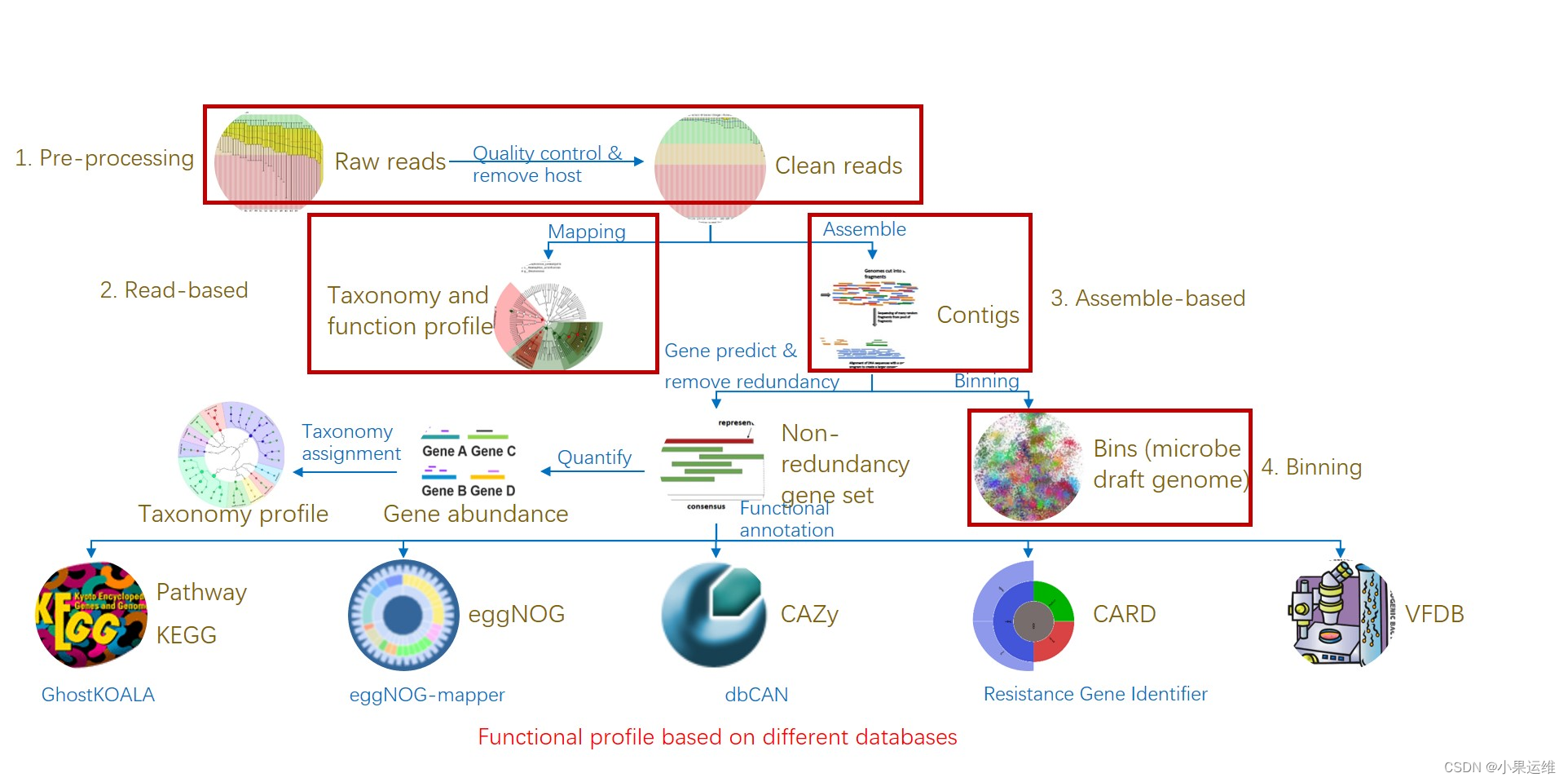
redis-cluster集群
redis3.0引入的分布式存储方案
集群由多个node节点组成,redis数据分布在这些节点当中。
在集群之中分为主节点和从节点
集群模式当中,主从一一对应,数据的写入和读取与主从模式一样,主负责写,从只能读,
集群模式自带哨兵模式,可以自动实现故障切换,但是在故障切换完成之前,整个集群都将不可用。切换完毕之后,集群会立刻恢复。
集群模式按照数据分片:
1、数据分片:是集群的核心功能,每个主都可以对外提供读、写的功能,但是数据是一一对应写入主的对应从节点。在集群模式中,可以容忍数据的不完整。
2、高可用:集群的主要目的。
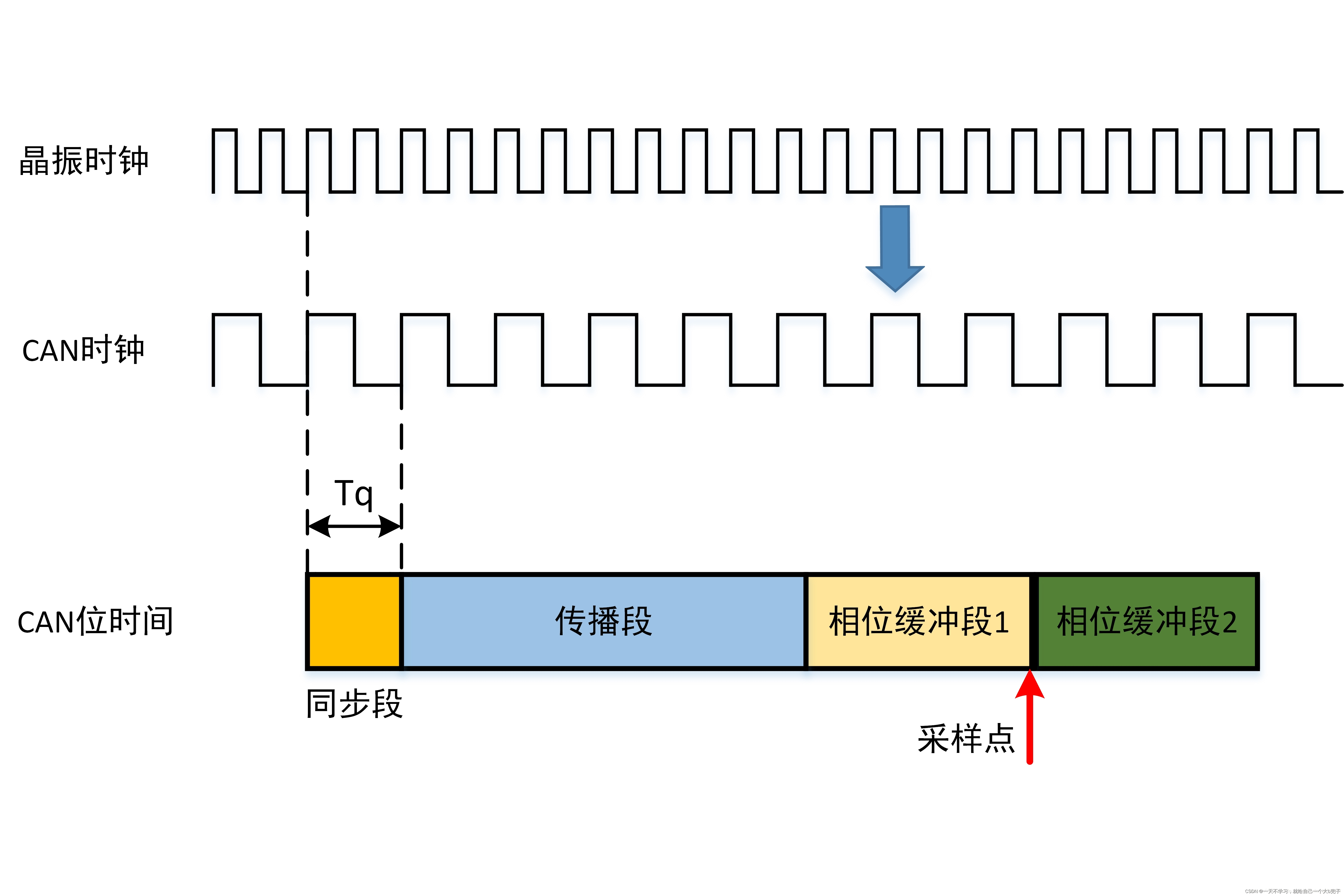
数据分片的实现:
redis的集群引入了哈希槽的概念。
在redis集群当中,一共有16384个哈希槽位。(0-16383)
根据集群当中的主从节点数,分配哈希槽位,每个主从节点只负责一部分哈希槽位。
每次读写都涉及到哈希槽位,key通过CRC16校验之后,对16384取余数,余数值决定数据放入哪个哈希槽位。通过这个值去找到对应的哈希槽位所在地节点,然后直接跳转到这个节点进行存取操作。
注:主从节点的哈希槽位的值是连续的,如果出现不连续的哈希值,或者有哈希槽位没有被分配,整个集群将会报错。
主从复制的意义:主宕机之后,主节点原来复制的哈希槽将会不可用,需要从节点代替主节点继续负责原有的哈希操作。保证集群正常工作。
故障切换的过程中,会提示集群不可用,切换完成集群恢复继续工作。
redis-cli -h 192.168.233.7 --cluster create (所有ip地址) --cluster-replicas1
replicas 1:规定一个主只有一个从。
主从的配合是随机分配的。
在集群模式当中,只能选择0库,集群模式不能切换库,只能使用默认库。
Adding replica 192.168.233.15:6379 to 192.168.233.7;6379
Adding replica 192.168.233.16:6379 to 192.168.233.8;6379
Adding replica 192.168.233.17:6379 to 192.168.233.9;6379
(error)MOVED 4768.192.168.233.7:6379
表名客户端尝试读取键值对test1,但是实际槽位在4768,集群要求客户端移动到4768所在的主机节点,获取数据。
