视频课程地址:https://www.bilibili.com/video/BV1WY4y197g7
课程资料链接:https://pan.baidu.com/s/15KpnWeKpvExpKmOC8xjmtQ?pwd=5ay8
这里写目录标题
- 一、VMware准备Linux虚拟机
- 1.1. VMware安装Linux虚拟机
- 1.1.1. 修改虚拟机子网IP和网关
- 1.1.2. 安装Linux虚拟机
- 1.2. VMware克隆三台Linux虚拟机
- 1.3. 为三台虚拟机配置固定IP
- 1.4. 配置免密登录
- 1.5. JDK环境部署
- 1.6. 防火墙、SELinux、时间同步配置
- 1.6.1. 关闭防火墙
- 1.6.2. 关闭SELinux
- 1.6.3. 配置时间同步
- 1.7. 使用VMware快照功能保存当前已配置好的初始环境
- 二、在虚拟机里部署HDFS集群
- 2.1. 部署node1虚拟机
- 2.2. 部署node2和node3虚拟机
- 2.3. 初始化并启动Hadoop集群(格式化文件系统)
- 2.4. 快照部署好的集群
- 2.5. 部署过程中可能会遇到的问题
- 2.5. Hadoop HDFS集群启停脚本
- 三、使用HDFS文件系统
- 3.1. 使用命令操作HDFS文件系统
- 3.1.1. HDFS文件系统基本信息
- 3.1.2. HDFS文件系统的2套命令体系
- 3.1.3. 创建文件夹
- 3.1.4. 查看指定目录下的内容
- 3.1.5. 上传文件到HDFS指定目录下
- 3.1.6. 查看HDFS中文件的内容
- 3.1.7. 从HDFS下载文件到本地
- 3.1.8. 复制HDFS文件
一、VMware准备Linux虚拟机
1.1. VMware安装Linux虚拟机
VMware虚拟机安装程序下载地址(需要自己想办法激活):https://download3.vmware.com/software/WKST-1750-WIN/VMware-workstation-full-17.5.0-22583795.exe
CentOS操作系统镜像下载地址:https://vault.centos.org/7.6.1810/isos/x86_64/CentOS-7-x86_64-DVD-1810.iso
1.1.1. 修改虚拟机子网IP和网关
下载后,先安装VMware虚拟机,安装成功后,需改虚拟机网络配置。
1、在“编辑”-“虚拟网络编辑器”中修改NAT8网卡的子网IP地址;
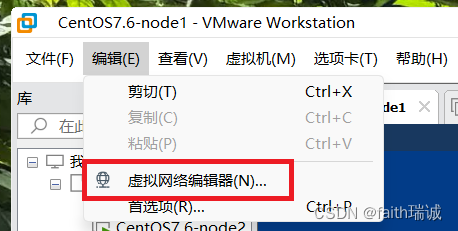
2、进入编辑器后,选择“VMnet8”网卡,然后点击右下角的“更改设置”按钮;
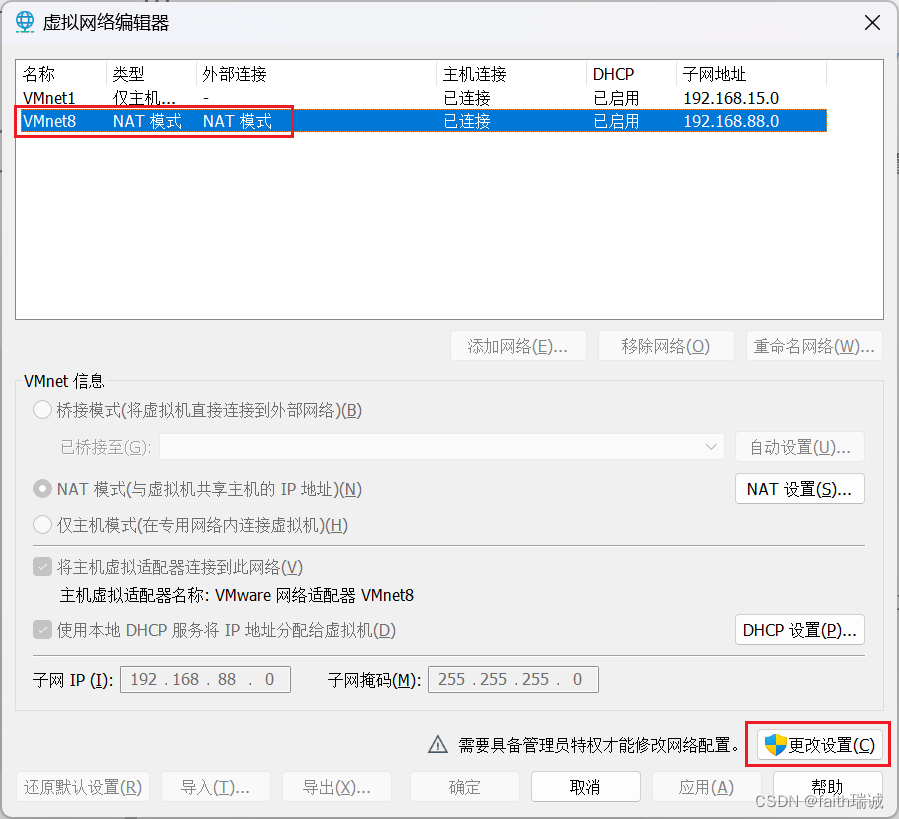
3、获取管理员权限后,选择“VMnet8”网卡,将其子网IP修改为“192.168.88.0”;
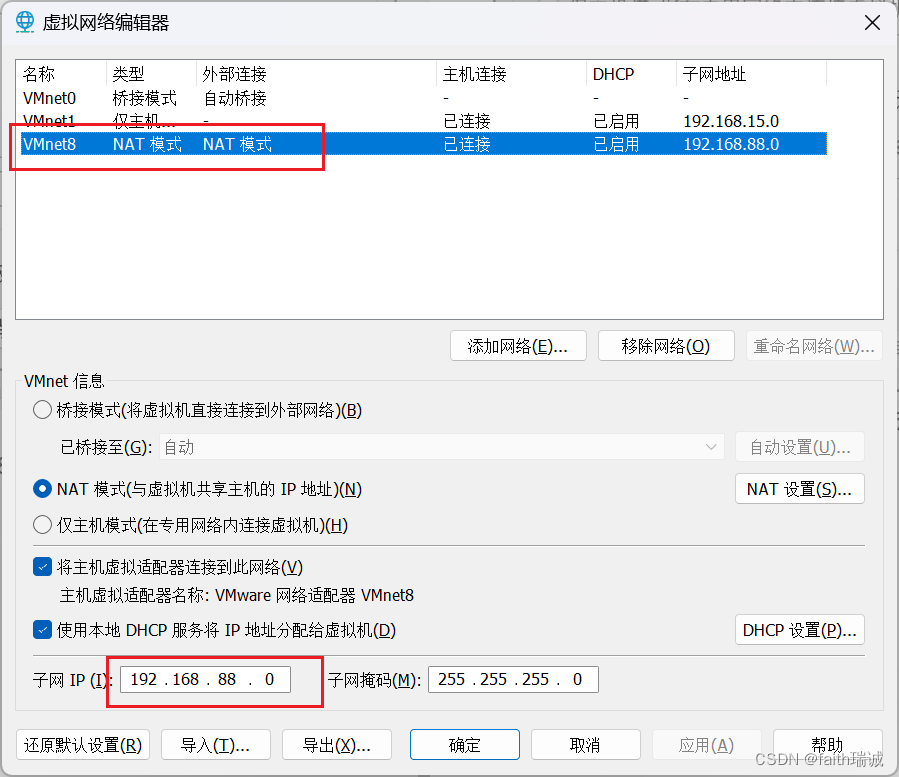
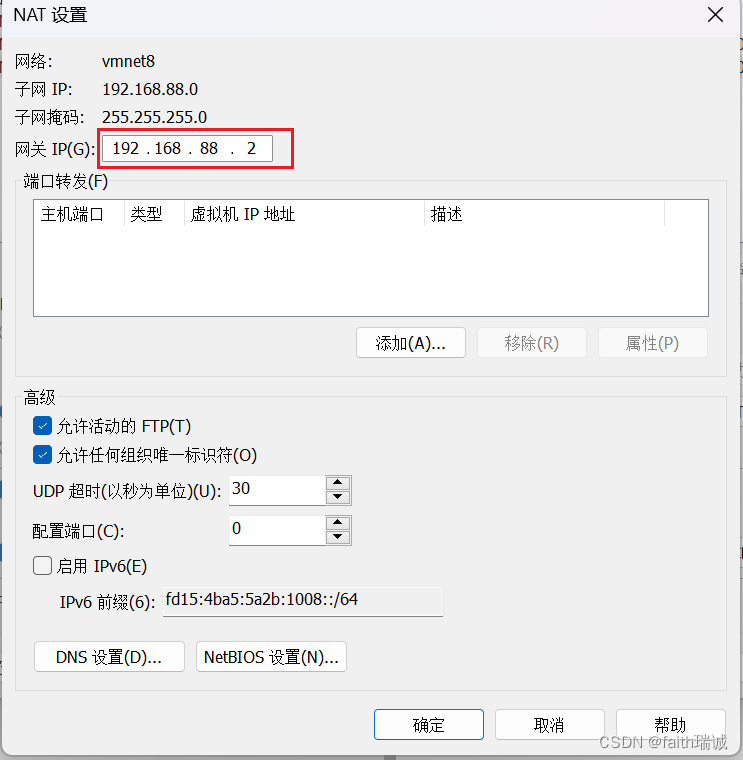
4、点击“NAT设置”按钮,在NAT设置界面,将网关IP修改为“192.168.88.2”,并保存上述设置。
1.1.2. 安装Linux虚拟机
1、通过VMware菜单中的“文件”-“新建虚拟机”创建一个新的虚拟机;
