The Elastic Stack, 包括 Elasticsearch【搜索,分析】、 Kibana【可视化】、 Beats 和 Logstash【数据的搜集】(也称为 ELK Stack)。能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。
Elaticsearch,简称为 ES, ES 是一个开源的高扩展的分布式全文搜索引擎, 是整个 ElasticStack 技术栈的核心。
它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。
文章目录
目录
文章目录
前言
一、倒排索引
二、es的安装
三、ES中常见的概念
四、ES常用API接口
4.1查询匹配
4.2多条件查询
4.3匹配数组
4.4精确匹配
五、ik分词器
六、spring boot整合es
总结
前言
使用场景
国外:
-
维基百科,类似百度百科,“网络七层协议”的维基百科,全文检索,高亮,搜索推荐
-
Stack Overflow(国外的程序讨论论坛),相当于程序员的贴吧。遇到it问题去上面发帖,热心网友下面回帖解答。
-
GitHub(开源代码管理),搜索上千亿行代码。
-
电商网站,检索商品
-
日志数据分析,logstash采集日志,ES进行复杂的数据分析(ELK技术,elasticsearch+logstash+kibana)
-
商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订阅《java编程思想》的监控,如果价格低于27块钱,就通知我,我就去买。
-
BI系统,商业智能(Business Intelligence)。大型连锁超市,分析全国网点传回的数据,分析各个商品在什么季节的销售量最好、利润最高。成本管理,店面租金、员工工资、负债等信息进行分析。从而部署下一个阶段的战略目标。
国内:
-
百度搜索,第一次查询,使用es。
-
OA、ERP系统站内搜索。
一、倒排索引
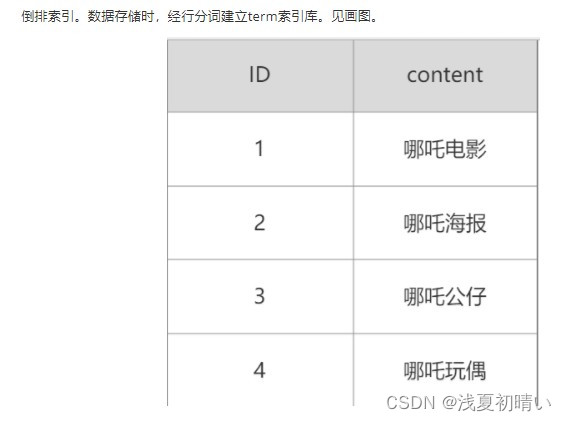
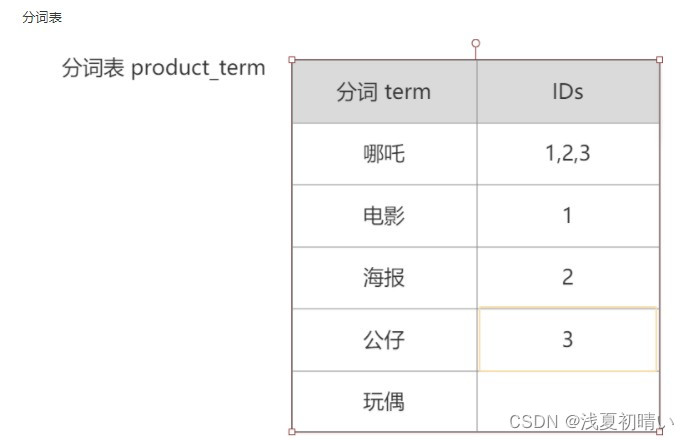
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。
二、es的安装
需要电脑有jdk环境
1.下载安装包并解压
下载地址:下载 Elastic 产品 | Elastic/
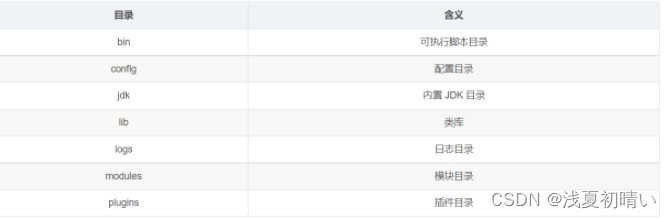
解压后,进入 bin 文件目录,点击 elasticsearch.bat 文件启动 ES 服务 。
注意: 9300 端口为 Elasticsearch 集群间组件的通信端口, 9200 端口为浏览器访问的 http协议 RESTful 端口。
打开浏览器,输入地址: http://localhost:9200,测试返回结果
2.kibana是es数据的前端展现,数据分析时,可以方便地看到数据。
历史版本下载:Past Releases of Elastic Stack Software | Elastic/
1、下载,解压kibana。
2、启动Kibana:bin\kibana.bat
3、浏览器访问 http://localhost:5601 进入Dev Tools界面。像plsql一样支持代码提示。
4、发送get请求,查看集群状态GET _cluster/health。相当于浏览器访问。
三、ES中常见的概念
集群
集群这一概念已经遍及天下了,在Elasticsearch中也不例外,可以将多台Elasticsearch节点组成集群使用,可以在任意一台节点上进行搜索。
节点
节点是一台Elasticsearch服务器,可以存储、查询、创建索引,也可以与其它节点一共组成一个集群。
索引---数据库
索引是具有某种相似特性的文档集合,熟悉mysql的应该不会对于这个名词陌生,Elasticsearch使用的是倒排索引。
文档---一条记录
一个文档是一个可以被索引的基础信息单元。
分片
单个索引包含数据太大的话,将会降低索引速度。为此,Elasticsearch提供了将索引细分成多个片段的能力,就是分片。
副本
副本是ElasticSearch索引分片的备份,主要应对与节点故障时保存数据的可用性。副本与它的原始分片不会在同一个节点上,以此来保存单节点故障时的高可用。
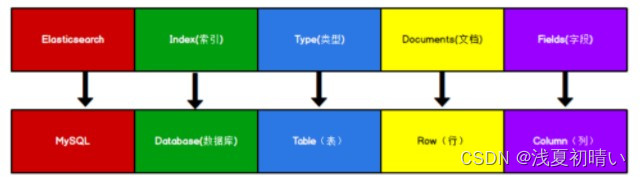
注意: ES6.0以后Type这个概念模糊了,7.0以后不在使用Type. 默认索引的type都是_doc
索引----数据库
类型---表
文档---一条记录
