1.常用函数介绍
0 设备准备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
这行代码是用来选择设备的,根据是否有可用的 CUDA 设备来选择使用 GPU 还是 CPU 进行计算。
更详细的解释如下:
-
torch.cuda.is_available():这个函数用来检查是否有可用的 CUDA 设备。如果返回True,表示有可用的 CUDA 设备;如果返回False,表示没有可用的 CUDA 设备。 -
"cuda:0"和"cpu":这是设备的标识符。"cuda:0"表示选择第一个可用的 CUDA 设备,而"cpu"表示选择 CPU 设备。 -
torch.device():这是一个用来表示设备的类。通过传入设备标识符,可以创建一个设备对象。 -
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu"):这行代码使用了条件语句,如果有可用的 CUDA 设备,则选择"cuda:0",否则选择"cpu"。然后将选择的设备赋值给device变量。
这行代码的作用是根据是否有可用的 CUDA 设备来选择使用 GPU 还是 CPU 进行计算。在后续的代码中,可以使用 device 变量来指定模型和张量所在的设备,以便进行相应的计算。例如:
model = YourModel().to(device)
input_tensor = input_tensor.to(device)
这样就可以将模型和输入数据都移动到指定的设备上进行计算。如果有可用的 CUDA 设备,计算将在 GPU 上进行;如果没有可用的 CUDA 设备,计算将在 CPU 上进行。
1.1 数据集
1.1.1数据集对象创建
在PyTorch中,数据集对象通常继承自torch.utils.data.Dataset类。创建数据集对象时,需要重写__len__()和__getitem__()方法。下面是一个创建自定义数据集对象的示例:
import torch
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, index):
x = self.data[index][0]
y = self.data[index][1]
return x, y
#测试用例
data = [(torch.randn(10), torch.randint(0, 2, (1,))) for _ in range(100)]
dataset = MyDataset(data)
在这个例子中,我们创建了一个名为MyDataset的自定义数据集类,它继承自torch.utils.data.Dataset类。
- 在
__init__()方法中,我们接收一个数据列表data,并将其存储在类属性self.data中。 __len__()方法返回数据集的长度,即len(self.data)。__getitem__()方法根据索引index返回数据集中的一个样本。
在这个例子中,我们假设每个样本由一个特征向量和一个标签组成,所以我们从数据列表中取出特征向量和标签,并将其作为返回值。我们创建了一个包含100个样本的数据集,每个样本由一个10维的特征向量和一个0到1之间的二进制标签组成。然后,我们将这个数据集传递给MyDataset类,创建一个数据集对象。
1.1.2 数据集划分
在 PyTorch 中,可以使用 torch.utils.data.random_split() 函数来随机划分数据集。
下面是一个示例代码,展示了如何使用 random_split() 函数随机划分数据集:
from torch.utils.data import random_split
# 创建一个数据集对象
dataset = ...
