1.前言
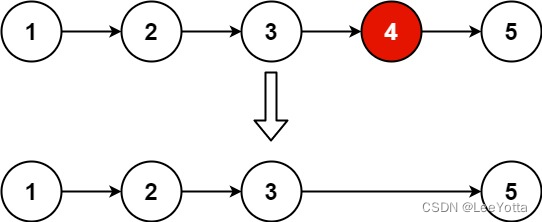
K-mean 是无监督的聚类算法
算法分类:

2.实现步骤
1.数据加工:把数据转为全数字(比如性别男女,转换为0 和 1)
2.模型训练 fit
3.预测
3.代码
原数据类似这样(source:http:img-blog.csdnimg.cn/20201212150816452.png):

代码:
from sklearn.cluster import KMeans from sklearn import preprocessing
skill_info_df.to_excel("C:/work/20230224待分类数据/test.xlsx")
# fordrop the string people Chinese name
for_train_skill_info_df = skill_info_df.iloc[:, 1:]
# set k
k_model = KMeans(n_clusters=5)
# 数据归一化
min_max_scaler = preprocessing.MinMaxScaler()
train_x = min_max_scaler.fit_transform(for_train_skill_info_df)
# 训练模型
k_model.fit(train_x)
predict_y = k_model.predict(train_x)
print(predict_y)
# add predict result to data
skill_info_df['class'] = predict_y
skill_info_df.to_excel("C:/work/20230224预测结果/classified_info.xlsx")
4.常见问题
4.1 数据加工: 行列转换:
python实现列转行--pivot_table函数-CSDN博客
ps:pivot 函数遇到为空情况填充NAN,导入模型会报字符串非数字错误。
解决办法:设置 fill_value 参数:数据为空情况处理,默认填充NAN值。可以修改如果原数据为空,比如设为0
4.2 数据加工:查找df行特定列的值
问题描述:当使用 isin 函数 或者 == 判断时候,返回的是Series 数据类型。不是单独的数值all_prod_df[all_prod_df['product_id'].isin(sample_list)]
直接投到模型中训练会报错
pandas的iloc和loc行列定位-CSDN博客
4.3 修改df数据中的男女为 0 1
basic_info_df['性别'][basic_info_df['性别'] == '男'] = 1 basic_info_df['性别'][basic_info_df['性别'] == '女'] = 0
4.4 df中新增一列,根据list新增
方法1:直接指定df列名赋值为list即可
skill_info_df['age'] = age_list
ps:list的长度要和df对齐
方法二:

df新增一列数据,并指定列名-CSDN博客
4.5 根据df的几列创建新的df
直接 df1 = df[[ '列名' ]]
python中dataframe,df中挑选几列生成新df-CSDN博客