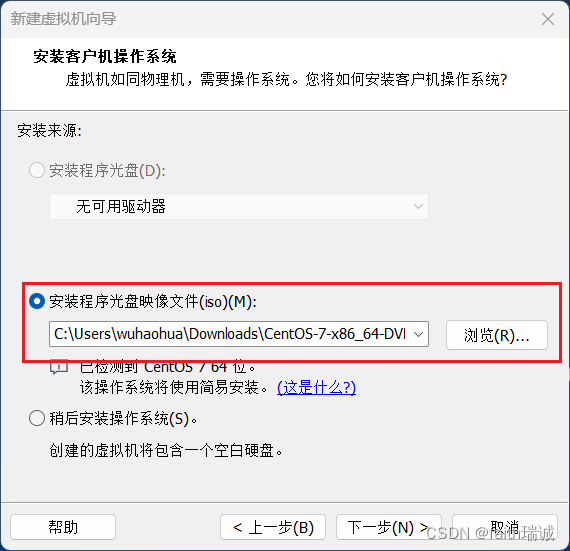
2、选择前面下载的CentOS操作系统镜像;
3、输入Linux系统用户名和密码(该密码也是root的密码);
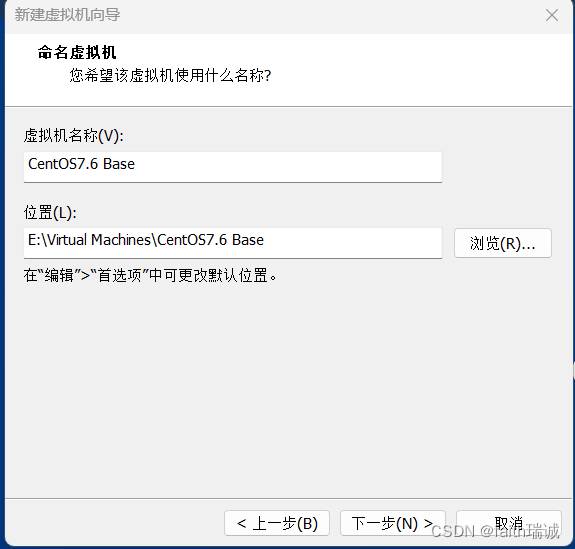
4、填写虚拟机名称和虚拟机的存放位置;
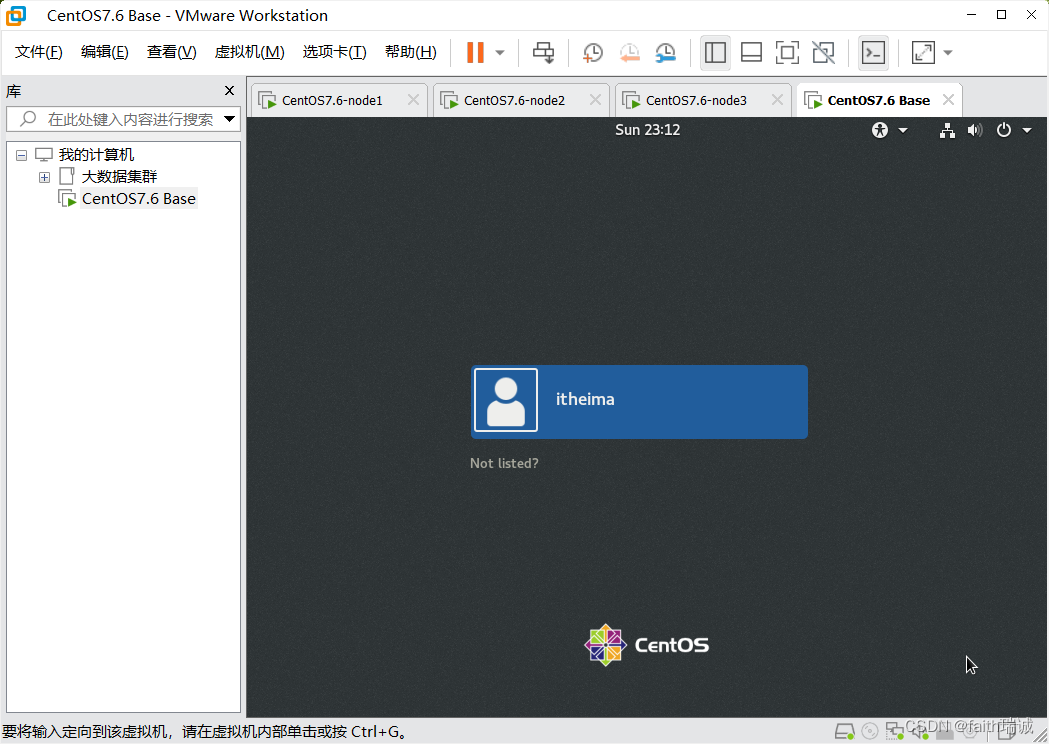
5、之后一直下一步、完成,然后虚拟机开始自己安装,直至安装完成,此过程视个人电脑和网络情况可能需要半小时左右,中间不用任何操作,待系统安装完毕后,虚拟机会自动重启,看到如下界面,代表安装成功。
1.2. VMware克隆三台Linux虚拟机
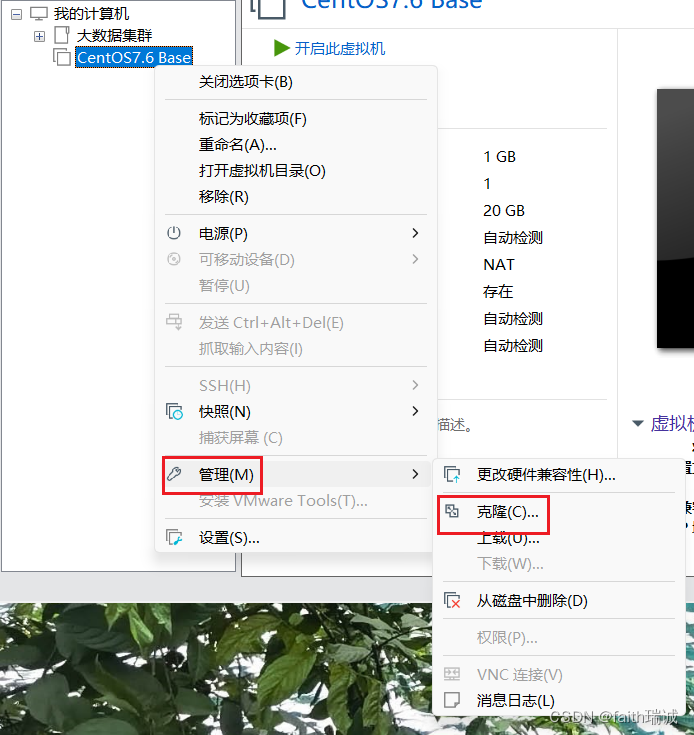
1、将前面安装好的虚拟机关机,然后在VMware左侧的菜单中,鼠标右键刚才安装好的虚拟机,选择“管理”-“克隆”;
2、然后点击下一页按钮,直到“克隆方法”界面;

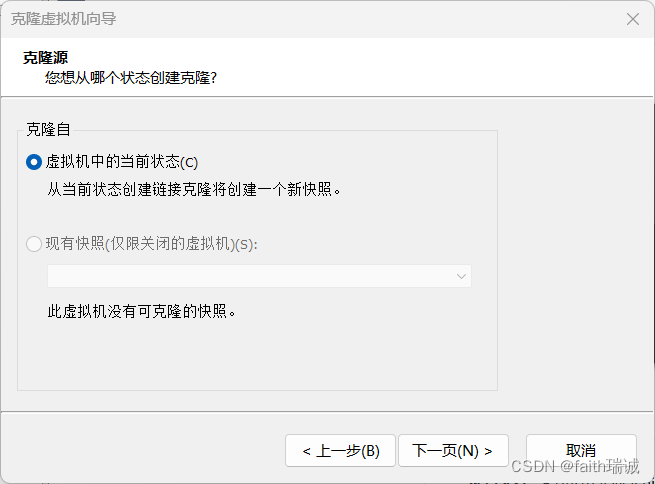
3、在克隆方法界面选择“创建完整克隆”,然后继续下一页;
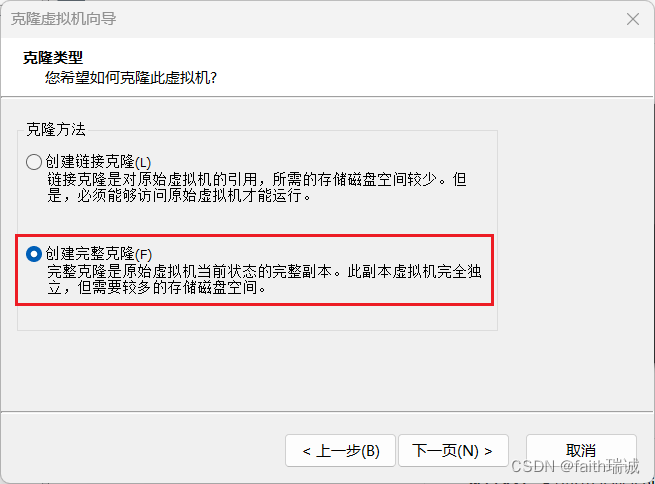
4、重命名虚拟机名称为node1,选择克隆出来的虚拟机存放的路径,然后点击“完成”按钮,VMware就会克隆出一个一摸一样的虚拟机,此过程很快,一般3~5秒的样子;
5、依照上述方法,再克隆出node2和node3,总共3台虚拟机出来;
6、此时先别启动这3台虚拟机,先对3台虚拟机的内存大小进行调整,分别将node1调整到4GB,node2和node3调整成2GB;
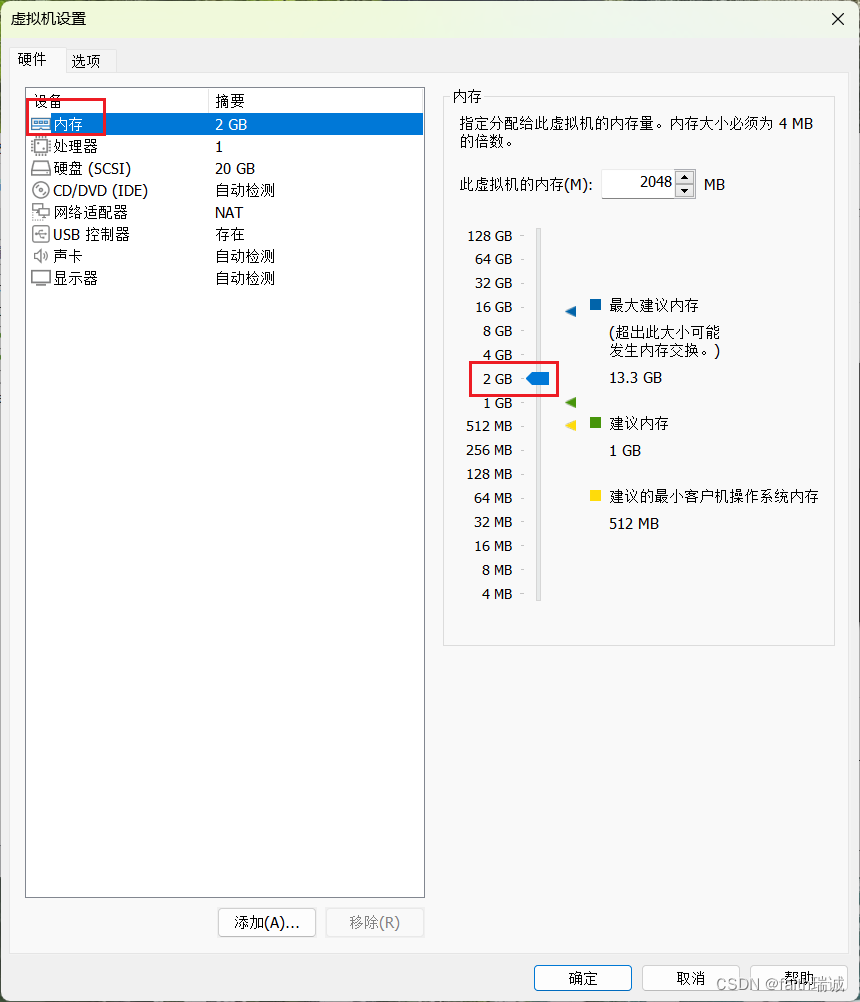 7、内存调整完毕后,分别将node1、2、3开机,在开机时,VMware会弹窗提示“无法连接虚拟设备 ide1:0…”,直接点“否”即可,至此,虚拟机克隆完毕,后续我们使用的也是这3台虚拟机。
7、内存调整完毕后,分别将node1、2、3开机,在开机时,VMware会弹窗提示“无法连接虚拟设备 ide1:0…”,直接点“否”即可,至此,虚拟机克隆完毕,后续我们使用的也是这3台虚拟机。
1.3. 为三台虚拟机配置固定IP
1、三台虚拟机分别启动后,在虚拟机中打开命令行,修改主机名,输入如下命令:
# 切换成root用户
[itheima@locahost ~]$ su -
# 修改当前虚拟机的主机名,这里只演示node1,node2和node3命令相同,只是最后的参数需要修改成node2和node3
[root@locahost ~]# hostnamectl set-hostname node1
2、上述命令执行完毕后,关闭命令行,并重新打开命令行,此时可以看到命令行内的主机名已经变成了node1、node2和node3
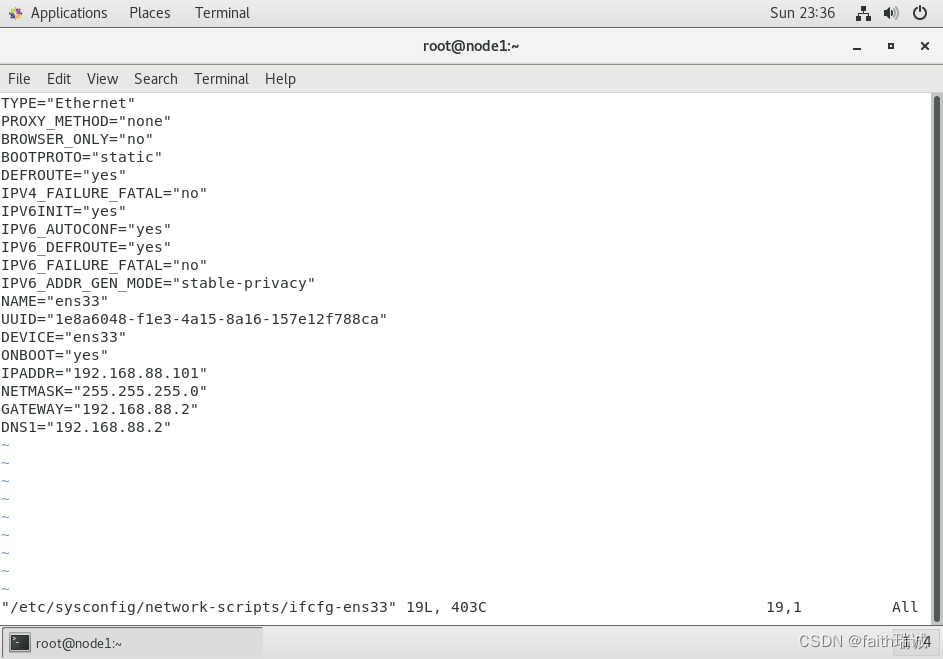
3、在命令行里切换到root用户,并执行如下命令:
vim /etc/sysconfig/network-scripts/ifcfg-ens33
4、打开ifcfg-ens33文件后,将其中BOOTPROTO配置项的值修改为static,然后再在文件末尾追加如下内容:
IPADDR="192.168.88.101"
NETMASK="255.255.255.0"
GATEWAY="192.168.88.2"
DNS1="192.168.88.2"
其中,在node1虚拟机中,IPADDR的值为192.168.88.101,node2虚拟机的IPADDR的值为192.168.88.102,node3虚拟机的IPADDR的值为192.168.88.103;
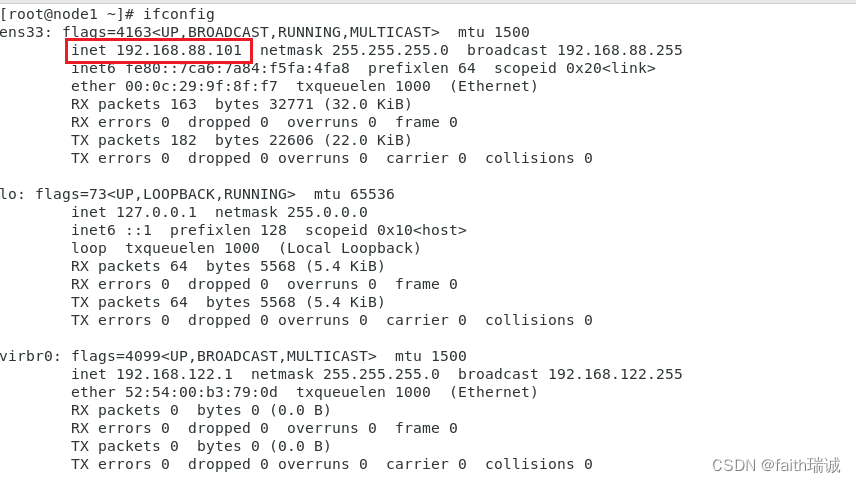
5、修改网网卡配置后,在命令行中重启网卡,执行如下命令:
systemctl restart network
然后可以使用ifconfig命令查看及其的IP地址,查看上述修改是否成功。
1.4. 配置免密登录
1、修改Windows系统(本机,非虚拟机)的hosts文件(目录为C:\Windows\System32\drivers\etc\),将如下内容追加在hosts文件末尾并保存
192.168.88.101 node1
192.168.88.102 node2
192.168.88.103 node3
2、使用本机的ssh工具连接三台虚拟机(node1、node2、node3),后续所有的命令通过ssh工具操作;
3、分别修改三台虚拟机的hosts文件,此处以node1为例,在命令行中输入
vim /etc/hosts
在hosts文件中追加如下内容:
192.168.88.101 node1
192.168.88.102 node2
192.168.88.103 node3
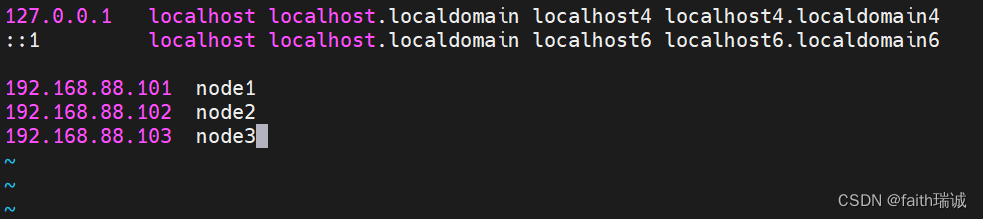
保存并退出,然后同样的步骤修改node2和node3的hosts文件。
4、在三台虚拟机上分别执行ssh-keygen -t rsa -b 4096命令,然后一路回车到底,给三台虚拟机分别生成好自己的密钥;
5、在三台虚拟机上都执行如下命令,完成免密登录的授权操作:
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
执行命令过程中,有配置项需要确认输入yes,然后,还需要输入root密码;
6、可以在node1虚拟机通过命令ssh node2查看是否已经配置好了node1到node2的免密登录,同理,可以在node2验证到另两台服务器的免密登录;
7、至此,我们配置好了三台虚拟机root用户之间的免密登录,接下来,我们还需要配置三台虚拟机之间hadoop用户的免密登录;
8、使用useradd hadoop和passwd hadoop命令分别在三台虚拟机上创建hadoop用户;
9、在三台虚拟机上使用su - hadoop命令切换成hadoop用户,然后使用签名用过的ssh-keygen -t rsa -b 4096命令生成hadoop用户的ssh密钥;
10、然后再在三台虚拟机上执行如下命令,实现hadoop用户之间的免密登录:
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
具体操作和上面配置root用户的免密登录时一样。至此,免密登录配置完成。
1.5. JDK环境部署
1、目前还是使用jdk 1.8版本,下载页面:https://www.oracle.com/cn/java/technologies/downloads/,打开页面一直往下划,划到JDK 1.8的部分,下载x64 Compressed Archive版本;
