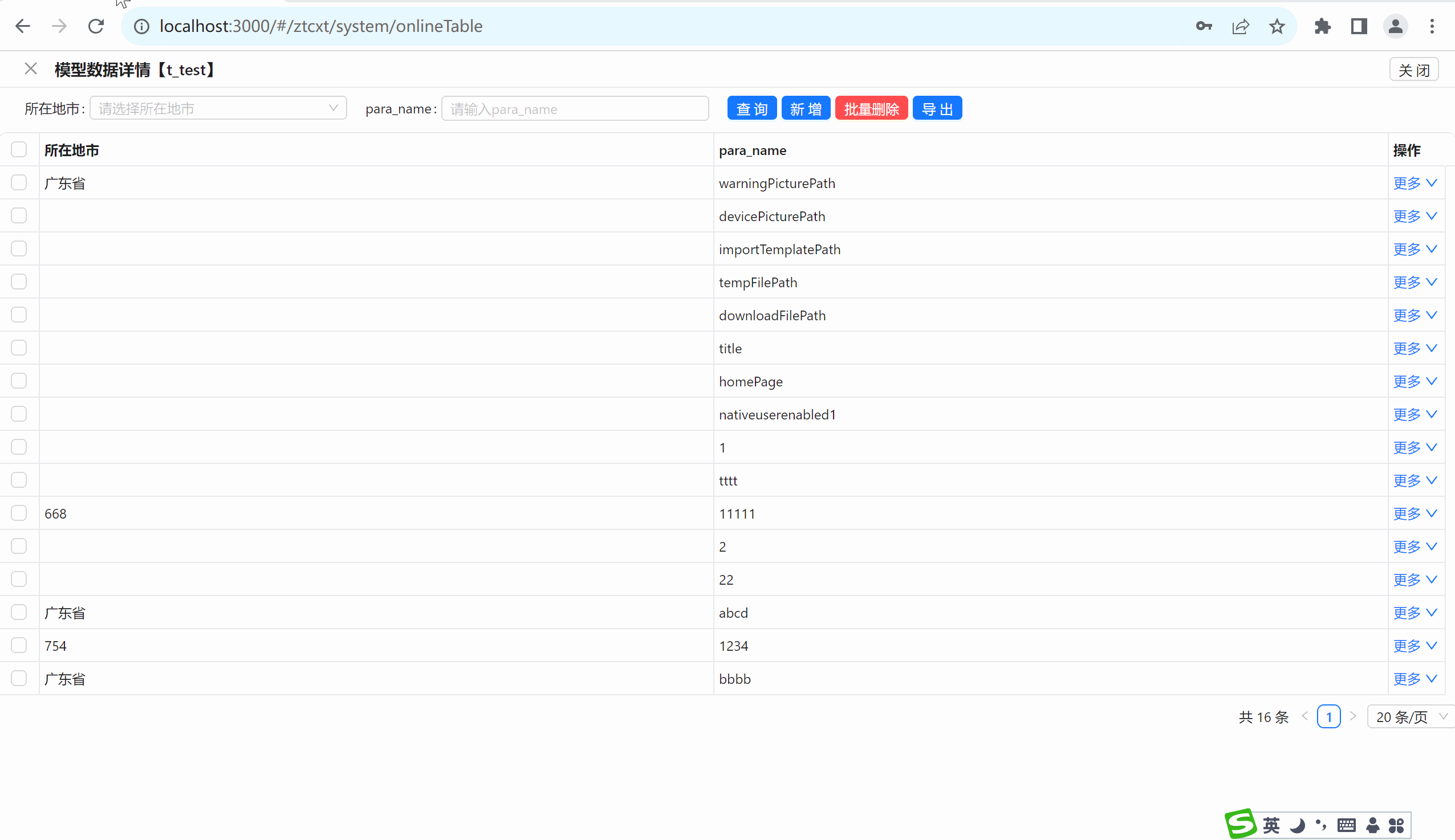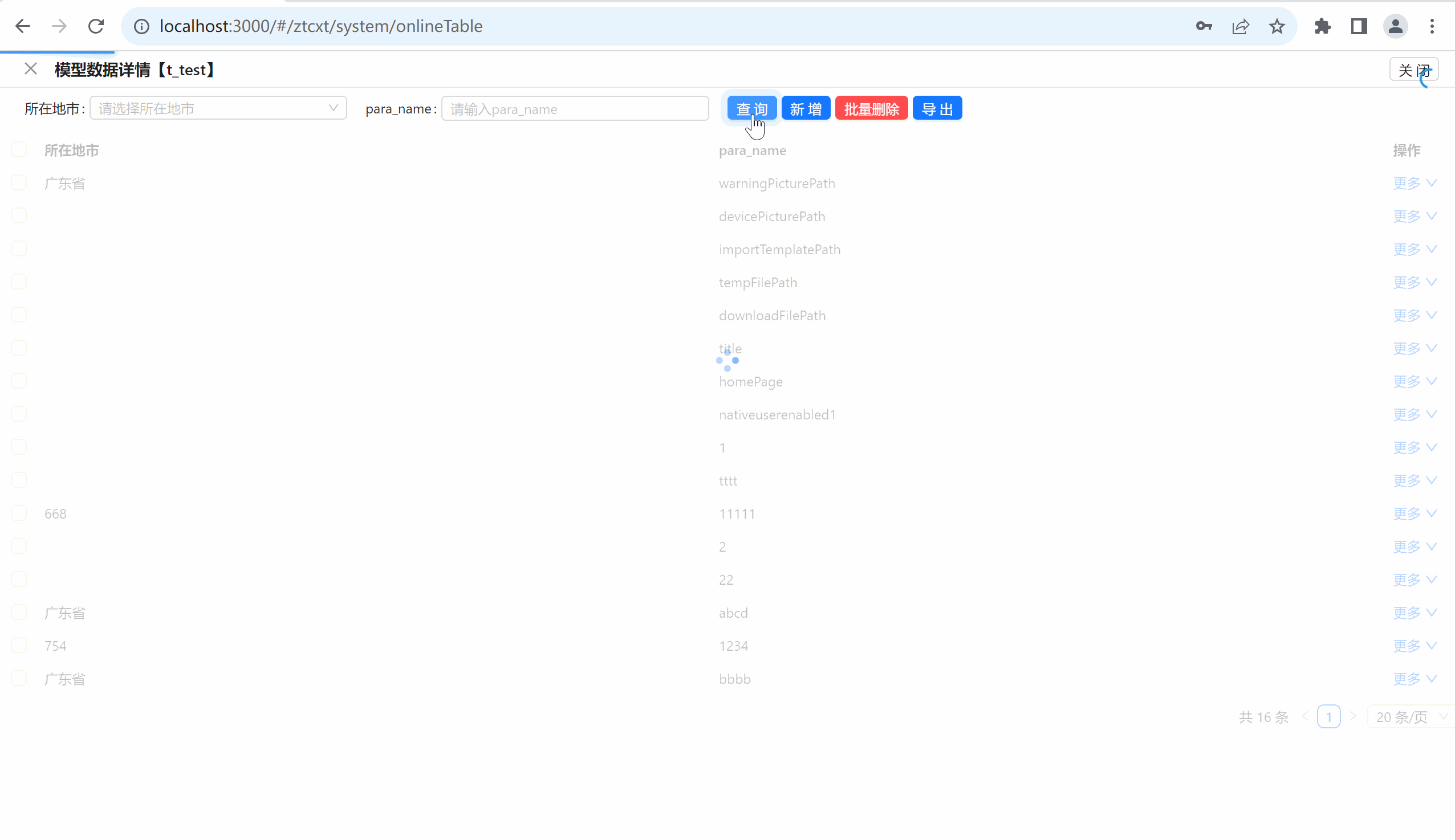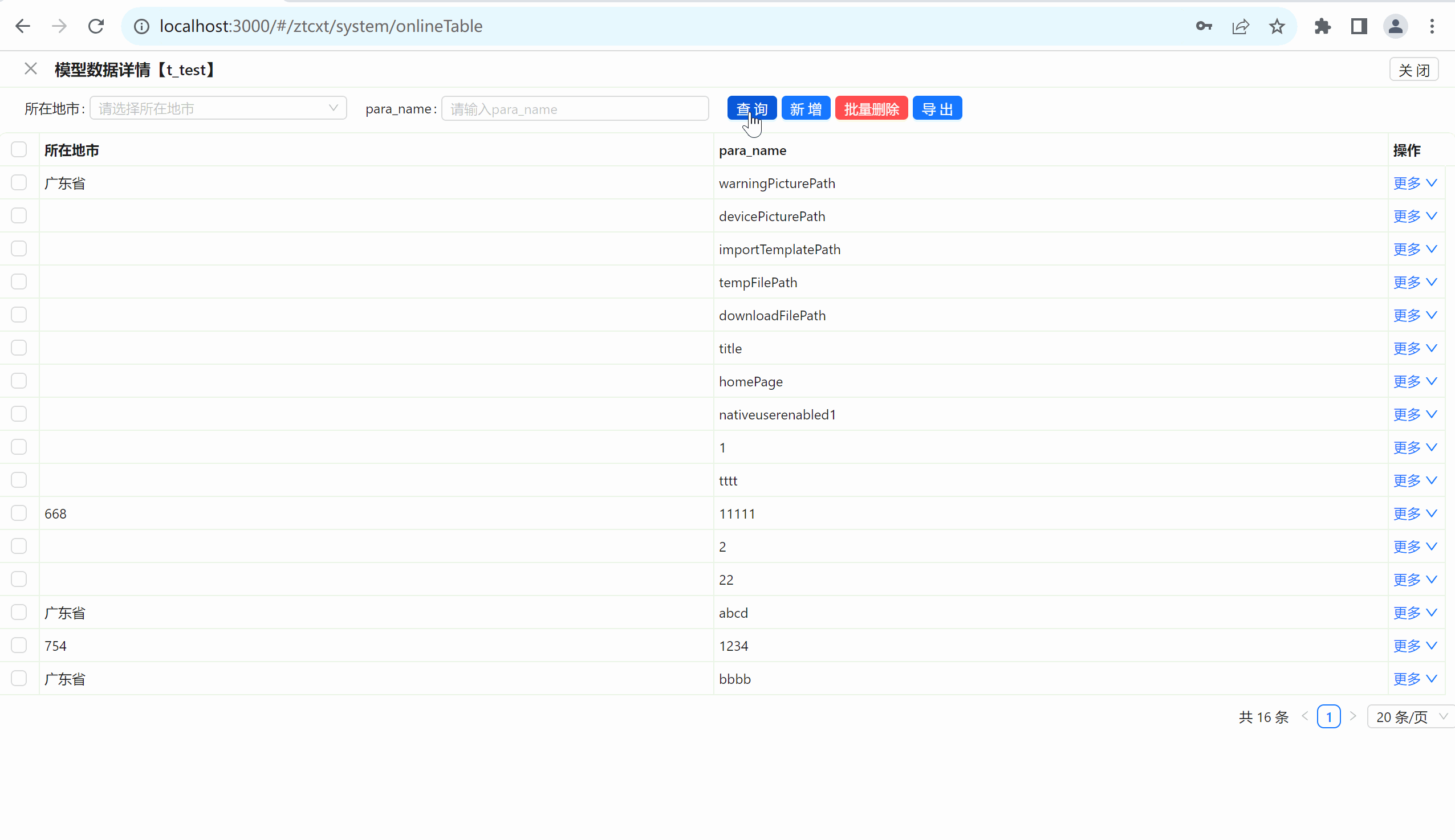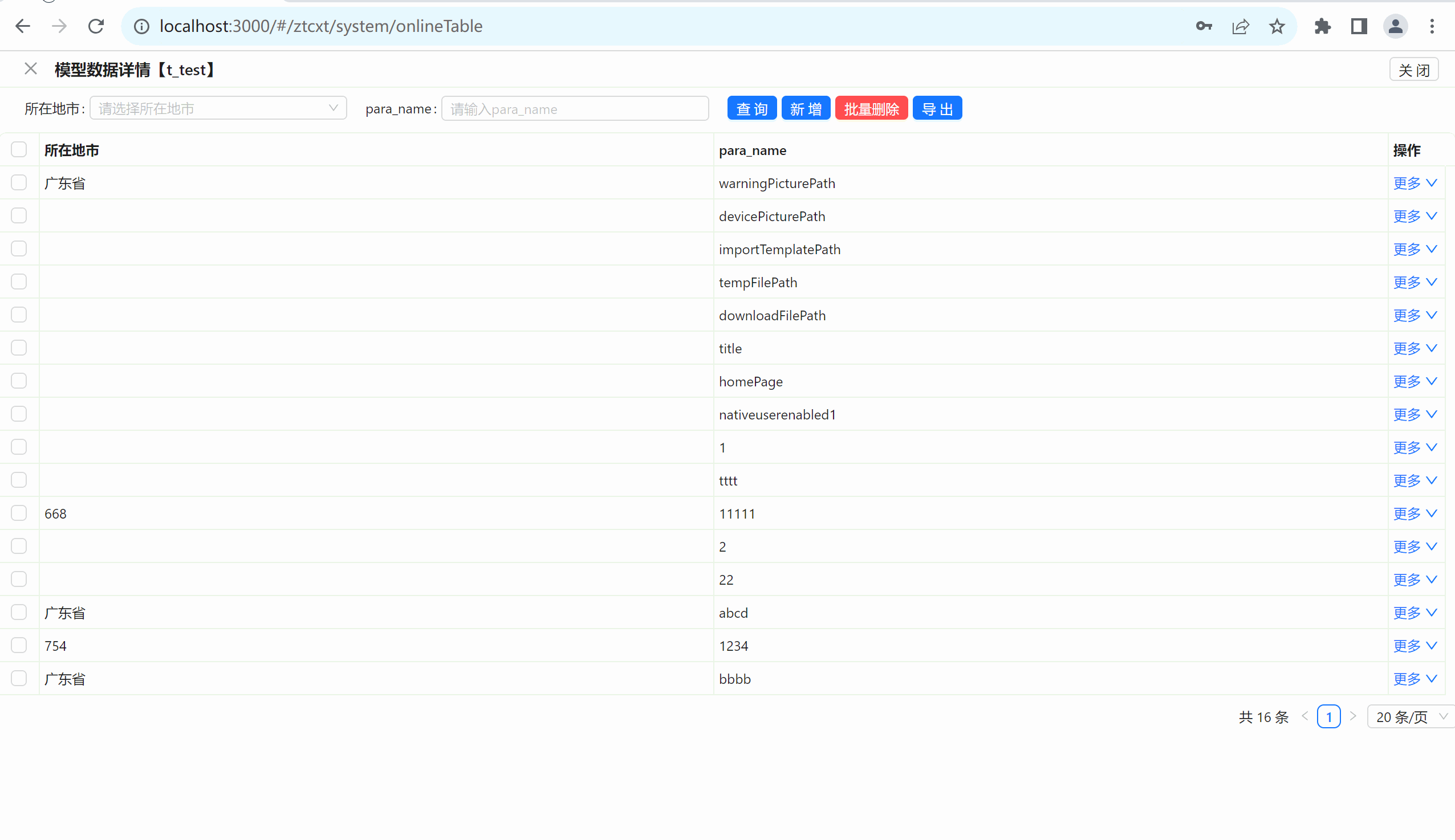
文章目录
- 一、理论知识
- 二、代码实现
- 2.1从零开始实现Dropout
- 【相关总结】
- np.random.uniform(low,high,size)
- astype
- torch.rand()
一、理论知识
1.动机
- 一个好的模型需要对输入数据的扰动鲁棒
- 使用有噪音的数据等价于Tikhonov正则
- 丢弃法:在层之间加入噪音
2.无偏差的加入噪音
- 对x加入噪音得到x’,我们希望

- 丢弃法对每个元素进行如下扰动


3.使用场景
- 通常将丢弃法作用在隐藏全连接层的输出上

4.推理中的丢弃法 - 正则项只在训练中使用:他们影响模型参数的更新
- 在推理过程中,丢弃法直接返回输出

总结: - 丢弃法将一些输出项随机置0来控制模型复杂度
- 常作用在多层感知机的隐藏层输出上
- 丢弃概率是控制模型复杂度的超参数
二、代码实现