append-only yes 初始化库之后为空,否则会报错
集群流程:
1、集群自带主从和哨兵
2、每个主从节点之间相互隔离的,可以容忍数据的不完整。目的:高可用。
3、哈希槽位决定每个节点的读写操作,在创建key时,系统已经分配好了指定槽位。
4、MOVED不是报错,只是提醒客户端去分配的槽位节点,获取数据。
proxy.responses 1;在集群之中只要有一个节点响应,然后代理服务器就会把响应传递给客户端,可以增加整个系统的稳定性。
只要有一个节点可以响应,那么客户端就可以继续发起请求
四层转发:ip+端口
四层:全局配置
string四层
upstring七层(http)--->做反向代理
nginx可以提供多端口服务(80、6379...)
ELK日志分析系统:
ELK是一套完整的日志集中处理方案,由三个开源的软件简称组成
E:ElasticSearch:ES是一个开源的,分布式的存储检索引擎(索引型的非关系型数据库。)存储日志。(分片索引的形式存储)
Java代码开发的。基于Lucene结构开发的一套全文检索引擎。拥有一个web接口。用户可以通过浏览器的形式和ES组件进行通信。
作用:存储,允许全文搜索,结构化搜索(索引点),索引点可以支持大容量的日志数据。也可以搜索所有不同类型的文档。
K:kiabana图形化界面。可以更好的分析存储在ES上的日志数据。提供了一个图形化的界面,来浏览ES上的日志数据。汇总、分析、搜索。(方便用户检索)
L:Logstash:数据收集引擎(收集、处理),支持动态的(实时的)从各种服务应用收集日志资源,还可以对收集到的日志数据进行过滤、分析,丰富,统一格式等待操作。然后把数据同步到es存储引擎。(分析、过滤)
RUBY语言编写的,运行在Java虚拟机上的一个强大的数据处理工具。数据传输,格式化处理,格式化输出。主要用来处理日志。
数据处理工具:
filebeat:轻量级的开源的,日志数据工具。收集的速度较快,但是没有数据分析和过滤的能力,一般是结合logstash一块使用
Kafka
RabbitMQ:中间件消息队列
总结:ELK的作用,当我们管理一个大集群时,需要分析和定位的日志就会很多,每一台服务器分别去分析,将会耗时耗力。所以我们应运而生了一个集中的统一的日志管理和分析系统。极大地提高的定位问题的效率。
日志收集的特征:
1、收集,可以收集基本上市面上常用的软件日志。
2、传输,收集到的日志需要发送到ES上
3、存储:es负责存储数据
4、UI:图形化界面(Kiabana)
三台主机:
es1:20.0.0.100
es2:20.0.0.120
logstash+kiabana:20.0.0.121(4核8G)
三台组件,每台最少要2核4G
ELK的版本(6.7.2)6、7版本主流
修改elasticsearch主配置文件
cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak
vim /etc/elasticsearch/elasticsearch.yml
--17--取消注释,指定集群名字
cluster.name: my-elk-cluster
--23--取消注释,指定节点名字:Node1节点为node1,Node2节点为node2
node.name: node1
node.master: true #是否master节点,false为否
node.data: true #是否数据节点,false为否
--33--取消注释,指定数据存放路径
path.data: /var/lib/elasticsearch
--37--取消注释,指定日志存放路径
path.logs: /var/log/elasticsearch
--43--取消注释,避免es使用swap交换分区
bootstrap.memory_lock: true
--55--取消注释,设置监听地址,0.0.0.0代表所有地址
network.host: 0.0.0.0
--59--取消注释,ES 服务的默认监听端口为9200
http.port: 9200 #指定es集群提供外部访问的接口
transport.tcp.port: 9300 #指定es集群内部通信接口
--68--取消注释,集群发现通过单播实现,指定要发现的节点
discovery.zen.ping.unicast.hosts: ["192.168.233.12:9300", "192.168.233.13:9300"]
vim elasticsearch.yml
bootstrap.memory_lock:true 禁止es使用交换分区
network.host :0.0.0.0 监听地址0.0.0.0代表所有地址
http.port:9200 对外提供访问的端口
transport.tcp.port:9300 ES内部通信的端口
path.data: /var/lib/elasticsearch 指定数据存放路径
path.data: /var/log/elasticsearch 指定日志存放路径
discovery.zen.ping.unicast.hosts: ["node1", "node2"]
集群发现通过单播实现,指定要发现的节点或者地址 ["192.168.233.12:9300"," "].
grep -v "^#" 检查一下
/var/log/ElasticSearch 如果有错,看日志
es的性能调优:(第一次搭建时需要优化的)
修改打开的最大内存大小和最大文件数(对机器)
vim /etc/security/limits.conf
* soft nofile 65536(软限制)
* hard nofile 65536(硬限制)
* soft nproc 32000 (内存使用量限制)
* hard nproc 32000
* soft memlock unlimited
* hard memlock unlimited
优化系统配置文件(对用户)
vim /etc/systemd/system.conf
DefaultLimitNOFILE=65536
一个用户会话的默认最大文件描述符的限制量。
文件描述符:用于标识打开文件或者I/O资源限制的整数。
DefautLimitNPROC=32000
一个用户可以打开的最大进程数量的限制32000.一个用户的终端可以运行多少个进程。
DefautLimitMEMLOCK=infinity
一个用户的终端默认锁定内存的限额,不限制
以上配置都需要重启主机才能生效
内核优化:
ES是基于lucene架构,实现一款索引型数据库。lucene可以利用操作系统的内存来缓存ES的索引数据。
提供更快的查询速度。在工作中我们会把系统的一半内存留给lucene。
机器内存小于64G,50%给es,50%给操作系统,供lucene使用。
机器内存大于64G,ES分配4~32G即可,其他的都给操作系统,供lucene。
vim /etc/sysctl.conf
vm.max_map_count=262144
一个进程可以拥有的最大内存映射区参数。
内存映射,将文件或者其他设备映射到进程地址空间的方法。允许进程直接读取或写入文件,无需常规的I/O方式。
映射空间越大,ES和lucene的速度越快。
2g/262144
4g/4194304
8g/8388608
http.cors.enabled: true
开启跨域访问支持,默认为 false
http.cors.allow-origin: "*"
开启跨域访问之后允许访问的域名地址*:所有
9100是可视化工具的访问端口;9200的ES数据库的访问端口。
logstash的命令常用选项:
-f 指定配置文件,根据配置文件识别输入和输出流。
-e 测试,从命令行当中获取输入,然后经过logstash加工之后,形成一个标准输出
-t 检测配置文件是否正确,然后退出。
logstash -e 'input { stdin{} } output { stdout{} }'
所有的键盘命令行输出,转化成标准输出(rubydebug的模式),6.0之后,logstash的默认输出格式就是rubydebug格式的标准输出。
logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["192.168.233.20:9200"] } }'
--path.data /opt/test1
区分不同的数据存放目录。
6.0之后的logstash自带的输出格式rubydebug,自动的把输出格式,定义为统一的标准格式输出。
rubydebug
在以前的版本需要手动配置
Nov 27 12:05:56 test1 logstash:2023-11-27T12:05:56.354[logstash.config.config.sourceloader] No configuration found in the configured sources.
