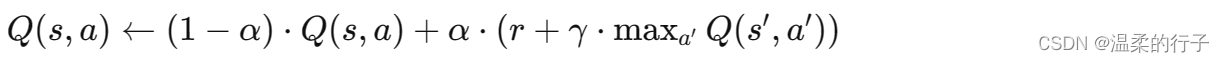这里写目录标题
- transformer
- abstract
- conclusion
- introduction
- background
- 注意力机制
- mlp
- transformer和RNN传递序列信息
- embedding之后维度越大的向量归一化后其单个值就越小,乘个根号512
- position encoding加入时序信息
transformer
abstract
编码器和解码器的架构 处理一个序列对
纯基于注意力,selfattention,没有RNN
*在论文里面同样贡献
序列转录,给一个序列生成另一个序列
传统 依赖于循环或者卷积神经网络,
dispensing with 免除,不需要
indispensable 不可或缺的
BLEU score机器翻译里大家经常用到的衡量标准
一开始用在 机器翻译 比较小的领域
conclusion
使得生成不那么时序化!!!
introduction
输出结构化信息比较多的时候会用到编码器解码器的架构
CNN
时序性,难以在时间上并行
一步一步往后传递
如果序列较长,可能需要丢弃比较靠前的时序信息,否则需要足够的内存开销存下所有时序信息
并行的改进,分解的方法 提升并行度
attention在RNN上的应用,成功地用在编码器和解码器,如何很有效地把编码器东西传递给解码器,和RNN使用
纯注意力机制,并行度高
background
卷积神经网络 替换掉 循环神经网络
使得减少时序计算
卷积神经网络 对较长序列难以建模,像素块,很多层卷积 才能把隔得很远地两个像素 融合起来
注意力机制 能看到所有的像素(扩大感受野?)
卷积神经网络可以做多个输出通道,每个输出通道可以认为是去识别不一样的 模式
多输出通道,多头注意力机制 模仿 卷积神经网络 多输出通道地效果
自注意力机制
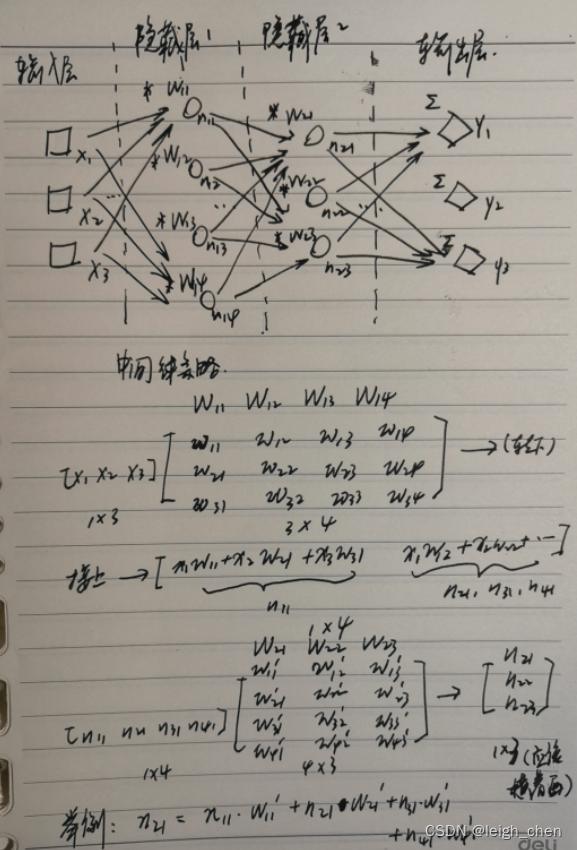
模型架构
序列模型里,比较好的是编码器解码器 架构
将输入序列,表示为长度为n,原始的词变成机器学习可以理解的一些列的向量
解码器,词是一个一个生成的,自回归,auto-regressive
过去时刻的输出会作为当前的输入
解码器在做预测的开始是没有输入的,是解码器先前的输出会作为后来的输入
embeddeding 一个一个词表示成一个一个向量,
resnet残差块是个块,n个块摞在一起
Nx 多个transformer块堆在一起
一个多头注意力层加一个MLP(MLP就是前馈神经网络),中间有些残差连接,
残差连接需要输入和输出一样大小,不一样大小则需要投影,