字段---列
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。 为了方便大家理解,我们将 Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比
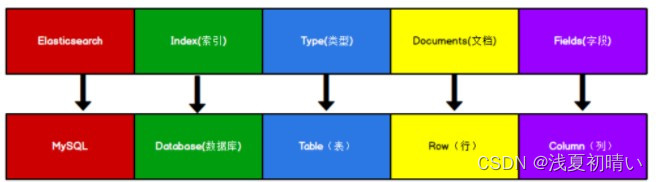
ES 里的 Index 可以看做一个库,而 Types 相当于表, Documents 则相当于表的行。这里 Types 的概念已经被逐渐弱化, Elasticsearch 6.X 中,一个 index 下已经只能包含一个type, Elasticsearch 7.X 中, Type 的概念已经被删除了。
四、ES常用API接口
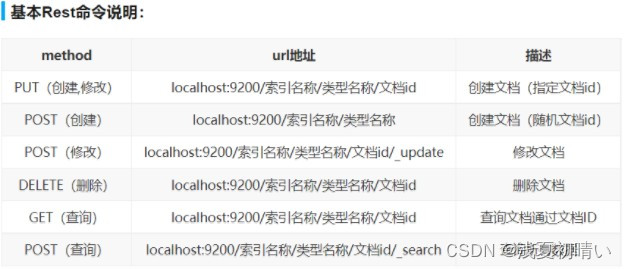
#查询所有
GET /qy158-index/_search
{
"query": {
"match_all": {
}
}
}
#创建索引
PUT /myindex
{
"mappings": {
"properties": {
"id":{"type": "integer"},
"name":{"type": "text"},
"age":{"type": "integer"}
}
}
}
#获取索引的结构
GET /qy158-index
#查询kibana里面所有的索引
GET /_cat/indices?v
#删除索引
DELETE /myindex
#添加文档
PUT /myindex/_doc/4
{
"name":"likeyou",
"age":11
}
#根据id查询文档
GET /qy158-index/_doc/6
#修改文档内容
POST /myindex/_doc/1/_update
{
"doc":{
"name":"修改为张三"
}
}
#删除1号文档文档
DELETE /qy158-index/_doc/1
#传递参数查询
GET /myindex/_search?q=name:修
#模糊查询 term精度匹配
GET /qy158-index/_search
{
"query": {
"match": {
"name": "张"
}
}
}
#范围匹配
GET /myindex/_search
{
"query": {
"range": {
"age": {
"gte":16
}
}
}
}
#排序
GET /myindex/_search
{
"query": {
"match": {
"name": "老"
}
},
"_source": ["name","age"],
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
#分页查询
GET /myindex/_search
{
"query": {
"match": {
"name": "老"
}
},
"from": 1,
"size": 1
}
#多条件查询
GET /myindex/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "老"
}
},
{
"match": {
"age": 11
}
}
]
}
}
}
#自定义高亮的前缀和后缀
GET /myindex/_search
{
"query": {
"match": {
"name": "老"
}
},
"highlight": {
"pre_tags": "<font color:'red'>",
"post_tags": "</font>",
"fields": {
"name": {}
}
}
}
GET _search
{
"query": {
"match_all": {}
}
}4.1查询匹配
-
match:匹配(会使用分词器解析(先分析文档,然后进行查询)) -
_source:过滤字段 -
sort:排序 -
form、size分页
// 查询匹配
GET /blog/user/_search
{
"query":{
"match":{
"name":"流"
}
}
,
"_source": ["name","desc"]
,
"sort": [
{
"age": {
"order": "asc"
}
}
]
,
"from": 0
,
"size": 1
}
4.2多条件查询
-
must相当于and -
should相当于or -
must_not相当于not (... and ...) -
filter过滤
/// bool 多条件查询
must <==> and
should <==> or
must_not <==> not (... and ...)