2、下载后,在虚拟机里面切换成root用户,然后将刚才下载好的jdk压缩包上传到root目录下,执行如下命令:
mkdir -p /export/server
# 解压刚才上传的jdk压缩包到/export/server目录
tar -zxvf jdk-8u391-linux-x64.tar.gz -C /export/server/
# 创建软连接
ln -s /export/server/jdk1.8.0_391/ /export/server/jdk
3、配置环境变量,使用命令vim /etc/profile打开环境变量配置文件,然后在文件末尾追加如下内容:
export JAVA_HOME=/export/server/jdk
export PATH=$PATH:$JAVA_HOME/bin
然后使用source /etc/profile命令使环境变量生效;
4、将操作系统自带的jdk替换成我们刚才安装的jdk:
# 删除系统自带的java程序
rm -f /usr/bin/java
# 软连接我们自己安装的java程序
ln -s /export/server/jdk/bin/java /usr/bin/java
此时,jdk配置完成,可以使用java -version和javac -version命令校验系统所使用的java是否已经是我们自己安装的JDK。
5、使用scp命令,将已解压的jdk文件夹复制到node2和node3
# 复制到node2
scp -r /export/server/jdk1.8.0_391/ node2:`pwd`/
# 复制到node3
scp -r /export/server/jdk1.8.0_391/ node3:`pwd`/
6、然后参考上面的流程,创建软连接、配置环境变量、移除系统自带的java,完成node2和node3的配置。
1.6. 防火墙、SELinux、时间同步配置
1.6.1. 关闭防火墙
在三台虚拟机上分别执行如下命令:
# 关闭防火墙
systemctl stop firewalld.service
# 关闭防火墙的开机自启
systemctl disable firewalld.service
1.6.2. 关闭SELinux
使用vim /etc/sysconfig/selinux打开selinux的配置文件,将其中的SELINUX=enforcing修改为SELINUX=disabled,然后保存退出,并重启虚拟机(可通过reboot命令)即可。
1.6.3. 配置时间同步
在三台虚拟机上分别依次执行以下步骤
1、安装ntp软件
yum install -y ntp
2、更新时区
# 删除系统的默认时区信息
rm -f /etc/localtime
# 设置虚拟机的时区为中国上海时区
ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
3、同步时间
# 使用阿里云的ntp服务校准本机时间
ntpdate -u ntp.aliyun.com
4、开启ntp服务并设置开机自启
# 启动NTP服务
systemctl start ntpd.service
# 设置NTP服务开机自启动
systemctl enable ntpd.service
1.7. 使用VMware快照功能保存当前已配置好的初始环境
1、将三台虚拟机全部关机;
2、在VMware中,在左侧虚拟机上右键,选择“快照”-“拍摄快照”,填写快照名称和备注,创建虚拟机快照;
node2和node3重复上述步骤,完成快照拍摄
二、在虚拟机里部署HDFS集群
下载Hadoop:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
本次演示部署结构如下图所示:
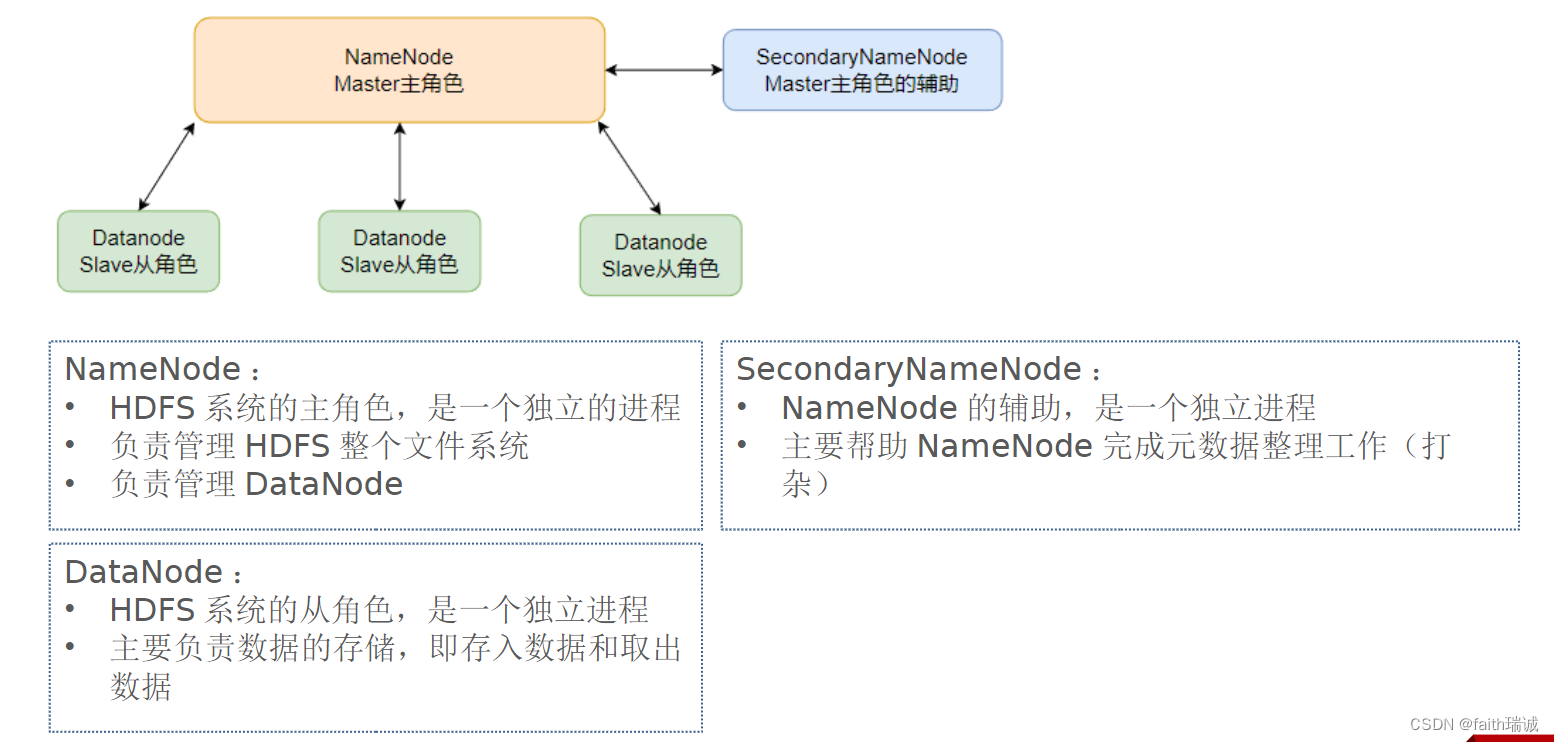
本次部署服务清单如下表所示:
| 节点 | 部署的服务 |
|---|---|
| node1 | NameNode、DataNode、SecondaryNameNode |
| node2 | DataNode |
| node3 | DataNode |
2.1. 部署node1虚拟机
1、将下载好的Hadoop压缩包上传至node1虚拟机的root目录;
2、将Hadoop压缩包解压至/export/server目录下
tar -zxvf hadoop-3.3.4.tar.gz -C /export/server/
3、创建hadoop目录的软链接
# 切换工作目录
cd /export/server/
# 创建软连接
ln -s /export/server/hadoop-3.3.4/ hadoop
4、hadoop目录结构如下

| 目录 | 存放内容 |
|---|---|
| bin | 存放Hadoop的各类程序(命令) |
| etc | 存放Hadoop的配置文件 |
| include | 存放Hadopp用到的C语言的头文件 |
| lib | 存放Linux系统的动态链接库(.so文件) |
| libexec | 存放配置Hadoop系统的脚本文件(.sh和.cmd文件) |
| licenses_binary | 存放许可证文件 |
| sbin | 管理员程序(super bin) |
| share | 存放二进制源码(jar包) |
5、配置workers文件
cd etc/hadoop/
vim workers
将workers文件原有的内容删掉,改为
node1
node2
node3
保存即可;
6、配置hadoop-env.sh文件,使用vim hadoop-env.sh打开,修改以下配置:
# 指明JDK安装目录
export JAVA_HOME=/export/server/jdk
# 指明HADOOP安装目录
export HADOOP_HOME=/export/server/hadoop
# 指明HADOOP配置文件的目录
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
#指明HADOOP运行日志文件的目录
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
7、配置core-site.xml文件,使用vim core-site.xml打开文件,修改以下配置:
<configuration>
<property>
<!--HDFS 文件系统的网络通讯路径-->