CNN,空间维度往下减,kenel维度往上拉
输出维度512,固定长度来表示,方便 残差相加,使得模型更加简单
要多少层,每一层维度多大
batchNorm和layerNorm
layerNorm从transformer开始火
输入时二维的情况
在transformer和正常的RNN里面,输入往往是三维,一个序列的样本(一个batch),每个样本有很多的元素,每个元素由一个向量来表示(feature,设置成了统一的512)
batch是几句话,seq这句话里有多少词,feature是一个词的向量表示
layerNorm,切面代表一个句子,把每个样本归一化,算每个样本的均值和方差,相对来说更稳定一些,不用管每个样本长度不一致
batchNorm,切面代表一个特征,把特征归一化
从而保证训练和预测的时候行为是一致的,不让他作弊看到本应该由他自己预测出来的东西
输出就是value的加权和
加型的注意力机制,处理query和key不等长的情况
点积的注意力机制和 scale dot product很像,后者除了根号dk,向量长度比较长,做点积,值可能会比较大或者比较小,值比较大的时候,相对差距变大,最大的那个值softmax之后更加趋近于1,剩下的更加趋近于0,像两端靠拢,算梯度,梯度比较小,跑不动
注意力机制
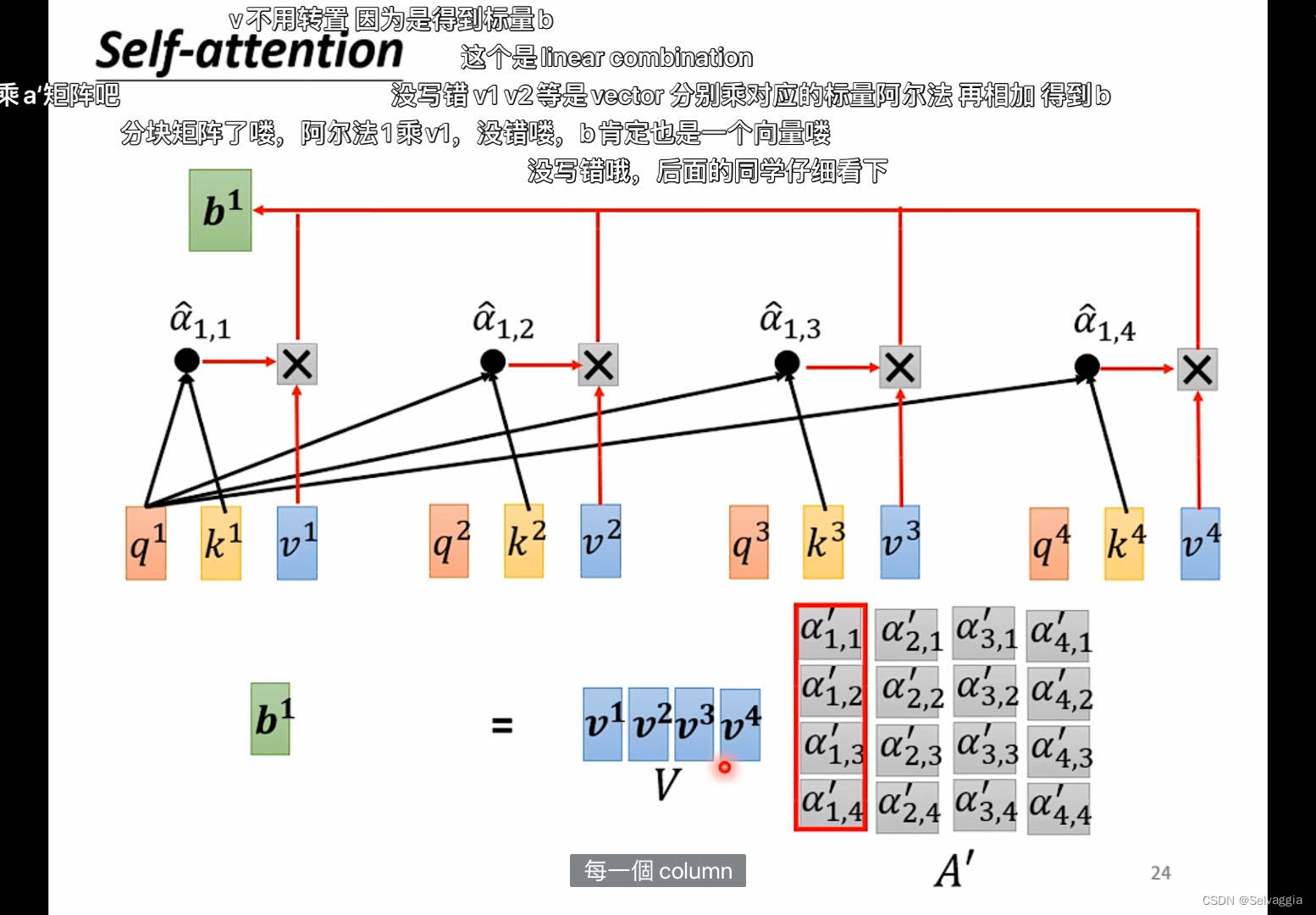
v的加权和
q和k更相近,k对应的v的加权就更大
权重对应着给的query和 v对应的k 的相似度
kv不变,query变,权重的分配会改变
不同的相似函数导致不同的注意力版本,dot product
pn是字母识别错误,其实是批量
这里应该是bn,batch size,理解为一个样本
假设bn为1
kqv是一样的东西就是自注意力机制
kv来自编码器的输出,q来自解码器下一个attention的输入
解码的时候是根据输入序列去预测它的下一个输出,相当于一个一个解码,编码的时候只需要将完整的序列输入进去做编码就可以
按计算顺序说“上一层”比较好,老师说下一层指的是图上的下一层
编码器的输出作为kv
解码器上一层的输出作为query
去编码器的输出里挑我感兴趣的东西
attention在编码器和解码器传递信息的时候起到的作用
mlp
对序列中每个词position wise做mlp再输出
MLP 就是FFN嘛
attention就是把序列中的信息抓取出来,做一次汇聚
做投影,mlp的时候,映射成我更想要的语义空间
做完attention已经拥有了想要的序列信息,mlp只要point wise对每个点做独立做就好
这个地方序列信息已经被汇聚完成
相当于每一个小蓝块都已经包含了整个序列的信息?就相互独立了?
