1.GAN
生成对抗网络(GAN)是一种深度学习模型,由两个网络组成:生成器(Generator)和判别器(Discriminator)。生成器负责生成假数据,而判别器则负责判断数据是真实的还是 fake的。这两个网络互相竞争,生成器试图生成更真实的数据以欺骗判别器,而判别器则试图更好地识别生成的数据。
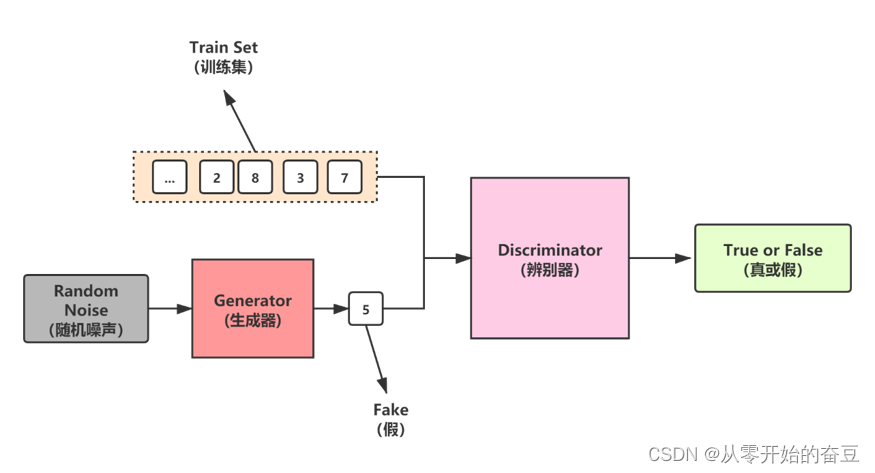
GAN 的基本思想是:通过训练生成器和判别器,使得生成器能够生成与真实数据非常相似的数据,同时使得判别器能够更有效地识别这些数据。
1.1 概念
- 生成器(Generator):生成器是一个神经网络,其目的是生成假的数据,看起来像是真实的。生成器通常包含一些神经网络层,如卷积层、全连接层等。生成器接受随机噪声作为输入,并生成看起来像是真实数据的输出。
- 判别器(Discriminator):判别器也是一个神经网络,其目的是识别数据是真实的还是 fake的。判别器通常也包含一些神经网络层,如卷积层、全连接层等。判别器接受输入数据,并输出一个分数,表示输入数据是真实的还是 fake的。
- 生成对抗训练:生成对抗训练是指同时训练生成器和判别器。生成器试图生成更真实的数据,以欺骗判别器。判别器则试图更好地识别生成的数据,以避免被欺骗。生成器和判别器之间的竞争导致它们不断改进,以提高生成数据的真实性。
- 生成器损失和判别器损失:生成器损失是指生成器试图生成更真实数据的损失。生成器损失通常使用生成器的对抗损失和生成损失之和来计算。判别器损失是指判别器试图更好地识别真实数据和假数据的损失。判别器损失通常使用判别器识别真实数据和假数据的损失之和来计算。
- 对抗性训练:对抗性训练是指在训练过程中,使用生成器生成的假数据来训练判别器,以提高判别器的识别能力。同时,使用判别器识别的反馈来训练生成器,以提高生成器生成更真实数据的能力。
1.2 优势
GAN(Generative Adversarial Network)是一种生成对抗网络,主要由生成器和判别器组成。生成器负责生成假数据,而判别器负责判断数据是真实的还是 fake的。GAN 的训练过程相对复杂,但是它可以生成非常真实的数据,并且可以用来进行数据增强、图像生成、视频生成等应用。
GAN 的优势主要体现在以下几个方面:
- 生成数据非常真实:GAN 可以生成非常真实的数据,可以用来进行数据增强、图像生成、视频生成等应用。
- 可以生成大量数据:GAN 可以生成大量的数据,可以用来进行机器学习、深度学习等应用。
- 可以生成不同类型的数据:GAN 可以生成不同类型的数据,可以用来进行图像生成、视频生成等应用。
- 可以进行对抗训练:GAN 可以进行对抗训练,可以提高模型的鲁棒性和泛化能力。
虽然 GAN 具有优势,但是也存在一些挑战,例如训练过程复杂、生成器容易过拟合、对抗训练难以实现等。因此,在实际应用中,需要根据具体情况进行优化和调整。
1.3 训练技巧
- 使用批归一化(Batch Normalization):批归一化是一种在卷积神经网络中常用的加速训练和提高模型性能的方法。在 GAN 的生成器和判别器中可以使用批归一化来提高性能。
- 使用 Leaky ReLU 激活函数:Leaky ReLU 激活函数是一种在 ReLU 激活函数中加入一个小于 1 的常数,以避免神经元死亡的方法。在 GAN 的生成器和判别器中可以使用 Leaky ReLU 激活函数来提高性能。
- 使用 U-Net 结构:U-Net 是一种用于图像分割的网络结构,其结构可以同时实现编码器和解码器。在 GAN 的生成器中可以使用 U-Net 结构来提高生成图像的质量。
- 使用对抗性损失(Adversarial Loss):对抗性损失是一种可以增加生成器损失的方法,通过在损失函数中加入一个与真实数据接近的噪声来增加生成器的难度。在 GAN 的训练过程中可以使用对抗性损失来提高性能。
- 使用预训练模型:预训练模型是一种在已有数据集上训练好的模型,可以用于迁移学习和提高性能。在 GAN 的生成器和判别器中可以使用预训练模型来提高性能。
- 使用注意力机制(Attention):注意力机制是一种可以提高模型性能和泛化能力的方法,可以在 GAN 的生成器和判别器中使用注意力机制来提高性能。
总结起来,GAN 的训练过程需要综合考虑多个方面,包括数据预处理、损失函数选择、正则化、梯度裁剪、对抗性训练、数据增强和 early stopping 等技巧。同时,还可以使用一些额外的技巧,如批归一化、Leaky ReLU 激活函数、U-Net 结构、对抗性损失、预训练模型和注意力机制等来进一步提高 GAN 的性能。
2 代码实现
步骤:
- 导入所需的库和模块。
- 定义生成器的网络结构,包括全连接层和激活函数。
- 定义判别器的网络结构,也包括全连接层和激活函数。
- 定义训练函数,包括将模型移动到设备、定义损失函数和优化器、开始训练的循环等。
- 设置随机种子。
- 设置设备,如果有可用的GPU则使用GPU,否则使用CPU。
- 加载MNIST数据集,并进行数据预处理。
- 初始化生成器和判别器。
- 设置训练的参数,如训练轮数、生成器的输入维度等。
- 调用训练函数进行训练。
# 导入torch模块
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
# 定义生成器的网络结构
class Generator(nn.Module):
def __init__(self, latent_dim):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(latent_dim, 256), # 全连接层,输入latent_dim维,输出256维
nn.LeakyReLU(0.2), # LeakyReLU激活函数
nn.Linear(256, 512), # 全连接层,输入256维,输出512维
nn.LeakyReLU(0.2),
nn.Linear(512, 1024), # 全连接层,输入512维,输出1024维
nn.LeakyReLU(0.2),
nn.Linear(1024, 784), # 全连接层,输入1024维,输出784维
nn.Tanh() # Tanh激活函数
)
def forward(self, x):
return self.model(x)
