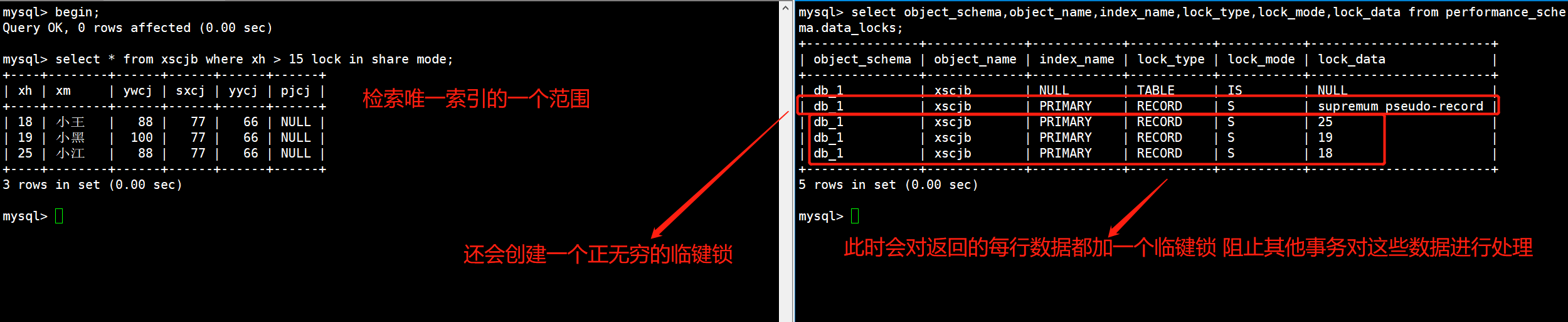
常规文件的权限是什么?如何分配或修改这些权限?文件夹(目录)的权限是什么?显示常规文件和文件夹的区别
讨论:①常规的文件权限有四种,r可读、w可写、x可执行、-没有权限;②可以使用chmod命令来分配或者修改文件的权限,其语法是 chomd 权限 filename ;③linux是一个多用户多任务的操作系统,可以通过用户好用户组来更好的控制目录文件的权限,具体说来就是:每一个文件都有一个拥有者,该拥有则属于某一个用户组,每一个文件的权限可以细分为三组(拥有者权限、用户组其他用户的权限、其他用户权限),可以使用 chmod 拥有者:所属组 目录 来修改文件的权限,可以使用ls -la来查看文件的权限;④显示常规文件其第一列的第一个字母为-,而目录文件的第一列的第一个字母为d,常规来讲,一个文件的默认访问权限是 -rw-rw-rw-,一个目录的默认访问权限是drwxrwxrwx。⑤对于目录来讲,r表示对其下文件可读,w表示对文件夹可添加可删除,x表示可以进入到该目录。
当无法执行命令“chown、chgrp、chmod”等,请给出可能的原因,如何保证成功执行。
讨论:linux对于文件的管理最常用的命令有“chown、chgrp和chmod”,chown用来改变文件的所有权,这个命令只有root用户可以使用;chgrp也是只有root用户可以使用;chmod对于文件的所有者和root用户都可以使用;如果无法执行以上的命令,可以切换到root用户再来执行。
怎么新建一个目录?如何复制或者删除一个非空的目录。
讨论:①可以使用mkdir新建一个空的目录;②可以使用cp -r old new 对非空目录进行复制,rm -r old 对非空目录进行删除。
当用户使用“mv a b”,请表示出b如果是一个文件、目录或者不存在时的可能性。
讨论:mv命令可以将文件或者目录移动到另一个目录,或者对文件进行改名。如果b是一个文件,系统会把a改名为b,原来的b会被覆盖;如果b是一个目录,系统会把文件a移动到b的目录下,作为b的子文件(如果b本身也有名为a的文件,原来b下的a会被覆盖);如果b不存在,系统会把a改名成b。
什么是文件系统?请举个例子。(也许你可以使用U盘)
讨论:操作系统中用于负责管理和存储文件信息的软件机构称为文件管理系统,简称文件系统。在linux中,文件系统必须先被挂载才能使用可以使用mount和umount去挂载或者卸载一个文件,被挂载的文件会被暂时覆盖,一般只有使用超级用户才可以实现该权限。
sda1表示第一块硬盘的第一个分区;
sdb表示第二块硬盘。
比如mount /dev/sdb /home/aa:这个命令表示把sdb的文件挂在到aa目录下。
可以使用df来显示文件的的挂载情况。
什么是管道,怎么去使用管道去创建一个组合命令,请给出一个例子。
讨论:①管道是linux的一种通信机制,管道可以实现把一个程序的输出直接连接到另一个程序的输入,从本质上讲,管道是一种特殊的文件;②可以使用管道符 | 来建立管道,格式命令为 a | b,表示a的输出作为b的输入,比如可以使用组合命令 find . -name . p*.c -print|xargs grep include ,这条命令的意思是把所有名字以p开头,以.c结尾的文件找到,并且把这些文件的 include 字符都找到。
使用 ls -l | more,这也是常用的管道命令。
管道符可以一直连续的使用,换句话说一条组合命令可以使用多个管道符。
假设一个人正在读取一个大型的程序的源代码,他想要检查一个函数的定义,这个函数不在当前的读取文件中,你对他有什么建议。
讨论:可以使用查找定位的方式,在linux中可以使用find进行查找文件,使用grep对文件内容进行匹配。一般来说一个函数的定义存在于头文件中,可以使用 find -e filename.h,查找文件,使用grep functionName filename.h 来查找文件内容。
组合起来可以使用以下组合命令: find -e *.h | xargs grep functionName。
如果一个人想要在网上发送一个大型的程序的所有文件给他的舍友,你可以给他一些建议吗。
讨论:可以使用打包压缩的方式对文件进行处理,方便网络上的传输。在linux上,可以使用tar对文件进行打包成一个文件,使用gzip和bzip2对文件进行压缩,可以大大节省内存。例如可以使用 tar cvf asd a把打包成asd文件,使用 gzip把asd压缩成压缩文件,再传输。
可以使用tar vtf filename 查看filename文件的打包的情况,但是并不解开打包
假设网下登录TTY1,但是由于某一种原因停止了,你能给出一个解决的方案吗?