# 计算数据集的大小
dataset_size = len(dataset)
# 计算训练集和验证集的大小
train_size = int(0.8 * dataset_size)
val_size = dataset_size - train_size
# 使用 random_split() 函数随机划分数据集
train_dataset, val_dataset = random_split(dataset, [train_size, val_size])
在这个例子中,我们首先创建了一个数据集对象 dataset。然后,我们计算了数据集的大小 dataset_size。接下来,我们计算了训练集和验证集的大小,并将它们分别设置为 train_size 和 val_size。最后,我们使用 random_split() 函数将数据集随机划分为训练集和验证集,并将它们分别存储在 train_dataset 和 val_dataset 变量中。
需要注意的是,random_split() 函数会打乱数据集的顺序。因此,划分的训练集和验证集的顺序是随机的。
1.1.3 数据集加载器
在PyTorch中,可以使用torch.utils.data.DataLoader类加载数据集。下面是一个使用DataLoader加载自定义数据集的示例:
# 创建数据加载器
dataloader = DataLoader(dataset, batch_size=10, shuffle=True)
# 使用数据加载器
for batch_idx, (inputs, targets) in enumerate(dataloader):
print(f"Batch {batch_idx}:")
print(f" Inputs: {inputs.shape}")
print(f" Targets: {targets.shape}")
使用torch.utils.data.DataLoader类将其转换为数据加载器dataloader。DataLoader类需要两个参数:数据集对象dataset和批次大小batch_size。shuffle参数设置为True,表示在训练过程中对数据进行随机打乱。
最后,我们使用for循环遍历数据加载器,并每次从数据加载器中获取一个批次的数据,将其存储在inputs和targets变量中。我们可以使用print()函数输出每个批次的数据形状。在这个例子中,我们假设每个批次的大小为10,并且每个样本的特征向量大小为10,新的二进制标签大小为1。
1.2卷积网络结构
1.2.1 参数配置
-
torch.nn.Linear:
- 用法:
torch.nn.Linear(in_features, out_features, bias=True) - 参数:
- in_features:输入特征的大小。
- out_features:输出特征的大小。
- bias:是否使用偏置项,默认为True。
- 用途:线性层用于进行线性变换,将输入特征映射到输出特征空间。
- 用法:
-
torch.nn.Conv2d:
- 用法:
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, bias=True) - 参数:
- in_channels:输入通道数。
- out_channels:输出通道数。
- kernel_size:卷积核的大小。
- stride:卷积步长,默认为1。
- padding:填充大小,默认为0。
- bias:是否使用偏置项,默认为True。
- 用途:二维卷积层用于处理二维输入数据,例如图像。
- 用法:
-
torch.nn.ConvTranspose2d:
- 用法:
torch.nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, bias=True) - 参数:
- in_channels:输入通道数。
- out_channels:输出通道数。
- kernel_size:卷积核的大小。
- stride:卷积步长,默认为1。
- padding:填充大小,默认为0。
- output_padding:输出填充大小,默认为0。
- bias:是否使用偏置项,默认为True。
- 用途:二维转置卷积层用于将低维特征图转换为高维特征图,常用于图像生成任务或图像分割任务。
- 用法:
-
torch.nn.MaxPool2d:
- 用法:
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False) - 参数:
- kernel_size:池化窗口的大小。
- stride:池化步长,默认为None,表示与kernel_size相同。
- padding:填充大小,默认为0。
- dilation:扩张率,默认为1。
- return_indices:是否返回池化操作的索引,默认为False。
- ceil_mode:是否使用向上取整的方式计算输出大小,默认为False。
- 用途:二维最大池化层用于减小特征图的空间尺寸,并保留最显著的特征。
- 用法:
-
torch.nn.AvgPool2d:
- 用法:
torch.nn.AvgPool2d(kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True, divisor_override=None) - 参数:
- kernel_size:池化窗口的大小。
- stride:池化步长,默认为None,表示与kernel_size相同。
- padding:填充大小,默认为0。
- ceil_mode:是否使用向上取整的方式计算输出大小,默认为False。
- count_include_pad:是否将填充值包含在计算中,默认为True。
- divisor_override:覆盖除数的值,默认为None。
- 用途:二维平均池化层用于减小特征图的空间尺寸,并对每个池化窗口内的特征进行平均。
- 用法:
-
torch.nn.BatchNorm2d:
- 用法:
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) - 参数:
- num_features:输入特征的通道数。
- eps:数值稳定性参数,默认为1e-05。
- momentum:动量参数,用于计算移动平均和方差,默认为0.1。
- affine:是否使用可学习的缩放和偏移参数,默认为True。
- track_running_stats:是否跟踪运行时的统计信息,默认为True。
- 用途:二维批归一化层用于加速神经网络的训练过程和提高模型的泛化能力,对每个通道的特征进行归一化,并通过学习可调参数来进一步调整特征的均值和方差。
- 用法:
-
torch.nn.ReLU:
- 用法:
torch.nn.ReLU(inplace=False) - 参数:
- inplace:是否进行原地操作,默认为False。
- 用途:ReLU激活函数用于引入非线性性,将负值置为零。
- 用法:
-
torch.nn.Dropout:
- 用法:
torch.nn.Dropout(p=0.5, inplace=False) - 参数:
- p:丢弃概率,默认为0.5。
- inplace:是否进行原地操作,默认为False。
- 用途:随机失活层用于在训练过程中随机丢弃一部分神经元,以减少过拟合。
- 用法:
1.2.2代码实例
- torch.nn.Linear:
import torch
import torch.nn as nn
# 创建一个线性层,输入特征大小为10,输出特征大小为5
linear_layer = nn.Linear(10, 5)
# 创建一个随机输入张量
input_tensor = torch.randn(3, 10)
# 将输入张量传递给线性层进行线性变换
output = linear_layer(input_tensor)
print(output.shape) # 输出: torch.Size([3, 5])
- torch.nn.Conv2d:
import torch
import torch.nn as nn
# 创建一个二维卷积层,输入通道数为3,输出通道数为16,卷积核大小为3x3
conv_layer = nn.Conv2d(3, 16, kernel_size=3)
# 创建一个随机输入张量,大小为(batch_size, channels, height, width)
input_tensor = torch.randn(4, 3, 32, 32)
# 将输入张量传递给卷积层进行卷积操作
output = conv_layer(input_tensor)
print(output.shape) # 输出: torch.Size([4, 16, 30, 30])
- torch.nn.ConvTranspose2d:
import torch
import torch.nn as nn
# 创建一个二维转置卷积层,输入通道数为16,输出通道数为8,卷积核大小为4x4
conv_transpose_layer = nn.ConvTranspose2d(16, 8, kernel_size=4)
# 创建一个随机输入张量,大小为(batch_size, channels, height, width)
input_tensor = torch.randn(4, 16, 14, 14)
# 将输入张量传递给转置卷积层进行转置卷积操作
output = conv_transpose_layer(input_tensor)
print(output.shape) # 输出: torch.Size([4, 8, 17, 17])
- torch.nn.MaxPool2d:
import torch
import torch.nn as nn
# 创建一个二维最大池化层,池化窗口大小为2x2
maxpool_layer = nn.MaxPool2d(kernel_size=2)
# 创建一个随机输入张量,大小为(batch_size, channels, height, width)
input_tensor = torch.randn(4, 3, 32, 32)
# 将输入张量传递给最大池化层进行池化操作
output = maxpool_layer(input_tensor)
print(output.shape) # 输出: torch.Size([4, 3, 16, 16])
- torch.nn.AvgPool2d:
import torch
import torch.nn as nn
# 创建一个二维平均池化层,池化窗口大小为2x2
avgpool_layer = nn.AvgPool2d(kernel_size=2)
# 创建一个随机输入张量,大小为(batch_size, channels, height, width)
input_tensor = torch.randn(4, 3, 32, 32)
# 将输入张量传递给平均池化层进行池化操作
output = avgpool_layer(input_tensor)
print(output.shape) # 输出: torch.Size([4, 3, 16, 16])
- torch.nn.BatchNorm2d:
import torch
import torch.nn as nn
# 创建一个二维批归一化层,输入特征通道数为3
batchnorm_layer = nn.BatchNorm2d(3)
# 创建一个随机输入张量,大小为(batch_size, channels, height, width)
input_tensor = torch.randn(4, 3, 32, 32)
# 将输入张量传递给批归一化层进行归一化操作
output = batchnorm_layer(input_tensor)
print(output.shape) # 输出: torch.Size([4, 3, 32, 32])
- torch.nn.ReLU:
import torch
import torch.nn as nn
# 创建一个ReLU激活函数
relu = nn.ReLU()
# 创建一个随机输入张量
input_tensor = torch.randn(3, 5)
# 将输入张量传递给ReLU激活函数进行非线性变换
output = relu(input_tensor)
print(output)
- torch.nn.Dropout:
import torch
import torch.nn as nn
# 创建一个随机失活层,丢弃概率为0.5
dropout_layer = nn.Dropout(p=0.5)
# 创建一个随机输入张量
input_tensor = torch.randn(3, 5)
# 将输入张量传递给随机失活层进行随机丢弃
output = dropout_layer(input_tensor)
print(output)
1.2.3 动手实践
#搭建神经网络
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = nn.Conv2d(1,6,5)
self.conv2 = nn.Conv2d(6,16,5)
self.fc1 = nn.Linear(16*8*8,120)
self.fc2 = nn.Linear(120,84)
def forward(self,x):
input_size=x.size(0)
x=self.conv1(x)
#print(x.size())
x=F.relu(x)
x=F.max_pool2d(x,2)
x=self.conv2(x)
#print(x.size())
x=F.relu(x)
x=x.view(input_size,-1)
x=self.fc1(x)
#print(x.size())
x=F.relu(x)
x=self.fc2(x)
return F.log_softmax(x,dim=1)
1.3训练迭代
使用优化器进行模型训练时,可以根据需要选择不同的优化器算法和设置不同的参数。
-
创建优化器对象:
optimizer = torch.optim.Optimizer(model.parameters(), lr=learning_rate)这里的
model.parameters()是指模型的可学习参数,lr是学习率(learning rate)。除了学习率,还可以设置其他参数,如权重衰减(weight decay)、动量(momentum)等。 -
在每个训练迭代中进行以下步骤:
- 清零梯度:
optimizer.zero_grad() - 前向传播:计算模型的输出
- 计算损失:根据模型输出和目标值计算损失函数的值
- 反向传播:计算梯度,使用
loss.backward()方法 - 更新参数:调用
optimizer.step()方法来更新模型的参数
- 清零梯度:
-
设置不同的优化器参数:
- 学习率调整:可以使用
optimizer.param_groups获取优化器的参数组,并对每个参数组设置不同的学习率。 - 权重衰减:可以通过设置
weight_decay参数来应用 L2 正则化,以减小模型参数的大小。 - 动量:对于带有动量的优化器(如 SGD、Adam),可以设置
momentum参数来控制动量的大小。
- 学习率调整:可以使用
下面是一个更详细的示例代码片段,展示了优化器的用法:
import torch
import torch.nn as nn
import torch.optim as optim
# 创建模型实例(这里是你创建的模型)
model = YourModel()
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=0.001, momentum=0.9)
# 在每个训练迭代中进行以下步骤:
for inputs, labels in dataloader:
# 清零梯度
optimizer.zero_grad()
# 前向传播
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
1.4模型评估
model.eval() 是一个模型方法,用于将模型设置为评估模式。在评估模式下,模型会禁用一些特定的操作,如 Dropout 层和批归一化层的随机性,以确保输出的一致性和可重复性。
更详细的用法如下:
-
设置模型为评估模式:
model.eval()这将把模型设置为评估模式,禁用一些随机性操作。
-
在评估模式下进行推断或评估:
with torch.no_grad(): # 进行推断或评估操作 output = model(input_tensor)在评估模式下,通常会使用
torch.no_grad()上下文管理器来禁用梯度计算,以提高推断或评估的效率。
下面是一个更详细的示例代码片段,展示了 model.eval() 的用法:
import torch
import torch.nn as nn
model.eval()
correct=0
with torch.no_grad():
for data,target in dataloader:
output = model(data)
pred = output.argmax(dim=1,keepdim=True)
correct+=pred.eq(target.view_as(pred)).sum().item()
return correct/len(dataloader.dataset)
在上述示例中,首先创建了模型实例,然后使用 model.eval() 将模型设置为评估模式。接下来,加载了预训练模型参数,并在评估模式下进行推断或评估操作。使用 torch.no_grad() 上下文管理器来禁用梯度计算,以提高推断或评估的效率。
请注意,model.eval() 方法只是将模型设置为评估模式,并不会自动执行推断或评估操作。你需要根据具体的需求编写相应的代码来进行推断或评估。
1.5 保存模型
保存模型是在训练完成后将模型的参数保存到磁盘上,以便后续加载和使用。以下是保存模型的一般步骤:
-
定义模型:
model = YourModel() -
训练模型:
# 训练过程... -
保存模型参数:
torch.save(model.state_dict(), 'model.pth')上述代码将模型的参数保存到名为
'model.pth'的文件中。model.state_dict()返回一个包含模型参数的字典,torch.save()函数将该字典保存到文件中。
完整的示例代码如下:
import torch
import torch.nn as nn
# 定义模型
model = YourModel()
# 训练模型
# ...
# 保存模型参数
torch.save(model.state_dict(), 'model.pth')
保存模型参数后,你可以使用 torch.load() 函数加载模型参数,并将其应用于新的模型实例中:
import torch
import torch.nn as nn
# 定义模型
model = YourModel()
# 加载模型参数
model.load_state_dict(torch.load('CNN.pth'))
通过加载模型参数,你可以恢复之前训练好的模型,并在后续的推断或评估中使用它。
2.在MNIST数据集实验
2.1 结果
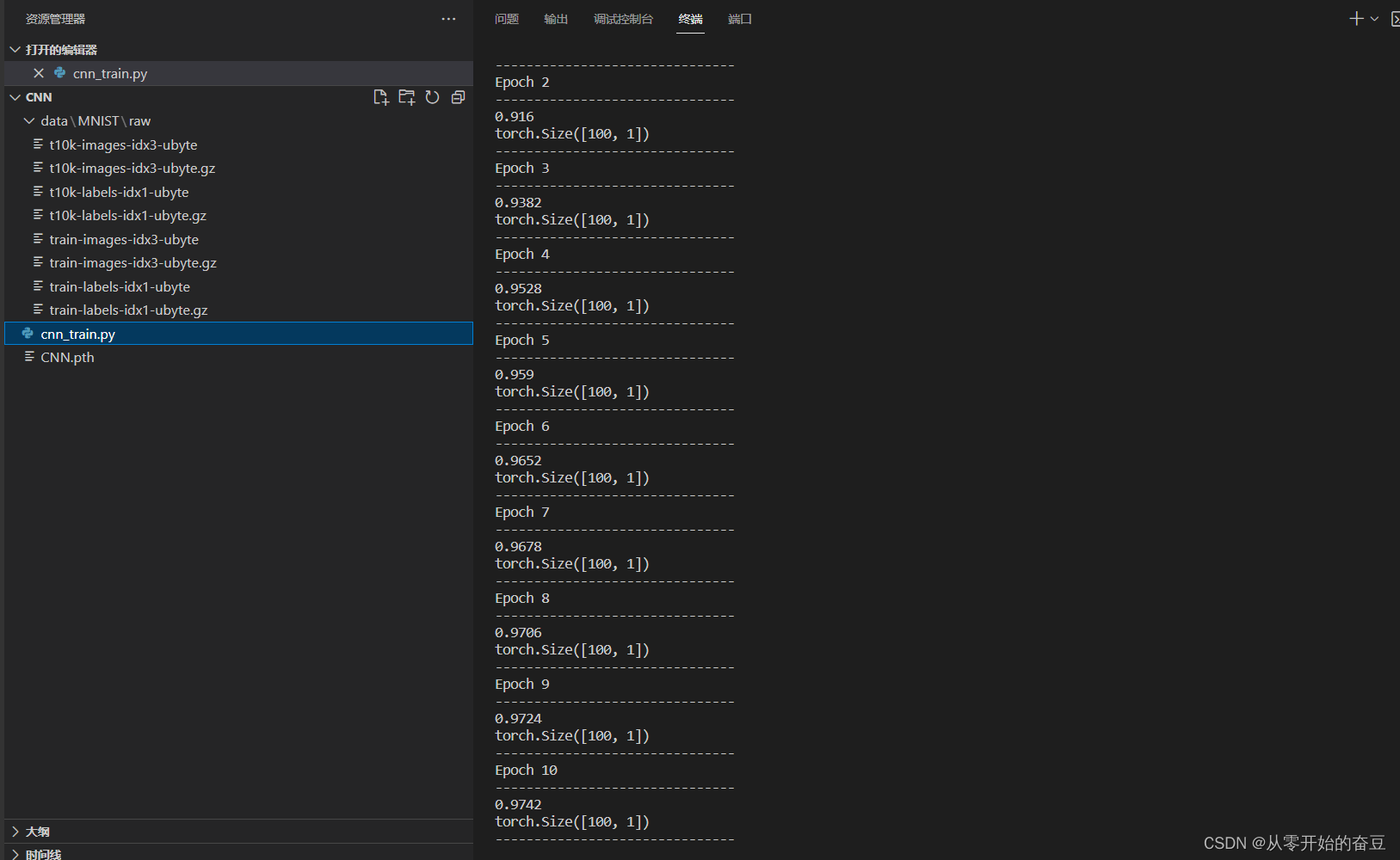
数据如图所示

训练得到,保存模型:
调用预测:

调用保存的模型:

2.2总代码
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
import torchvision.transforms as transforms
import torchvision
import torch.nn.functional as F
from torch import nn, optim
import torch
from torch.utils.data import Dataset
import numpy as np
""" class MyDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, index):
x = self.data[index][0]
y = self.data[index][1]
return x, y
data = [(torch.randn(10), torch.randint(0, 2, (1,))) for _ in range(100)]
print(data)
dataset = MyDataset(data)
print(dataset)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True)"""
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
# 指定数据集的根目录
root = './data'
# 定义数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 加载MNIST数据集
mnist_dataset = torchvision.datasets.MNIST(
root=root,
train=True,
transform=transform,
download=True
)
print(len(mnist_dataset))
#划分数据集
train_dataset, val_dataset = torch.utils.data.random_split(mnist_dataset, [55000, 5000])
# 创建数据加载器
mnist_train_dataloader = DataLoader(
dataset=train_dataset,
batch_size=100,
shuffle=False,
)
mnist_val_dataloader = DataLoader(
dataset=val_dataset,
batch_size=100,
shuffle=False,
)
#搭建神经网络
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = nn.Conv2d(1,6,5)
self.conv2 = nn.Conv2d(6,16,5)
self.fc1 = nn.Linear(16*8*8,120)
self.fc2 = nn.Linear(120,84)
def forward(self,x):
input_size=x.size(0)
x=self.conv1(x)
