dataloader_tools.py
import torchvision
from torchvision import transforms
from torch.utils.data import DataLoader
def load_data():
# 载入MNIST训练集
train_dataset = torchvision.datasets.MNIST(
root = "../datasets/",
train=True,
transform=transforms.ToTensor(),
download=True
)
# 载入MNIST测试集
test_dataset = torchvision.datasets.MNIST(
root = "../datasets/",
train=False,
transform=transforms.ToTensor(),
download=True
)
# 生成训练集和测试集的dataloader
train_dataloader = DataLoader(dataset=train_dataset,batch_size=12,shuffle=True)
test_dataloader = DataLoader(dataset=test_dataset,batch_size=12,shuffle=False)
return train_dataloader,test_dataloader
models.py
import torch
from torch import nn
# 教师模型
class TeacherModel(nn.Module):
def __init__(self,in_channels=1,num_classes=10):
super(TeacherModel,self).__init__()
self.relu = nn.ReLU()
self.fc1 = nn.Linear(784,1200)
self.fc2 = nn.Linear(1200,1200)
self.fc3 = nn.Linear(1200,num_classes)
self.dropout = nn.Dropout(p=0.5) #p=0.5是丢弃该层一半的神经元.
def forward(self,x):
x = x.view(-1,784)
x = self.fc1(x)
x = self.dropout(x)
x = self.relu(x)
x = self.fc2(x)
x = self.dropout(x)
x = self.relu(x)
x = self.fc3(x)
return x
class StudentModel(nn.Module):
def __init__(self,in_channels=1,num_classes=10):
super(StudentModel,self).__init__()
self.relu = nn.ReLU()
self.fc1 = nn.Linear(784,20)
self.fc2 = nn.Linear(20,20)
self.fc3 = nn.Linear(20,num_classes)
def forward(self,x):
x = x.view(-1,784)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
return x
train_tools.py
from torch import nn
import time
import torch
import tqdm
import torch.nn.functional as F
def train(epochs, model, model_name, lr,train_dataloader,test_dataloader,device):
# ----------------------开始计时-----------------------------------
start_time = time.time()
# 设置参数开始训练
best_acc, best_epoch = 0, 0
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
for epoch in range(epochs):
model.train()
# 训练集上训练模型权重
for data, targets in tqdm.tqdm(train_dataloader):
# 把数据加载到GPU上
data = data.to(device)
targets = targets.to(device)
# 前向传播
preds = model(data)
loss = criterion(preds, targets)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 测试集上评估模型性能
model.eval()
num_correct = 0
num_samples = 0
with torch.no_grad():
for x, y in test_dataloader:
x = x.to(device)
y = y.to(device)
preds = model(x)
predictions = preds.max(1).indices # 返回每一行的最大值和该最大值在该行的列索引
num_correct += (predictions == y).sum()
num_samples += predictions.size(0)
acc = (num_correct / num_samples).item()
if acc > best_acc:
best_acc = acc
best_epoch = epoch
# 保存模型最优准确率的参数
torch.save(model.state_dict(), f"../weights/{model_name}_best_acc_params.pth")
model.train()
print('Epoch:{}\t Accuracy:{:.4f}'.format(epoch + 1, acc),f'loss={loss}')
print(f'最优准确率的epoch为{best_epoch},值为:{best_acc},最优参数已经保存到:weights/{model_name}_best_acc_params.pth')
# -------------------------结束计时------------------------------------
end_time = time.time()
run_time = end_time - start_time
# 将输出的秒数保留两位小数
if int(run_time) < 60:
print(f'训练用时为:{round(run_time, 2)}s')
else:
print(f'训练用时为:{round(run_time / 60, 2)}minutes')
def distill_train(epochs,teacher_model,student_model,model_name,train_dataloader,test_dataloader,alpha,lr,temp,device):
# -------------------------------------开始计时--------------------------------
start_time = time.time()
# 定以损失函数
hard_loss = nn.CrossEntropyLoss()
soft_loss = nn.KLDivLoss(reduction="batchmean")
# 定义优化器
optimizer = torch.optim.Adam(student_model.parameters(), lr=lr)
best_acc,best_epoch = 0,0
for epoch in range(epochs):
student_model.train()
# 训练集上训练模型权重
for data,targets in tqdm.tqdm(train_dataloader):
# 把数据加载到GPU上
data = data.to(device)
targets = targets.to(device)
# 教师模型预测
with torch.no_grad():
teacher_preds = teacher_model(data)
# 学生模型预测
student_preds = student_model(data)
# 计算hard_loss
student_hard_loss = hard_loss(student_preds,targets)
# 计算蒸馏后的预测结果及soft_loss
ditillation_loss = soft_loss(
F.softmax(student_preds/temp,dim=1),
F.softmax(teacher_preds/temp,dim=1)
)
# 将hard_loss和soft_loss加权求和
loss = temp * temp * alpha * student_hard_loss + (1-alpha)*ditillation_loss
# 反向传播,优化权重
optimizer.zero_grad()
loss.backward()
optimizer.step()
#测试集上评估模型性能
student_model.eval()
num_correct = 0
num_samples = 0
with torch.no_grad():
for x,y in test_dataloader:
x = x.to(device)
y = y.to(device)
preds = student_model(x)
predictions = preds.max(1).indices #返回每一行的最大值和该最大值在该行的列索引
num_correct += (predictions ==y).sum()
num_samples += predictions.size(0)
acc = (num_correct/num_samples).item()
if acc>best_acc:
best_acc = acc
best_epoch = epoch
# 保存模型最优准确率的参数
torch.save(student_model.state_dict(),f"../weights/{model_name}_best_acc_params.pth")
student_model.train()
print('Epoch:{}\t Accuracy:{:.4f}'.format(epoch+1,acc))
print(f'student_hard_loss={student_hard_loss},ditillation_loss={ditillation_loss},loss={loss}')
print(f'最优准确率的epoch为{best_epoch},值为:{best_acc},')
# --------------------------------结束计时----------------------------------
end_time = time.time()
run_time = end_time - start_time
# 将输出的秒数保留两位小数
if int(run_time) < 60:
print(f'训练用时为:{round(run_time, 2)}s')
else:
print(f'训练用时为:{round(run_time / 60, 2)}minutes')
训练教师网络
import torch
from torchinfo import summary #用来可视化的
import models
import dataloader_tools
import train_tools
# 设置随机数种子
torch.manual_seed(0)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 使用cuDNN加速卷积运算
torch.backends.cudnn.benchmark = True
# 载入MNIST训练集和测试集
train_dataloader,test_dataloader = dataloader_tools.load_data()
# 定义教师模型
model = models.TeacherModel()
model = model.to(device)
# 打印模型的参数
summary(model)
# 定义参数并开始训练
epochs = 10
lr = 1e-4
model_name = 'teacher'
train_tools.train(epochs,model,model_name,lr,train_dataloader,test_dataloader,device)
最优准确率的epoch为9,值为:0.9868999719619751
用非蒸馏的方法训练学生网络
import torch
from torchinfo import summary #用来可视化的
import dataloader_tools
import models
import train_tools
# 设置随机数种子
torch.manual_seed(0)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 使用cuDNN加速卷积运算
torch.backends.cudnn.benchmark = True
# 生成训练集和测试集的dataloader
train_dataloader,test_dataloader = dataloader_tools.load_data()
# 从头训练学生模型
model = models.StudentModel()
model = model.to(device)
# 查看模型参数
print(summary(model))
