TIFS期刊 A类期刊
新知识点

Introduction
Linguistic Steganalysis in Few-Shot Scenario模型是个预训练方法。
评估了四种文本加密分析方法,TS-CSW、TS-RNN、Zou、SeSy,用于分析和训练的样本都由VAE-Stego生产(编码方式使用AC编码)。
实验是对比在少样本的情况下,各个模型的效果,当训练样本少于10的时候(few-shot),上面提到的TS-CSW和TS-RNN的表现都不好。
Zou和SeSy的方法用了pre-trained language mode,当训练标记样本到达1000的时候表现更好。
TS-CSW和TS-RNN的方法当样本达到10000的时候表现也很好。
表明,现有的分析网络需要大量样本作为训练的铺垫。
之前的文章 Few-shot text steganalysis based on attentional meta-learner[30]这篇文章考虑了few-shot的问题,但是作者的评价是:
Although this linguistic steganalysis method performs well when combined with multi-task scenario, there are some
problems in practical applications. Firstly, this method may not be able to demonstrate its advantages when there are
too few labeled samples to constitute multi-task, which limits its scope of application. Secondly, it is time-consuming
and labor-intensive to label samples accurately with various embedding rates and steganography algorithms
为了分析现实世界的实用场景,这篇文章只关注只有少量标记样本的实际场景(practiacl scenario)。
实验
第一阶段用 labeled data 去 fune-tune pretrained language model
第二阶段用 unlabeled data去进行 self-training(这个没太懂场景和效果问题)
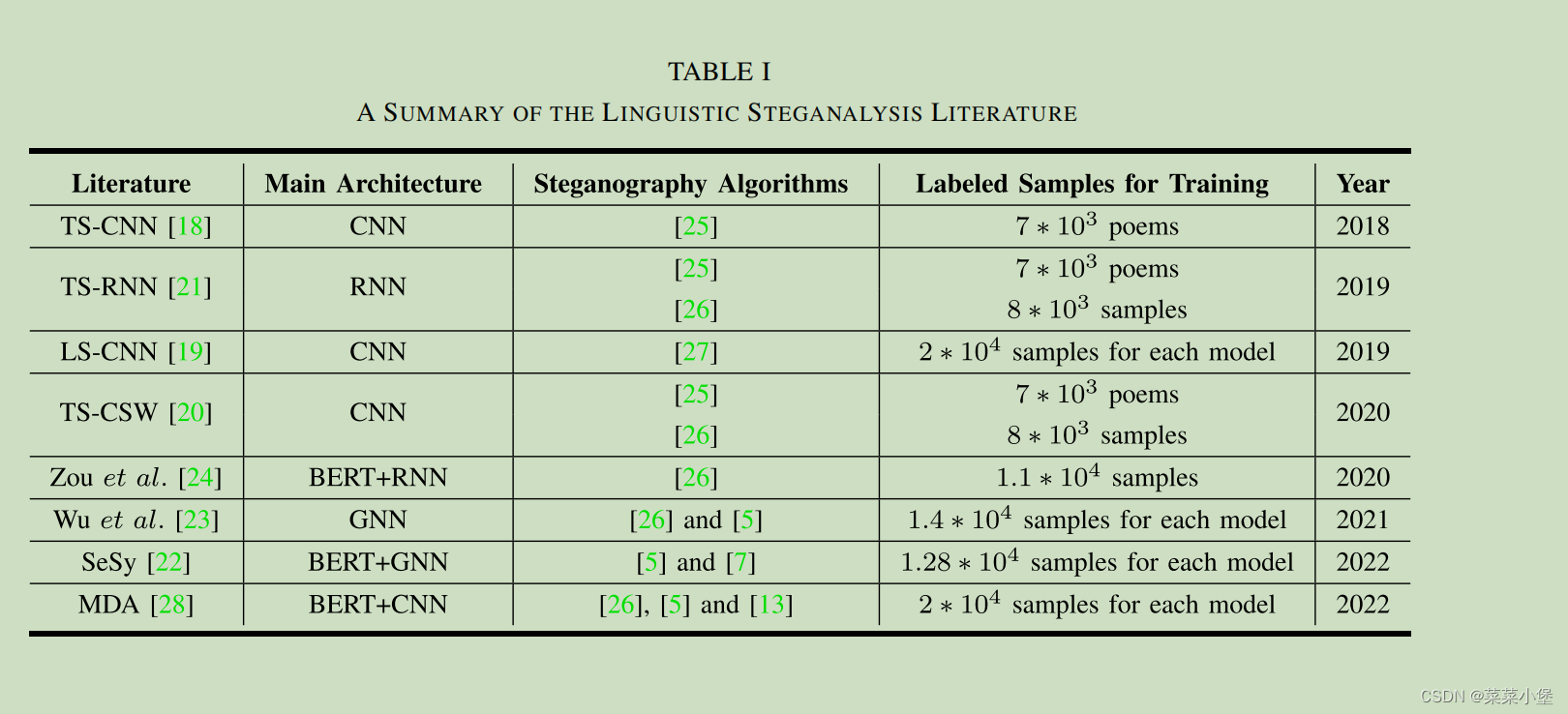
总结的文本分析所用的方法和模型。👆
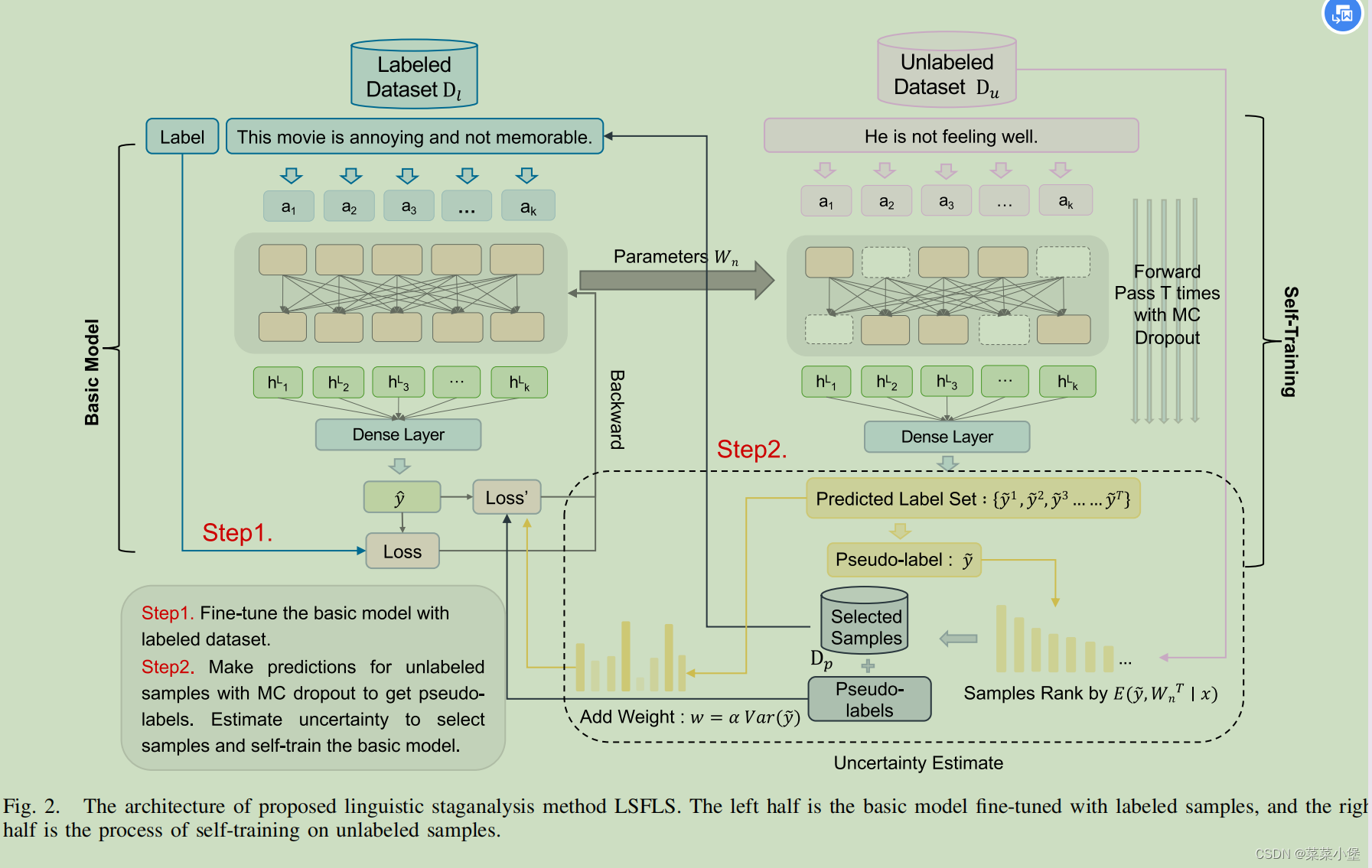
这是作者所用的模型,她提出了一个概念是,在slef-training的模型中,通过无标签(不知道是否是stego还是正常的cover)的文本来进行分析,选择more obvious and easier samples去标记pseudo-labeled(伪标记) dataset---------
D
p
D_p
Dp。
D
p
D_p