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<!--io 操作文件缓冲区大小-->
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
8、配置hdfs-site.xml文件,修改以下配置:
<configuration>
<property>
<!--hdfs 文件系统,默认创建的文件权限设置-->
<name>dfs.datanode.data.dir.perm</name>
<!-- 700权限即rwx------ -->
<value>700</value>
</property>
<property>
<!--NameNode 元数据的存储位置-->
<name>dfs.namenode.name.dir</name>
<!-- 在 node1 节点的 /data/nn 目录下 -->
<value>/data/nn</value>
</property>
<property>
<!--NameNode 允许哪几个节点的 DataNode 连接(即允许加入集群)-->
<name>dfs.namenode.hosts</name>
<value>node1,node2,node3</value>
</property>
<property>
<!--hdfs 默认块大小-->
<name>dfs.blocksize</name>
<!--268435456即256MB-->
<value>268435456</value>
</property>
<property>
<!--namenode 处理的并发线程数-->
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<!--从节点 DataNode 的数据存储目录,即数据存放在node1、node2、node3三台机器中的路径-->
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
</configuration>
9、根据上一步的配置项,在node1节点创建/data/nn和/data/dn目录,在node2和node3节点创建/data/dn目录;
10、将已配置好的hadoop程序从node1分发到node2和node3:
# 切换工作目录
cd /export/server/
# 将node1的hadoop-3.3.4/目录复制到node2的同样的位置
scp -r hadoop-3.3.4/ node2:`pwd`/
# 将node1的hadoop-3.3.4/目录复制到node3的同样的位置
scp -r hadoop-3.3.4/ node3:`pwd`/
11、将Hadoop加入环境变量,使用vim /etc/profile打开环境变量文件,将以下内容添加在文件末尾:
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行source /etc/profile命令使环境变量配置生效;
12、修改相关目录的权限:
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export/
2.2. 部署node2和node3虚拟机
本小节内容如无特殊说明,均需在node2和node3虚拟机分别执行!
