手把手教你搭建代理IP池:
项目简介:
爬虫代理IP池项目,主要功能为定时采集网上发布的免费代理验证入库,定时验证入库的代理保证代理的可用性,提供API和CLI两种使用方式。同时你也可以扩展代理源以增加代理池IP的质量和数量。
GitHub地址:
jhao104/proxy_pool: Python ProxyPool for web spider (github.com)
部署安装流程:
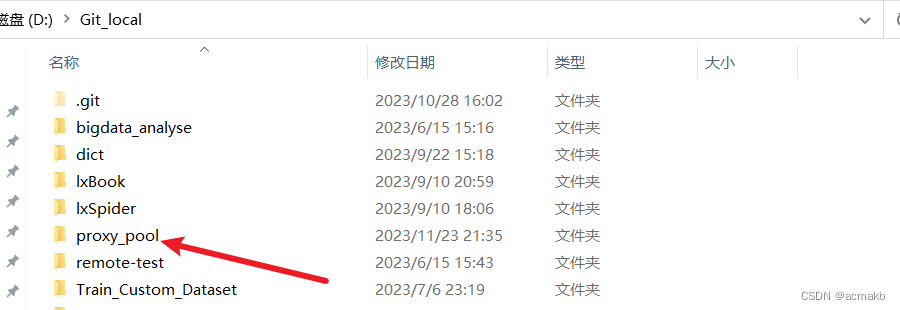
首先需要将git源码克隆到本地:
git clone git@github.com:jhao104/proxy_pool.git
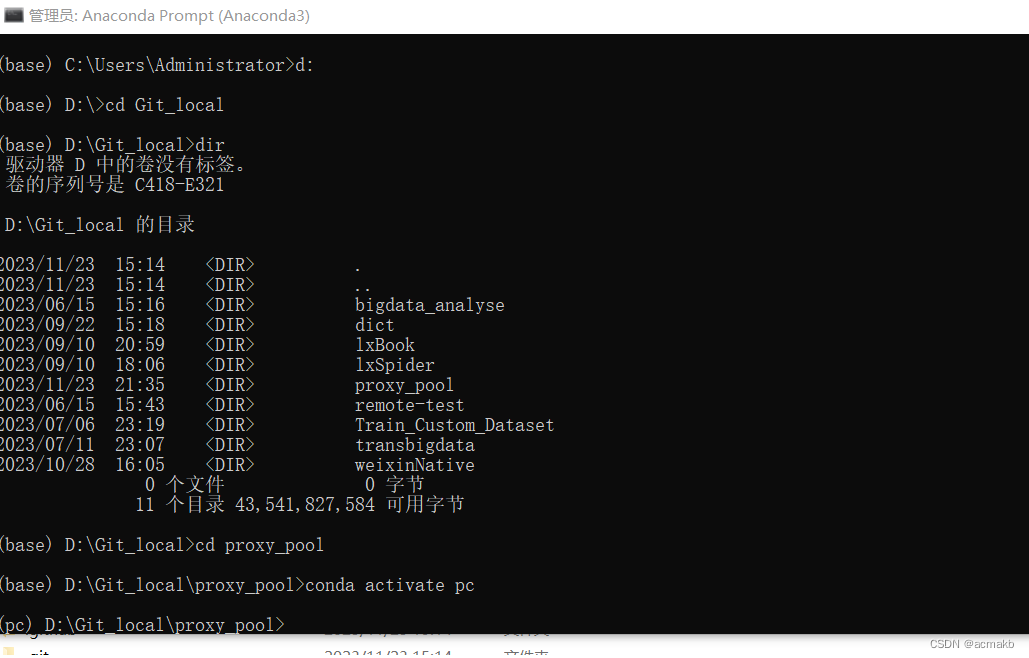
重新创建一个python虚拟环境,防止包依赖冲突:
conda create -n env_name python=x.x
conda create -n pc python=3.8

查看当前所有环境:
conda env list
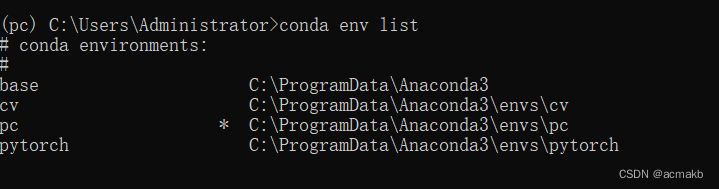
进入某个环境:
conda activate 环境名
conda activate pc

安装相关包:
找到项目所在的requirements.txt 所在的目录:
我的在:D:\Git_local\proxy_pool\requirements.txt
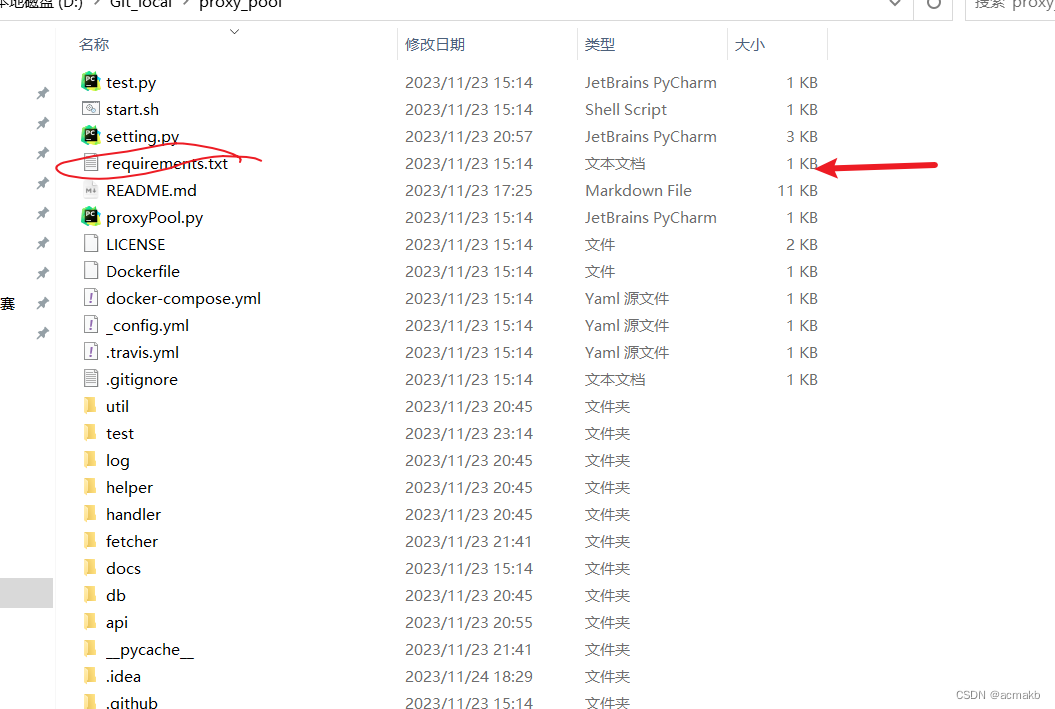
然后在环境里面输入:
pip install D:\Git_local\proxy_pool\requirements.txt
环境部署就成功了,很多GitHub的项目如果需要在本地运行都需要这样的操作,因为python的库之前存在依赖,必须是某个版本的才可以,不然就会冲突。
数据库配置:
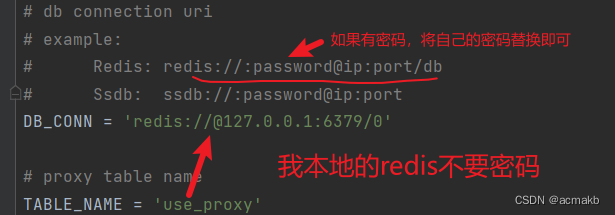
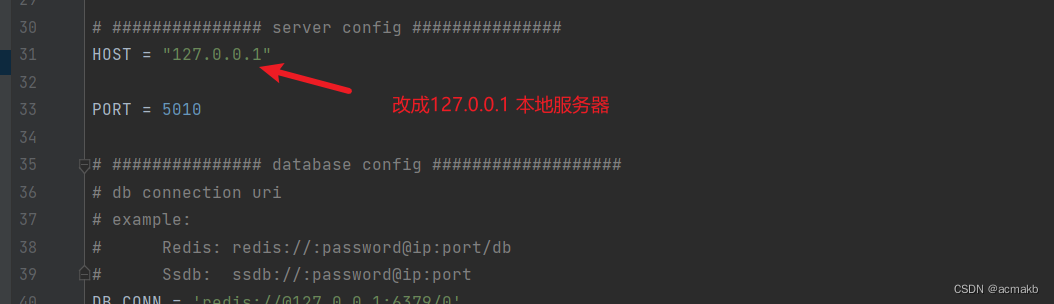
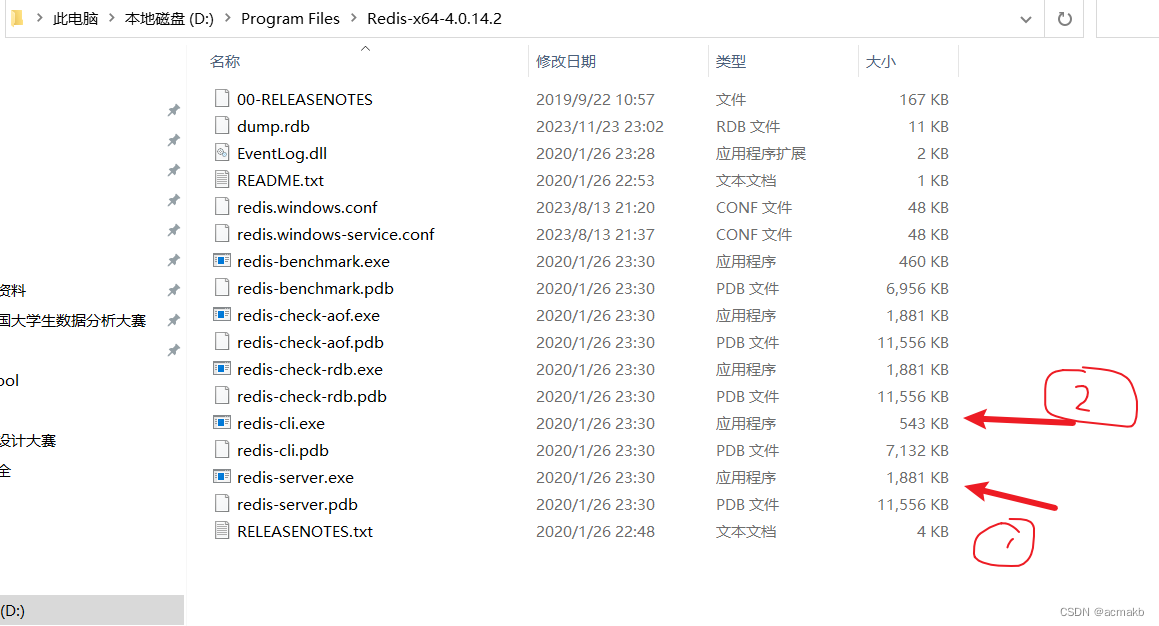
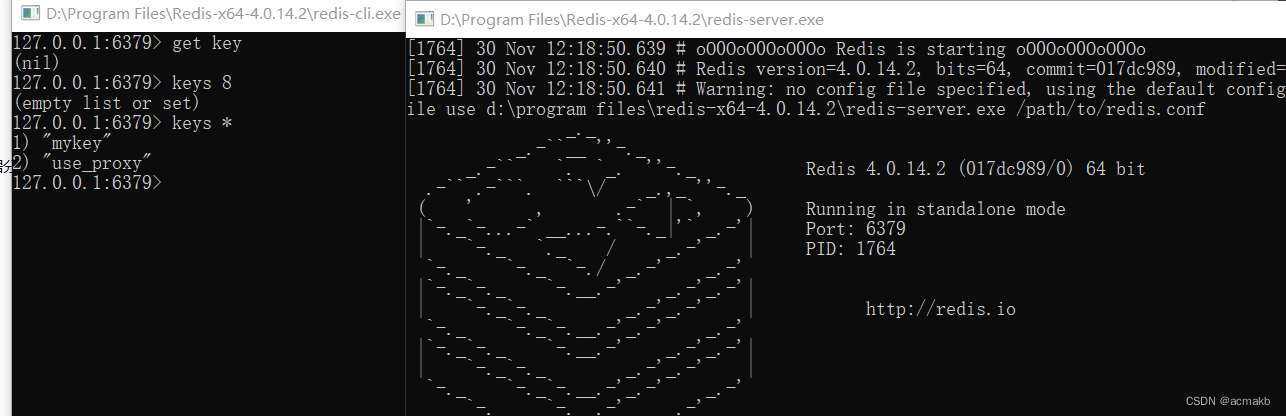
开启redis数据库:
注意先开启服务端,在开启客户端
启动项目:
# 如果已经具备运行条件, 可用通过proxyPool.py启动。
# 程序分为: schedule 调度程序 和 server Api服务
# 启动调度程序
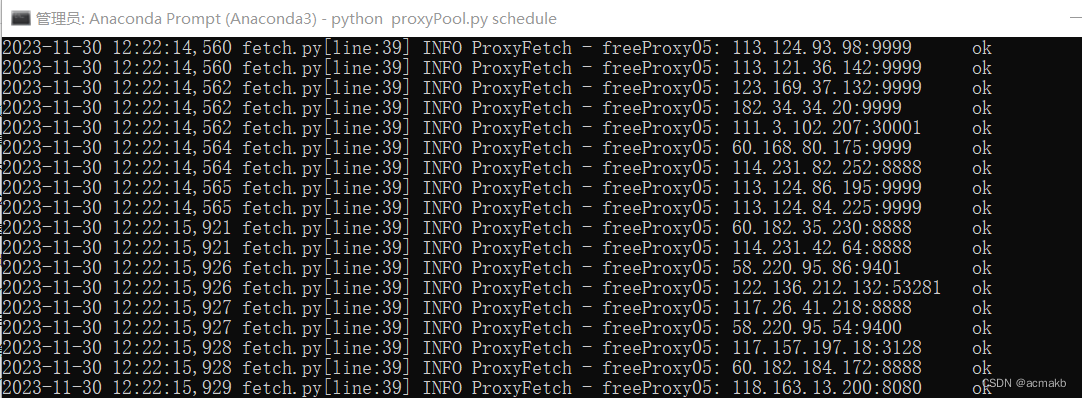