Dp便于后续的训练过程,提取和学习足够和更明显的特征,逐渐澄清分布差异。我们可以重复这个过程,然后得到了一种有效的少镜头语言步进分析方法。
basic model
对于基础模型,通过已标记数据集
D
l
D_l
Dl来训练模型
B
W
(
∗
)
B^W(*)
BW(∗)(Bert)。
训练的损失函数是:
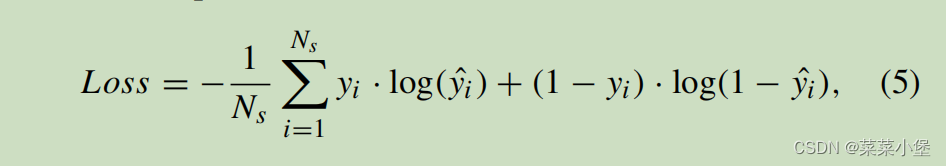
N s N_s Ns是batch size,y_hat是预测结果,y是真实结果。
Self-Training Framework

其中的MC dropout是一种选择模型确定性较大的label给数据贴上。(个人理解类似于max_pooling,通过多次的选取特征明显的值来获取模型最能分辨的一些语句)。
MC dropout
其中 6 ,7 ,8 ,9 ,10几个公式在论文中展示了,效果就是从无标签的文本中选出最大特征的数据(这种数据对于basic model的训练效果最佳),从而实现对于整个模型的正循环的训练。
实验
dataset
使用IMDB和Twitter、News的文本,然后使用BERT-LSTM的架构训练一个VAE-stego的加密模型,对于每个模型,都使用了HC(Huffman Coding)和AC(Arithmetic Coding)两种编码方式来实现。
选择了嵌入率是,HC的candidate pool size 设为了32,每个单词的平均嵌入bit约为5。
AC的candidate pool size 设为了dictionary size,每个单词的平均嵌入bit约为7。
experimental settings
实验模型使用的bert,12层transformer,hidden dimension为768, 最大句子长度是128。
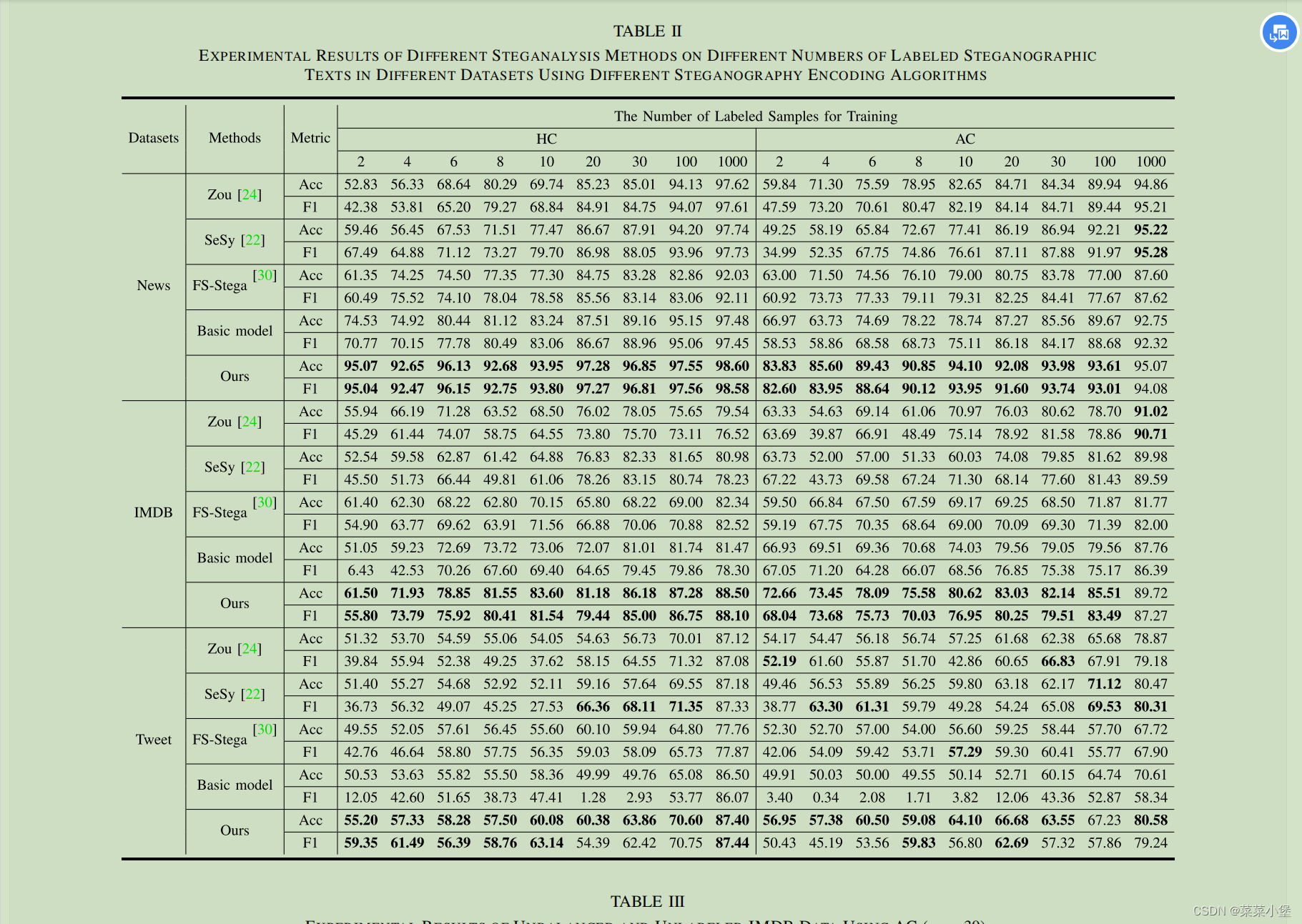
相同的steganalysis methods,做了对比试验,都使用bert作为基本模型,使用了 Zou,SeSy和FSStega进行了对比,在训练labeled sample小于等于10的情况下,作者的准确率(acc)要高于其他几个10%左右。
performance on unlabeled dataset
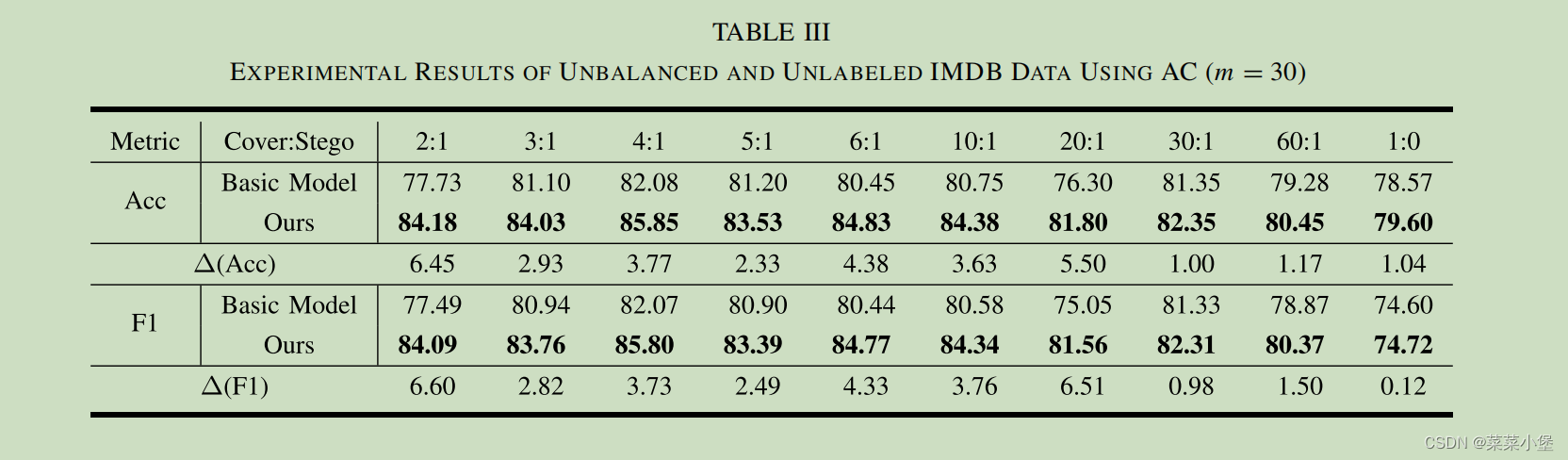
为了模拟真实场景(因为真实场景所含有的加密的样本比较少),作者把Cover:Stego的比例从2:1调整到1:0。然后在IMDB数据集上面的AC编码进行训练。由于训练的样本较少,基础模型不稳地,所以这次训练选择使用30个banlance labeled samples对之前的basic model进行再训练,然后再用unbalanced(正负样本比例不均衡) 和 unlabeled dataset对self-training进行训练。
Performance on Unlabeled Datasets With Mixed Language Styles
把三个数据集混合进行训练,按占比不同做新的数据集训练,然后按照训练的步骤再进行实验分类。

a是只进行basic model训练后的分类结果,b是通过unlabeled数据集训练后的分类结果,c是把a和b训练好的最终模型,来进行分类的结果(b产生的sample再进行a训练,把a的模型训练到最佳)。
