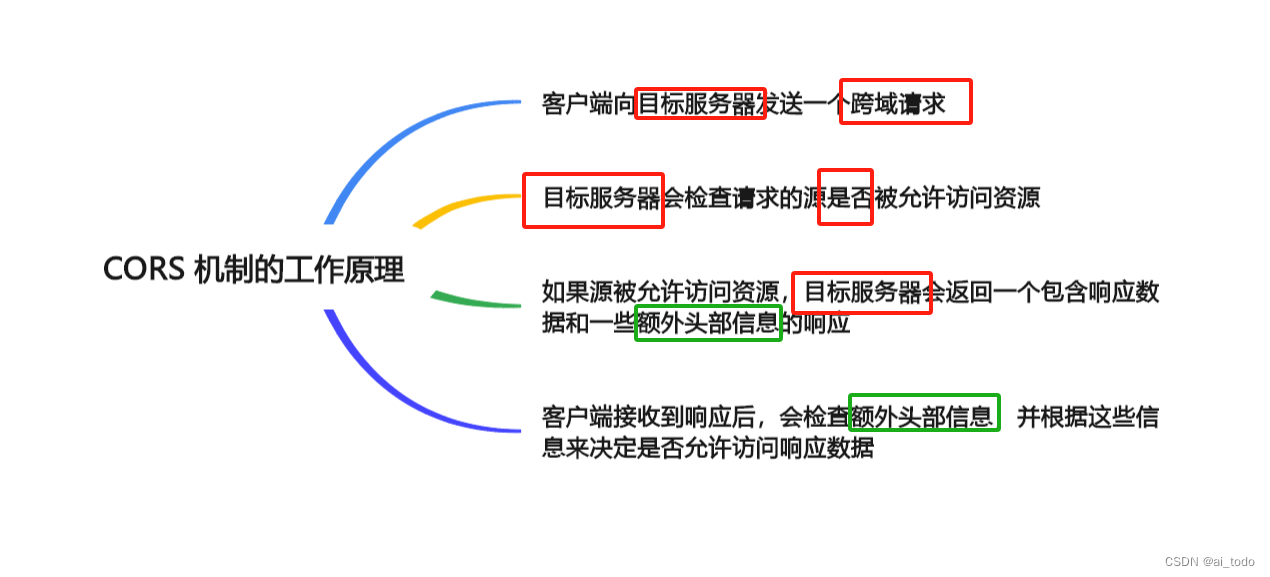
文章目录
- 第一节.准备
- 1.1 版本信息
- 1.2 准备
- 第二节.type
- 2.1 system
- 2.2 const
- 2.3 eq_ref
- 2.4 ref
- 2.5 ref_or_null
- 2.6 index_merge
- 2.7 unique_subquery
- 2.8 range
- 2.9 index
- 2.10 all
- 第三节. Extra
- 3.1 No tables used
- 3.2 No tables used
- 3.3 Using where
- 3.4 No matching min/max row
- 3.5 Using index
- 3.6 Using index condition
- 3.7 Using filesort
- 3.8 Using temporary
- 第四节. Explain总结
第一节.准备
1.1 版本信息
- MySQL 5.6.3以前只能
EXPLAIN SELECT;MYSQL 5.6.3以后就可以EXPLAIN SELECT,UPDATE,DELETE - 在5.7以前的版本中,想要显示 partitions 需要使用
explain partitions命令;想要显示filtered 需要使用explain extended命令。在5.7版本后,默认explain直接显示partitions和filtered中的信息。
1.2 准备
创建两张表,利用函数和存储过程各在两张表中插入10000条数据。
CREATE TABLE s1 (
id INT AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
INDEX idx_key1 (key1),
UNIQUE INDEX idx_key2 (key2),
INDEX idx_key3 (key3),
INDEX idx_key_part(key_part1, key_part2, key_part3)
) ENGINE=INNODB CHARSET=utf8;
CREATE TABLE s2 (
id INT AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
INDEX idx_key1 (key1),
UNIQUE INDEX idx_key2 (key2),
INDEX idx_key3 (key3),
INDEX idx_key_part(key_part1, key_part2, key_part3)
) ENGINE=INNODB CHARSET=utf8;
第二节.type
完整的访问方法如下: system , const , eq_ref , ref , fulltext , ref_or_null ,index_merge , unique_subquery , index_subquery , range , index , ALL 。
2.1 system
当表中只有一条记录,并且该表使用的存储引擎的统计数据是精确的,比如:MyISAM、Memory, 那么对该表的访问方法就是system。
CREATE TABLE t(i INT) ENGINE=MYISAM;
INSERT INTO t VALUES(1);
EXPLAIN SELECT * FROM t;