python proxyPool.py schedule
# 启动webApi服务
python proxyPool.py server
python proxyPool.py schedule
python proxyPool.py server
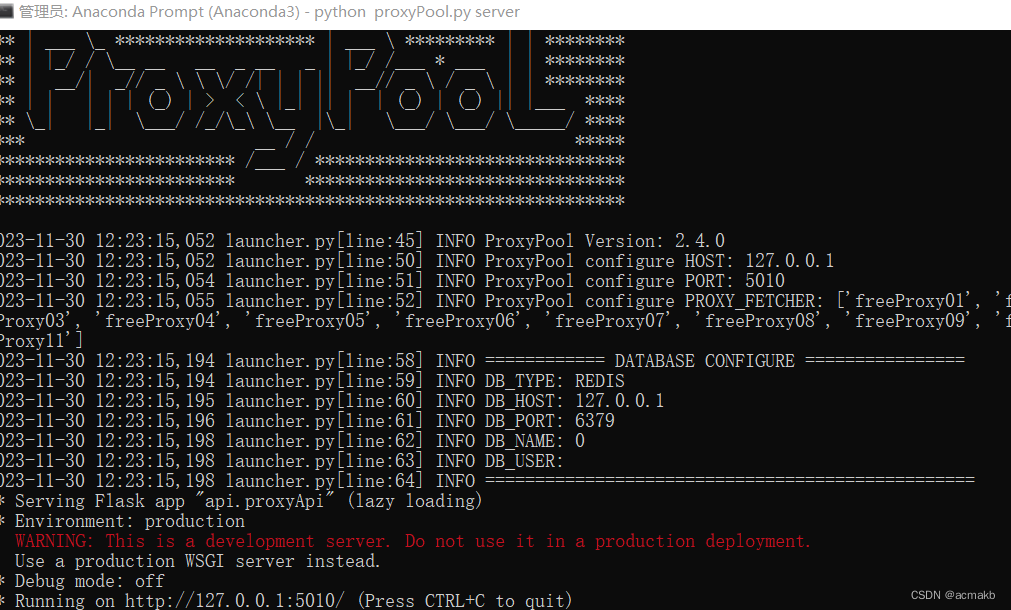
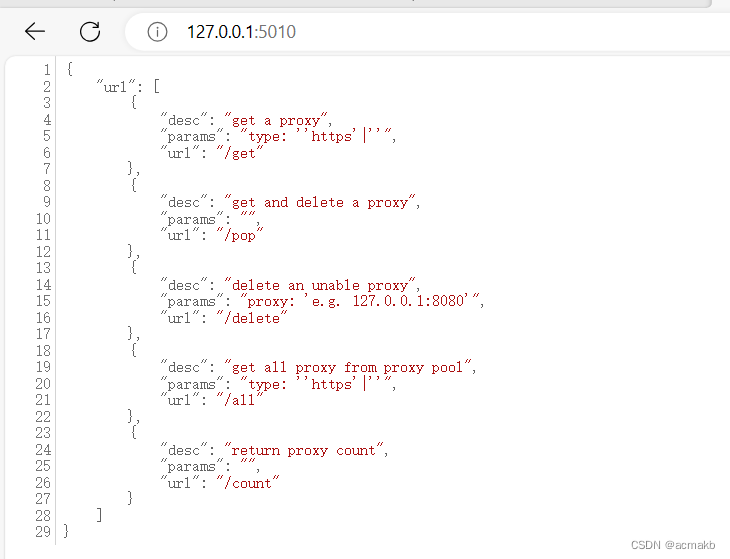
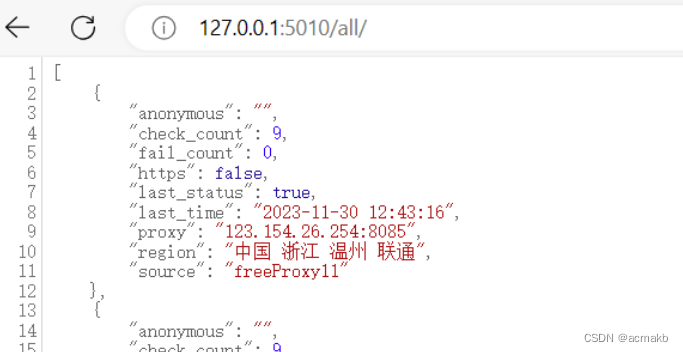
成功!!!
代码接口:
import requests
def get_proxy():
return requests.get("http://127.0.0.1:5010/get/").json()
def delete_proxy(proxy):
requests.get("http://127.0.0.1:5010/delete/?proxy={}".format(proxy))
# your spider code
def getHtml():
# ....
retry_count = 5
proxy = get_proxy().get("proxy")
while retry_count > 0:
try:
html = requests.get('http://www.example.com', proxies={"http": "http://{}".format(proxy)})
# 使用代理访问
return html
except Exception:
retry_count -= 1
# 删除代理池中代理
delete_proxy(proxy)
return None