2.1从零开始实现Dropout
import torch
from torch import nn
from d2l import torch as d2l
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
if dropout == 1:
# 全置0,即全丢弃
return torch.zeros_like(x)
if dropout == 0:
# 全保留
return X
# 掩码中的元素大于 dropout 的值时为 True,表示该元素丢弃;
mask = np.random.uniform(0, 1, X.shape) > dropout
# mask = (torch.randn(X.shape) > dropout).float()
# 进行归一化,保持期望不变
return mask.astype(np.float32) * X / (1.0 - dropout)
需要解释一下最后为什么需要进行归一化(即对保留的元素进行缩放)
在进行 Dropout 操作时,为了保持期望值不变,需要对被保留的神经元的输出进行归一化。Dropout 实际上是在训练期间按照一定概率随机将某些神经元的输出置零,这样可以防止模型过拟合。
假设在一个 Dropout 操作中,有一部分神经元被保留,而一部分被置零。那么为了保持期望值不变,就需要对被保留的神经元的输出进行归一化。这是因为在测试阶段,所有神经元都会参与预测,而在训练阶段,有一部分参与训练。如果在训练时不对被保留的神经元的输出进行归一化,那么在测试时整体的输出值就会偏大,因为所有神经元都要参与预测。具体而言,对于被保留的神经元,其输出值 X 会乘以一个缩放因子,即 1.0 / (1.0 -dropout)。这样,在训练阶段,因为有一部分神经元被置零,乘以缩放因子后可以保持整体期望值不变。在测试阶段,因为所有神经元都是活跃的,这个缩放因子就等于1,不影响整体输出。
所以,通过除以 (1.0 - dropout) 进行归一化,可以在 Dropout操作中保持整体期望值不变,确保在训练和测试阶段输出值的一致性。
训练时输出的期望是E(x)=[(1-p)x+p*0]/(1-p) = x
测试阶段的期望值等于模型的实际输出,X
【相关总结】
np.random.uniform(low,high,size)
生成服从[low,high)范围内的均匀分布的元素。
low:生成元素值的下界(默认为0)
high:生成元素值的上界(默认为1)