# 定义判别器的网络结构
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 512), # 全连接层,输入784维,输出512维
nn.LeakyReLU(0.2),
nn.Linear(512, 256), # 全连接层,输入512维,输出256维
nn.LeakyReLU(0.2),
nn.Linear(256, 1), # 全连接层,输入256维,输出1维
nn.Sigmoid() # Sigmoid激活函数
)
def forward(self, x):
return self.model(x)
# 定义训练函数
def train(generator, discriminator, dataloader, num_epochs, latent_dim, device):
# 将模型移动到设备
generator.to(device)
discriminator.to(device)
# 定义损失函数和优化器
criterion = nn.BCELoss() # 二分类交叉熵损失函数
optimizer_G = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999)) # 生成器的优化器
optimizer_D = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999)) # 判别器的优化器
# 开始训练
for epoch in range(num_epochs):
for i, (real_images, _) in enumerate(dataloader):
# 将图像转换为向量
real_images = real_images.view(-1, 784).to(device)
# 获取图像的batch_size
batch_size = real_images.size(0)
# 定义真实标签和 fake标签
real_labels = torch.ones(batch_size, 1).to(device)
fake_labels = torch.zeros(batch_size, 1).to(device)
# 训练判别器
optimizer_D.zero_grad()
# 计算真实图像的输出
real_outputs = discriminator(real_images)
# 计算真实图像的损失
real_loss = criterion(real_outputs, real_labels)
# 生成假图像
z = torch.randn(batch_size, latent_dim).to(device)
fake_images = generator(z)
# 计算假图像的输出
fake_outputs = discriminator(fake_images.detach())
# 计算假图像的损失
fake_loss = criterion(fake_outputs, fake_labels)
# 计算判别器的损失
d_loss = real_loss + fake_loss
# 反向传播
d_loss.backward()
# 更新参数
optimizer_D.step()
# 训练生成器
optimizer_G.zero_grad()
# 计算假图像的输出
fake_outputs = discriminator(fake_images)
# 计算生成器的损失
g_loss = criterion(fake_outputs, real_labels)
# 反向传播
g_loss.backward()
# 更新参数
optimizer_G.step()
# 每200步打印一次损失
if (i+1) % 200 == 0:
print(f"Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(dataloader)}], "
f"D_loss: {d_loss.item():.4f}, G_loss: {g_loss.item():.4f}")
# 每1步打印一次图像
if (epoch+1) % 1 == 0:
# 生成图像
with torch.no_grad():
z = torch.randn(10, 100).to(device)
generated_images = generator(z).cpu().view(-1, 28, 28)
# 展示原始数据和生成数据的图像
fig, axes = plt.subplots(2, 5, figsize=(10, 4))
for i, ax in enumerate(axes.flat):
if i < 5:
ax.imshow(real_images[i].view(28, 28), cmap='gray')
ax.set_title('Real')
else:
ax.imshow(generated_images[i-5], cmap='gray')
ax.set_title('Generated')
ax.axis('off')
plt.tight_layout()
plt.show()
# 设置随机种子
torch.manual_seed(42)
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载MNIST数据集
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.MNIST(root="./data", train=True, transform=transform, download=True)
train_dataloader = DataLoader(train_dataset, batch_size=64, shuffle=True)
# 初始化生成器和判别器
latent_dim = 100
generator = Generator(latent_dim)
discriminator = Discriminator()
# 训练GAN模型
num_epochs = 50
train(generator, discriminator, train_dataloader, num_epochs, latent_dim, device)
2.1结果
第一轮:

训练之后: