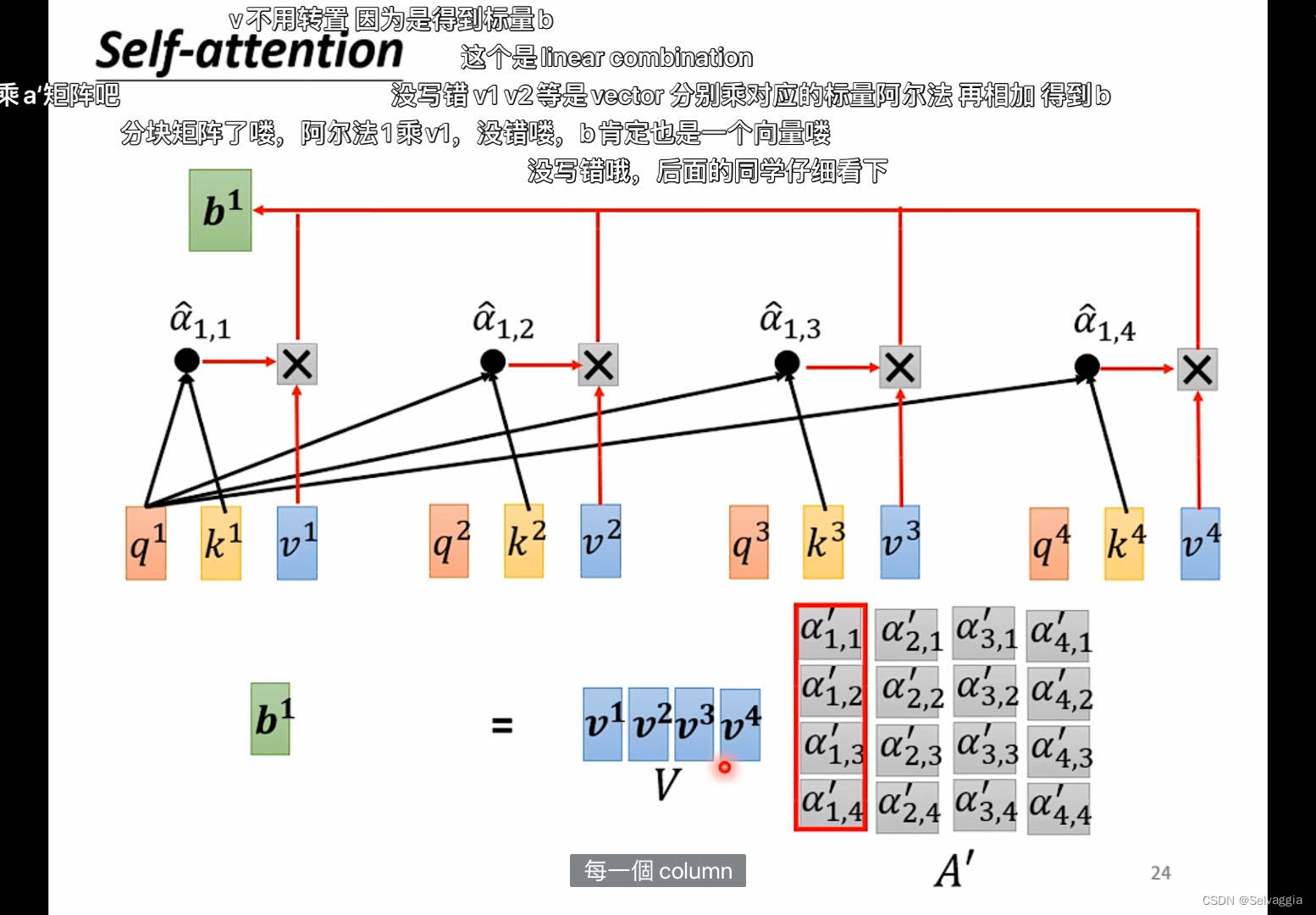
前言:做FPGA大赛期间遇到的问题,自己coding过程。
包含:hdmi、摄像头等多输入源的拼接;了解DDR以及多种DMA传输方式,修改底层突发长度以及存储位宽;单输入源任意角度旋转(无需降低帧率)。
文章目录
- 前言
- 免责声明
- 一、hdmi、摄像头等多输入源的拼接
- 二、WDMA传输
- 三、单输入源的任意旋转
- 任意突发长度修改
- 旋转部分
- 其他事项记录
- 总结
前言
写这篇文章的原因呢,是因为之前参加FPGA大赛的时候遇到很多问题找不到系统的解决办法,本文主要提供一个大概的关于图像的大概处理流程;当然根本原因是没晋级决赛了哇,但是不得不承认我在这个比赛的过程中学习到了非常多的东西,记录下来帮助更多希望入门FPGA和图像处理的朋友们。接下来的内容会以提出问题->分析问题->解决问题的形式展示。
免责声明
本人做FPGA很多年,但是系统的做FPGA图像处理这是第一次,本文仅记录一月以来的调试内容,如果内容有问题请通过邮箱联系我,评论偶尔会看。代码(紫光同创版)免费提供(仅仅提供我写的部分)
一、hdmi、摄像头等多输入源的拼接
问题:DDR在某个时刻只能进行读或者写操作的条件下如何进行数据处理?怎么才能最大程度的减缓帧丢失?