#换成InnoDB
CREATE TABLE tt(i INT) ENGINE=INNODB;
INSERT INTO tt VALUES(1);
EXPLAIN SELECT * FROM tt;

2.2 const
当我们根据主键或者唯一二级索引列与常数进行等值匹配时,对单表的访问方法就是const
EXPLAIN SELECT * FROM s1 WHERE id = 10005;

EXPLAIN SELECT * FROM s1 WHERE key2 = 10066;

2.3 eq_ref
在连接查询时,如果被驱动表是通过主键或者唯一二级索引列等值匹配的方式进行访问的(如果该主键或者唯一二级索引是联合索引的话,所有的索引列都必须进行等值比较),则对该被驱动表的访问方法就是eq_ref
EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s1.id = s2.id;

2.4 ref
当通过普通的二级索引列与常量进行等值匹配时来查询某个表,那么对该表的访问方法就可能是ref
EXPLAIN SELECT * FROM s1 WHERE key1 = 'a';

2.5 ref_or_null
EXPLAIN SELECT * FROM s1 WHERE key1 = 'a' OR key1 IS NULL;

2.6 index_merge
单表访问方法时在某些场景下可以使用Intersection、Union、Sort-Union这三种索引合并的方式来执行查询
EXPLAIN SELECT * FROM s1 WHERE key1 = 'a' OR key3 = 'a';

2.7 unique_subquery
unique_subquery是针对在一些包含IN子查询的查询语句中,如果查询优化器决定将IN子查询转换为EXISTS子查询,而且子查询可以使用到主键进行等值匹配的话,那么该子查询执行计划的type列的值就是unique_subquery
EXPLAIN SELECT * FROM s1
WHERE key2 IN (SELECT id FROM s2 WHERE s1.key1 = s2.key1) OR key3 = 'a';

2.8 range
如果使用索引获取某些范围区间的记录,那么就可能使用到range访问方法
EXPLAIN SELECT * FROM s1 WHERE key1 IN ('a', 'b', 'c');

EXPLAIN SELECT * FROM s1 WHERE key1 > 'a' AND key1 < 'b';

2.9 index
当我们可以使用索引覆盖,但需要扫描全部的索引记录时,该表的访问方法就是index
EXPLAIN SELECT key_part2 FROM s1 WHERE key_part3 = 'a';

按照常理,因为联合索引是以key_part1开头的,所以此查询无法使用索引。但是要查询的列key_part2的信息包含在此联合索引中,所以解析结果的key列显示使用了联合索引,这就是覆盖索引。但是想找到key_part3 = 'a’的信息,需要扫描全部的索引记录。
2.10 all
最熟悉的全表扫描
EXPLAIN SELECT * FROM s1;

结果值从最好到最坏依次是:
system > const > eq_ref> ref > fulltext > ref_or_null >> index_merge >unique_subquery > index_subquery >range > index > ALL。> 其中比较重要的几个提取出来(红色的字体)。SQL 性能优化的目标:至少要达到 range 级别,要求是 ref 级别,最好是> const级别。(阿里巴巴开发手册要求)
第三节. Extra
更准确的理解MySQL到底将如何执行给定的查询语句
3.1 No tables used
当查询语句的没有FROM子句时将会提示该额外信息
EXPLAIN SELECT 1;

