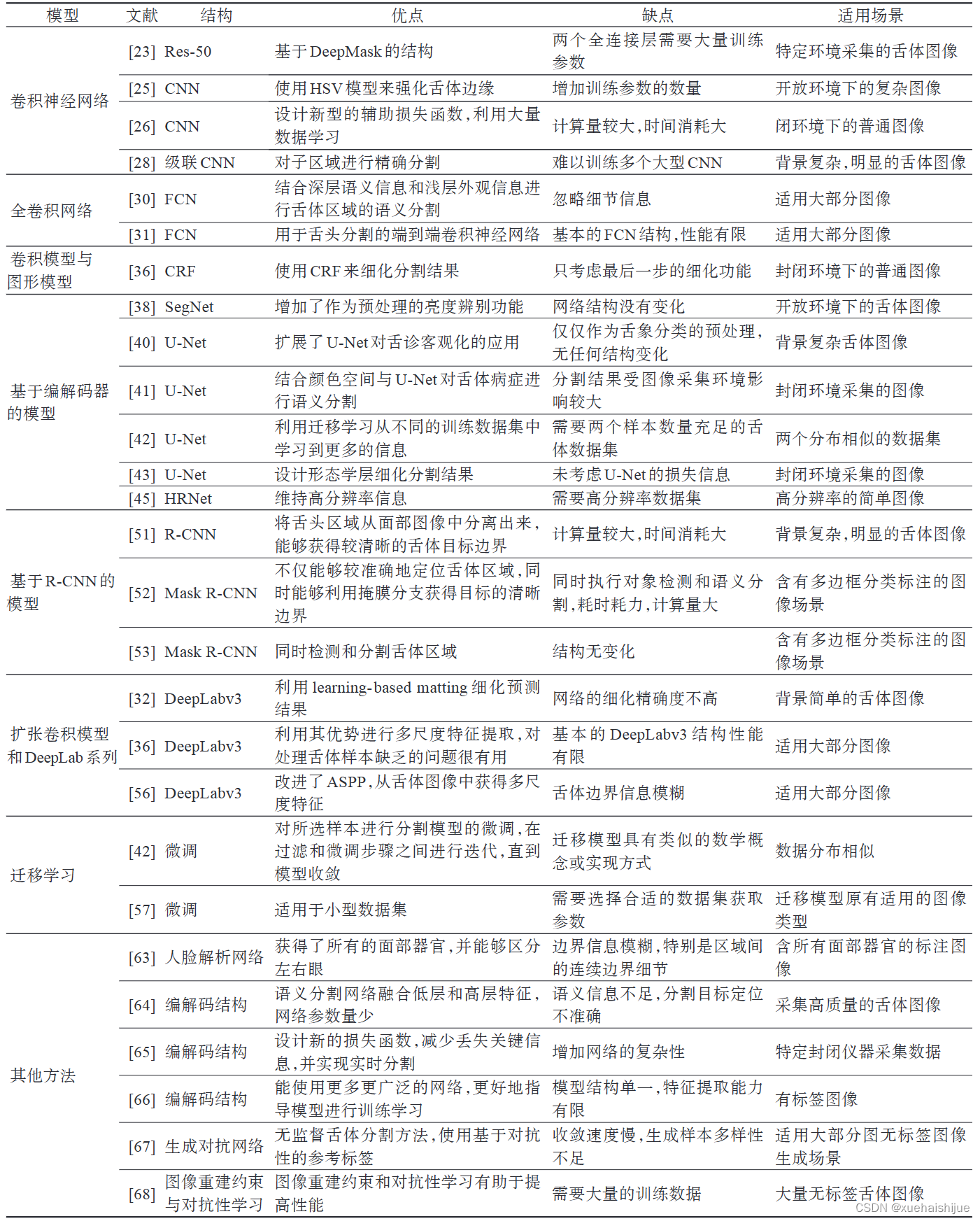
7.基于深度学习的舌体分割方法
卷积神经网络
卷积神经网络(convolutional neural network,CNN)是深度学习中应用最广泛的架构之一,特别是在计算机视觉任务中。CNN可以通过卷积和池化操作﹐自动学习图像各层次的特征。其主要优势是所有的感受野都有相应的权重。因此,与全连接神经网络相比,CNN需要的参数较少。由于卷积神经网络最早被用于手写数字识别$和图像分类0,在计算机视觉领域中得到了广泛的应用。
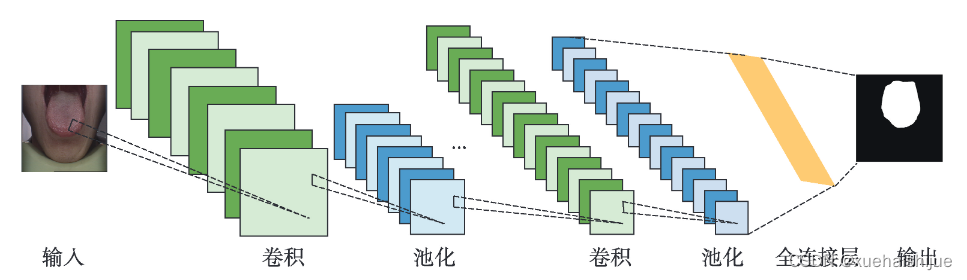
CNN主要由三类层组成:(1)卷积层。应用于降维和特征提取。卷积运算含有激活函数(如 sigmoid、tanh和ReLU)用于数据拟合。(2)池化层。一般指均值或最大池化操作,用统计信息代替特征值,降低空间分辨率。(3)全连接层。在CNN中作为分类器使用,其通过权重矩阵组将所有的局部特征组合成一个完整的结果图。如图3所示。在网络的前半部分,卷积层的感受野较小,用于捕捉图像的局部细节。随着感受野数量的增加,图像信息变得更加复杂和抽象。通过多层卷积运算,得到不同尺度的抽象表示。一些最著名的CNN架构包括:AlexNet[19]、 VGG-Net20]、ResNet21和 DenseNetP2]。Lin等人P设计了一个结合Res-50和 DeepMaskP的舌体分割网络。以50层的ResNet为骨干网络,可以获得更高的分类精度和更低的训练误差。Li等人2设计了一个增强的HSV卷积神经网络预测舌体轮廓。然而,该网络需要一些额外的预处理,如亮度识别和图像增强,这使得整个分割过程变得复杂。Cai等人P⒃提出了一种新型的辅助损失函数,该函数与CNN相结合,利用大量数据学习来建立端到端的分割模型。