在使用xilinx系列FPGA的时候里面有一个很常用的IP:AXI-interconnect;AXI-interconnect是一个一主多从的模块,对多通道从机进行数据缓存通过自动仲裁,输出。他的优点简单,emm,只有简单。
最初,解决这个问题的时候进行了降帧的处理,即DDR的某片区域存够了摄像头或者hdmi输入的一帧数据进行暂停处理,当DDR的另一片区域也存够了hdmi或者摄像头输入的一帧再进行输出。
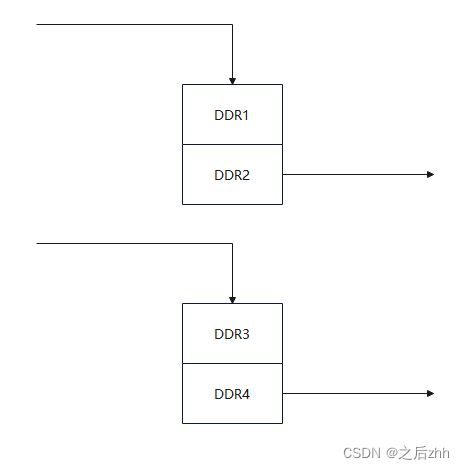
如图所示,每个区域会在存满一帧以后等待另一个输入也存满的时候进行输出,然后在此进行下一次存储。这样造成的结果会使得两个输入源的帧率成倍的降低。
那么我们在没有AXI-interconnect IP的条件下,如何进行仲裁呢?怎么才能减缓帧率的丢失呢?
为了解决这个问题,我使用的数据仲裁方法是——固定优先级算法进行仲裁。
if(wfifo_rcount_1 >= wr_bust_len )begin
state_cnt <= WRITE_ADDR_1;
end
else if(wfifo_rcount_2 >= wr_bust_len )begin
state_cnt <= WRITE_ADDR_2;
end
else if(raddr_rst_h)begin
state_cnt <= DDR3_DONE;
end
else if(rfifo_wcount_1 < rd_bust_len )begin
state_cnt <= READ_ADDR_1;
end
else if(rfifo_wcount_2 < rd_bust_len )begin
state_cnt <= READ_ADDR_2;
end
这个算法的缺点很明显,就是可能会造成总线主设备的“饥饿”或“撑”的现象,但是由于DDR速率远远超过fifo的存储速率在从机不多的条件下远远满足我所需要的要求。
有了仲裁算法,剩下的就是对AXI总线的coding了,有兴趣的人可以参考博客AXI-lite以及debug过程,这里要注意的是紫光同创今年这个版本的DDR的特点:使用的是Simplified AXI4 接口,配置较为简单。即:读写地址需要进行握手,数据则不需要。
在进行完数据仲裁之后,就可以各输入源进行写入和读出的操作了,经测试,帧率完美吻合,使用两帧缓存乒乓操作不会出现画面撕裂现象。
最后,记录一下DDR里面的数据计算方法,因为这个也曾困扰我一个晚上。
首先PGL50H中,DDR支持32bit,含有4Gbit(一片512MB,两片1024MB)内存。生成ip后的地址位宽为28bit;
当所有地址写满的时候我们计算一下内存是否吻合:
2^28*32/8=1,073,741,824Byte = 1024MB
最初版代码使用的是:
burst_len=16; input_data_width=16; AXI_data_width=256;DDR_data_width=32;
那么每次地址变化应该是:addr=addr+burst_len*AXI_data_width/DDR_data_width;