# 定义参数并开始训练
epochs = 10
lr = 1e-4
model_name = 'student'
train_tools.train(epochs, model, model_name, lr,train_dataloader,test_dataloader,device)
最优准确率的epoch为9,准确率为:0.9382999539375305,最优参数已经保存到:weights/student_best_acc_params.pth
训练用时为:1.74minutes
用知识蒸馏的方法训练student model
import torch
import train_tools
import models
import dataloader_tools
# 设置随机数种子
torch.manual_seed(0)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 使用cuDNN加速卷积运算
torch.backends.cudnn.benchmark = True
# 加载数据
train_dataloader,test_dataloader = dataloader_tools.load_data()
# 加载训练好的teacher model
teacher_model = models.TeacherModel()
teacher_model = teacher_model.to(device)
teacher_model.load_state_dict(torch.load('../weights/teacher_best_acc_params.pth'))
teacher_model.eval()
# 准备新的学生模型
student_model = models.StudentModel()
student_model = student_model.to(device)
student_model.train()
# 开始训练
lr = 0.0001
epochs = 20
alpha = 0.3 # hard_loss权重
temp = 7 # 蒸馏温度
model_name = 'distill_student_loss'
# 调用train_tools中的
train_tools.distill_train(epochs,teacher_model,student_model,model_name,train_dataloader,test_dataloader,alpha,lr,temp,device)
最优准确率的epoch为9,值为:0.9204999804496765,
训练用时为:2.14minutes

loss改为:
# temp的平方乘在student_hard_loss
loss = temp * temp * alpha * student_hard_loss + (1 - alpha) * ditillation_loss
最优准确率的epoch为9,值为:0.9336999654769897,
训练用时为:2.12minutes
loss改为:
# temp的平方乘ditillation_loss
loss = alpha * student_hard_loss + temp * temp * (1 - alpha) * ditillation_loss
最优准确率的epoch为9,值为:0.9176999926567078,
训练用时为:2.09minutes
上面的几种loss,蒸馏损失都出现了负数的情况。不太对劲。

其它开源的知识蒸馏算法如下:
open-mmlab开源的工具箱包含知识蒸馏算法
mmrazor
github.com/open-mmlab/mmrazor
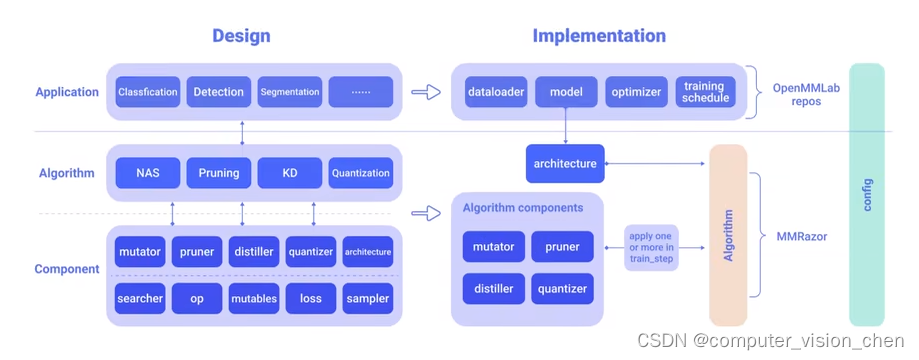
NAS:神经架构搜索
剪枝:Pruning
KD: 知识蒸馏
Quantization: 量化
自定义知识蒸馏算法:
mmdeploy
可以把算法部署到一些厂商支持的中间格式,如ONNX,tensorRT等。
HobbitLong的RepDistiller
github.com/HobbitLong/RepDistiller

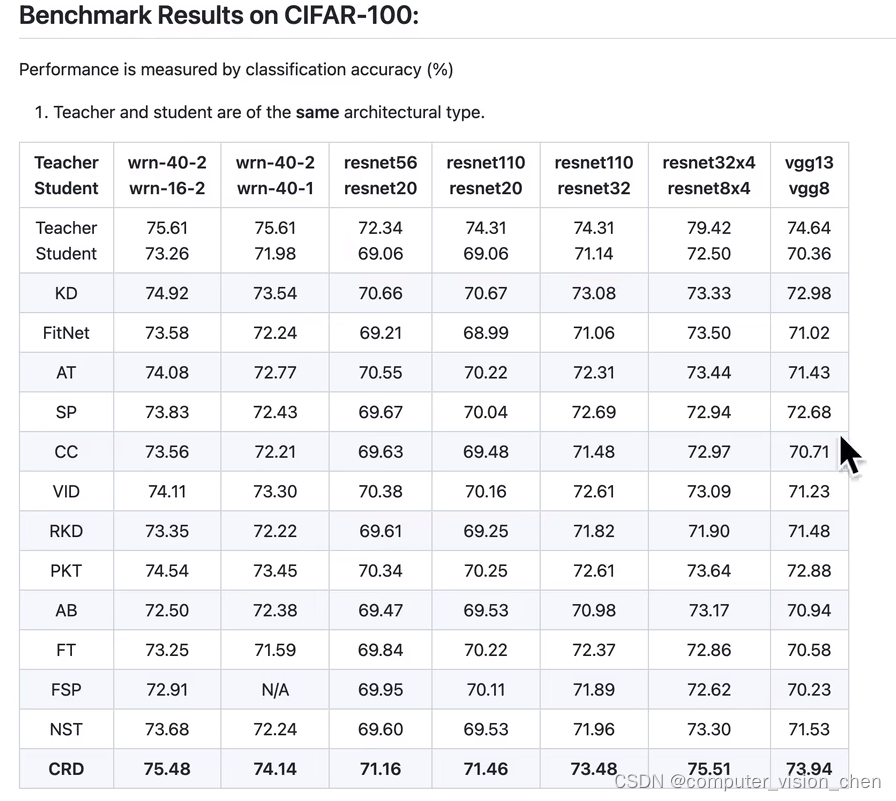
里面有12种最新的知识蒸馏算法。
蒸馏网络可以应用于同一种模型,将大的学习的知识蒸馏到小的上面。
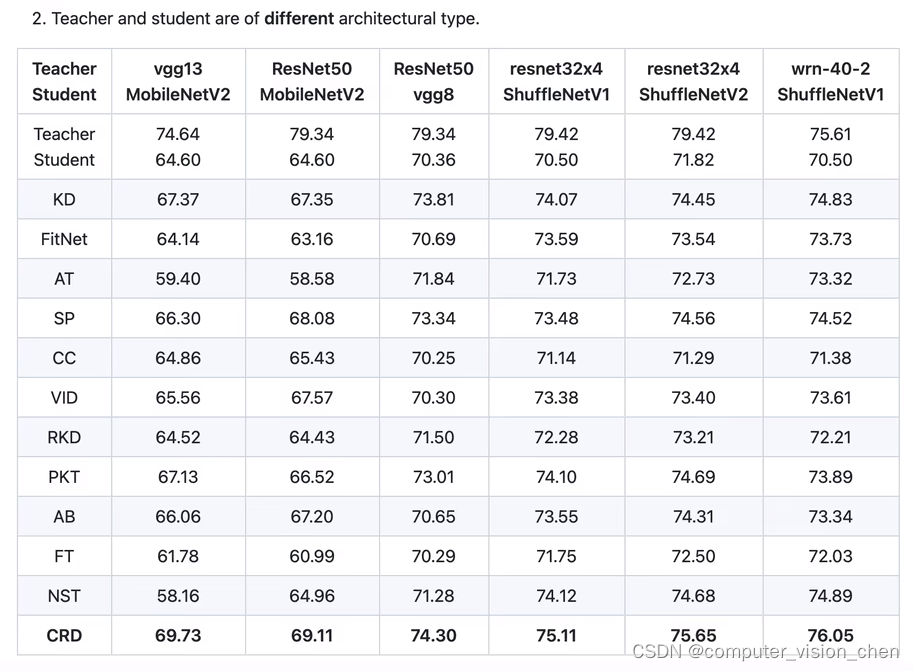
如下将resnet100做教师网络,resnet32做学生网络。
将一种模型迁移到另一种模型上。如vgg13做教师网络,mobilNetv2做学生网络: