22. 数据结构
22.1.1. 栈(stack)
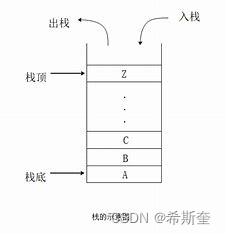
栈(stack)是限制插入和删除只能在一个位置上进行的表,该位置是表的末端,叫做栈顶 (top)。它是后进先出(LIFO)的。对栈的基本操作只有 push(进栈)和 pop(出栈)两种, 前者相当于插入,后者相当于删除最后的元素。
22.1.2. 队列(queue)
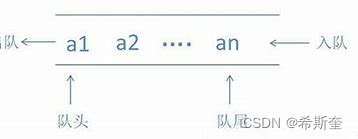
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的 后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为 队尾,进行删除操作的端称为队头。
22.1.3. 链表(Link)
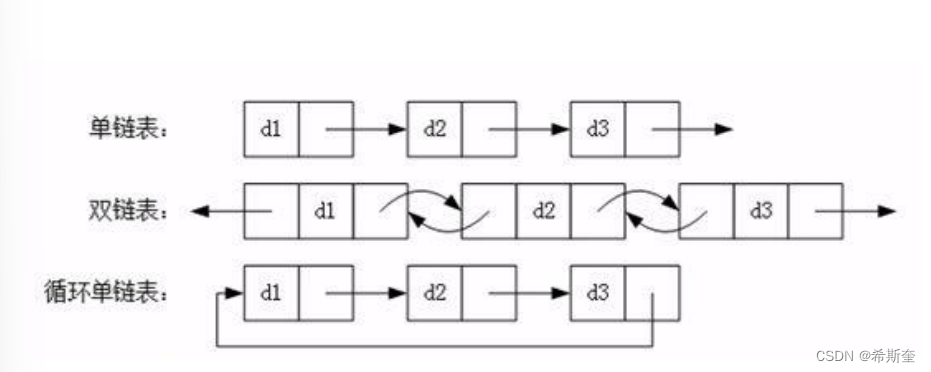
链表是一种数据结构,和数组同级。比如,Java 中我们使用的 ArrayList,其实现原理是数组。而 LinkedList 的实现原理就是链表了。链表在进行循环遍历时效率不高,但是插入和删除时优势明显。
22.1.4. 散列表(Hash Table)
散列表(Hash table,也叫哈希表)是一种查找算法,与链表、树等算法不同的是,散列表算法 在查找时不需要进行一系列和关键字(关键字是数据元素中某个数据项的值,用以标识一个数据 元素)的比较操作。
散列表算法希望能尽量做到不经过任何比较,通过一次存取就能得到所查找的数据元素,因而必 须要在数据元素的存储位置和它的关键字(可用 key 表示)之间建立一个确定的对应关系,使每个 关键字和散列表中一个唯一的存储位置相对应。因此在查找时,只要根据这个对应关系找到给定 关键字在散列表中的位置即可。这种对应关系被称为散列函数(可用 h(key)表示)。
用的构造散列函数的方法有:
(1)直接定址法: 取关键字或关键字的某个线性函数值为散列地址。 即:h(key) = key 或 h(key) = a * key + b,其中 a 和 b 为常数
(2)数字分析法
(3)平方取值法: 取关键字平方后的中间几位为散列地址。
(4)折叠法:将关键字分割成位数相同的几部分,然后取这几部分的叠加和作为散列地址。
(5)除留余数法:取关键字被某个不大于散列表表长 m 的数 p 除后所得的余数为散列地址, 即:h(key) = key MOD p p ≤ m
(6)随机数法:选择一个随机函数,取关键字的随机函数值为它的散列地址, 即:h(key) = random(key)
22.1.5. 排序二叉树
首先如果普通二叉树每个节点满足:左子树所有节点值小于它的根节点值,且右子树所有节点值 大于它的根节点值,则这样的二叉树就是排序二叉树。
22.1.5.1. 插入操作
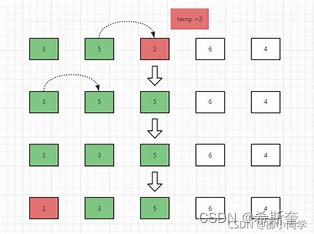
首先要从根节点开始往下找到自己要插入的位置(即新节点的父节点);具体流程是:新节点与 当前节点比较,如果相同则表示已经存在且不能再重复插入;如果小于当前节点,则到左子树中寻找,如果左子树为空则当前节点为要找的父节点,新节点插入到当前节点的左子树即可;如果 大于当前节点,则到右子树中寻找,如果右子树为空则当前节点为要找的父节点,新节点插入到 当前节点的右子树即可。
22.1.5.2. 删除操作
删除操作主要分为三种情况,即要删除的节点无子节点,要删除的节点只有一个子节点,要删除 的节点有两个子节点。
1. 对于要删除的节点无子节点可以直接删除,即让其父节点将该子节点置空即可。
2. 对于要删除的节点只有一个子节点,则替换要删除的节点为其子节点。
3. 对于要删除的节点有两个子节点,则首先找该节点的替换节点(即右子树中最小的节点), 接着替换要删除的节点为替换节点,然后删除替换节点。
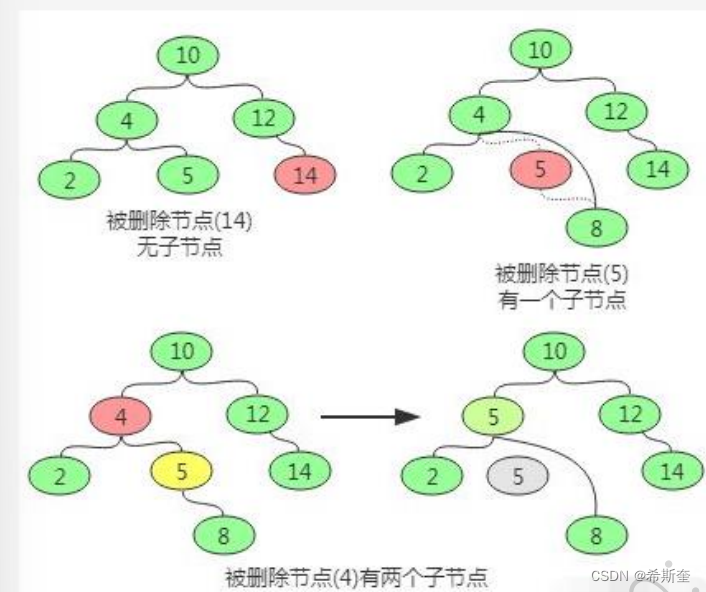
22.1.5.3. 查询操作
查找操作的主要流程为:先和根节点比较,如果相同就返回,如果小于根节点则到左子树中 递归查找,如果大于根节点则到右子树中递归查找。因此在排序二叉树中可以很容易获取最 大(最右最深子节点)和最小(最左最深子节点)值。
22.1.6. 红黑树
R-B Tree,全称是 Red-Black Tree,又称为“红黑树”,它一种特殊的二叉查找树。红黑树的每 个节点上都有存储位表示节点的颜色,可以是红(Red)或黑(Black)。
22.1.6.1. 红黑树的特性
(1)每个节点或者是黑色,或者是红色。
(2)根节点是黑色。
(3)每个叶子节点(NIL)是黑色。 [注意:这里叶子节点,是指为空(NIL 或NULL)的叶子节点!]
(4)如果一个节点是红色的,则它的子节点必须是黑色的。
(5)从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
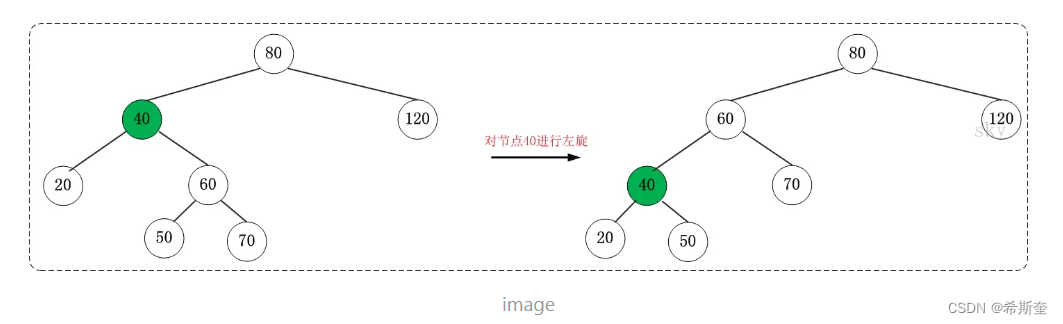
22.1.6.1. 左旋
对 x 进行左旋,意味着,将“x 的右孩子”设为“x 的父亲节点”;即,将 x 变成了一个左节点(x 成了为 z 的左孩子)!。 因此,左旋中的“左”,意味着“被旋转的节点将变成一个左节点”。
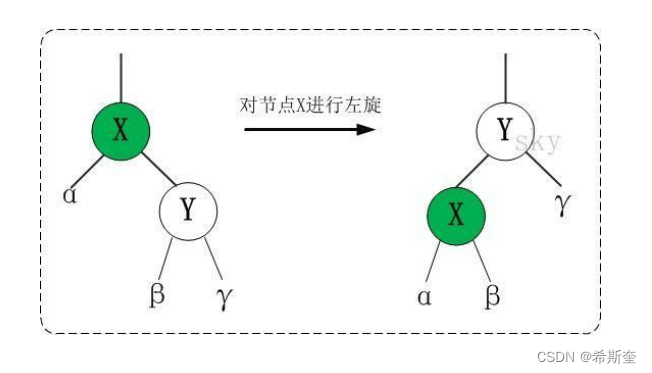
LEFT-ROTATE(T, x)
y ← right[x] // 前提:这里假设 x 的右孩子为 y。下面开始正式操作
right[x] ← left[y] // 将 “y 的左孩子” 设为 “x 的右孩子”,即 将β设为 x 的右孩子
p[left[y]] ← x // 将 “x” 设为 “y 的左孩子的父亲”,即 将β的父亲设为 x
p[y] ← p[x] // 将 “x 的父亲” 设为 “y 的父亲”
if p[x] = nil[T]
then root[T] ← y // 情况 1:如果 “x 的父亲” 是空节点,则将 y 设为根节点
else if x = left[p[x]]
then left[p[x]] ← y // 情况 2:如果 x 是它父节点的左孩子,则将 y 设为“x 的父节点
的左孩子”
else right[p[x]] ← y // 情况 3:(x 是它父节点的右孩子) 将 y 设为“x 的父节点的右孩
子”
left[y] ← x // 将 “x” 设为 “y 的左孩子”
p[x] ← y // 将 “x 的父节点” 设为 “y”
22.1.6.1. 右旋
对 x 进行右旋,意味着,将“x 的左孩子”设为“x 的父亲节点”;即,将 x 变成了一个右节点(x 成了为 y 的右孩子)! 因此,右旋中的“右”,意味着“被旋转的节点将变成一个右节点”。
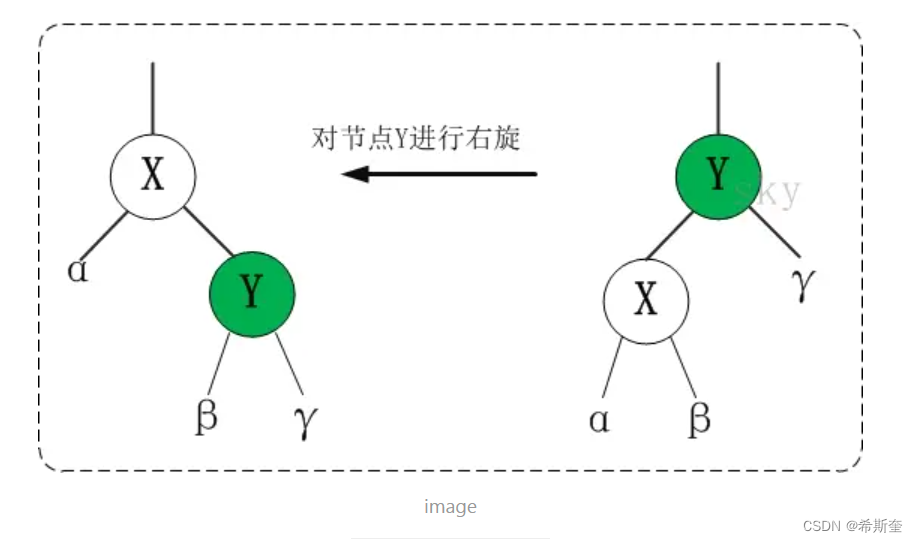
RIGHT-ROTATE(T, y)
x ← left[y] // 前提:这里假设 y 的左孩子为 x。下面开始正式操作
left[y] ← right[x] // 将 “x 的右孩子” 设为 “y 的左孩子”,即 将β设为 y 的左孩子
p[right[x]] ← y // 将 “y” 设为 “x 的右孩子的父亲”,即 将β的父亲设为 y
p[x] ← p[y] // 将 “y 的父亲” 设为 “x 的父亲”
if p[y] = nil[T]
then root[T] ← x // 情况 1:如果 “y 的父亲” 是空节点,则将 x 设为根节点
else if y = right[p[y]]
then right[p[y]] ← x // 情况 2:如果 y 是它父节点的右孩子,则将 x 设为“y 的父节
点的左孩子”
else left[p[y]] ← x // 情况 3:(y 是它父节点的左孩子) 将 x 设为“y 的父节点的左孩
子”
right[x] ← y // 将 “y” 设为 “x 的右孩子”
p[y] ← x // 将 “y 的父节点” 设为 “x”22.1.6.1. 添加
第一步: 将红黑树当作一颗二叉查找树,将节点插入。
第二步:将插入的节点着色为"红色"。
根据被插入节点的父节点的情况,可以将"当节点 z 被着色为红色节点,并插入二叉树"划分为三 种情况来处理。
① 情况说明:被插入的节点是根节点。 处理方法:直接把此节点涂为黑色。
② 情况说明:被插入的节点的父节点是黑色。 处理方法:什么也不需要做。节点被插入后,仍然是红黑树。
③ 情况说明:被插入的节点的父节点是红色。这种情况下,被插入节点是一定存在非空祖父节点 的;进一步的讲,被插入节点也一定存在叔叔节点(即使叔叔节点为空,我们也视之为存在,空节 点本身就是黑色节点)。理解这点之后,我们依据"叔叔节点的情况",将这种情况进一步划分为 3 种情况(Case)。
第三步: 通过一系列的旋转或着色等操作,使之重新成为一颗红黑树。
22.1.6.2. 删除
第一步:将红黑树当作一颗二叉查找树,将节点删除。
这和"删除常规二叉查找树中删除节点的方法是一样的"。分 3 种情况:
① 被删除节点没有儿子,即为叶节点。那么,直接将该节点删除就 OK 了。
② 被删除节点只有一个儿子。那么,直接删除该节点,并用该节点的唯一子节点顶替它的位置。
③ 被删除节点有两个儿子。那么,先找出它的后继节点;然后把“它的后继节点的内容”复制给 “该节点的内容”;之后,删除“它的后继节点”。
第二步:通过"旋转和重新着色"等一系列来修正该树,使之重新成为一棵红黑树。 因为"第一步"中删除节点之后,可能会违背红黑树的特性。所以需要通过"旋转和重新着色"来修正 该树,使之重新成为一棵红黑树。
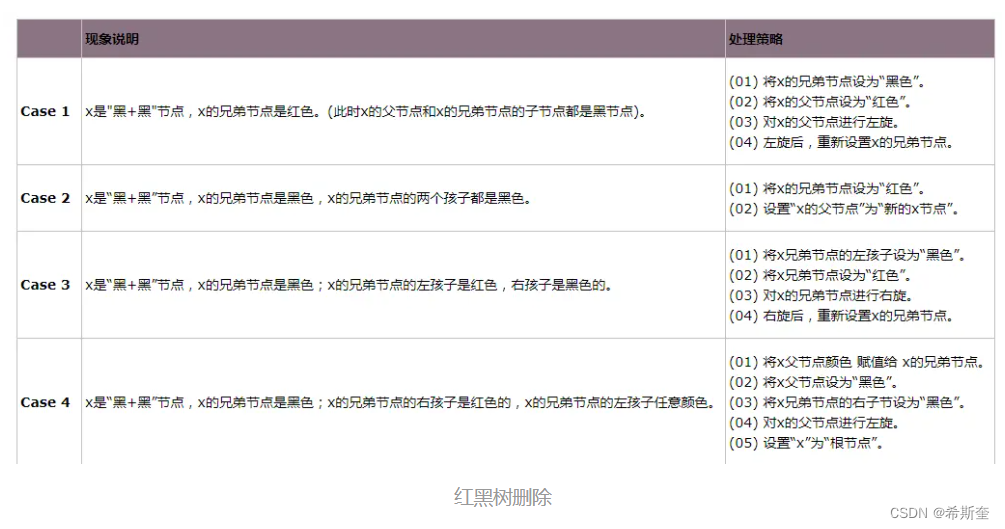
选择重着色 3 种情况。
① 情况说明:x 是“红+黑”节点。
处理方法:直接把 x 设为黑色,结束。此时红黑树性质全部恢复。
② 情况说明:x 是“黑+黑”节点,且 x 是根。
处理方法:什么都不做,结束。此时红黑树性质全部恢复。
③ 情况说明:x 是“黑+黑”节点,且 x 不是根。
处理方法:这种情况又可以划分为 4 种子情况。这 4 种子情况如下表所示:
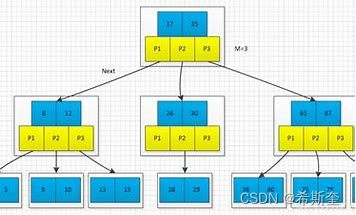
22.1.7. B-TREE
B-tree 又叫平衡多路查找树。一棵 m 阶的 B-tree (m 叉树)的特性如下(其中 ceil(x)是一个取上限 的函数):
1. 树中每个结点至多有 m 个孩子;
2. 除根结点和叶子结点外,其它每个结点至少有有 ceil(m / 2)个孩子;
3. 若根结点不是叶子结点,则至少有 2 个孩子(特殊情况:没有孩子的根结点,即根结点为叶子 结点,整棵树只有一个根节点);
4. 所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部结点或查询 失败的结点,实际上这些结点不存在,指向这些结点的指针都为 null);
5. 每个非终端结点中包含有 n 个关键字信息: (n,P0,K1,P1,K2,P2,......,Kn,Pn)。其 中:
a) Ki (i=1...n)为关键字,且关键字按顺序排序 K(i-1)< Ki。
b) Pi 为指向子树根的接点,且指针 P(i-1)指向子树种所有结点的关键字均小于 Ki,但都大于 K(i1)。
c) 关键字的个数 n 必须满足: ceil(m / 2)-1 <= n <= m-1。
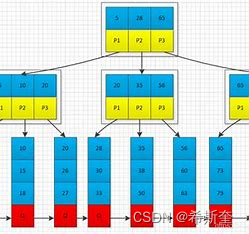
一棵 m 阶的 B+tree 和 m 阶的 B-tree 的差异在于:
1.有 n 棵子树的结点中含有 n 个关键字; (B-tree 是 n 棵子树有 n-1 个关键字)
2.所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本 身依关键字的大小自小而大的顺序链接。 (B-tree 的叶子节点并没有包括全部需要查找的信息)
3.所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (B-tree 的非终节点也包含需要查找的有效信息)
22.1.8. 位图