地址变化这里一定要仔细理解,不然后续旋转无法清楚
DDR中每个地址存放的数据位宽为32bit,每一次burst传输256个bit,也就意味着每一次burst的时候DDR对应的地址变化是8

如果进行16次burst,那自然就是burst_len*8;
二、WDMA传输
摘要:WDMA(Waste Direct Memory Access),即一种极其占用DDR内存和时间的传输方式,由于它极其消耗资源,因此我给它命名为WDMA。
在正式介绍WDMA之前,介绍一下目前我目前接触到的几种DMA传输方式:VDMA,CDMA,XDMA,FDMA;前三种DMA传输方式是xilinx厂家提供的ip,最后一个FDMA是米联客提供的ip。简单介绍一下前三种。
VDMA:简单来说就是为了缓存帧图像专门开发出来的一个DMA方式,可以满足改变帧速率,缓存帧的需求。
CDMA:用过MicroBlaze的应该都很了解,就是PL和PS之间的沟通渠道,ZYNQ则是用到DDR的时候会用到这个DMA传输方式。
XDMA:我使用XDMA都是用来进行PCIe数据沟通的,可见xilinx series 7 PCIE xdma测试记录
这里重点说一下FDMA(米联客开发,有详细的文档说明,目前已经更新到第六版,如有需求请通过邮箱联系我),是我在比赛最开始准备使用的一款ip,我这有详细的文档介绍,这里只说一下我前期准备过程中学到的一些东西。

首先是名字FDMA,为什么叫FDMA? 解答:FDMA(Fast Direct Memory Access)是一种快速DMA缓存方式。
FDMA的优点:如果使用过xilinx的DMA ip那么大家应该了解,配置起来稍显麻烦,不够灵活。而FDMA突出特点是简单直接。FDMA主要是定义了一个AXI4 FULL的ip,其余需要的DDR等外设只需要挂载在AXI4总线上就可以进行外设读取存储的操作了,跟着米联客的教程,一步一步做,不要光看一定要有自己debug的过程。
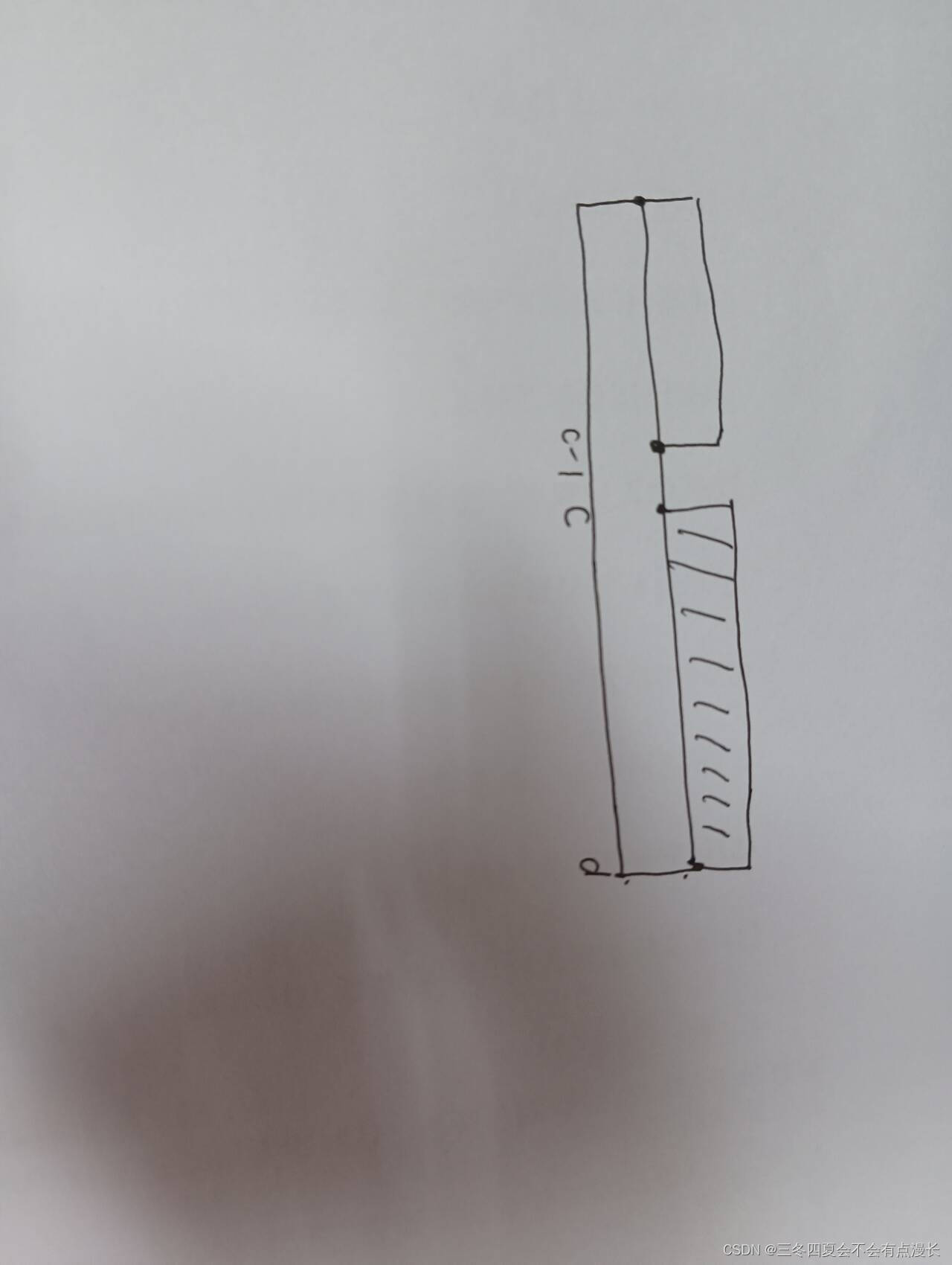
FDMA使用的三帧缓存架构数据框图如下:
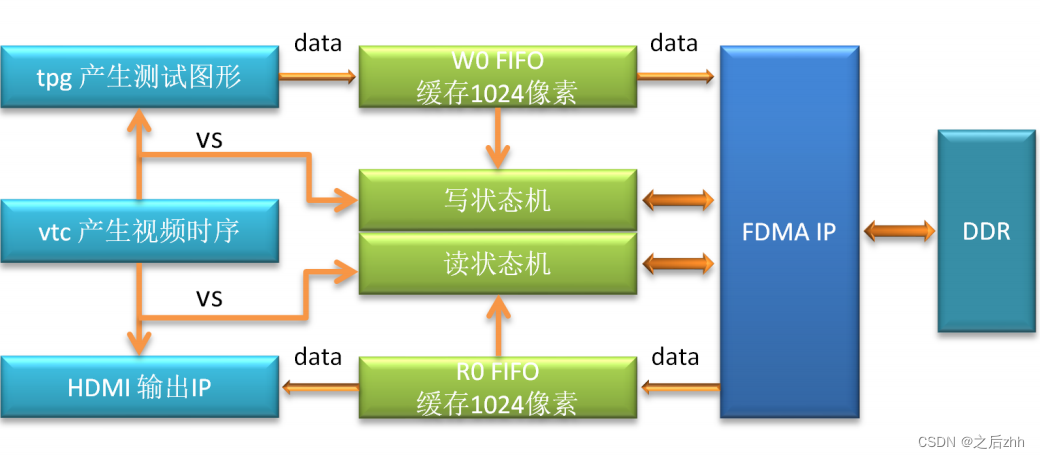
使用xilinx的话我们就是为了简单,那么如果此时有多通道的输入,我们只需要调用axi-interconnect ip就行,如果通道数过多的话我建议使用自己写的仲裁方式,因为这个ip只能满足低时序,数据量不是那么大的情况下使用。
三帧缓存架构,这里定义的FBUF_SIZE就是来控制帧缓存的一个parameter。
//write
if(W0_bcnt == BURST_TIMES) begin
if(W0_Fbuf == FBUF_SIZE)
W0_Fbuf <= 7'd0;
else
W0_Fbuf <= W0_Fbuf + 1'b1;
W_MS <= S_IDLE;
end
//read
if(R0_bcnt == BURST_TIMES ) begin
R_MS <= S_IDLE;
if(W0_Fbuf == 7'd0)
R0_Fbuf <= FBUF_SIZE;
else
R0_Fbuf <= W0_Fbuf - 1'b1;
end
//frame 地址切换
assign O_bufn = I_bufn < BUF_DELAY? (BUF_LENTH - BUF_DELAY + I_bufn) : (I_bufn - BUF_DELAY) ;
三帧缓存,里面的操作就是对帧的缓存和读出有一个乒乓操作,当然我们的代码中没有修改使用的是两帧缓存方案的乒乓操作,这里介绍一下三帧缓存方案:
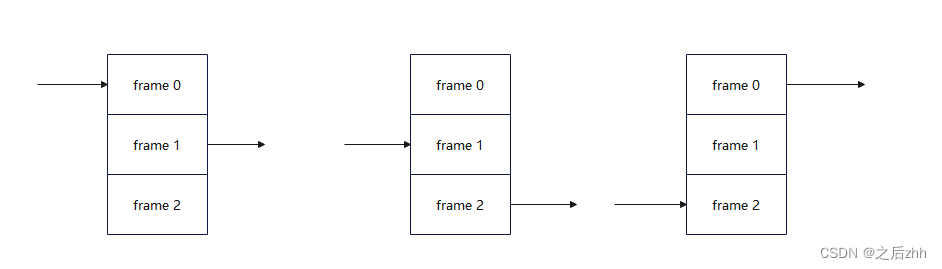
如图所示,我读出的帧和写入的帧两个地址永远不会重叠,我们做的地址切换就有这样的操作。
assign O_bufn = I_bufn < BUF_DELAY? (BUF_LENTH - BUF_DELAY + I_bufn) : (I_bufn - BUF_DELAY) ;
// 3帧缓存 延迟2帧推导 BUF_DELAY = 2 ,BUF_LENTH = 3
//0<BUF_DELAY(2) BUF_LENTH(3) - BUF_DELAY(2) + I_bufn(0) = 1
//1<BUF_DELAY(2) BUF_LENTH(3) - BUF_DELAY(2) + I_bufn(1) = 2
//2=BUF_DELAY(2) I_bufn(2) - BUF_DELAY(2) = 0
FDMA配置问题等等可以看文档说明,说的绝对比我明白的多。
那开始进入正题,WDMA的介绍。
为什么叫WDMA呢,上面已经有过介绍,这里用图片来简单介绍一下,由于输入的图像位宽是16,而一个DDR地址的位宽为32bit,如果我们想让每个地址对应一个点,显示还要做一个像素点的“挑选”。按照简单输入地址和输出地址做对应来说,输出地址从0-1的时候对应的DDR里面都是0,那这么定义的话addr_o>>1=addr_DDR。那我们的挑选规则就是
addr_o[0] -> data[15:0];
addr_o[1] -> data[31:16];
由于我们想做的是任意旋转,每次我只要一个点,而点的对应最好就是一个DDR地址存储的数据就是一个像素点,这样会大大简化算法复杂度,于时就有了WDMA的产生,这是它的第一层含义。
 那么它的第二层含义在哪呢?
那么它的第二层含义在哪呢?
使用的紫光同创的DDR最低一次burst最少传输256bit数据,如果对应旋转的话,我一次只要一个点,那就对应不上了,第二层含义就是修改读出地址,重复读出已经读过的数据,这是第二个含义。
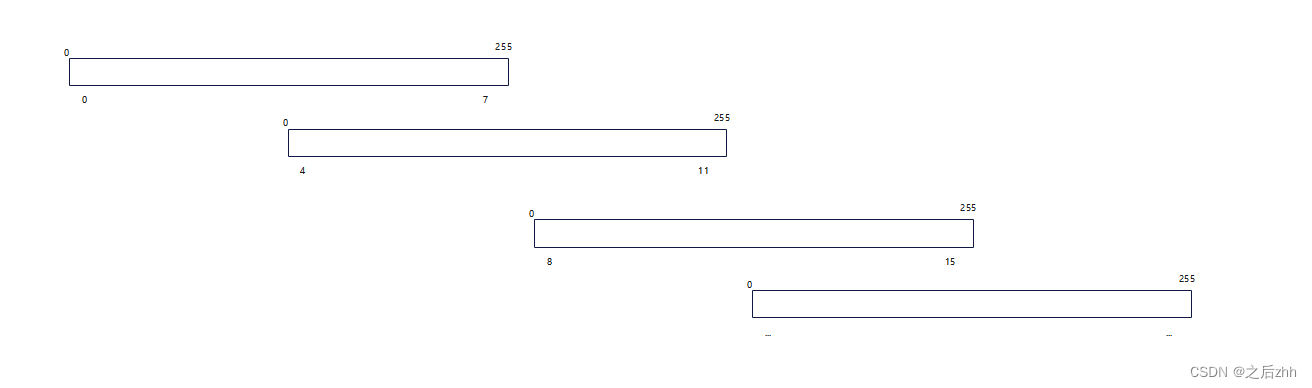
为了到达想要的状态,不得不进行这样的资源消耗,这样带来的效果是非常好的,可以在任意旋转的状态下保持和平常一样的帧率。
三、单输入源的任意旋转
有了上述一、二的解释,最后一节就很好说了,我们只需要在满足所需要的缓存内存和地址映射就可以完成任意旋转了。
难点: 突发长度的修改,任意地址的读取,满足时序的要求等。
这里先看一下最开始的效果,一行显示1024个像素点的时候,16个像素点表示1个点的结果如下。