没有找到适合的配置文件
elk:
es:存储数据,索引型的数据库
logstash:收集日志,然后按照标准化格式发送给ES(RUBYDEBUG的格式)。
K:可视化工具。更人性化的显示用户信息,方便用户检索查询
http的日志,写一个nginx的logstash的配置收集文件(要使用json的格式)
elfk:filebeat 日志收集工具 和logstash相同。
filebeat是一个轻量级的日志收集工具,所使用的系统资源比logstash部署和启动时使用的资源要小的多。
filebeat可以运行在非java环境,他可以代替logstash在非java环境上收集日志。
filebeat无法实现数据的过滤,一般是结合logstash的数据过滤功能一块使用。
filebeat收集的数据可以发往多个主机。也就是远程收集。
filebeat负责收集
logstash过滤,形成标准输出给es(logstash默认接收的端口5044)
nohup ./filebeat -e -c filebeat/yml > filebeat.out &
nohup 表示在后台记录执行命令的过程
./filebeat 运行文件
-e 使用标准输出的同时进行syslog文件输出
-c 指定配置文件
执行过程输出到filebeat.out这个文件当中,&后台运行。
logstash收集日志的过程:
input(从哪里收集)
filter(过滤)
output(发送es实例)
enabled:true
paths:
本地收集:
远程收集,远程收集多个日志。
logstash可以使用任意端口,只要没被占用都可以使用,推荐1024之后开始。
5044
5045
5046
logstash性能上的优化:logstash启动是在jvm虚拟机当中启动,启动一次至少要占500M内存。
pipeline.workers:2
logstash的工作线程,默认值就是CPU数,4核给2个 8 4 给一半即可 2核,2个。
pipeline.batch.size:125
一次性能够批量处理检索事件的大小,125条数。200
pipeline.batch.delay:50
查询更新的延迟。50毫秒,也可以自行调整。 15 10 也要看机器性能。
ELFK
logstash之外,filebeat
fluentd
EFK
代替logstash,实现EFK。fluentd(老一点的logstash,新型项目用fluentd)
zookeeper集群+kafka集群:
kafka在3.0版本之前依赖于zookeeper。
zookeeper是一个开源,分布式的架构。提供协调服务(Apache项目)
基于观察者模式涉及的分布式服务管理架构。
存储和管理数据。分布式节点上的服务接受观察者的注册。一旦分布式节点上的数据发生变化,由zookeeper负责通知分布式节点上的服务。
zookeeper:分为领导者 追随者 leader follower组成的集群
特点:
只要有一半以上的集群存活,zookeeper集群就可以正常工作。
适用于安装奇数台的服务集群。全局数据一致,每个zookeeper的节点都保存相同的数据。维护监控服务的数据一致性。
数据更新的原子性。要么都成功,要么都失败。
实时性,只要有变化,立刻同步。
zookeeper的应用场景:
1、统一命名服务,在分布式的环境下,对所有的应用和服务进行统一命名。
2、统一配置管理,配置文件同步,kafka的配置文件被修改,可以快速同步到其他节点。
3、统一集群管理,实时掌握所有节点的状态。
4、服务器动态上下线、
5、实现负载均衡,把访问的服务器的数据,发送到访问最少的服务器处理客户端的请求。
领导者和追随者:zookeeper的选举机制
以3台服务器为例:A B C
A先启动,发起第一次选举,投票投给自己,3台,但是只有1票,不满足半数,A的状态的looking。
B启动,再发起一次选举,A和B分别投自己一票,交换选票信息,myid,A发现B的myid比A大,A的这一票会转而投给B。A 0 B 2 没有半数以上的结果,A B会进入looking。B有可能成为leader。
C启动,MYID c的myid最大 A和B都会把票投给C A 0 B 0 C 3
C的状态变为leader,A和B都变成follower。
D myid4
只要leader确定,后续加入的服务器都是追随者。
只有两种情况才会开启选举机制:
1、初始化的情况会发生选举
2、服务器之间的leader丢失了连接状态。
leader已经存在,建立连接即可
leader不存在,leader不存在。
1、服务器ID大的胜出。
2、EPOCH大,直接胜出。
3、EPOCH相同,事务ID大的胜出。
EPOCH 每个leader任期的代号,没有leader,大家的逻辑地位是相同的,每投完一次之后,数据是递增的。 2 3
事务id,标识服务器的每一次变更,每变更一次,事务ID变化一次。
服务器ID,zookeeper集群当中的机器都有一个ID,每台机器不重复,和myid保持一致。
zookeeper+kafka(2.7.0)
kafka(3.4.1)
zookeeper+kafka(2.7.0)实现过程:
192.168.233.10 zookeeper+kafka
192.168.233.20 zookeeper+kafka
192.168.233.30 zookeeper+kafka
2核/4G
配置文件
cd /usr/local/zookeeper-3.5.7/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
tickTime=2000
服务器与客户端之间的心跳时间,2秒检测一次服务器和客户端之间的通信。
initLimit=10
领导者和追随者之间,初始连接时,能够容忍的超时时间 10*2s
syncLimit=5
同步超时时间,领导者和追随者之间,同步通信超时的时间,5*2s,leader会认为follower丢失,移出集群。
dataDir=/opt/zookeeper/data
dataLogDir=/opt/zookeeper/logs
保存数据的目录,需要单独创建
server.1=192.168.233.10:3188:3288
server.2=192.168.233.20:3188:3288
server.3=192.168.233.30:3188:3288
最后添加整个集群的信息
1.每个zookeeper的初始myid。
192.168.233.10:服务器的ip地址
3188:领导者和追随者之间交换信息的端口(内部通信的端口)
3288:一旦leader丢失响应,开启选举,3288就是用来执行选举时的服务器之间的通信端口。
消息队列:kafka
为什么要引入消息队列(MQ),他也是一个中间件。在高并发环境下,同步请求太多,来不及处理。来不及处理的请求会形成阻塞。
比方说数据库就会形成行锁或者表锁。请求线程满了,超标了,too many connection。会引发整个系统雪崩。消息队列的作用就体现出来了。
消息队列的作用:异步处理请求。流量削峰,应用解耦。
解耦:
耦合:在软件系统当中,修改其中一个组件需要修改所有其他组件。高度耦合。
低度耦合:修改其中一个组件,对其他组件影响不大,无需修改所有。
A B C
只要通信保证,其他的修改不影响整个集群,每个组件可以独立的扩展,修改,降低组件之间的依赖性。
依赖点就是接口约束,通过不同的端口,保证集群通信即可。
特点
可恢复性:系统当中有一部分组件消失,不影响整个系统。也就是说在消息队列当中,即使有一个处理消息的进程失败,一旦恢复,还可以重新加入到队列当中,继续处理消息。
缓存机制:可以控制和优化数据经过系统的时间和速度,解决生产消息和消费消息处理速度不一致的问题。
峰值的处理能力:消息队列在峰值的情况之下,能够顶住突发的访问压力。避免专门为了突发情况而对系统进行修改。
异步通信(kafka核心):允许用户把一个消息放入队列,但是不立即处理,等用户想处理的时候再处理。
消息队列的模式:
点对点 一对一:消息的生产者发送消息到队列中,消费者从队列当中提取信息,消费者提取完之后,队列中被提取的消息将会被移除。后续的消费者不能再消费队列当中的消息。消息队列可以有多个消费者,但是一个消息,只能由一个消费者提取。
如:RABBITMQ
发布/订阅模式:一对多,又叫做观察者模式,消费者提取数据之后,队列当中的消息不会被清除。
生产者发布一个消息到主题,所有的消费者都是通过主题来获取消息。
主题:topic topic类似一个数据流的管道,生产者把消息发布到主题。消费者从主题当中订阅数据。主题可以分区,每个分区都有自己的偏移量。
分区:partition 每个主题都可以分成多个分区。每个分区是数据的有序子集。分区可以运行kafka进行水平拓展,以处理大量的数据。
消息在分区中按照偏移量存储,消费者可以独立读取每个分区的数据。
偏移量:是每个消息在分区当中的唯一的标识。消费者可以通过偏移量来跟踪获取已读或者未读消息的位置。也可以通过提交偏移量,来记录已处理的信息。
消费方式:
第一种,begin从头开始,消费所有
第二种,实时获取,我只消费,后续产生的消息
第三种,指定偏移量,(指定从哪个位置开始消费),要通过代码实现。
生产者:producer 生产者把数据发送到kafka的主题当中,负责写入消息。
消费者:consumer 从主题当中读取数据,消费者可以是一个也可以是多个。每个消费者有一个唯一的消费组ID,kafka通过消费者实现负载均衡和容错性。
经纪人:Broker 每个kafka节点都有一个Borker,每个经纪人负责一台服务器,id唯一,存储主题分区当中的数据,处理生产和消费者的请求。
维护元数据(zookeeper) 3.0之前.