3.2 No tables used
查询语句的WHERE子句永远为FALSE时将会提示该额外信息
EXPLAIN SELECT * FROM s1 WHERE 1 != 1;

3.3 Using where
当我们使用全表扫描来执行对某个表的查询,并且该语句的WHERE子句中有针对该表的搜索条件时,在Extra列中会提示上述额外信息。
EXPLAIN SELECT * FROM s1 WHERE common_field = 'a';

当使用索引访问来执行对某个表的查询,并且该语句的WHERE子句中有除了该索引包含的列之外的其他搜索条件时,在Extra列中也会提示上述额外信息。
EXPLAIN SELECT * FROM s1 WHERE key1 = 'a' AND common_field = 'a';

3.4 No matching min/max row
当查询列表处有MIN或者MAX聚合函数,但是并没有符合WHERE子句中的搜索条件的记录时,将会提示该额外信息
# 此时表中不存在这样的数据
EXPLAIN SELECT MIN(key1) FROM s1 WHERE key1 = 'abcdefg';

3.5 Using index
当我们的查询列表以及搜索条件中只包含属于某个索引的列,也就是在可以使用覆盖索引的情况下,在Extra列将会提示该额外信息。比方说下边这个查询中只需要用到idx_key1而不需要回表操作:
EXPLAIN SELECT key1 FROM s1 WHERE key1 = 'a';

EXPLAIN SELECT key1,id FROM s1 WHERE key1 = 'a';

此时查询列表中多了id列,由于key1的二级索引中含有id信息,所以还是using index;
EXPLAIN SELECT key1,id,key2 FROM s1 WHERE key1 = 'a';

再加一个查询列key2就不能走覆盖索引了。
3.6 Using index condition
有些搜索条件中虽然出现了索引列,但却不能使用到索引。
EXPLAIN SELECT * FROM s1 WHERE key1 > 'z' AND key1 LIKE '%a';

按照正常逻辑,where后的查询条件无法使用索引。但是结果显示使用到了索引,这就是索引下推。
3.7 Using filesort
有一些情况下对结果集中的记录进行排序是可以使用到索引的。
EXPLAIN SELECT * FROM s1 ORDER BY key1 LIMIT 10;

这个查询语句可以利用idx_key1索引直接取出key1列的10条记录,然后再进行回表操作就好了。但是很多情况下排序操作无法使用到索引,只能在内存中(记录较少的时候)或者磁盘中〈(记录较多)的时候进行排序,MySQL把这种在内存中或者磁盘上进行排序的方式统称为文件排序(英文名: filesort)。如果某个查询需要使用文件排序的方式执行查询,就会在执行计划的Extra列中显示Using filesort提示,比如这样:
EXPLAIN SELECT * FROM s1 ORDER BY common_field LIMIT 10;

3.8 Using temporary
在许多查询的执行过程中,MySQL可能会借助临时表来完成一些功能,比如去重、排序之类的,比如我们在执行许多包含DISTINCT、GROUP BY、UNION等子句的查询过程中,如果不能有效利用索引来完成查询,MySQL很有可能寻求通过建立内部的临时表来执行查询。如果查询中使用到了内部的临时表,在执行计划的Extra列将会显示Using temporary提示:
EXPLAIN SELECT DISTINCT common_field FROM s1;

EXPLAIN SELECT common_field, COUNT(*) AS amount FROM s1 GROUP BY common_field;

执行计划中出现Using temporary并不是一个好的征兆,因为建立与维护临时表要付出很大成本的,所以我们最好能使用索引来替代掉使用临时表。比如:扫描指定的索引idx_key1即可
EXPLAIN SELECT key1, COUNT(*) AS amount FROM s1 GROUP BY key1;

第四节. Explain总结
- EXPLAIN不考虑各种Cache,只针对SQL语句做分析
- EXPLAIN不能显示MySQL在执行查询时所作的优化工作,只显示最终结果
- EXPLAIN不会告诉你关于触发器、存储过程的信息或用户自定义函数对查询的影响情况
部分统计信息是估算的,并非精确值(比如rows,filted)