Paraformer(Parallel Transformer)非自回归端到端语音系统需要解决两个问题:
- 准确预测输出序列长度,送入预测语音信号判断包含多少文字。 如何从encoder 的输出中提取隐层表征,作为decoder的输入。
采用一个预测器(Predictor)来预测文字个数并通过Continuous integrate-and-fire (CIF)机制来抽取文字对应的声学隐变量
- 如何增强非自回归预测内部依赖的建模能力。
基于GLM的 Sampler模块来增强模型对上下文语义的建模
Paraformerr的组成:Encoder(编码器),Predictor(预测器),Sampler(采样器),Decoder(解码器),loss function。
- Encoder(编码器),把声学特征转变成固定维度的稠密向量.
- Predictor(预测器),预测文字个数 N ′ N^{'} N′,实现语音和文本对齐,并通过Continuous integrate-and-fire (CIF)机制来抽取文字对应的声学隐变量 E a E_a Ea。
- Sampler(采样器),通过采样,将声学特征向量与目标文字向量变换成含有语义信息的特征向量,配合双向的Decoder来增强模型对于上下文的建模能力;采用Glangcing LM增强非自回归的上下文建模能力.
- Decoder(解码器),把向量转变成目标文字
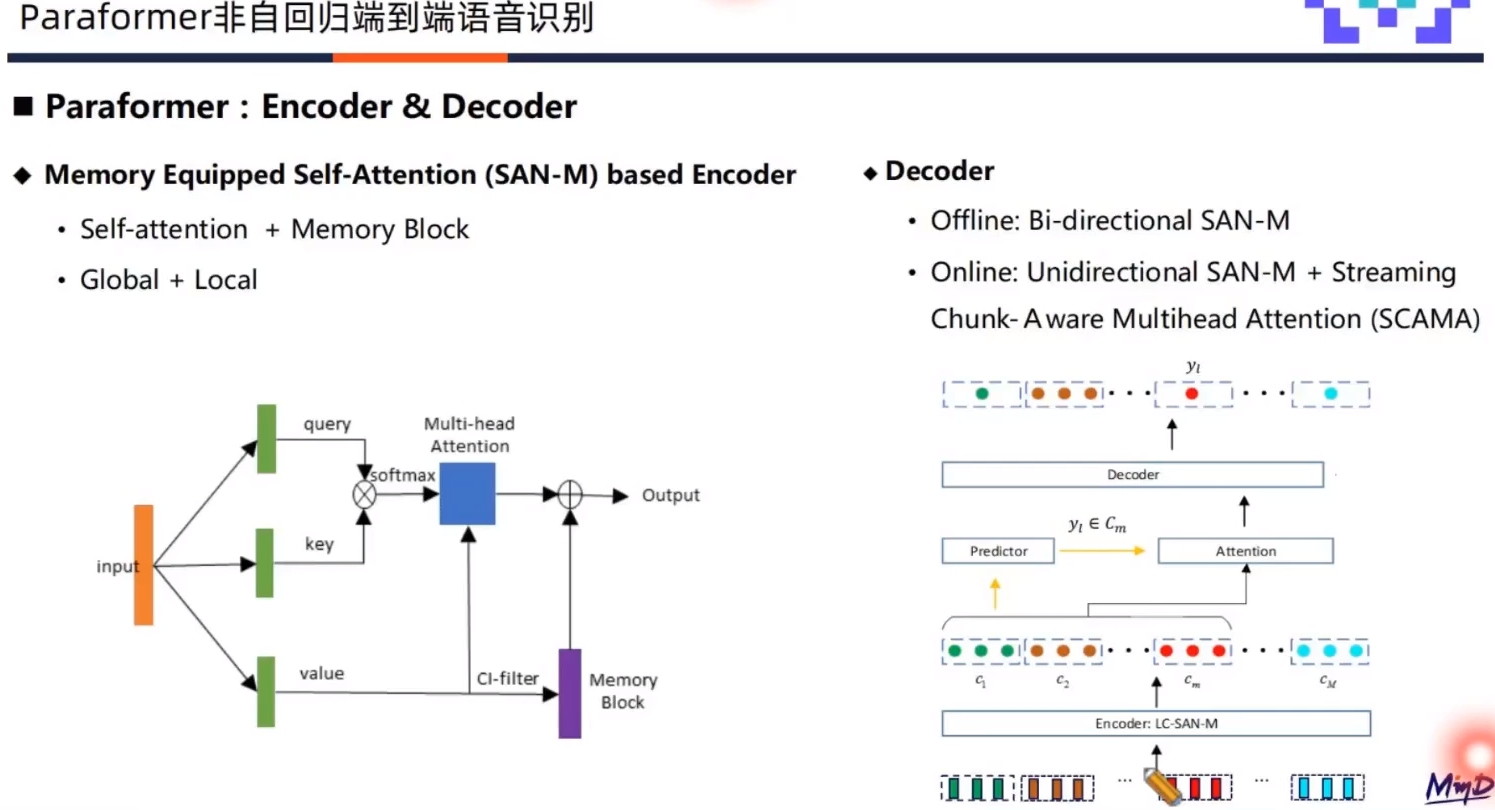
Encoder
采用SAN-M结构,对于语音建模来说,全局建模和局部建模都极为关键,所以标准的Self-attention层增加了局部建模模块Memory Block,从而增加Self-attention的局部建模能力。
Decoder
离线和流式系统采用不同结构。离线识别使用双向SAN-M,流式识别采用单向的SAN-M,并结合基于SCAMA的流式注意力机制来实现。SCAMA流式注意力机制原理如上图所示,首先针对语音特征进行分chunk操作,送入encoder建模后进入predictor分别预测每个chunk的输出token数目。Decoder在接受到token数目和隐层表征后,来基于SCAMA流式注意力机制预测每个chunk的输出。
Predictor
基于CIF来预测输出token的数目,并提取隐层表征
E
a
E_a
Ea作为decoder的输入。即将encoder预测输出送入函数,将每帧的预测输出转化为一个0-1之间的概率分布,连续给集合的概率得到一个域限门值 β,根据 β 输出一个token。
Continuous Integrate-and-Fire(CIF)来产生声学embedding
E
a
E_a
Ea。CIF是软单调对齐,被用来做流式语音识别。CIF累积权重
α
\alpha
α并整合隐藏表示H,直到累积的权重达到给定阈值β,这表明已经达到了声学边界.在训练过程中,将权值α按目标长度进行缩放,在训练过程中,将权值α按目标长度进行缩放,使声学嵌入的数量
E
a
E_a
Ea与目标嵌入的数量
E
c
E_c
Ec相匹配,并直接使用权值
α
\alpha
α产生
E
a
E_a
Ea进行推理。因此,在训练和推理之间可能存在不匹配,导致预测器的精度下降。由于NAR模型比流模型对预测器精度更敏感,我们建议使用动态阈值β代替预定义阈值来减少不匹配。动态阈值机制表述为:
β
=
Σ
t
=
1
T
α
t
⌈
Σ
t
=
1
T
α
t
⌉
\beta=\frac{\Sigma_{t=1}^T\alpha_t}{\lceil \Sigma_{t=1}^T\alpha_t\rceil}
β=⌈Σt=1Tαt⌉Σt=1Tαt
训练的时候额外采用平均绝对就差MAE Loss来使得预测的概率和等于整个输出的token数目。推理的时候采用门限值 β 为1,也就是累积到1的时候输出一个token,来预测整条语音的输出字数。
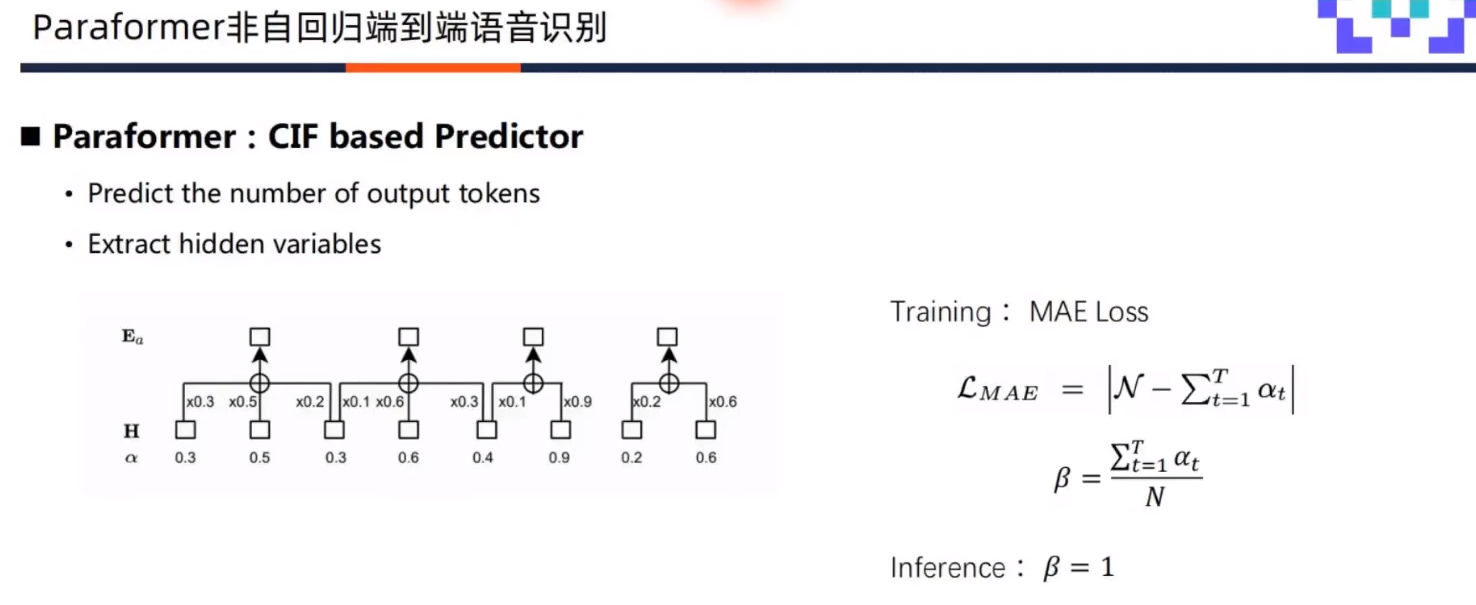
举例如下图,
α
\alpha
α从左到右,0.3+0.5+0.3=1.1>1,于是fire一个token。
E
α
1
=
0.3
∗
H
1
+
0.5
∗
H
2
+
0.2
∗
h
3
E_{\alpha 1}=0.3*H1+0.5*H2+0.2*h3
Eα1=0.3∗H1+0.5∗H2+0.2∗h3。由于还剩0.1的值没有用,于是0.1用于下一个token计算。同理,
E
α
2
=
0.1
∗
H
3
+
0.6
∗
H
4
+
0.3
∗
H
5
E_{\alpha 2}=0.1*H3+0.6*H4+0.3*H5
Eα2=0.1∗H3+0.6∗H4+0.3∗H5,
E
α
3
=
0.1
∗
H
5
+
0.9
∗
H
6
E_{\alpha 3}=0.1*H5+0.9*H6
Eα3=0.1∗H5+0.9∗H6。
E
α
4
=
0.2
∗
H
7
+
0.6
∗
H
8
E_{\alpha 4} =0.2*H7+0.6*H8
Eα4=0.2∗H7+0.6∗H8. 共fire了4次,也就是4个
E
α
E_\alpha
Eα
。
Sampler
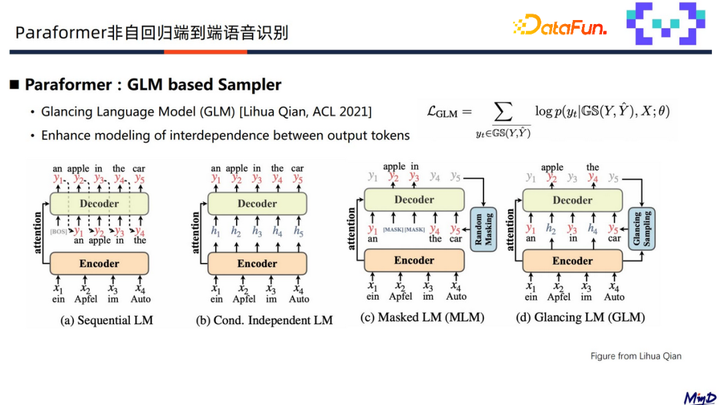
上图中展示了四种常见的建模方式:
第一个是自回归Decoder,即当前时刻依赖前一时刻的输出;
第二个是标准的单轮迭代的非自回归端到端Decoder,使用独立建模方式;
第三个是 MLM,它是多轮迭代非自回归常采用的方式,将某些时刻替换成mask,利用周边的token预测mask的位置,并通过多轮迭代的方式提升预测精度。
第四个是Paraformer采用的建模方式,通过GLM浏览语言模型对隐层表征和grand truth的label进行采样,预测隐层表征对应输出的token来提升token的内部建模能力,从而减少Paraformer中的替换错误。
假设输入
(
X
,
Y
)
(X,Y)
(X,Y),
X
X
X表示语音,有
T
T
T帧,
Y
Y
Y表示文字,有
N
N
N个文字。Encoder把输入
X
X
X映射到隐藏表示
H
H
H。 然后Predictor把隐藏表示映射为预测的文字个数
N
′
N^{'}
N′和对应的声学向量embedding
E
a
E_a
Ea。输入
E
a
E_a
Ea和
H
H
H给Decoder,产生最后的预测
Y
′
Y^{'}
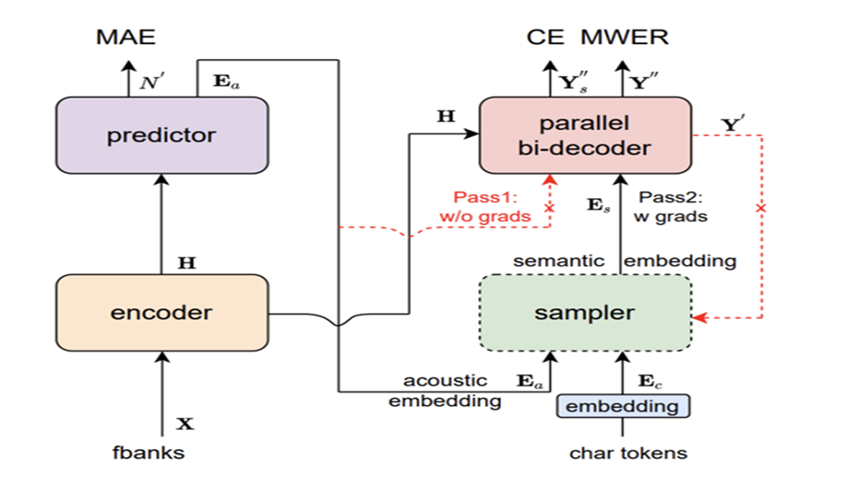
Y′,这是第一次解码,主要为了得到预测的结果并通过Sampler模块来采样,这时梯度并不回传(其实代码里是可选择的)。Sampler 采样
E
a
E_a
Ea和目标
E
c
E_c
Ec来产生
E
s
E_s
Es,需要依据
Y
′
Y^{'}
Y′和
Y
Y
Y之间的距离。Decoder最后使用
E
s
E_s
Es和
H
H
H来预测最终的结果
Y
′
′
Y^{''}
Y′′,这时才会回传梯度。最后,
Y
′
′
Y^{''}
Y′′用来采样负例并计算MWER, 通过目标长度N和预测的
N
′
N^{'}
N′来计算MAE。
最后,
Y
′
′
Y^{''}
Y′′ 用来采样负例并计算MWER, 通过目标长度N和预测的
N
′
N^{'}
N′来计算MAE(平均绝对误差)。MWER(最小化词错误率)和MAE通过CE(交叉熵)联合训练。
推断时,Sampler模块可以去掉,只使用 E a E_a Ea和 H H H来预测 Y ′ Y^{'} Y′。
loss
基于负样本采样的MWER训练准则。
https://zhuanlan.zhihu.com/p/649558283
https://zhuanlan.zhihu.com/p/637849790
https://arxiv.org/abs/2206.08317