size:输出设置
import numpy as np
# 默认为[0,1)的均匀分布
arr = np.random.uniform()
print(arr)
# 指定low,high
arr = np.random.uniform(2, 8)
print(arr)
# 指定size
arr = np.random.uniform(2,8, (3,3))
print(arr)
0.8091521937664127
7.354698032780574
[[2.43782389 4.08495999 2.84664462]
[5.61473981 6.99573442 7.15074041]
[3.27288764 2.22821273 5.99610331]]
astype
转换数组数据类型
import numpy as np
# 创建一个整数数组
arr_int = np.array([1, 2, 3, 4, 5])
# 将整数数组转换为浮点数数组
arr_float = arr_int.astype(np.float32)
print(arr_float)
[1. 2. 3. 4. 5.]
# 创建一个布尔数组
arr_bool = np.array([True, False, True, False])
# 将布尔数组转换为整数数组
arr_int_from_bool = arr_bool.astype(np.int)
print(arr_int_from_bool)
[1 0 1 0]
torch.rand()
用于生成随机数,生成在区间 [0, 1) 内均匀分布的随机数,包括 0,但不包括 1。
import torch
# 生成一个包含随机数的张量,形状为 (3, 4)
random_tensor = torch.rand(3, 4)
print(random_tensor)
tensor([[0.2901, 0.8945, 0.7689, 0.5298],
[0.6336, 0.8918, 0.8178, 0.8453],
[0.0051, 0.8169, 0.1454, 0.9368]])
如果需要生成在其他区间的随机数,可以通过适当的缩放和平移来实现。例如,如果要生成在区间 [a, b) 内均匀分布的随机数,可以使用:
tensor([[3.1698, 2.7084, 2.2045, 4.5003],
[3.1167, 4.5860, 3.7704, 4.0340],
[3.1466, 2.3846, 4.7165, 4.7822]])