这是最开始,不浪费任何资源时候的效果。
接下来演示使用WDMA的效果

任意突发长度修改
在代码中修改rd_butst_len=5‘d1,这时候我们进行一次burst会传递256个数据,此时出现的结果是上述模糊图像。那么还要修改的地方就是我的输入数据
wr_fifo wr_fifo_init (
.wr_clk (wr_clk), // input
.wr_rst (!rst_n|wfifo_rst_h), // input
.wr_en (datain_valid), // input
.wr_data ({datain,16'd0}), // input [31:0]
.wr_full (), // output
.wr_water_level(), // output [12:0]
.almost_full (), // output
.rd_clk (ddr_clk), // input
.rd_rst (!rst_n|wfifo_rst_h), // input
.rd_en (wfifo_rden), // input
.rd_data (wfifo_dout), // output [255:0]
.rd_empty (), // output
.rd_water_level(wfifo_rcount), // output [9:0]
.almost_empty () // output
);
这里修改之后相当于我每个地址存放的是一个像素点,此时又要进行一个计算,就是一帧图像需要占据的DDR的大小是多少;
1280 * 720 * 32 / 32 = 921600,这是对应的我们DDR的最大地址,很明显资源浪费多了一倍
输入是16bit时 : 1280 * 720 * 16 / 32 = 460800
接下来是对读地址进行重复读操作的代码
if(axi_arready && axi_arvalid) begin
axi_arvalid <= 1'b0;
axi_araddr_n_1 <= axi_araddr_n_1 + 5'd4;
end
如果正常完成一次burst应该是地址加8(见一所述),因为每次读出的数据不希望是256bit所以对地址进行这样的操作。
如果仅仅修改完这次加载代码会发现,什么东西都没了,为什么呢?
在代码里面仲裁是通过固定优先级来实现的,读操作的许可证,是通过rd_fifo的数据位来进行控制的,当一次burst吐出256个数据而我只要128个数据的时候会造成DDR->fifo时序和数据位的错乱,因此,要做一个强制拉回的操作,在代码里是这样控制的。
always@(posedge clk or negedge rst_n)
if(!rst_n)
rd_data_cnt <= 6'd0;
else if(rd_data_cnt== 6'd31 && (state_cnt == READ_DATA_1 ||state_cnt == READ_ADDR_1))
rd_data_cnt <= 0;
else if(axi_rvalid && (state_cnt == READ_DATA_1 ||state_cnt == READ_ADDR_1))
rd_data_cnt <= rd_data_cnt + 1;
else if(state_cnt == READ_DATA_1 ||state_cnt == READ_ADDR_1 )
rd_data_cnt <= rd_data_cnt ;
else
rd_data_cnt <= 0 ;
//------------------------------------------------------------------------------------------------------
//------------------------------------------------------------------------------------------------------
READ_ADDR_1:begin
if(rd_data_cnt==6'd31 )
state_cnt <= DDR3_DONE;
else if(axi_arvalid && axi_arready)
state_cnt <= READ_DATA_1;
else
state_cnt <= state_cnt;
end
READ_DATA_1:begin //
if( rd_data_cnt < 6'd31)
state_cnt <= READ_ADDR_1; //
else if(rd_data_cnt==6'd31 )
state_cnt <= DDR3_DONE;
else //
state_cnt <= state_cnt; //
end
这就是全部内容了,当完成强制拉回操作之后,就可以对任意地址,任意突发长度,任意数据的读取操作了。
写完文章一下午最多提问的是关于拉回操作为什么这么做,体现在哪里
不管是使用官方例程还是黑金的axi,最初的burst_len=16。
使用代码的时候一开始突发长度为16的时候所有东西都正常这是肯定的,那么当现在burst=1的时候会有问题,那该怎么改呢,才能正确呢?好,强制进行16次burst为1的操作 ,此时的地址跳变为8,结果你会发现,哎,正常了。
那么我们进行下一步,开始浪费资源,重复去读,此时地址跳变为4,那么该怎么做呢?很明显,强制进行16x2次burst为1的操作即可。这是对强制拉回操作的一个解释。
旋转部分
旋转模块采用的是逆向思维,用目标图像的坐标去与原图的坐标进行坐标匹配,若在原图像中能找到匹配的图像,就显示该点旋转后的点坐标,若在原图中找不到该点,则不显示该点。具体算法参考19年FPGA大赛大佬,下面是他的链接https://blog.csdn.net/weixin_42905573/article/details/105941991
在任意旋转模块中,首先要保证的是得到一帧完整存在的图像,对于显示器输出坐标做一个回环,经过旋转算法模块对应到DDR中的数据,取出显示,本模块数据流程框图如图。
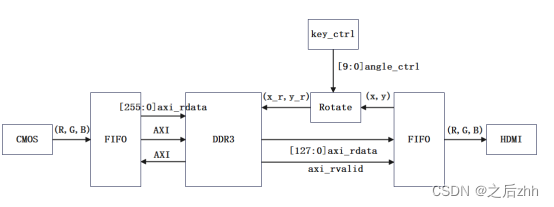
