Flume 功能

Flume主要作用,就是实时读取服务器本地磁盘数据,将数据写入到 HDFS。
Flume是 Cloudera提供的高可用,高可靠性,分布式的海量日志采集、聚合和传输的系统工具。
Flume 架构
Flume组成架构如下图所示:
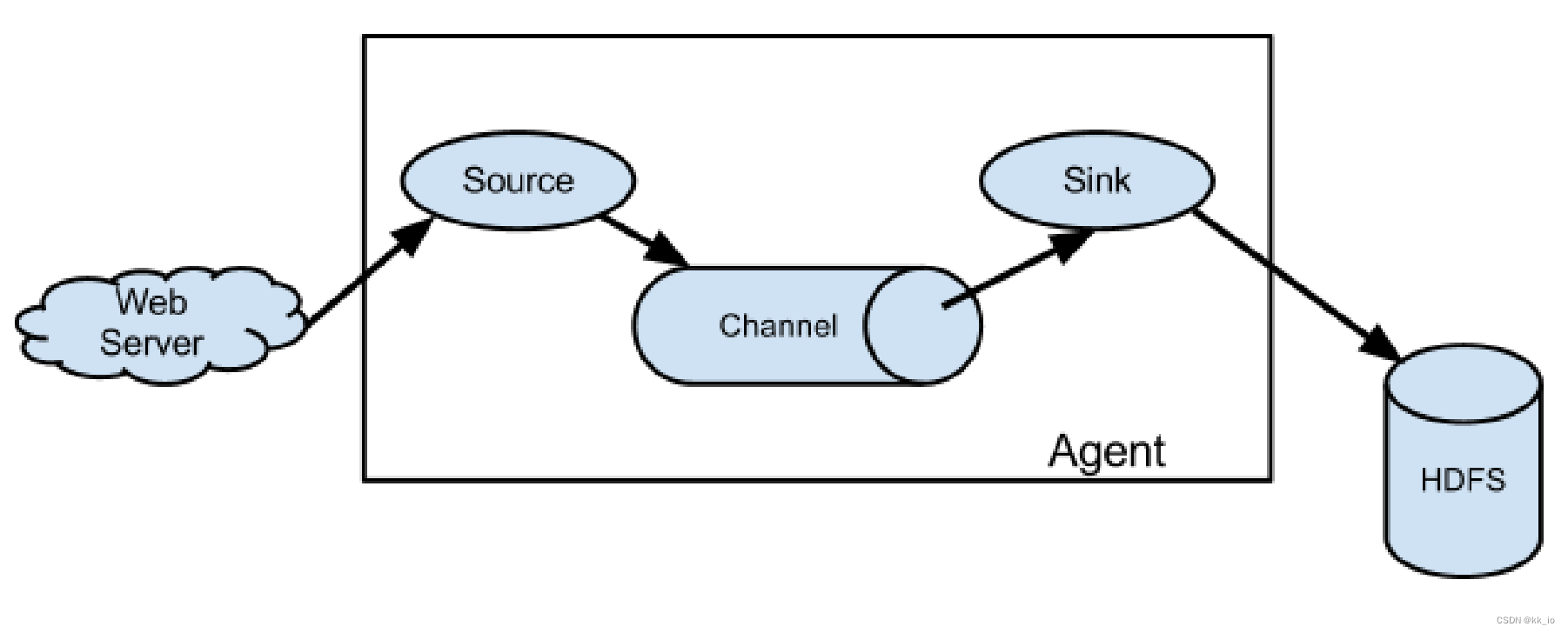
Agent
每个 Agent 代表着一个 JVM 进程,它以事件的方式将数据从源头送至目的地。
Agent 由 3 个部分组成,Source、Channel、Sink。
- Source:Source是负责接收数据到Flume Agent 的组件,Source 组件可以处理各种类型、各种格式的日志数据。
- Sink:Sink不断轮询Channel中的事件并且批量移除他们,并将这些数据批量写入到存储或者索引系统,或被发送到另一个Flume Agent。
- Channel:Channel是位于Source 和Sink 之间的缓冲区。因此,Channel允许 Source和 Sink 有不同的运行速率。Channel 是线程安全的, 可以同时处理几个 Source 的写操作和多个 Sink 的读操作。
Flume自带两种 Channel:Memory Channel 和File Channel。
Memory Channel 是一个内存队列,Source将事件写入其尾部,Sink从其头部读取事件。 Memory Channel 将源写入的事件存储在堆上。由于它将所有数据存储在内存中,因此提供了高吞吐量。 它最适合那些不担心数据丢失的流。 它不适合涉及数据丢失的数据流。
File Channel将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。 - Event:Flume 传输数据的基本单元,数据以 Event的形式将数据从源头送至目的地。Event由Header 和 Body 组成,Header用来存放event 的属性,为 K-V结构,Body 用于存放数据,为字节数组结构。
安装 flume
话不多说,直接开始安装 flume。
- 前往 http://archive.apache.org/dist/flume/ , 选择1.9.0
- 将apache-flume-1.9.0-bin.tar.gz使用 sftp上传到linux的/opt/software目录下
- 解压apache-flume-1.9.0-bin.tar.gz到/opt/module/目录下
[logan@hadoop101 hadoop]$ tar -zxf /opt/software/apache-flume-1.9.0-bin.tar.gz -C /opt/module/
- 创建软链接
cd /opt/module
ln -snf flume-1.9.0/ flume
- 删除jar 包,否则会报错
cd /opt/module/flume
rm lib/guava-11.0.2.jar
注意删除guava,一定要配置 Hadoop 环境变量,否则会报错:
Caused by: java.lang.ClassNotFoundException: com.google.common.collect.Lists
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 1 more
- 修改log4j.properties配置文件
[logan@hadoop101 flume]$ vim conf/log4j.properties
# 注意是修改内容
flume.log.dir=/opt/module/flume/logs
- 验证 flume
[logan@hadoop101 flume]$ /opt/module/flume/bin/flume-ng version
Flume 1.9.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: d4fcab4f501d41597bc616921329a4339f73585e
Compiled by fszabo on Mon Dec 17 20:45:25 CET 2018
From source with checksum 35db629a3bda49d23e9b3690c80737f9
Flume日志采集
配置解析
需要采集的日志文件分布在hadoop101,hadoop102两台日志服务器,故需要在hadoop101,hadoop102上配置日志采集 Flume。Flume需要采集日志文件内容,并对日志格式(JSON)进行校验,然后将校验通过的日志发送到 Kafka。
此处选择TailDirSource和 KafkaChannel。
- TailDirSource优势:支持断点续传、多目录。
- KafkaChannel优势:省去了 Sink,提高了效率。
- 日志采集 Flume关键配置 :
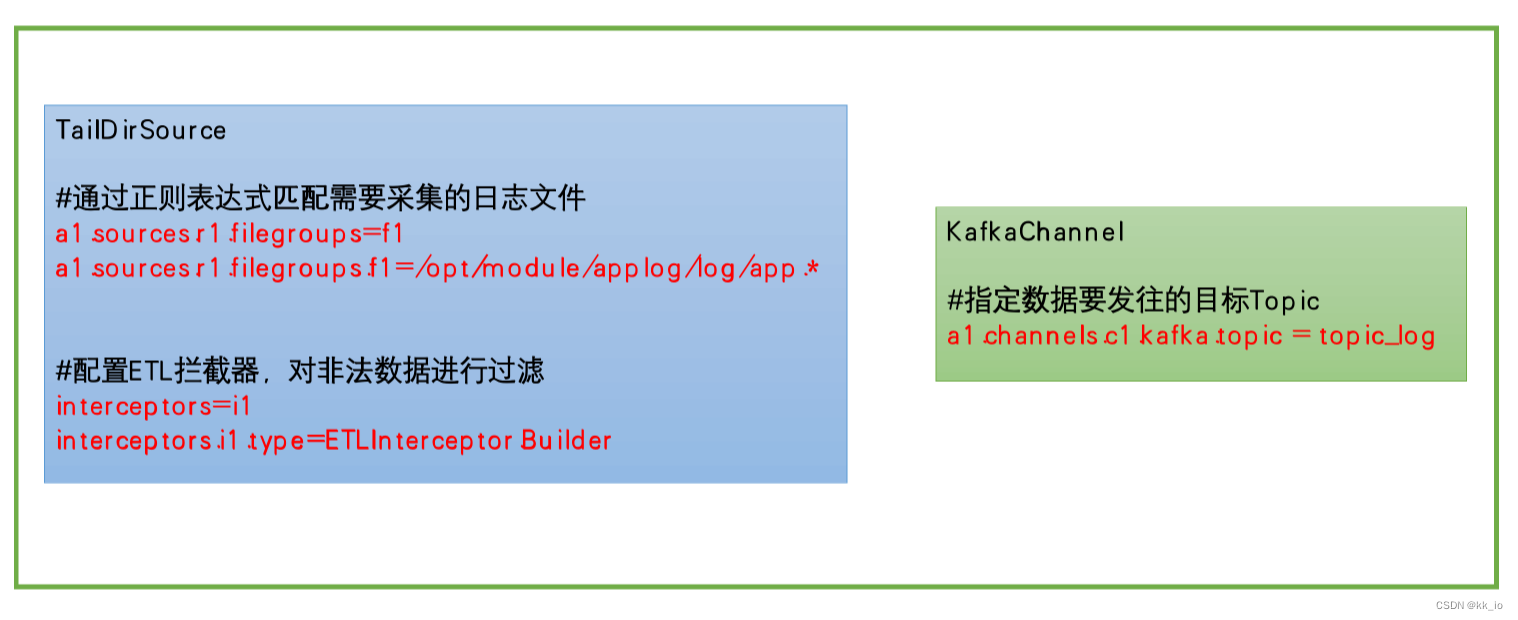
Flume日志采集配置
- 创建Flume 配置文件
[logan@hadoop101 flume]$ pwd
/opt/module/flume
[logan@hadoop101 flume]$ mkdir job
[logan@hadoop101 flume]$ vim job/file_to_kafka.conf
#定义组件
a1.sources = r1
a1.channels = c1
#配置source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.logan.gmall.flume.interceptor.ETLInterceptor$Builder
#配置channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop101:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false
#组装
a1.sources.r1.channels = c1
- 编写拦截器
- 创建Maven工程flume-interceptor
- 创建包:com.logan.gmall.flume.interceptor
- 在pom.xml文件中添加如下配置
<dependencies> <dependency> <groupId>org.apache.flume</groupId> <artifactId>flume-ng-core</artifactId> <version>1.9.0</version> <scope>provided</scope> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.62</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>2.4</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build>- 在com.logan.gmall.flume.utils包下创建JSONUtil类
package com.logan.gmall.flume.utils; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONException; public class JSONUtil { /** * 通过异常判定是否是JSON字符串 */ public static boolean isJSONValidate(String input){ try { JSON.parseObject(input); return true; } catch (JSONException e) { return false; } } }- 在com.logan.gmall.flume.interceptor包下创建ETLInterceptor类
package com.logan.gmall.flume.interceptor; import com.logan.gmall.flume.utils.JSONUtil; import org.apache.flume.Context; import org.apache.flume.Event; import org.apache.flume.interceptor.Interceptor; import java.nio.charset.StandardCharsets; import java.util.Iterator; import java.util.List; public class ETLInterceptor implements Interceptor { @Override public void initialize() { } @Override public Event intercept(Event event) { //1、获取body当中的数据并转成字符串 byte[] body = event.getBody(); String log = new String(body, StandardCharsets.UTF_8); //2、判断字符串是否是一个合法的json,是:返回当前event;不是:返回null if (JSONUtil.isJSONValidate(log)) { return event; } else { return null; } } @Override public List<Event> intercept(List<Event> list) { Iterator<Event> iterator = list.iterator(); while (iterator.hasNext()){ Event next = iterator.next(); if(intercept(next)==null){ iterator.remove(); } } return list; } public static class Builder implements Interceptor.Builder{ @Override public Interceptor build() { return new ETLInterceptor(); } @Override public void configure(Context context) { } } @Override public void close() { } }- 打包
- 将打包文件放到hadoop101 的/opt/moduie/flume/lib文件夹下
