以花朵分类的数据集来进行测试。
Oxford 102 Flowers Dataset 是一个花卉集合数据集,主要用于图像分类,它分为 102 个类别共计 102 种花,其中每个类别包含 40 到 258 张图像。
该数据集由牛津大学工程科学系于 2008 年发布,相关论文有《Automated flower classification over a large number of classes》。
1.制作Dataset
Dataloader作为pytorch数据输入的类型,制作Dataloader就是我们在运行模型时所需要处理的第一个事情。Dataset 存储样本及其相应的标签,DataLoader 将 Dataset 封装为迭代器,要制作Dataloader第一步就是制作Dataset。
通常我们拿到一份数据,数据中有样本表标注文件,比如花朵分类的文件夹中,有训练数据、测试数据、训练数据的标注和测试数据的标注。
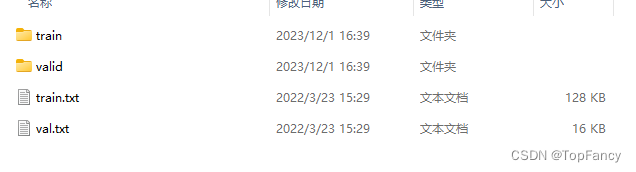
标注文件
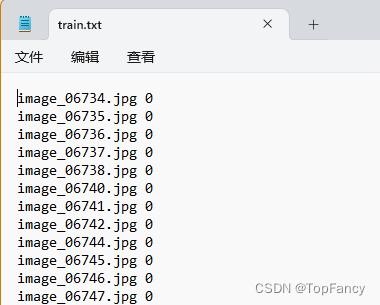
创建dataset只需要集成Dataset中的"__init__“,”__len__“,”__getitem__"三个方法即可,init方法负责将数据读进来,getitem方法用于dataloader迭代获取数据和标注,len用来获取数据数量。
如下所示:
import os
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import torch
from torch import nn
import torch.optim as optim
import torchvision
#pip install torchvision
from torchvision import transforms, models, datasets
#https://pytorch.org/docs/stable/torchvision/index.html
import imageio
import time
import warnings
import random
import sys
import copy
import json
from PIL import Image
from torch.utils.data import Dataset, DataLoader
class FlowerDataset(Dataset):
def __init__(self, root_dir, ann_file, transform=None):
self.ann_file = ann_file
self.root_dir = root_dir
self.img_label = self.load_annotations()
self.img = [os.path.join(self.root_dir,img) for img in list(self.img_label.keys())]
self.label = [label for label in list(self.img_label.values())]
self.transform = transform
def __len__(self):
return len(self.img)
def __getitem__(self, idx):
image = Image.open(self.img[idx])
label = self.label[idx]
if self.transform:
image = self.transform(image)
label = torch.from_numpy(np.array(label))
return image, label
# 用于读取标注文件
def load_annotations(self):
data_infos = {}
with open(self.ann_file) as f:
samples = [x.strip().split(' ') for x in f.readlines()]
for filename, gt_label in samples:
data_infos[filename] = np.array(gt_label, dtype=np.int64)
return data_infos
2.制作Dataloader
- 数据预处理
但我们的数据量比较小时,可以定义一个数据预处理的函数,通过对图像进行裁剪、旋转、灰度转换等来增加数据集的数量。
data_transforms = {
'train':
transforms.Compose([
transforms.Resize(64),
transforms.RandomRotation(45),#随机旋转,-45到45度之间随机选
transforms.CenterCrop(64),#从中心开始裁剪
transforms.RandomHorizontalFlip(p=0.5),#随机水平翻转 选择一个概率概率
transforms.RandomVerticalFlip(p=0.5),#随机垂直翻转
transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),#参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相
transforms.RandomGrayscale(p=0.025),#概率转换成灰度率,3通道就是R=G=B
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#均值,标准差
]),
'valid':
transforms.Compose([
transforms.Resize(64),
transforms.CenterCrop(64),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
然后就可以从实际数据中生成Dataloader了
train_dataset = FlowerDataset(root_dir=train_dir, ann_file = './flower_data/train.txt', transform=data_transforms['train'])
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
![[原创]Delphi的SizeOf(), Length(), 动态数组, 静态数组的关系.](https://img-blog.csdnimg.cn/direct/741c87b9ab8347a2b97774e41ccf6733.png)