本方案配置的摄像头分辨率为1280 * 720p,HDMI显示也是1280 * 720p,因此如果对应到坐标位置,每一行用x表示,x从0开始计数到1280,用y来表示此时已经计数到哪一行,对应到DDR一帧图像中选取的坐标点的addr信息为ddr_addr=x_r+1280*y_r。
使用之前介绍的WDMA方式,可以对DDR中的任意数据进行读出,且满足时序要求,使用二级缓存乒乓操作的方式可以保证画面不撕裂。
if(axi_arready && axi_arvalid)begin
axi_arvalid <= 1'b0;
axi_araddr_n_1 <= axi_araddr_n_1 + rd_bust_len*5'd4;
axi_araddr_n_11 <= ( x_rotate >= 1280 || y_rotate > 720 ) ? 28'd0 : x_rotate[12:0] + y_rotate[12:0] *12'd1280;
if(x_cnt> 12'd1280-12'd8)begin
x_cnt <= 32'd0;
y_cnt <= y_cnt + 1;
end
else begin
x_cnt <= x_cnt + 5'd4;
y_cnt <= y_cnt;
end
end
//-------------------------------------------------------------------------------------------
coor_trans coor_trans_inst
(
.clk ( clk ),
.rst_n ( rst_n ),
.angle ( 10'd180 ),
.x_in ( x_cnt ),
.y_in ( y_cnt ),
.x_out ( x_rotate ),
.y_out ( y_rotate )
);
效果展示
A4EA9C00A50A042A13BD13535A3E5A90
以上是对这次FPGA大赛的一次总结,如果按照工程走可完成的任务是图像拼接,旋转,以太网收发(本文主要讲摄像头,不涉及以太网的东西),上述所用的所有算法代码等如有需求可以通过邮箱联系我:784927721@qq.com
其他事项记录
在这次比赛中,学到了很多东西,最后记录一点小东西,希望能在不经意之间帮到大家,做完之后我们的视频中在旋转的过程中一些该是黑色的地方有很多毛刺,分析原因,是在外层r_data的时候用了组合逻辑进行了输出,不影响输出,但是某些时序可能没有对上。
在这过比赛中收获最大的可能是在资源消耗过大的时候,使用大量组合逻辑会影响布局布线规则,而我使用组合还是时序的条件都是看是否当前输入要和时钟产生关系,没想到最后使用一点组合逻辑就会导致了很多时序问题。
篇幅有限,上述还有很多仿真工作以及debug过程没有展示。
本文全部原创,如果转载请联系作者,侵权必究。
总结
这次比赛,感谢全国大学生FPGA创新设计竞赛组委会所提供的宝贵的参赛机会,感谢FPGA紫光同创为我们提供的一切支持,感谢米联客ip作者在晚上十一点被我打扰还一点一点与我讲解ip的问题所提供的帮助。
因为淋过雨,所以想给别人撑伞。