采集测试
- 启动Zookeeper、Kafka集群
- 启动 hadoop101上的日志采集Flume
[logan@hadoop101 flume]$ bin/flume-ng agent -n a1 -c conf/ -f job/file_to_kafka.conf -Dflume.root.logger=info,console
- 启动一个Kafka的Console-Consumer
[logan@hadoop101 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop11:9092 --topic topic_log
- 生成模拟数据
[logan@hadoop101 module]$ mkdir -p /opt/module/applog/log/
[logan@hadoop101 module]$ vim /opt/module/applog/log/app.2023-12-02.log
{"common":{"ar":"500000","ba":"iPhone","ch":"Appstore","is_new":"1","md":"iPhone Xs","mid":"mid_552171","os":"iOS 13.3.1","uid":"919","vc":"v2.1.134"},"displays":[{"display_type":"activity","item":"1","item_type":"activity_id","order":1,"pos_id":5},{"display_type":"activity","item":"2","item_type":"activity_id","order":2,"pos_id":5},{"display_type":"query","item":"19","item_type":"sku_id","order":3,"pos_id":4},{"display_type":"query","item":"3","item_type":"sku_id","order":4,"pos_id":2},{"display_type":"query","item":"5","item_type":"sku_id","order":5,"pos_id":2},{"display_type":"promotion","item":"19","item_type":"sku_id","order":6,"pos_id":4},{"display_type":"query","item":"14","item_type":"sku_id","order":7,"pos_id":2},{"display_type":"query","item":"9","item_type":"sku_id","order":8,"pos_id":2},{"display_type":"promotion","item":"35","item_type":"sku_id","order":9,"pos_id":1}],"page":{"during_time":9853,"page_id":"home"},"ts":1672512476000}
{"actions":[{"action_id":"favor_add","item":"9","item_type":"sku_id","ts":1672512480386},{"action_id":"get_coupon","item":"2","item_type":"coupon_id","ts":1672512483772}],"common":{"ar":"500000","ba":"iPhone","ch":"Appstore","is_new":"1","md":"iPhone Xs","mid":"mid_552171","os":"iOS 13.3.1","uid":"919","vc":"v2.1.134"},"displays":[{"display_type":"promotion","item":"19","item_type":"sku_id","order":1,"pos_id":4},{"display_type":"promotion","item":"14","item_type":"sku_id","order":2,"pos_id":5},{"display_type":"query","item":"21","item_type":"sku_id","order":3,"pos_id":1},{"display_type":"query","item":"11","item_type":"sku_id","order":4,"pos_id":2},{"display_type":"promotion","item":"28","item_type":"sku_id","order":5,"pos_id":1}],"page":{"during_time":10158,"item":"9","item_type":"sku_id","last_page_id":"home","page_id":"good_detail","source_type":"promotion"},"ts":1672512477000}
- 观察kafka是否有消费到数据