1、为hadoop创建软链接,命令都是一样的,如下所示:
cd /export/server/
ln -s /export/server/hadoop-3.3.4/ hadoop
2、将Hadoop加入环境变量,使用vim /etc/profile打开环境变量文件,将以下内容添加在文件末尾:
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行source /etc/profile命令使环境变量配置生效;
3、修改相关目录的权限:
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export/
2.3. 初始化并启动Hadoop集群(格式化文件系统)
1、在node1虚拟机上执行以下命令:
# 切换为hadoop用户
su - hadoop
# 格式化namenode
hadoop namenode -format
2、启动集群,在node1虚拟机上执行以下命令:
# 一键启动整个集群,包括namenode、secondarynamenode和所有的datanode
start-dfs.sh
# 查看当前系统中正在运行的Java进程,可以看到每台虚拟机上hadoop的运行情况
jps
3、执行上述步骤之后,我们可以在我们自己的电脑(非虚拟机)上查看 HDFS WEBUI(即HADOOP管理页面),可以通过访问namenode所在服务器的9870端口查看,在本案例中因为namenode处于node1虚拟机上,所以可以访问http://node1:9870/打开。PS:因为之前我们已经配置了本机的hosts文件,所以这里可以使用node1访问,其实这个地址对应的就是http://192.168.88.101:9870/。
4、如果看到以下界面,代表Hadoop集群启动成功了。
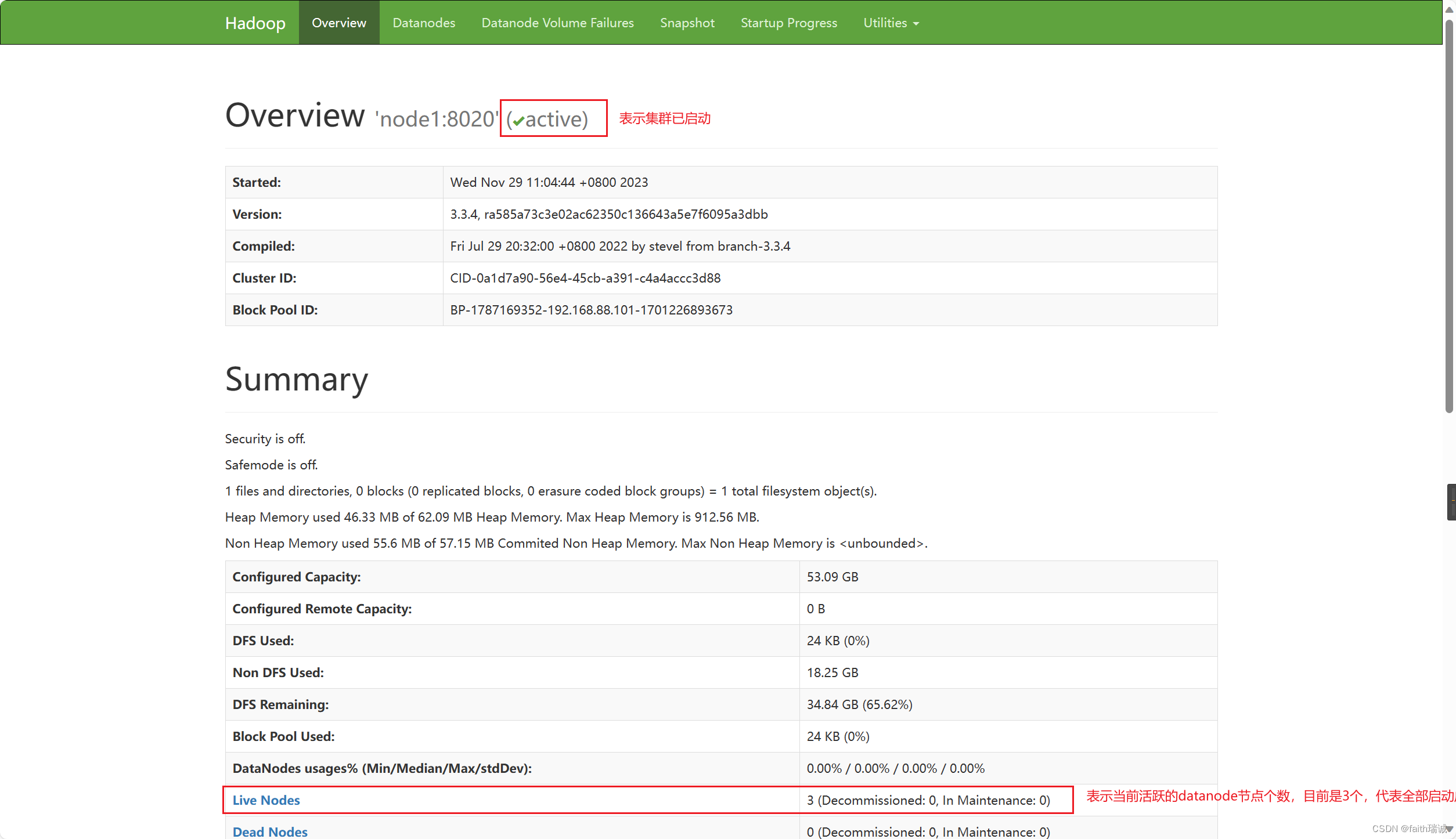
2.4. 快照部署好的集群
为了保存刚部署好的集群,在后续如果出现无法解决的问题,不至于重新部署一遍,使用虚拟机快照的方式进行备份。
1、一键关闭集群,在node1虚拟机执行以下命令:
# 切换为hadoop用户
su - hadoop
# 一键关闭整个集群
stop-dfs.sh
关闭完成后,可以在node1、node2、node3虚拟机中使用jps命令查看相应Java进程是否已消失。
2、关闭三台虚拟机;
3、在VMware中,分别在三台虚拟机上右键,“快照”-“拍摄快照”功能创建快照。
2.5. 部署过程中可能会遇到的问题
- 在以Hadoop用户身份执行
start-dfs.sh命令时,提示Permission denied。此时需要检查三台虚拟机上相关路径(/data、/export/server及其子路径)上hadoop用户是否具有读、写、执行的权限。 - 在执行
start-dfs.sh命令后,使用jps命令可以查看已启动的服务,若发现有服务未启动成功的,可以查看/export/server/hadoop/logs目录下的日志文件,若在日志文件中看到类似于无权限、不可访问等报错信息,同样需要检查对应机器的相关路径权限。 - 执行
hadoop namenode -format、start-dfs.sh、stop-dfs.sh等Hadoop相关命令时,若提示command not found,则代表着环境变量没配置好,需要检查三台机器的/etc/profile文件的内容(需要使用source命令使环境变量生效)以及hadoop的软连接是否正确。 - 执行
start-dfs.sh命令后,node1的相关进程启动成功,但node2和node3没有启动的,需要检查workers文件的配置是否有node2和node3。 - 若在日志文件中看到WstxEOFException或Unexpected EOF等信息,大概率是xml配置文件有问题,需要仔细检查core-site.xml和hdfs-site.xml文件里面的内容(少了某个字母或字符、写错了某个字母或字符),尤其是符号。
综上,常见出错点总结为:
- 权限未正确配置;
- 配置文件错误;
- 未格式化
2.5. Hadoop HDFS集群启停脚本
注意:在使用以下命令前,一定要确保当前是hadoop用户,否则将报错或没有效果!!!