zookeeper:zookeeper负责保存元数据,元数据就是topic主题的相关信息,(发在哪台主机上,指定了多少分区,以及副本数,偏移量)。
zookeeper自建一个主题:_consumer_offsets。
3.0之后不依赖zookeeper的核心,元数据由kafka节点自己管理。
kafka的工作流程:

至少一次语义:只要消费者进入,确保消息至少被消费一次。
num.network.threads=3
处理网络请求的线程数量,默认即可
num.io.threads=8
处理磁盘的IO线程数量,一定要比硬盘数大。
socket.send.buffer.bytes=102400
发送套接字的缓冲区大小。
socket.receive.buffer.bytes=102400
接受者接受套接字缓冲区的大小。
socket.request.max.bytes=104857600
请求套接字的缓冲区大小,单位字节
log.dirs=/var/log/kafka
指定收到的日志目录
num.partitions=1
在此kafka服务器上创建topic,默认分区数。如果指定了,这个配置无效。
num.recovery.threads.per.data.dir=1
用来恢复,回收,清理data下的数据的线程数量。kafka默认是不允许删除主题的。
log.retention.hours=168
生产者发布的数据文件在主题当中保存的时间。168小时,默认是7天。
Kafka 命令行操作
一定要在/usr/local/kafka/bin路径上进行操作
kafka-topics.sh --create --zookeeper 20.0.0.120:2181,20.0.0.121:2181,20.0.0.122:2181 --replication-factor 2 --partitions 3 --topic test1
创建主题:(创建主题一定要有分区、有分区一定要有副本)
1、在kafka的bin目录下,是所有的kafka可执行命令文件
2、--zookeeper 指定的是zookeeper的地址和端口,保存kafka的元数据
3、--replication-factor 2 定义每个分区的副本数
4、partitions 3 指定主题的分区数
5、--topic test1 指定主题的名称。
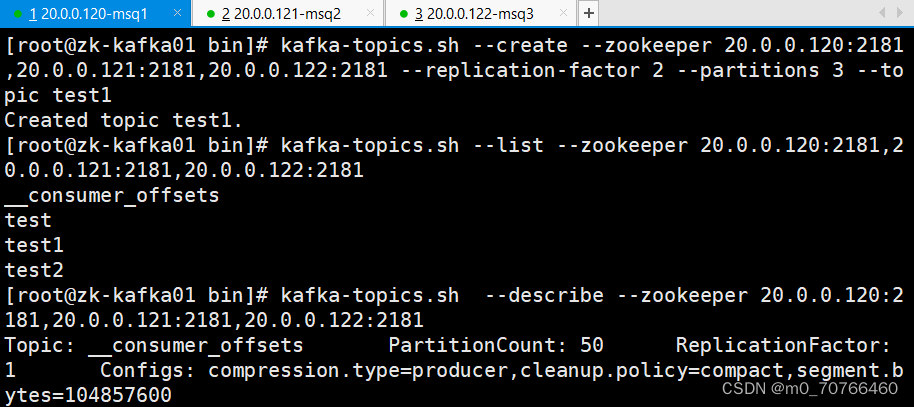
查看当前服务器中的所有 topic
kafka-topics.sh --list --zookeeper 192.168.233.10:2181,192.168.233.20:2181,192.168.233.30:2181
查看某个 topic 的详情
[root@test1 efak]# kafka-topics.sh --describe --zookeeper 192.168.233.10:2181,192.168.233.20:2181,192.168.233.30:2181
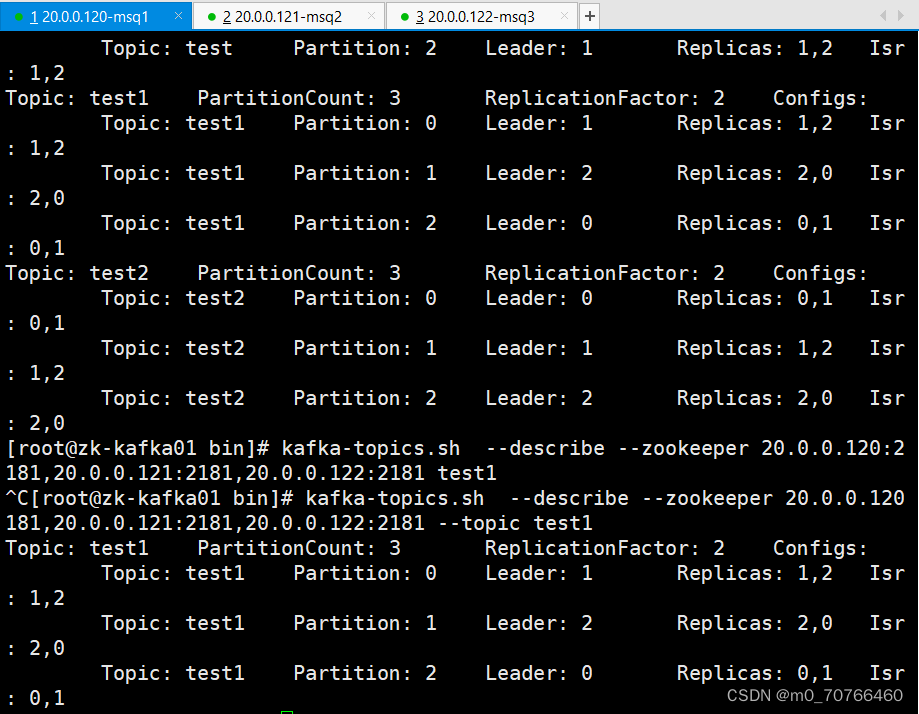
Topic: test3 PartitionCount: 3 ReplicationFactor: 2 Configs:
Topic: test3 Partition: 0 Leader: 3 Replicas: 3,1 Isr: 3,1
Topic: test3 Partition: 1 Leader: 1 Replicas: 1,3 Isr: 1,3
Topic: test3 Partition: 2 Leader: 3 Replicas: 3,1 Isr: 3,1
Partition:分区编号
Leader:每个分区都有一个领导者(Leader),领导者负责处理分区的读写操作。
在上述输出中,领导者的编号分别为 3、1、3。
Replicas:每个分区可以有多个副本(Replicas),用于提供冗余和容错性。
在上述输出中,Replica 3、1、2 分别对应不同的 Kafka broker。
Isr:ISR(In-Sync Replicas)表示当前与领导者保持同步的副本。
ISR 3、1分别表示与领导者同步的副本。
先做地址映射:
vim /etc/hosts
20.0.0.120 test1
20.0.0.121 test2
20.0.0.122 test3
发布消息
kafka-console-producer.sh --broker-list 192.168.233.10:9092,192.168.233.20:9092,192.168.233.30:9092 --topic test1
消费消息