然而CNN有如下一些明显的缺点。在训练过程中,每个像素需要遍历提取补丁,因此其速度太慢,而且很难决定通道大小。如果太小会缺乏上下文信息,反之如果太大会导致大量的冗余计算。因此,一些研究者对其进行了改进,充分利用空间信息,如空间包含关系等,可作为图像分割的先验辅助知识加以应用PT。
级联结构可以在处理阶段划分子区域,也可以在细化阶段剔除假阳性结果。阳性像素样本(舌体)和阴性像素样本(背景区域)之间的不平衡可能导致训练模型产生预测偏差。利用子区域层次结构保持高召回率,级联结构可过滤筛选大量的背景区域。Yuan等人2设计了三个级联CNN用于舌体检测分割,每个阶段都有不同的任务。第一阶段是获取候选的舌体区域。下一阶段是选择最终的候选者﹐用边界回归进行校准,并预测34个坐标。最后一个阶段是对这些坐标进行细化,得到分割后的结果。
级联结构大大降低了标签的工作量,并为训练过程提供了足够的监督能力。虽然训练多个子网络比训练单一的端到端网络更困难,计算量较大,时间消耗大,但级联网络考虑到了子区域的空间关系。该结构不仅大大提高了效率,而且提高了准确性。
全卷积网络FCN
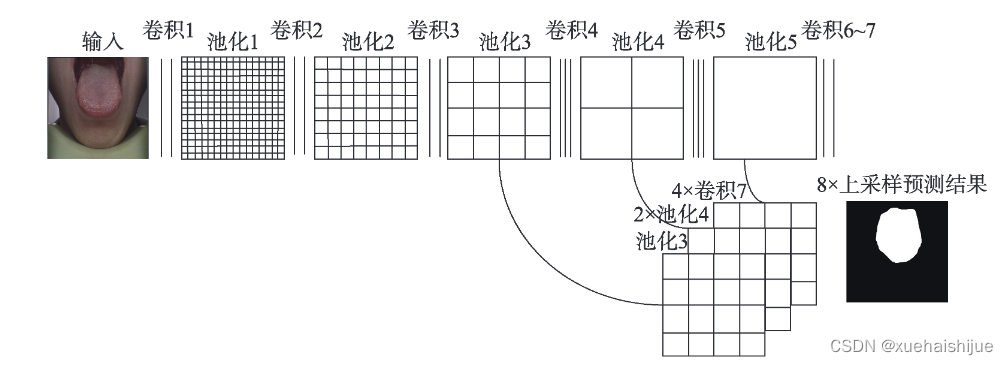
端到端和像素到像素的卷积神经网络被证明优于当时最先进的语义分割方法。全卷积网络( fullyconvolutional network ,FCN)2’用卷积操作代替了传统的全连接操作,其架构交替使用多层普通卷积和池化操作。最后实现了两种转换:分类网络向分割网络的转换和图像级分类向像素级分类的转换。FCN可以解决全连接层中输人图像的大小必须固定的问题(即可以处理任何大小的输入图像)。反卷积层有利于完善输出结果。跳跃连接与不同深度层的结果相结合,可以达到更好的鲁棒性和准确性。Li等人3提出了基于FCN的分割模型,结合深层语义信息和浅层外观信息进行舌体区域的语义分割。Wang等人3采用了FCN来处理舌部轮廓模糊和周围组织颜色相近的问题,从而为后续的舌部分析和辩证诊断获得更好的分割结果。Xue等人[3P’将FCN-8S应用于舌体图像分割,其网络结构如图4所示。由于一系列卷积和池化操作,图像越小,分辨率越低。为了在像素级对图像进行分类,FCN对第五卷积层的输出进行32×上采样,以恢复掩膜的大小。但由于损失了一些细节,原始结果不够准确。因此,第四层和第五层的输出采用了2倍和4倍两种尺度的上采样操作,将其融合在第三层的特征图。最后,上采样操作产生的特征图与输入图像的大小相同。
这项工作被认为是图像分割的一个里程碑﹐表明可以进行端到端图像语义分割的深度学习网络。然而FCN也有一些局限性。上采样操作的结果是模糊的,对图像中的小细节不敏感,这限制了该模型在医学图像分析中的性能。由于速度较慢,不能实时分割对象。此外FCN也不能有效利用全局上下文信息,不易转换为三维模型。
8.基于编解码器的模型
U-Net
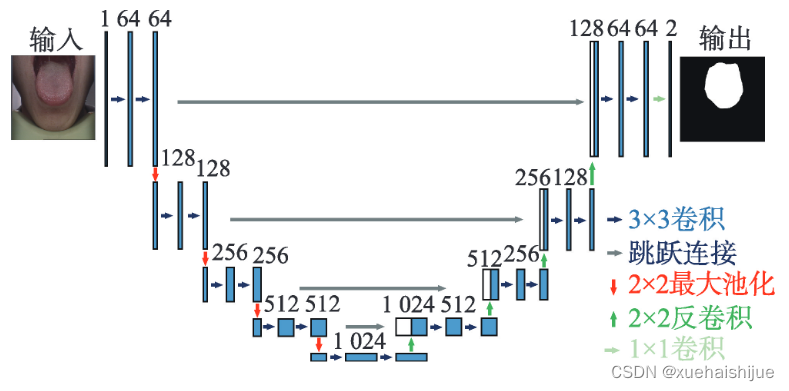
一些模型最初是为生物医学图像分割而设计的,它们的灵感来自于FCN和编解码器模型。Ron-neberger等人P提出了一种用于生物显微镜图像分割的U-Net,如图所示。U-Net有效提高了上下文信息的利用率。同时,它只需要少量的样本,在医学图像领域得到了广泛的应用。其训练策略依赖于数据增强,可以更有效地从现有的注释图像中学习。它的整体结构也由两部分组成:用于捕捉上下文信息的收缩路径(编码网络)和用于精确定位的扩展路径相较于SegNet,U-Net需要更多的内存,单一的卷积核尺寸局限了分割目标的精确度。Xu等人4利用U-Net获取舌体图像特征,从而为后续舌象分类提供准确的分割结果。Trajanovski等人结合颜色空间与U-Net对舌体病症进行语义分割。Li等人P结合U-Net和转移学习,设计了一个名为迭代跨域舌体分割的框架。U-Net用于获取不同数据集的原始掩码和共享权重,以便将共享权重传输到下一阶段。由于经典的U-Net会产生一个带有噪声的粗糙预测结果,Zhou等人设计了一个形态层来完善预测结果,证明了所提出的网络不仅可以得到更快、更准确的结果,而且可以应对舌体的特征不同的挑战。
9.迁移学习
深度学习需要大量的数据,这样可以利用数据增强来改善这一问题。为了进一步提高网络的准确性,可以将转移学习应用于舌体图像分割,从预先训练的模型中提取网络权重的主要特征。另外,转移学习可以避免网络过拟合,加快训练速度。转移学习有两种策略:第一种是微调,第二种是冻结与训练。微调使用原有数据集的预训练模型,并训练目标数据集的所有层,它适用于训练一个较大的数据集。冻结与训练是冻结除用于分类的全连接层以外的所有层(它们的权重不更新),然后训练最后一层。此外,它还可以冻结前几层,然后对其余层进行微调。它适用于少数数据集。迁移学习一般适用于两个数据分布较为相似的数据集训练。
卢运西等人[0T利用ImageNet数据集的预训练模型来初始化网络的权重。该方法训练了舌体数据集中的所有层,使各个网络更好地应用于舌体图像分割。当损失曲线和分割精度曲线变得稳定时,网络停止训练。
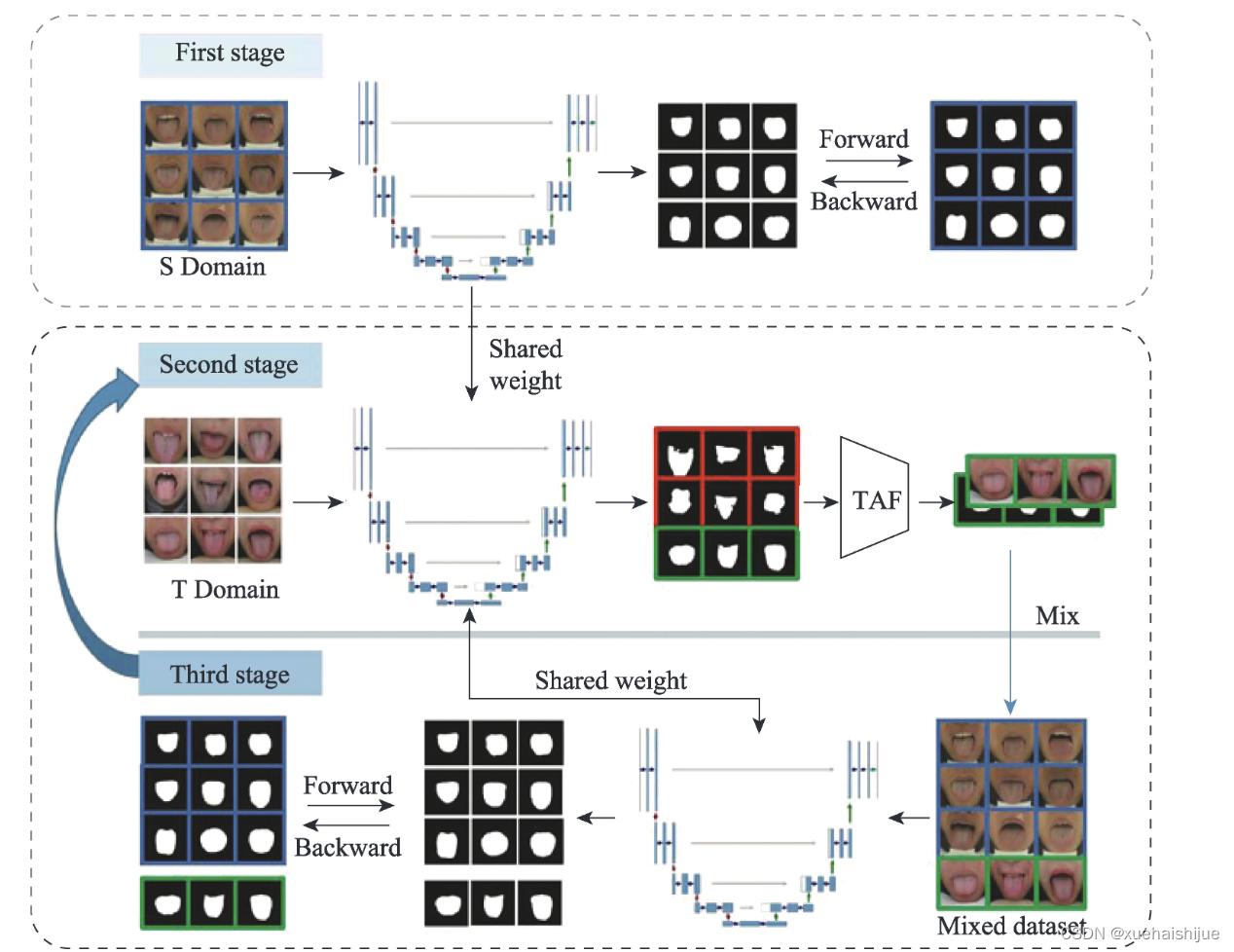
Li等人根据目标数据集的U-Net预测掩码选择满意的样本,如图所示。对所选样本进行分割模型的微调,在过滤和微调步骤之间进行迭代,直到模型收敛。
数据集与模型训练
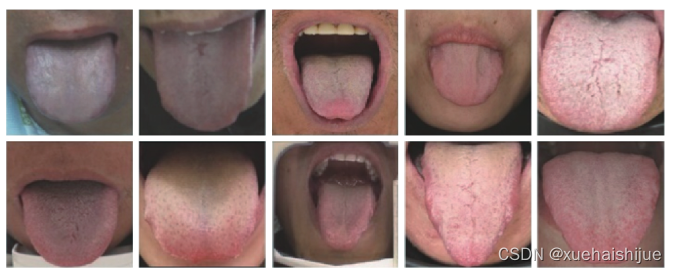
大多数研究者使用的是自建数据库,其数据库从各医院和互联网上收集并经由专业人员注释,如图所示。在训练深度学习模型的过程中,训练样本的数量对分割模型的性能有直接影响。如果样本数量较少,会导致模型过拟合,因此使用数据增强可减少出现这种情况。数据增强是一种数据扩充的方法,通过对原始数据集进行不同的改变,包括旋转﹑翻转﹑裁剪和镜像,从而增加数据样本的数量。数据增强后的舌体图像及其标签作为输入图像输入深度学习网络。
不同算法结果对比
本文选择最优模型进行UI界面的编写
10.系统整合
下图完整源码&数据集&环境部署视频教程&自定义UI界面

参考博客《基于深度学习面向中医诊断的舌象图像分割系统》