-
Hadoop HDFS 组件内置了HDFS集群的一键启停脚本。
-
$HADOOP_HOME/sbin/start-dfs.sh,一键启动HDFS集群
执行流程:- 在执行此脚本的机器上,启动SecondaryNameNode;
- 读取
core-site.xml内容(fs.defaultFS项),确定NameNode所在机器,启动NameNode; - 读取
workers内容,确定DataNode所在机器,启动全部DataNode。
-
$HADOOP_HOME/sbin/stop-dfs.sh,一键关闭HDFS集群
执行流程:- 在执行此脚本的机器上,关闭SecondaryNameNode;
- 读取
core-site.xml内容(fs.defaultFS项),确定NameNode所在机器,关闭NameNode; - 读取
workers内容,确认DataNode所在机器,关闭全部NameNode。
-
-
除了一键启停外,也可以单独控制某个进程的启停。
-
$HADOOP_HOME/sbin/hadoop-daemon.sh,此脚本可以单独控制所在机器的进程启停
用法:hadoop-daemon.sh (start|status|stop) (namenode|secondarynamenode|datanode) -
$HADOOP_HOME/sbin/hdfs,此程序也可以单独控制所在机器的进程启停
用法:hdfs --daemon (start|status|stop) (namenode|secondarynamenode|datanode)
-
三、使用HDFS文件系统
3.1. 使用命令操作HDFS文件系统
3.1.1. HDFS文件系统基本信息
- HDFS和Linux系统一样,均是以
/作为根目录的组织形式; - 如何区分HDFS和Linux文件系统:
- Linux文件系统以
file://作为协议头,HDFS文件系统以hdfs://namenode:port作为协议头; - 例如,有路径
/usr/local/hello.txt,在Linux文件系统中表示为file:///usr/local/hello.txt,在HDFS文件系统中表示为hdfs://node1:8020/usr/local/hello.txt; - 但一般情况下,协议头是可以省略的,使用Linux命令时,会自动识别为
file://协议头,使用HDFS命令时,会自动识别为hdfs://namenode:port协议头; - 但如果需要再使用HDFS命令操作Linux文件时,需要明确使用
file://协议头。
- Linux文件系统以
3.1.2. HDFS文件系统的2套命令体系
老版本
用法:hadoop fs [generic options]
新版本
用法:hdfs dfs [generic options]
两套命令用法完全一致,效果完全一样,但某些特殊命令需要选择hadoop或hdfs命令。
3.1.3. 创建文件夹
用法:
hadoop fs -mkdir [-p] <path> ...
hdfs dfs -mkdir [-p] <path> ...
path为待创建的目录
-p 选项意思与Linux的mkdir -p一样,自动逐层创建对应的目录。
例如:
hadoop fs -mkdir -p file:///home/hadoop/test 在Linux系统下创建/home/hadoop/test文件夹;
hadoop fs -mkdir -p hdfs://node1:8020/itheima/bigdata 在HDFS中创建/itheima/bigdata文件夹;
hdfs dfs -mkdir -p /home/hadoop/itcast 在HDFS中创建/home/hadoop/itcast文件夹;
3.1.4. 查看指定目录下的内容
用法:
hadoop fs -ls [-h] [-R] [<path> ...]
hdfs dfs -ls [-h] [-R] [<path> ...]
path为指定的目录路径
-h 人性化显示size
-R 递归查看指定目录及其子目录。
例如:
hdfs dfs -ls / 查看HDFS 根目录下的内容
hadoop fs -ls / 查看HDFS 根目录下的内容,与上面等效
hdfs dfs -ls -R / 递归查看HDFS根目录下的内容
hdfs dfs -ls file:/// 查看当前这台Linux机器根目录下的内容
hdfs dfs -ls -h / 查看HDFS根目录下的内容,当文件大小大于1k之后,其大小会有单位,便于人的阅读;
3.1.5. 上传文件到HDFS指定目录下
用法:
hadoop fs -put [-f] [-p] <localsrc> ... <dst>
hdfs dfs -put [-f] [-p] <localsrc> ... <dst>
-f 当目标文件已存在时,覆盖目标文件
-p 保留访问和修改时间,所有权和权限
localsrc 要上传的本地(Linux系统)文件的路径
dst 要保存在HDFS中的具体路径。
例如:
hadoop fs -put file:///home/hadoop/test.txt hdfs://node1:8020/ 将本地/home/hadoop/下的test.txt文件上传到HDFS的根目录下的完整写法;
hdfs dfs -put test2.txt / 将本地当前目录下的test2.txt文件上传到HDFS的根目录下;
hdfs dfs -put -f test2.txt / 将本地目录下的test2.txt文件上传到HDFS的根目录下,并强制覆盖原有的test2.txt文件;
3.1.6. 查看HDFS中文件的内容
用法:
hadoop fs -cat <src> ...
hdfs dfs -cat <src> ...
读取大文件时,可以使用管道符配合more
hadoop fs -cat <src> | more
hdfs dfs -cat <src> | more
例如:
hadoop fs -cat /test.txt 查看HDFS根目录下test.txt文件的内容
hdfs dfs -cat /test2.txt | more 查看HDFS根目录下的test2.txt文件的内容,可以翻页,适用于查看大文件
3.1.7. 从HDFS下载文件到本地
用法:
hadoop fs -get [-f] [-p] <src> ... <localdst>
hdfs dfs -get [-f] [-p] <src> ... <localdst>
-f 当目标文件已存在时,覆盖目标文件
-p 保留访问和修改时间,所有权和权限
src 要下载的HDFS文件路径
localdst 要保存在本地Linux系统中的路径。
例如:
hadoop fs -get /test.txt . 将HDFS根目录下的test.txt文件下载到本地Linux系统的当前目录下;
hadoop fs -get -f /test.txt . 将HDFS根目录下的test.txt文件下载到本地Linux系统的当前目录下,若本地已存在test.txt,则强制覆盖;
hdfs dfs -get /test2.txt . 将HDFS根目录下的test2.txt文件下载到本地的当前目录下;
3.1.8. 复制HDFS文件
用法:
hadoop fs -cp [-f] <src> ... <dst>
hdfs dfs -cp [-f] <src> ... <dst>
-f 若目标文件存在,则强制覆盖目标文件
src 被复制的文件路径
dst 要复制到的目标路径