位图的原理就是用一个 bit 来标识一个数字是否存在,采用一个 bit 来存储一个数据,所以这样可 以大大的节省空间。 bitmap 是很常用的数据结构,比如用于 Bloom Filter 中;用于无重复整数的 排序等等。bitmap 通常基于数组来实现,数组中每个元素可以看成是一系列二进制数,所有元素 组成更大的二进制集合。
23. 加密算法
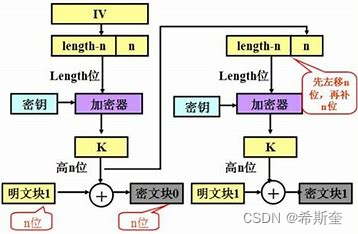
23.1.1. AES
高级加密标准(AES,Advanced Encryption Standard)为最常见的对称加密算法(微信小程序加密传 输就是用这个加密算法的)。对称加密算法也就是加密和解密用相同的密钥,具体的加密流程如下 图:
23.1.2. RSA
RSA 加密算法是一种典型的非对称加密算法,它基于大数的因式分解数学难题,它也是应用最广 泛的非对称加密算法。 非对称加密是通过两个密钥(公钥-私钥)来实现对数据的加密和解密的。公钥用于加密,私钥用 于解密。
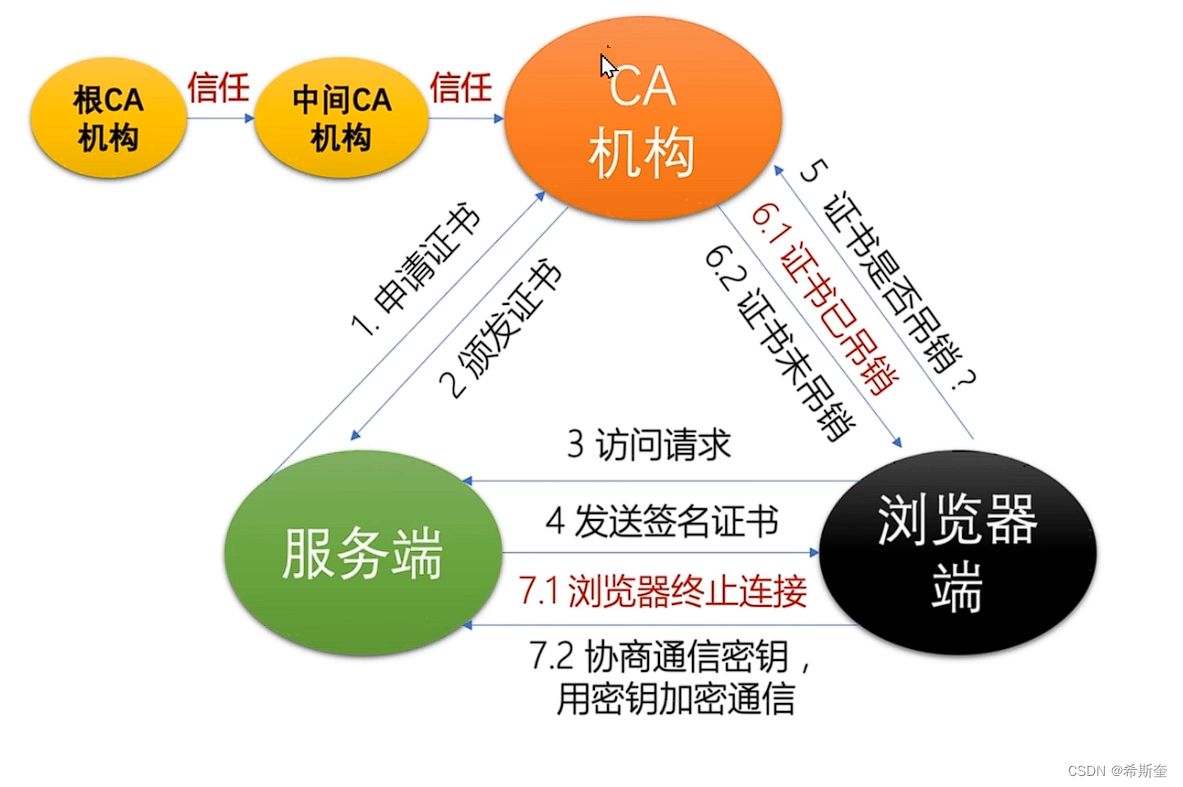
我们拿CSDN官网的证书举个例子:

此图是CSDN的证书👆
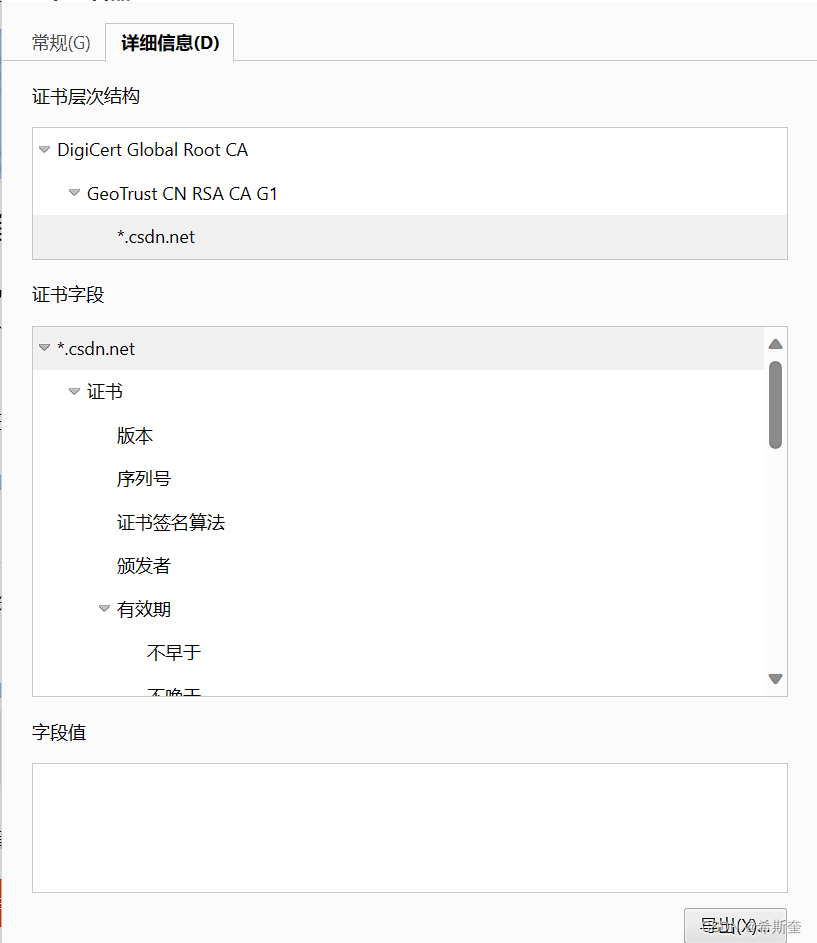
证书层次结构👆最终是根CA机构认证的证书,就可以说明此次通讯不会被第三人拦截和访问。
23.1.3. CRC
循环冗余校验(Cyclic Redundancy Check, CRC)是一种根据网络数据包或电脑文件等数据产生简 短固定位数校验码的一种散列函数,主要用来检测或校验数据传输或者保存后可能出现的错误。 它是利用除法及余数的原理来作错误侦测的。
23.1.4. MD5 MD5
常常作为文件的签名出现,我们在下载文件的时候,常常会看到文件页面上附带一个扩展 名为.MD5 的文本或者一行字符,这行字符就是就是把整个文件当作原数据通过 MD5 计算后的值, 我们下载文件后,可以用检查文件 MD5 信息的软件对下载到的文件在进行一次计算。两次结果对 比就可以确保下载到文件的准确性。 另一种常见用途就是网站敏感信息加密,比如用户名密码, 支付签名等等。随着 https 技术的普及,现在的网站广泛采用前台明文传输到后台,MD5 加密 (使用偏移量)的方式保护敏感数据保护站点和数据安全。
24. 分布式缓存
24.1.1. 缓存雪崩
缓存雪崩我们可以简单的理解为:由于原有缓存失效,新缓存未到期间所有原本应该访问缓存的请求都 去查询数据库了,而对数据库 CPU 和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列 连锁反应,造成整个系统崩溃。一般有三种处理办法:
1. 一般并发量不是特别多的时候,使用最多的解决方案是加锁排队。
2. 给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓 存。
3. 为 key 设置不同的缓存失效时间。
24.1.2. 缓存穿透
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在 缓存中找不到,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)。这样请 求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。 有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈 希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存 储系统的查询压力。另外也有一个更为简单粗暴的方法,如果一个查询返回的数据为空(不管是数据不 存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。 通过这个直接设置的默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库。
24.1.3. 缓存预热
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候, 先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
24.1.4. 缓存更新
缓存更新除了缓存服务器自带的缓存失效策略之外(Redis 默认的有 6 中策略可供选择),我们还可以 根据具体的业务需求进行自定义的缓存淘汰,常见的策略有两种:
(1)定时去清理过期的缓存;
(2)当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数 据并更新缓存。
24.1.5. 缓存降级
当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然 需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开 关实现人工降级。降级的最终目的是保证核心服务可用,即使是有损的。而且有些服务是无法降级的 (如加入购物车、结算)。