filter数据过滤
boost
minimum_should_match
GET /blog/user/_search
{
"query":{
"bool": {
"must": [
{
"match":{
"age":3
}
},
{
"match": {
"name": "流"
}
}
],
"filter": {
"range": {
"age": {
"gte": 1,
"lte": 3
}
}
}
}
}
}
4.3匹配数组
-
貌似不能与其它字段一起使用
-
可以多关键字查(空格隔开)— 匹配字段也是符合的
-
match会使用分词器解析(先分析文档,然后进行查询) -
搜词
// 匹配数组 貌似不能与其它字段一起使用
// 可以多关键字查(空格隔开)
// match 会使用分词器解析(先分析文档,然后进行查询)
GET /blog/user/_search
{
"query":{
"match":{
"desc":"年龄 牛 大"
}
}
}
4.4精确匹配
-
term直接通过 倒排索引 指定词条查询 -
适合查询 number、date、keyword ,不适合text
// 精确查询(必须全部都有,而且不可分,即按一个完整的词查询)
// term 直接通过 倒排索引 指定的词条 进行精确查找的
GET /blog/user/_search
{
"query":{
"term":{
"desc":"年 "
}
}
}
五、ik分词器
下载地址:Releases · medcl/elasticsearch-analysis-ik · GitHub
注意下载对应版本和es
需要解压到ElasticSearch的plugins目录ik文件夹下
重新启动es 就能加载插件了
text和keyword
text:
支持分词,全文检索、支持模糊、精确查询,不支持聚合,排序操作;
text类型的最大支持的字符长度无限制,适合大字段存储;
keyword:
不进行分词,直接索引、支持模糊、支持精确匹配,支持聚合、排序操作。
keyword类型的最大支持的长度为——32766个UTF-8类型的字符,可以通过设置ignore_above指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果。
// 测试keyword和text是否支持分词
// 设置索引类型
PUT /test
{
"mappings": {
"properties": {
"text":{
"type":"text"
},
"keyword":{
"type":"keyword"
}
}
}
}
// 设置字段数据
PUT /test/_doc/1
{
"text":"测试keyword和text是否支持分词",
"keyword":"测试keyword和text是否支持分词"
}
// text 支持分词
// keyword 不支持分词
GET /test/_doc/_search
{
"query":{
"match":{
"text":"测试"
}
}
}// 查的到
GET /test/_doc/_search
{
"query":{
"match":{
"keyword":"测试"
}
}
}// 查不到,必须是 "测试keyword和text是否支持分词" 才能查到
GET _analyze
{
"analyzer": "keyword",
"text": ["测试liu"]
}// 不会分词,即 测试liu
GET _analyze
{
"analyzer": "standard",
"text": ["测试liu"]
}// 分为 测 试 liu高亮查询
/// 高亮查询
GET blog/user/_search
{
"query": {
"match": {
"name":"流"
}
}
,
"highlight": {
"fields": {
"name": {}
}
}
}
// 自定义前缀和后缀
GET blog/user/_search
{
"query": {
"match": {
"name":"流"
}
}
,
"highlight": {
"pre_tags": "<p class='key' style='color:red'>",
"post_tags": "</p>",
"fields": {
"name": {}
}
}
}六、spring boot整合es
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency><dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.70</version>
</dependency>
<!-- lombok需要安装插件 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
创建配置类
@Configuration
public class ElaticsearchConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("127.0.0.1",9200,"http")));
return client;
}
}测试
package com.rcg;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.rcg.entity.User;
import org.elasticsearch.action.DocWriteResponse;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.IndicesClient;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.search.sort.SortOrder;
import org.elasticsearch.xcontent.XContentType;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
@SpringBootTest
class SpringbootEsApplicationTests {
@Autowired
private RestHighLevelClient restHighLevelClient;
@Test
void contextLoads() {
}
//判断索引是否存在
@Test
public void test01() throws IOException {
//获取es连接
IndicesClient indices = restHighLevelClient.indices();
//索引的名字
GetIndexRequest myindex = new GetIndexRequest("myindex");
//判断
boolean exists = indices.exists(myindex, RequestOptions.DEFAULT);
System.out.println("是否存在:"+exists);
//关闭连接资源
restHighLevelClient.close();
}
//创建索引
@Test
public void test02() throws IOException {
//获取索引操作的类对象
IndicesClient indices = restHighLevelClient.indices();
//获取创建索引的请求对象 封装了关于索引的信息
CreateIndexRequest createIndexRequest = new CreateIndexRequest("qy158-jd");
//操作
CreateIndexResponse createIndexResponse = indices.create(createIndexRequest, RequestOptions.DEFAULT);
System.out.println("是否创建成功" + createIndexResponse.isAcknowledged());
//关闭连接资源
restHighLevelClient.close();
}
//删除索引
@Test
public void test03() throws IOException {
IndicesClient indices = restHighLevelClient.indices();
DeleteIndexRequest myindex = new DeleteIndexRequest("myindex");
AcknowledgedResponse delete = indices.delete(myindex, RequestOptions.DEFAULT);
System.out.println("delete = " + delete.isAcknowledged());
//关闭连接资源
restHighLevelClient.close();
}
//添加文档
@Test
public void test04() throws IOException {
IndexRequest indexRequest = new IndexRequest("qy158-index");
//自定义id
indexRequest.id("1");
//指定字段
User user = new User("张老三",16,"南京");
indexRequest.source(JSON.toJSONString(user), XContentType.JSON);
IndexResponse index = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
DocWriteResponse.Result result = index.getResult();
System.out.println("result = " + result);
//关闭连接资源
restHighLevelClient.close();
}
@Test
public void test05() throws IOException {
GetRequest getRequest = new GetRequest("qy158-index", "6");
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
Map<String, Object> sourceAsMap = getResponse.getSourceAsMap();
System.out.println("sourceAsMap = " + sourceAsMap);
String s = getResponse.getSourceAsString();
System.out.println("s = " + s);
//字符串转对象
JSONObject jsonObject = new JSONObject(JSON.parseObject(s));
User user = jsonObject.toJavaObject(jsonObject, User.class);
System.out.println("user = " + user);
//关闭连接资源
restHighLevelClient.close();
}
//删除文档
@Test
public void test06() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest("qy158-index", "1");
DeleteResponse delete = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println("delete = " + delete.getResult());
//关闭连接资源
restHighLevelClient.close();
}
//修改文档
@Test
public void test07() throws IOException {
UpdateRequest updateRequest = new UpdateRequest("qy158-index", "1");
User user = new User("李四",18,"东京");
//更新的内容字段
updateRequest.doc(JSON.toJSONString(user),XContentType.JSON);
//操作
UpdateResponse update = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
System.out.println("update = " + update.getResult());
//关闭连接资源
restHighLevelClient.close();
}
//批量添加
@Test
public void test08() throws IOException {
BulkRequest bulkRequest = new BulkRequest("qy158-index");
List<User> list=new ArrayList<>();
list.add(new User("刘德华",12, "香港"));
list.add(new User("张学友",16, "北京"));
list.add(new User("黎明", 28,"郑州"));
list.add(new User("郭富城", 36,"上海"));
for (int i = 0; i < list.size(); i++) {
IndexRequest indexRequest = new IndexRequest();
indexRequest.id(String.valueOf(i+2));
indexRequest.source(JSON.toJSONString(list.get(i)),XContentType.JSON);
bulkRequest.add(indexRequest);
}
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest,RequestOptions.DEFAULT);
//关闭连接资源
restHighLevelClient.close();
}
//高级搜索
@Test
public void test09() throws IOException {
//搜索的请求对象
SearchRequest searchRequest = new SearchRequest("qy158-index");
//构建一个条件类对象
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//match多条件匹配条件
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("name", "张");
//加入各种条件
//加入多条件匹配
searchSourceBuilder.query(matchQueryBuilder);
//加入排序
searchSourceBuilder.sort("age", SortOrder.DESC);
//加入分页
searchSourceBuilder.from(0);
searchSourceBuilder.size(2);
//加入高亮
HighlightBuilder highlightBuilder=new HighlightBuilder();
highlightBuilder.field("name");
highlightBuilder.preTags("<font color='red'>");
highlightBuilder.postTags("</font>");
searchSourceBuilder.highlighter(highlightBuilder);
//把条件对象封装到请求里
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//获取相响应信息
SearchHits hits = searchResponse.getHits();
//解析结果
SearchHit[] hits1= hits.getHits();
for(SearchHit hit:hits1){
//得到旧的字段
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
//得到高亮的字段
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
//把旧的字段覆盖 只显示高亮的
sourceAsMap.put("name",highlightFields.get("name").getFragments()[0]);
System.out.println(sourceAsMap);
}
//关闭连接资源
restHighLevelClient.close();
}
}
总结
待补充