11.参考文献
[1]杨帆,廖庆敏.基于图论的图像分割算法的分析与研究[J].电视技术.2006,(7).DOI:10.3969/j.issn.1002-8692.2006.07.025 .
[2]闫成新,桑农,张天序.基于图论的图像分割研究进展[J].计算机工程与应用.2006,(5).DOI:10.3321/j.issn:1002-8331.2006.05.004 .
[3]高丽,令晓明.中医舌诊客观化研究进展[J].仪器仪表学报.2005,(z1).DOI:10.3321/j.issn:0254-3087.2005.z1.302 .
[4]高丽,令晓明.中医舌诊客观化研究进展[J].仪器仪表学报.2005,(8).DOI:10.3321/j.issn:0254-3087.2005.08.329 .
[5]王郁中,杨杰,周越,等.图像分割技术在中医舌诊客观化研究中的应用[J].生物医学工程学杂志.2005,(6).DOI:10.3321/j.issn:1001-5515.2005.06.011 .
[6]王永宏,杨志刚,李韵霞.中医舌诊客观化研究现状与展望[J].中医杂志.2004,(2).DOI:10.3321/j.issn:1001-1668.2004.02.044 .
[7]李斌,马东,钱宗才,等.彩色图像分割方法新进展[J].第四军医大学学报.1998,(0S1).66-68.
[8]刘建龙.基于图论的图像分割算法研究[J].哈尔滨工业大学.2006.
[9]任继军.彩色图象分割及其在中医舌图象处理中的应用[J].西北工业大学.2005.DOI:10.7666/d.y710956 .
[10]章毓晋编著. 图像工程 [M].清华大学出版社,2007.
![[C/C++]数据结构 关于二叉树的OJ题(利用分治思想解决难题)](https://img-blog.csdnimg.cn/direct/8c4ae499ddd44c9884149a83d61ea1ba.png)