我靠,清晰!!!!醍醐灌顶,一直不理解Position-wise啥意思
可以分开做mlp
因为前面已经考虑整个序列的信息做成输出了 因此做mlp时不需要再去考虑多个输出向量
transformer抽取序列信息,把这些信息加工成我想要的语义空间那个向量
MLP其主要作用是提取输入序列的非线性特征,并提高模型的表达能力 不太对
以下更合理
mlp应该是增强信息的泛化能力,即在抽象层面表示更多信息。
我的理解是原向量在经过self attention加工之后已经融合了全部序列的语义信息,因此没必要再考虑它的上下文信息,后面添加的MLP就相当于一个普通的分类神经网络,对每一个加工之后的向量做一个映射
transformer和RNN传递序列信息
MLP一个作用是加了非线性,因为attention里面没有非线性,第二个作用是特征提取
CNN没有隐藏层的mlp就是纯线性层
上一次的输出和当前的输入 一起作为 输入
都是用mlp来进行语义空间的转换,不一样的是怎么传递序列信息
transformer拉到整个全局的序列信息
CNN是利用上一个时刻的输出 一起作为当前的输入
rnn的序列信息提取是通过"状态转移"权重矩阵表达的,attention是通过向量映射矩阵表达的
讲得太好了,transformer就是先做空间相关性再做频道相关性(这里频道维度增加可以提高表示能力)。
2. Decoder output (维度为1xd_model)->Linear (d_modelxV大小参数矩阵)->维度为1xV的vector->Softmax->最大值位置即对应词在词库中的索引
3. 这里说的share the same weight matrix,就表示Embedding Layer和Linear Layer中的参数矩阵是一样的
就是softmax前的linear层,用的权重矩阵和embedding层共享(因为维度是一样的)
embedding之后维度越大的向量归一化后其单个值就越小,乘个根号512
学习embedding时可能会把每个向量的L2Norm 学得相对比较小(1. L2 Norm会将向量的所有值归一化,2. 维度越大的向量归一化后其单个值就越小,3. 而时序信息是递增的整数(往后看会讲),4. 为了让它们的规模相匹配,故而乘了一个根号d给前面),如果维度较大,学到一些权重 值就会变小,乘以根号d后放大,使得和PE相加 时二者在scale上差不多
也就是说,把embedding的结果变小一些,给后面加位置编码腾地方
就是让这两个东西值差的别那么大,防止pos encoding作用效果覆盖了原本emdeding
权重经l2正则化以后都比较小,维度越大权重会越小,为了让它能跟位置编码一个维度,乘了根号512
position encoding加入时序信息
attention这个东西不具有时序信息,打乱单词顺序之后attention不变,在输入加入时序信息,position encoding
position encoding是cos和sin的复合函数,在1和负一直接抖动
embedding乘上根号d也是为了让embeding向量里每个数字在正负一数值区间里
直接相加
在输入里面也加入了信息
小的embedding更难学习,对positional encoding也更敏感,模型不稳定
就是两个一样的单词出现在不同的位置, 加上position向量就不一样了, 但是也不会与其他词重复; 然后两个相邻的词虽然本身不一样, 但是加上position相似度会更大
相比于循环层卷积层,用自注意力机制是多么好
在colab上试着安装mmocr,运行了一下给的demo
看李沐老师transformer逐段精读看transformer论文