kafka-console-consumer.sh --bootstrap-server 192.168.233.10:9092,192.168.233.20:9092,192.168.233.30:9092 --topic test1 --from-beginning
-------------------------------------------------------------------------------------
--from-beginning:会把主题中以往所有的数据都读取出来
-------------------------------------------------------------------------------------
[root@test1 config]# kafka-topics.sh --describe --zookeeper 192.168.233.10:2181,192.168.233.20:2181,192.168.233.30:2181
Topic: __consumer_offsets PartitionCount: 50 ReplicationFactor: 1 Configs: compression.type=producer,cleanup.policy=compact,segment.bytes=104857600
Topic: test1 PartitionCount: 3 ReplicationFactor: 2 Configs:
Topic: test1 Partition: 0 Leader: 3 Replicas: 3,1 Isr: 3,1
Topic: test1 Partition: 1 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: test1 Partition: 2 Leader: 2 Replicas: 2,3 Isr: 2,3
Topic: test2 PartitionCount: 3 ReplicationFactor: 2 Configs:
Topic: test2 Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: test2 Partition: 1 Leader: 2 Replicas: 2,3 Isr: 2,3
Topic: test2 Partition: 2 Leader: 3 Replicas: 3,1 Isr: 3,1
__consumer_offsets 主题的作用是记录每个消费者组中每个消费者在每个分区上的偏移量。
这样,当消费者组中的消费者重新加入或者新的消费者加入时,它们可以从上次提交的偏移量处继续消费消息,
而不会重复消费或错过消息。
__consumer_offsets 主题的作用是记录每个消费者组中每个消费者在每个分区上的偏移量。
这样,当消费者组中的消费者重新加入或者新的消费者加入时,它们可以从上次提交的偏移量处继续消费消息,
而不会重复消费或错过消息。
请注意,对于这个主题,配置为 Replication Factor 为 1 可能会对高可用性造成一些影响。
在生产环境中,通常会将 __consumer_offsets 主题的 Replication Factor 设置得更高,
以确保偏移量信息的可靠性。
修改分区数
kafka-topics.sh --zookeeper 192.168.233.10:2181,192.168.233.20:2181,192.168.233.30:2181 --alter --topic test1 --partitions 6
删除 topic
kafka-topics.sh --delete --zookeeper 192.168.233.10:2181,192.168.233.20:2181,192.168.233.30:2181 --topic test1
你提到的 "Note: This will have no impact if delete.topic.enable is not set to true."
是关于删除 Kafka 主题的一个重要提示。默认情况下,Kafka 集群禁用了主题删除操作,为了确保不会意外删除数据。
在 Kafka 中,要执行主题删除操作,需要确保 delete.topic.enable 配置项被设置为 true。
这个配置项决定了是否允许删除主题。如果没有设置或设置为 false,即使你执行了删除主题的命令,
实际上也不会删除主题,而只是标记主题为 "marked for deletion"。
1、zookeeper:主要是分布式,观察者模式,统一各个服务器节点的数据。
在kafka当中,收集保存kafka的元数据。
2、kafka消息队列 订阅/发布模式(点对点、一对一) 速度快
RABBIT MQ 轻量级(实现rabbit MQ消息队列)
数据流向