#print(x.size())
x=F.relu(x)
x=F.max_pool2d(x,2)
x=self.conv2(x)
#print(x.size())
x=F.relu(x)
x=x.view(input_size,-1)
x=self.fc1(x)
#print(x.size())
x=F.relu(x)
x=self.fc2(x)
return F.log_softmax(x,dim=1)
#训练
def train(epoch_idx,model,dataloader,optimizer):
model.train()
for batch_idx, (data,target) in enumerate(dataloader):
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output,target)
loss.backward()
optimizer.step()
#预测结果
def test(model,dataloader):
model.eval()
correct=0
with torch.no_grad():
for data,target in dataloader:
output = model(data)
pred = output.argmax(dim=1,keepdim=True)
correct+=pred.eq(target.view_as(pred)).sum().item()
return correct/len(dataloader.dataset),pred
network = Net().to(device)
""" n_epochs = 10
learning_rate=0.01
optimizer = optim.SGD(network.parameters(), lr=learning_rate)
for i in range(1,n_epochs+1):
print(f"Epoch {i}\n-------------------------------")
train(epoch_idx = i, model = network,dataloader = mnist_train_dataloader, optimizer = optimizer)
accuray,result=test(model = network,dataloader = mnist_val_dataloader)
print(accuray)
print(result.shape)
print("-------------------------------")
torch.save(network.state_dict(), 'CNN.pth') """
network.load_state_dict(torch.load('CNN.pth'))
accuray,result=test(model = network,dataloader = mnist_val_dataloader)
data_loader_iter = iter(mnist_val_dataloader)
while True:
try:
item = next(data_loader_iter)
# 对 item 进行处理
image, label = item
except StopIteration:
break
images=image.numpy()
labels=label.numpy()
fig = plt.figure(figsize=(25,4))
for idx in np.arange(20):
ax = fig.add_subplot(2,10, idx+1, xticks=[], yticks=[])
ax.imshow(images[idx][0], cmap='gray')
ax.set_title('real:'+str(labels[idx].item())+'ped:'+str(result[idx].item()))
plt.show()