Generality Test
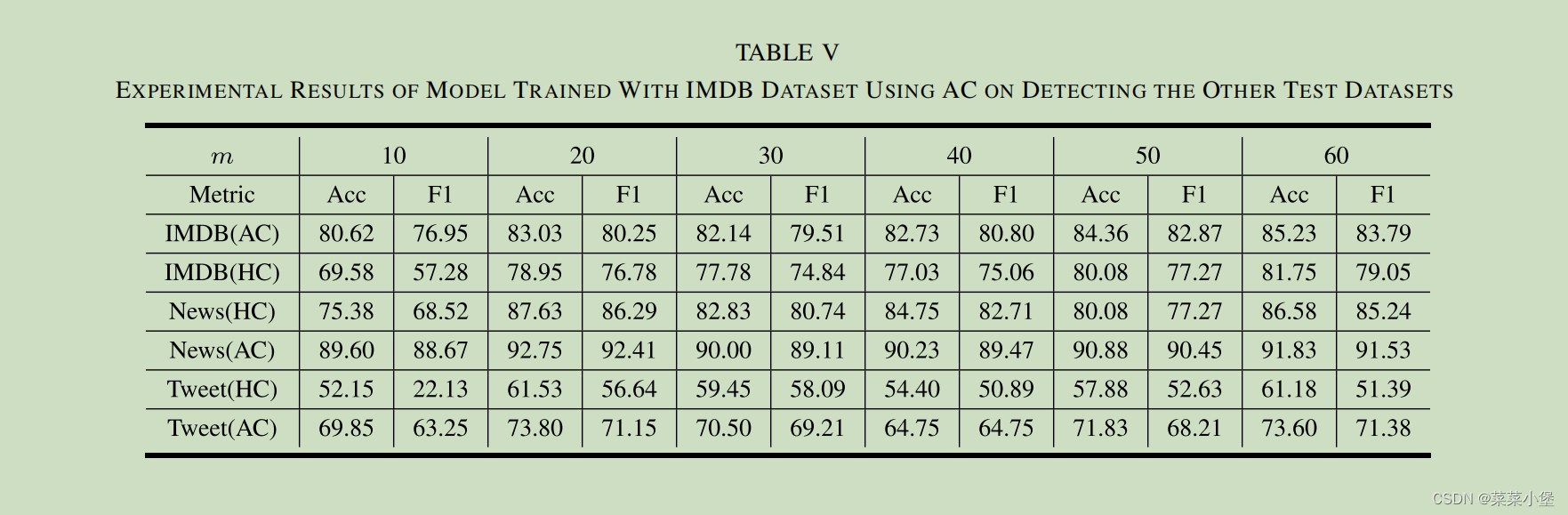
一共六个数据集,选用了IMDB的AC编码的数据集,来进行对其他5个数据集的验证测试。
Efficiency Test
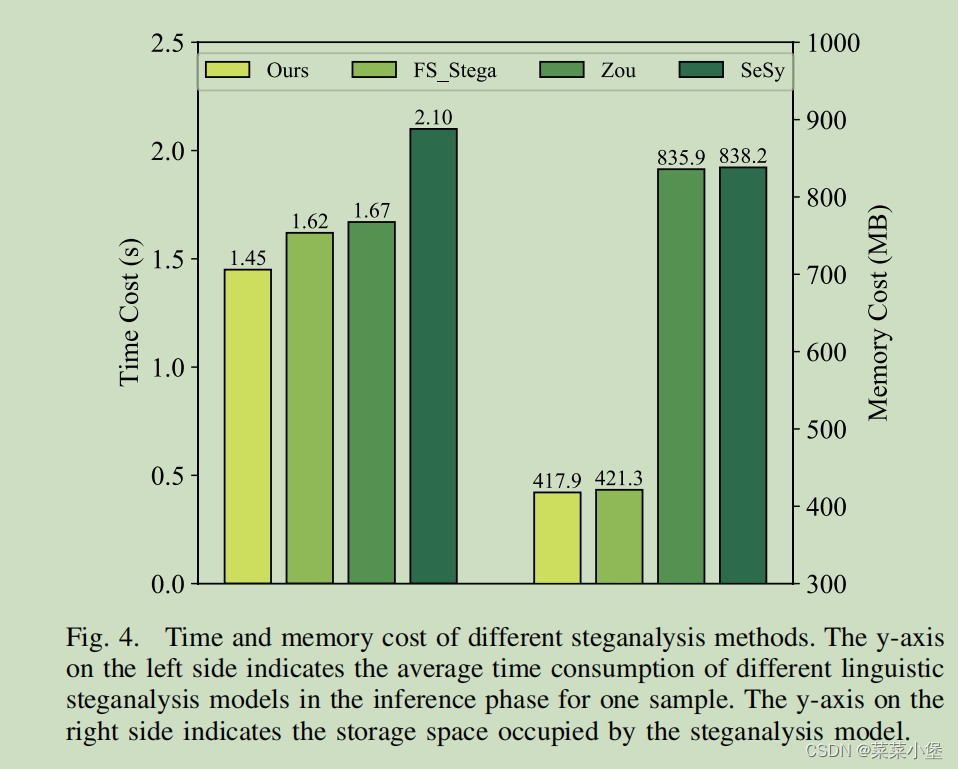
训练好的模型,做加密分析检测一次所需要的时间/内(显)存👆。
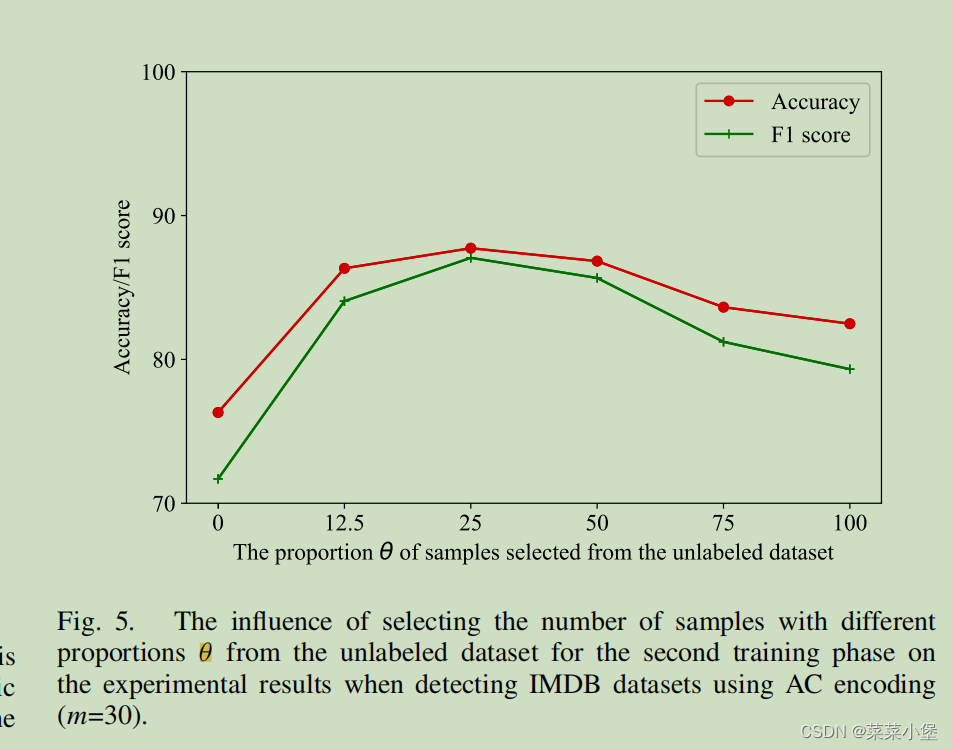
Hyper-Parameters Adoption
其中
θ
θ
θ是当unlableed产生假标记的数据后,labeled的数据(原始数据)再放进去训练basic model的比例(100%)则为完全的有监督学习。
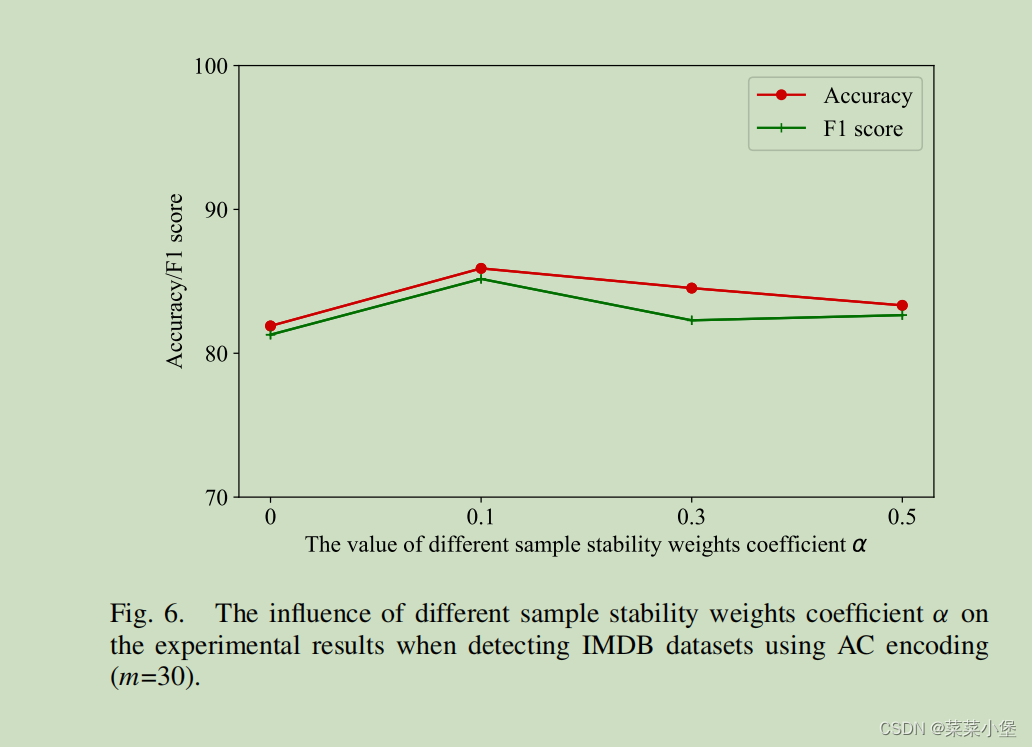
其中的
α
α
α是等式9的可更改选择加标签数据的比例。
作者做的实验是真的全面,佩服!