讨论:可以使用ps -t tty1 查看其中的命令,然后可以使用kill -9 PID 来杀死进程。杀死进程后,可以使用密码重新登录,继续其他的内容。
假设四个人(李、张、王、赵)在一个小组中开发一个系统。如何为其文件分配权限通常情况下,640是合理的。但是,如果只能使用“chmod”来修改权限,那就太天真了。您需要修改每个用户的默认设置,以确保在创建文件时拥有正确的权限。(也许你需要在互联网上搜索学习命令umask、useradd、groupadd等。)
讨论:若用户创建一个文件,则文件的默认访问权限为 -rw-rw-rw- ,创建目录的默认权限drwxrwxrwx ,而umask值则表明了需要从默认权限中去掉哪些权限来成为最终的默认权限值,umask 026 表示后续添加的文件的权限均为640(两个值相加为666),但是添加命令断电后命令就会失效;useradd用来添加用户;groupadd用来添加用户组。
详情可以查看:https://blog.csdn.net/yspg_217/article/details/121900800
描述使用vi的两种模式,如何打开两种模式
讨论:①vi有两种模式,一种是编辑模式,一种是命令模式。②使用vi filename 可以进入vi ,这个时候vi处于命令模式,在命令模式下,可以使用i 进入到编辑模式,表示从当前光标位置开始插入;可以使用a进入编辑模式,表示从当前光标位置的下一个位置开始插入文字;使用小写o表示从新的一行的行首开始插入文件;使用大写O表示从光标所在行的上面的新的一行插入文字。③在编辑模式下,使用esc可以回到命令模式下。
如何插入一行
讨论:在命令模式下,使用小写o表示从新的一行的行首开始插入文件;使用大写O表示从光标所在行的上面的新的一行插入文字。
怎么复制粘贴一行文本
讨论:①在命令模式下,vi使用yy复制光标所在的行;使用数字+yy表示复制光标所在的后n行;使用yw复制光标所在的第一个单词,使用数字+yw复制光标所在的n个单词;②vi使用小写字母p来粘贴缓冲区的字符到光标所在位置。
怎么在文件中匹配,怎么替换所匹配到的内容
讨论:①在命令模式下,vi使用/+搜索词对文件进行匹配,匹配成功后,可以使用小写n对匹配项从上而下移动,或者使用大写N对匹配项从下而上移动;②在命令模式下,可以使用s命令对光标所在位置的字符进行编辑,编辑后退出编辑模式,使用n在匹配项中移动,再使用 . 来重复上一条编辑指令;③可以使用全局替换指令对内容进行匹配和替换,指令举例如下:1,$s/old/new/g。
怎么重复或者撤销上一条命令
讨论:可以使用 . 重复上一条指令;使用 u 撤销上一条指令。
怎么在保存或者不保存的情况下退出vi
讨论:如果不需要保存,可以使用 :q! 强制退出vi,如果需要保存,可以使用 :qw 退出,其中w表示存盘。
问题一:如何定义和使用shell变量,给出一个例子
讨论:使用shell变量有三种方法,一种是用等号直接赋值,比如a=123;第二种是从键盘中读入,比如read b;第三种是使用for循环变量,比如 for i in a b c,可以对i循环赋值为a b c。
问题二:if/while语句可以利用多少种类型的判断?
讨论:if/while语句可以有三种类型的判断,一种是字符串的判断,比如判断写入的数据是否是yes/no;第二种是文件的判断,比如使用 -f 判断文件是否存在,使用 -d 判断文件是否是一个目录;第三种是判断一个值是否相等,shell变量虽然都是字符串,但是可以使用$()对字符串取值。
数值比较:-eq(等于)、-ne(不等于)、-gt(大于)、-ge(大于等于)、-lt(小于)、-le(小于等于)
字符串比较:=(等于)、!=(不等于)、-z(字符串长度为零)、-n(字符串长度不为零)
文件测试:-e(文件存在)、-d(目录存在)、-f(文件是否为文本)、-r/-w/-x(文件是否可读/可写/可执行)
逻辑运算:&&(与)、||(或)
其他特殊操作符:()(子shell)、[](数组)
问题三:什么是正则表达式,怎么样使用正则表达式去匹配得更加清楚
讨论:正则表达式可以用来匹配符合某一种规则的字符,以case语句中,需要匹配no的各种大小写的可能性,可以使用正则匹配 [Nn][Oo] | [Nn] ,这样可以使得条件表达式更加简洁。
正则表达式是一种用于匹配和操作文本的强大工具。它可以用来定义模式,从而实现更灵活和精确的文本搜索和替换。
以下是一些正则表达式的示例:
^hello:匹配以"hello"开头的字符串。world$:匹配以"world"结尾的字符串。[0-9]+:匹配一个或多个数字。.*:匹配任意字符(除了换行符)的任意次数。
通过使用正则表达式,我们可以创建更清晰的模式,以便更准确地匹配我们所需的文本。
问题四:程序(可执行文件)的参数是什么,函数的参数是什么,举例说明如何使用这些参数。
讨论:程序的位置参数和函数的位置参数是不同的,①程序的参数指的是整一个程序(命令的)参数,比如在命令行中输入ls -la ,该命令中的 -la 就是该命令的第一个参数,用 $1 表示;②函数的参数表示函数调用时传递的参数,跟在函数调用的后面。
问题五:什么是sed,什么是awk,举例说明怎么使用他们
讨论:sed是一个“流编辑”工具,它不面向屏幕,而且是非交互式的,流编辑器非常适合于执行重复的编辑,这种重复的编辑如果由人工完成将花费大量的时间,例如 echo “frankreich” | sed -e ‘s/frank/deutsch/’ 可以把前面的frank换成deutsch。
awk也是一个优秀的样式扫描和处理工具,awk的功能强于sed和grep,awk几乎可以完成grep和sed所能完成的全部工作。例如 who | awk ‘pts/1{print $1}’ 可以导出pts/1终端上登录的用户
请用代码展示使用标准c语言和使用系统调用来操控文件的区别
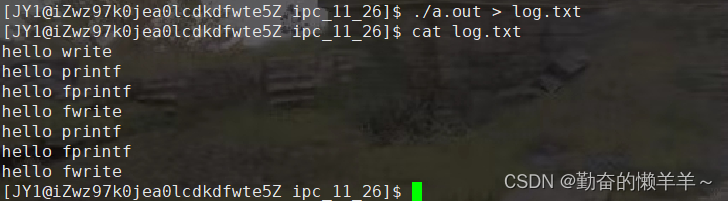
讨论:使用标准的c函数操控文件的函数包括fopen、fgets、fputc、fclose等,并且使用标准c函数操控的是文件的指针类型;而使用系统调用操控文件的函数包括open、read、write等,使用系统调用操控的是文件的描述符。一般来说,系统调用通常比标准c调用的效率高,这是因为标准c函数需要进行额外的库函数调用和缓冲操作。此外,标准c函数是跨平台的。而系统调用因为是直接调用操作系统的功能,所以可能在不同的操作系统中有不同的实现。
什么是mmap,怎么使用mmap来在多进程中共享内存
讨论:mmap是内存映射文件的一种方法,即将一个文件或者其他的映射对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址的映射关系。使用mmap进行映射,会得到磁盘和某一个文件的地址相同的地址,实现内存的共享
什么是文件夹?你能在文件夹里写点什么吗?为什么?描述文件夹的结构,并使用代码演示如何扫描文件夹。
讨论:文件目录对应的是文件的属性信息,文件的属性信息与文件的实体不是存在在一个位置上的,把文件的属性信息存放在一个位置,这一类的文件叫做目录文件,也就是windows上的文件夹。
在linux中,一切皆文件,目录也是一个文件,也有属于自己的innode,与普通文件不同,普通文件的数据块中存放的是文件数据,而目录文件的数据块中存储的是别的文件的信息,一条这样的信息就是一个FCB,也就是一个文件目录项,FCB的有序集合称为文件目录。
FCB包含文件的基本信息(文件名、物理地址、逻辑结构、物理结构等)、存储控制信息(可读可写可执行)、使用信息(文件建立时间、文件修改时间)
目录信息不可修改,因为目录信息保存的是文件的文件名,文件存放的物理地址等,这是在文件创建的时候就已经确定的。

在linux中,系统的目录呈现树状结构,最顶端为根目录/,根目录之下包含各个系统必须的目录。linux根目录下都是重要的目录,每一个目录都有其作用,不可随意删除
写一个自己版本的grep命令
略
gcc编译器对程序的编译过程
预编译(预处理):在这个阶段主要做了三件事情:展开头文件、宏替换、去掉注释行,这一阶段由gcc的预处理器完成,最终得到的还是源文件,文本格式。
编译:这个阶段需要调用gcc编译器对文件进行编译,最终得到一个汇编文件
汇编:这个阶段需要调用gcc的汇编器对文件进行汇编,最终得到一个二进制文件
链接:这个阶段需要调用gcc的链接器对程序需要调用的库进行链接,得到一个可以执行的文件
make构建工具
make是揭示makefile指令的命令工具,make构造项目的时候需要加载一个makefile的文件。
makefile中每一条规则都有三个部分组成:目标、依赖和命令(每一个命令都必须使用Tab缩进且独占一行)
略
fotk语句执行成功后,会返回一个子进程的pid给父进程,并且返回0给子进程,由于父子进程并发执行,所以这个时候x的值为1或者-1都有可能,看父子进程谁先被调用。
尝试使用wait和waitid来同步父子进程的执行
child_pid=wait(&stat_val);//父进程等待任意一个子进程结束完成
child_pid=wait(child_id,&stat_val,0);//父进程等待pid=child_id子进程的结束,如果pid=-1与wait一直,stat_val表示进程退出状态
什么是execl函数簇
execl函数簇不是指一个函数,而是execl函数的统称,execl函数可以在不创建新进程的情况下,以一个全新的程序替换当前的程序的正文、数据和堆栈。
例如.c程序中使用ls命令替换当前.c程序进行execlp(“ls”,“ls”,0);第一个参数ls为命令名,第二个ls为第一个参数,.c程序执行到这行代码时,会直接执行ls命令,后面的代码不执行。
在一个程序中有多少种信号,怎么使用一个用户定义信号
在linux系统中一共含有32种信号,可以使用kill -10 9969给pid=9969的进程发送信号10
#include<signal.h>
#include<stdio.h>
#include<unistd.h>
#include<signal.h>
void signal_handle(int sig_num){
if(sig_num==SIGUSR1)
printf("SIGUSR1-----\n");//在命令行中发送SIGUSR1信号可以执行signal_handle函数
printf("signal_handle\n");
}
int main(){
signal(SIGUSR1,signal_handle);
while(1){
printf("main------\n");
sleep(1);
}
return 0;
}
在程序运行过程中,使用kill -s SIGUSR1 pid可以在命令行中发送对应的执行给程序,从而执行信号所对应的信号处理函数。
signal和sigaction的区别是什么
下面所指的signal都是指以前的older signal函数,现在大多系统都用sigaction重新实现了signal函数,不会出现空窗期。
- signal在调用函数hander之前会有一段空窗期,在空窗期期间会先把hander指针恢复,这样会导致signal丢失信号,不能处理重复的信号;sigaction调用之后不会恢复hander指针,只有当再次调用sigaction修改handle指针才会恢复。
阅读以下代码,确定x的值,并在此基础上,说明进程和线程之间的区别
在以上代码中,x的值最后为-1。x的值在主线程中初始化为0,然后在主线程中设为1,在创建的线程fun中设置为-1。
线程和进程的区别在于:线程是调度的基本单位,进程是资源分配的基本单位;进程是程序的执行实例,是独立拥有存储空间的运行单位,每一个进程都有自己的地址空间、数据栈以及其他用于跟踪进程执行的辅助数据;线程是进程的一条的一条独立路径,线程几乎不独立拥有资源,线程共享进程的资源,包括文件描述符等,线程共享相同的地址空间,因此以上的x是会被主线程和其他线程共享。
如何进行线程的同步
①可以使用信号量控制线程的执行顺序,比如sem_init初始化一个信号量;sem_post相当于原子操作的V操作;sem_wait相当于原子操作的P操作;
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<string.h>
#include<pthread.h>
#include<semaphore.h>
void *thread_function(void *arg);
sem_t bin_sem;
#define WORK_SIZE 1024
char work_area[WORK_SIZE];
int main(){
int res;
pthread_t a_thread;
void *thread_result;
res=sem_init(&bin_sem,0,0);//信号量初始化为0
if(res!=0){
printf("Semaphore initialization failed");
exit(EXIT_FAILURE);
}
res=pthread_create(&a_thread,NULL,thread_function,NULL);
if(res!=0){
perror("Thread creation failed");
exit(EXIT_FAILURE);
}
printf("Input some text. Enter 'end' to finish\n");
while(strncmp("end",work_area,3)!=0){
fgets(work_area,WORK_SIZE,stdin);
sem_post(&bin_sem);
}
printf("\nWaiting for thread to finish\n");
res=pthread_join(a_thread,&thread_result);
if(res!=0){
perror("Thread join failed");
exit(EXIT_FAILURE);
}
printf("Thread join\n");
sem_destroy(&bin_sem);//清除信号资源
exit(EXIT_SUCCESS);
}
void * thread_function(void *arg){
sem_wait(&bin_sem);
while(strncmp("end",work_area,3)!=0){
printf("You input %d characters\n",strlen(work_area)-1);
sem_wait(&bin_sem);
}
pthread_exit(NULL);
}
②也可以使用互斥锁进行同步:pthread_mutex_init用来初始化一个互斥锁,pthread_mutex_lock、pthread_mutex_unlock进行加锁和解锁操作,pthread_mutex_destroy用来释放锁操作。
pthread_mutex_t mutex;
pthread_mutex_init(&mutex,NULL); ///< 初始化互斥锁
pthread_mutex_lock(&mutex); ///< 加锁
///< 操作公共资源
pthread_mutex_unlock(&mutex); ///< 解锁
pthread_mutex_destroy(&mutex); ///< 销毁互斥锁
请设计使用进程和线程实现相同目标的程序,请说明你对进程/线程应用范围的看法
使用进程(在C中使用fork):
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
int main() {
int x = 0;
if (fork() == 0) {
// 子进程
x++;
printf("子进程:x = %d\n", x);
} else {
// 父进程
wait(NULL);
printf("父进程:x = %d\n", x);
}
return 0;
}
[cch@aubin os]$ gcc demo.c
[cch@aubin os]$ ./a.out
子进程:x = 1
父进程:x = 0
[cch@aubin os]$
使用线程(在C中使用pthread):
#include <pthread.h>
#include <stdio.h>
int x = 0;
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
void *increment(void *arg) {
pthread_mutex_lock(&mutex);
x++;
printf("线程:x = %d\n", x);
pthread_mutex_unlock(&mutex);
return NULL;
}
int main() {
pthread_t thread1, thread2;
pthread_create(&thread1, NULL, increment, NULL);
pthread_create(&thread2, NULL, increment, NULL);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
printf("主线程:x = %d\n", x);
return 0;
}
[cch@aubin os]$ ./a.out
线程:x = 1
线程:x = 2
主线程:x = 2
[cch@aubin os]$
进程的应用范围:
并行计算: 进程适用于需要充分利用多核处理器进行并行计算的场景。每个进程有独立的内存空间,可以并行执行,提高计算效率。
稳定性: 进程之间的独立性可以提高程序的稳定性。一个进程的崩溃不会影响其他进程的执行。
资源隔离: 进程之间有独立的内存空间,可以更好地实现资源隔离,确保一个进程的错误不会波及到其他进程。
线程的应用范围:
轻量级任务: 线程适用于需要执行相对轻量级任务的场景,例如I/O密集型任务。线程的创建和切换开销较小。
共享内存: 线程之间共享同一进程的内存空间,适合在同一应用程序内共享数据。
响应性: 线程可用于实现更快的响应时间,例如在GUI应用程序中响应用户输入。
有名管道和无名管道的区别
无名管道
匿名性: 未命名管道是一种临时通信机制,没有明确的文件系统路径或标识符。它通常是由一个进程创建,并通过进程间的文件描述符传递给另一个进程使用。
单向通信: 未命名管道是单向的,无名管道的读端和写端是固定的,只能支持单向的数据流。通常,一个进程作为写入端,而另一个进程作为读取端。
生命周期: 未命名管道的生命周期与创建它的进程相关。当创建它的进程终止时,管道也会被销毁。
通信限制: 未命名管道通常在具有亲缘关系的进程之间使用,因为它们共享同一个父进程。
命名管道:
命名: 命名管道在文件系统中有一个明确的路径名,可以通过文件系统访问。它有一个标识符,允许不相关的进程通过路径名进行通信。
双向通信: 命名管道支持双向通信,进程可以通过相同的路径名进行读取和写入。
生命周期: 命名管道的生命周期不依赖于创建它的进程。它可以持续存在,直到显式地被删除或系统关闭。
通信范围: 命名管道允许不相关的进程进行通信,因为它们可以通过路径名引用。
无名管道和有名管道都不支持seek操作
代码展示如何实现管道的重定向IO
使用无名管道时,还可以搭配使用close()关闭文件描述符和dup()复制管道文件描述符来实现输入输出标准的重定向。
#defiine STD_INPUT 0
#define STD_OUTPUT 1
int main()
{
int fd[2];
int pid;
char str[256];
if (pipe(fd)<0) {
perror(“pipe create error!”);
exit(1);
}
if ((pid = fork())==-1) {
perror(“process fork error!”);
exit(1);
}
if (pid == 0) {//子进程
close(fd[0]);
close(STD_OUTPUT);
dup(fd[1]);
close(fd[1]);
printf(“abc\n”);//把数据输出到管道,管道写数据
}
else {//父进程
close(fd[1]);
close(STD_INPUT);
dup(fd[0]);
close(fd[0]);
fgets(str,sizeof(str),stdin);//从键盘输入数据到管道,管道读数据
printf(“%s\n”,str);
}
}
写代码表示两个程序的管道通信
//pipe4.c
#include<unistd.h>
#include<stdlib.h>
#include<stdio.h>
#include<string.h>
int main(int argc,char *argv[]){
int data_processed;
char buffer[BUFSIZ+1];
int file_descriptor;
memset(buffer,'\0',sizeof(buffer));
sscanf(argv[1],"%d",&file_descriptor);//读取格式化的argv[1]给file_descriptor
data_processed=read(file_descriptor,buffer,BUFSIZ);
printf("%d-read %d bytes:%s\n",getpid(),data_processed,buffer);
exit(EXIT_FAILURE);
}
# 0表示键盘,从键盘中读取输入并且输出
[cch@aubin os]$gcc pipe4.c -o pipe
[cch@aubin os]$ ./pipe 0
123466
4947-read 7 bytes:123466
[cch@aubin os]$
#include<unistd.h>
#include<stdlib.h>
#include<stdio.h>
#include<string.h>
int main(){
int data_processed;
int file_pipes[2];
const char some_data[]="123";
char buffer[BUFSIZ+1];
pid_t fork_result;
memset(buffer,'\0',sizeof(buffer));
if(pipe(file_pipes)==0){
fork_result=fork();
if(fork_result==-1){
fprintf(stderr,"Fork failure");
exit(EXIT_FAILURE);
}
//子进程
if(fork_result==0){
sprintf(buffer,"%d",file_pipes[0]);//将file_pipes[0]转换成字符串,以适应execl调用中参数类型的要求,其中fotmat参数与print中的类型一致
/*
execlp("ls", "ls", "-l", "-F", NULL); 使用程序名在PATH中搜索。
execl("/bin/ls", "ls", "-l", "-F", NULL); 使用参数1给出的绝对路径搜索。
*/
if(execl("pipe","pipe",buffer,(char *)0)==-1)
printf("execl error\n");
exit(EXIT_FAILURE);
}else{
data_processed=write(file_pipes[1],some_data,strlen(some_data));
printf("father:Wrote %d bytes\n",data_processed);
}
exit(EXIT_SUCCESS);
}
exit(EXIT_FAILURE);
}
[cch@aubin os]$ gcc demo.c
[cch@aubin os]$ ./a.out
father:Wrote 3 bytes
argv[1]=3
6098-read 3 bytes:123
[cch@aubin os]$
使用代码展示信号量、共享内存和消息队列的典型应用场景。
信号量:
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/ipc.h>
#include<sys/sem.h>
int main(){
//创建一个信号量集,并且设置信号量集中信号量的值为1
key_t key=12345;
int sem_id=semget(key,1,0666|IPC_CREAT);//不存在就创建
if(sem_id==-1)
{
perror("semget error");
exit(1);
}
//对信号了p操作
struct sembuf sops;
sops.sem_num=0;
sops.sem_op=-1;//p
sop.sem_flg=0;
if(semop(sem_id,&sops,1)<0){
perror("semop error");
return -1;
}
//互斥区
printf("互斥区操作\n");
sops.sem_op=1;//v操作
if(semop(sem_id,&sops,1)<0){
perror("semop error");
return -1;
}
//删除信号量
if(semctl(sem_id,0,IPC_RMID)<0)
{
perror("semctl error");
return -1;
}
/*
union semun{
int val;
struct semid_ds *buf;
ushort *array;
}argument;
argument.val=1;
if(semctl(sem_id,0,SETVAL,argument)==-1){//设置信号量的值
perror("semctl error");
exit(1);
}
*/
return 0;
}
共享内存:
//share2.c
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <stdlib.h>
#include <fcntl.h>
#include <string.h>
#include <errno.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#define MAXBUFSIZE 4096
#define SHAREMEMESIZE 4096
int read_file(char *buf, int size, const char *filename);
int main() {
int n, shm_id;
char buf[MAXBUFSIZE] = {0};
char *shm_p = NULL;
/*
获取共享内存,如果不存在则创建
*/
if ( (shm_id = shmget(0x666, SHAREMEMESIZE, 0644 | IPC_CREAT)) < 0) {
perror("shmget error");
return 1;
}
/*
把共享内存链接到当前进程的地址空间
*/
shm_p = (char *)shmat(shm_id, NULL, 0);
if (shm_p == (void *) -1) {
perror("shmat error:");
return 1;
}
// 从文件中读取数据
n = read_file(buf, MAXBUFSIZE, "./read_text");
if (n == -1) {
return 1;
}
printf("read from file: %s\n", buf);
// 将数据拷贝到共享内存
memcpy(shm_p, buf, strlen(buf));
// 把共享内存从当前进程分离
shmdt(shm_p);
return 0;
}
// 读文件内容到buf
int read_file(char *buf, int size, const char *filename) {
int fd, n;
// 打开read_test
if ( (fd = open(filename, O_RDONLY)) < 0) {
perror("open file_read_test error:");
return -1;
}
// 读取文件内容
n = read(fd, buf, size);
if (n < 0) {
perror("read file error:");
return -1;
}
// 关闭文件
close(fd);
return n;
}
//share
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <stdlib.h>
#include <fcntl.h>
#include <errno.h>
#include <string.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#define MAXBUFSIZE 4096
#define SHAREMEMESIZE 4096
int write_file(const char *buf, int size, const char *filename);
int main() {
int shm_id;
char buf[MAXBUFSIZE] = {0};
char *shm_p = NULL;
/*
获取共享内存,如果不存在则创建
*/
if ( (shm_id = shmget(0x666, SHAREMEMESIZE, 0644)) < 0) {
perror("shmget error");
return 1;
}
/*
把共享内存链接到当前进程的地址空间
*/
shm_p = (char *)shmat(shm_id, NULL, 0);
if (shm_p == (void *) -1) {
perror("shmat error:");
return 1;
}
// 拷贝共享内存中的数据
memcpy(buf, shm_p, MAXBUFSIZE);
// 将共享内存中的内容写入write_text文件中
write_file(buf, strlen(buf), "write_text");
printf("write to file: %s\n", buf);
// 把共享内存从当前进程分离
shmdt(shm_p);
//删除共享内存
if (shmctl(shm_id, IPC_RMID, 0) == -1) {
printf("shmctl failed\n");
return -1;
}
return 0;
}
// 将buf中的数据写入文件
int write_file(const char *buf, int size, const char *filename) {
int fd, n;
// 打开文件,不存在则创建
if ((fd = open(filename, O_WRONLY | O_CREAT, 0644)) < 0) {
perror("open file error:");
return -1;
}
// 写入内容
n = write(fd, buf, size);
if (n < 0) {
perror("write file error");
return -1;
}
close(fd);
return n;
}
[cch@aubin ipc]$ gcc share.c -o share
[cch@aubin ipc]$ gcc share2.c -o share2
[cch@aubin ipc]$ ./share2
read from file: this is read text
[cch@aubin ipc]$ ./share
write to file: this is read text
[cch@aubin ipc]$
消息队列:
//running.c
#include<stdlib.h>
#include<stdio.h>
#include<string.h>
#include<errno.h>
#include<unistd.h>
#include<sys/msg.h>
#define MAX_TEXT 512
struct my_msg_st {
long int my_msg_type;
char some_text[MAX_TEXT];
};
int main(){
int running=1;
struct my_msg_st some_data;
int msgid;
char buffer[BUFSIZ];
msgid=msgget((key_t)1234,0666|IPC_CREAT);
if(msgid==-1){
fprintf(stderr,"msgget failed with error:%d\n",errno);
exit(EXIT_FAILURE);
}
while(running){
printf("Enter some text:");
fgets(buffer,BUFSIZ,stdin);
some_data.my_msg_type=1;
strcpy(some_data.some_text,buffer);
if(msgsnd(msgid,(void*)&some_data,MAX_TEXT,0)==-1){//send 发送消息到msgid中
fprintf(stderr,"msgsnd failed\n");
exit(EXIT_FAILURE);
}
if(strncmp(some_data.some_text,"end",3)==0) running=0;
}
exit(EXIT_SUCCESS);
}
//running2.c
#include<stdlib.h>
#include<stdio.h>
#include<string.h>
#include<errno.h>
#include<unistd.h>
#include<sys/msg.h>
#define MAX_TEXT 512
struct my_msg_st {
long int my_msg_type;
char some_text[MAX_TEXT];
};
int main(){
int running=1;
int msgid;
struct my_msg_st some_data;
long int msg_to_receive=0;//接受消息类型设置,按照先进先出的顺序接收数据
//获取消息队列
msgid=msgget((key_t)1234,0666|IPC_CREAT);
if(msgid==-1){
fprintf(stderr,"msgget failed with error:%d\n",errno);
exit(EXIT_FAILURE);
}
while(running){
if(msgrcv(msgid,(void*)&some_data,BUFSIZ,msg_to_receive,0)==-1){
fprintf(stderr,"msgrcv failed with error:%d\n",errno);
exit(EXIT_FAILURE);
}
printf("You wrote:%s",some_data.some_text);
if(strncmp(some_data.some_text,"end",3)==0) running=0;
}
if(msgctl(msgid,IPC_RMID,0)==-1){//把消息队列删除
fprintf(stderr,"msgctl(IPC_RMID)failed\n");
exit(EXIT_FAILURE);
}
exit(EXIT_SUCCESS);
}
使用代码来显示POSIX信号量和IPC信号量之间的差异。
Posix信号量
#include <stdio.h>
#include <semaphore.h>
#include <fcntl.h>
int main() {
// 创建和初始化POSIX信号量
sem_t *posix_sem = sem_open("/my_posix_sem", O_CREAT, 0666, 1);
// 在临界区使用信号量
sem_wait(posix_sem);
// 临界区操作
printf("临界区操作\n");
sem_post(posix_sem);
// 删除POSIX信号量
sem_close(posix_sem);
sem_unlink("/my_posix_sem");
return 0;
}
IPC信号量:
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/ipc.h>
#include<sys/sem.h>
int main(){
//创建一个信号量集,并且设置信号量集中信号量的值为1
key_t key=12345;
int sem_id=semget(key,1,0666|IPC_CREAT);//不存在就创建
if(sem_id==-1)
{
perror("semget error");
exit(1);
}
//对信号p操作
struct sembuf sops;
sops.sem_num=0;
sops.sem_op=-1;//p
sop.sem_flg=0;
if(semop(sem_id,&sops,1)<0){
perror("semop error");
return -1;
}
//互斥区
printf("互斥区操作\n");
sops.sem_op=1;//v操作
if(semop(sem_id,&sops,1)<0){
perror("semop error");
return -1;
}
//删除信号量
if(semctl(sem_id,0,IPC_RMID)<0)
{
perror("semctl error");
return -1;
}
return 0;
}
posix信号量:
- posix信号量通常使用sem_open函数创建,信号由斜杠字符/开头的名称标识
- posix信号量可以在进程之间共享,进程可以使用上面的/开头的名称标识打开相同的信号量
- posix信号量支持使用sem_wait(P)、sem_post(V)、sem_close(关闭)等操作
- posix可以使用sem_ulink显示销毁,也可以在最后一个进程使用sem_close关闭信号量的时候自动销毁
System-V IPC信号量:
- 这种信号量通常使用semget系统调用创建,由一个整数标识符标识
- ipc信号量也可以在进程之间共享,但是这种共享是基于整数标识符而不是名称标识符
- ipc信号量的操作是使用semop系统调用来完成的,该调用允许在单个原子操作中执行一组信号量操作。
- ipc信号量使用带有IPC_RMID命令的semctl来删除信号量
在文件一章中,我们讨论了mmap(),它可以用于在进程之间共享内存。您能否将此技术与IPC的共享内存进行比较,并说明哪种技术更适合在进程之间共享大数据。
mmap: mmap是一种将文件内存映射到进程的虚拟地址空间的技术,在这种机制下,文件可以被视为内存的一部分,可以实现程序直接对这部分的内存进行读写操作,实现像访问内存一样对文件进行读写,这种方法提高了处理的效率,简化了文件的操作。
共享内存:共享内存使用的是shmget和shmat;共享内存提供semop,可以用于共享内存的进程之间的同步
二者区别:
数据源和持久化:
mmap: 通过 mmap 映射的数据通常来自文件系统中的文件。这意味着数据是持久化的——即使程序终止,文件中的数据依然存在。当你通过映射的内存区域修改数据时,这些更改最终会反映到磁盘上的文件中。
共享内存:共享内存是一块匿名的(或者有时与特定文件关联的)内存区域,它可以被多个进程访问。与 mmap 映射的文件不同,共享内存通常是非持久的,即数据仅在计算机运行时存在,一旦系统关闭或重启,存储在共享内存中的数据就会丢失。
使用场景:
mmap:mmap 特别适合于需要频繁读写大文件的场景,因为它可以减少磁盘 I/O 操作的次数。它也允许文件的一部分被映射到内存中,这对于处理大型文件尤为有用。
共享内存:共享内存通常用于进程间通信(IPC),允许多个进程访问相同的内存区域,这样可以非常高效地在进程之间交换数据。
性能和效率:
mmap:映射文件到内存可以提高文件访问的效率,尤其是对于随机访问或频繁读写的场景。系统可以利用虚拟内存管理和页面缓存机制来优化访问。
共享内存:共享内存提供了一种非常快速的数据交换方式,因为所有的通信都在内存中进行,没有文件 I/O 操作。
同步和一致性:
mmap:使用 mmap 时,必须考虑到文件内容的同步问题。例如,使用 msync 调用来确保内存中的更改被同步到磁盘文件中。
共享内存:在共享内存的环境中,进程需要使用某种形式的同步机制(如信号量、互斥锁)来避免竞争条件和数据不一致。
简而言之,mmap 主要用于将文件映射到内存以提高文件操作的效率,而共享内存主要用于进程间的高效数据交换。二者虽有相似之处,但各自适用于不同的应用场景,如果文件非常大,以至于无法或不方便完全加载到内存中时,可以使用mmap映射整个文件,并像访问内存数组一样访问文件的任何部分,而无需加载整个文件;如果是进程之间需要快速共享大量数据,可以使用共享内存。
如何在典型的应用场景中创建TCP和UDP套接字。
TCP:sockfd = socket(AF_INET, SOCK_STREAM,0);
UDP:sockfd =socket(AF_INET, SOCK_DGRAM,0);
描述了TCP/UDP通信中客户端和服务器的框架。使用代码展示如何创建并发服务器。
TCP服务器端:
通过上图我们可以看到服务器端的流程是:
调用socket()创建一个新的socket。
调用bind()将创建的socket绑定在一个地址上,即分配ip和端口。
调用listen()监听客户端访问。
调用accept()接收客户端的访问
调用read()/write()或者send()/recv()传输数据。
TCP客户端的流程是:
调用socket()创建一个新的socket
调用connect()将客户端通过地址请求连接到服务器的socket上。
调用read()/write()或者send()/recv()传输数据。
UDP服务器端的流程是:
调用socket()创建一个socket,类似于创建一个邮箱。
调用bind()绑定服务器的地址(一个众所周知的地址,比如一个公司的邮箱地址,以便允许客户访问)。
调用recvfrom()/sendto()接收、发送数据报。
调用close()关闭socket
UDP客户端的流程是:
调用socket()创建一个socket,类似于创建一个邮箱。
调用recvfrom()/sendto()接收、发送数据报。
调用close()关闭socket
使用代码显示select()、poll()函数的优点。
使用select和poll同时处理多个客户端连接请求
select代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#define MAX_CLIENTS 5
int main() {
int server_socket, client_sockets[MAX_CLIENTS];
fd_set readfds;
int max_sd, activity, new_socket, i;
struct sockaddr_in address;
int addrlen = sizeof(address);
// Create server socket
server_socket = socket(AF_INET, SOCK_STREAM, 0);
// Initialize sockaddr_in structure
// ...
// Bind server socket
// ...
// Listen for incoming connections
// ...
while (1) {
FD_ZERO(&readfds);
FD_SET(server_socket, &readfds);
max_sd = server_socket;
for (i = 0; i < MAX_CLIENTS; i++) {
int sd = client_sockets[i];
if (sd > 0)
FD_SET(sd, &readfds);
if (sd > max_sd)
max_sd = sd;
}
// Wait for an activity on any of the sockets
activity = select(max_sd + 1, &readfds, NULL, NULL, NULL);
// Handle activity on the server socket
if (FD_ISSET(server_socket, &readfds)) {
// Accept a new connection
new_socket = accept(server_socket, (struct sockaddr*)&address, (socklen_t*)&addrlen);
// Add the new socket to the array of client sockets
// ...
}
// Handle activity on client sockets
for (i = 0; i < MAX_CLIENTS; i++) {
int sd = client_sockets[i];
if (FD_ISSET(sd, &readfds)) {
// Handle data from client
// ...
}
}
}
return 0;
}
poll代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#define MAX_CLIENTS 5
int main() {
int server_socket, client_sockets[MAX_CLIENTS];
struct pollfd fds[MAX_CLIENTS + 1];
int nfds = 1; // including server socket
int i, ret;
struct sockaddr_in address;
int addrlen = sizeof(address);
// Create server socket
server_socket = socket(AF_INET, SOCK_STREAM, 0);
// Initialize sockaddr_in structure
// ...
// Bind server socket
// ...
// Listen for incoming connections
// ...
// Initialize pollfd structure for server socket
fds[0].fd = server_socket;
fds[0].events = POLLIN;
for (i = 0; i < MAX_CLIENTS; i++) {
fds[i + 1].fd = -1; // initialize client sockets to -1
}
while (1) {
// Wait for an activity on any of the sockets
ret = poll(fds, nfds, -1);
// Handle activity on the server socket
if (fds[0].revents & POLLIN) {
// Accept a new connection
client_sockets[nfds - 1] = accept(server_socket, (struct sockaddr*)&address, (socklen_t*)&addrlen);
fds[nfds].fd = client_sockets[nfds - 1];
fds[nfds].events = POLLIN;
nfds++;
}
// Handle activity on client sockets
for (i = 1; i < nfds; i++) {
if (fds[i].revents & POLLIN) {
// Handle data from client
// ...
}
}
}
return 0;
}
(1)select ()优点:
1)select 的可移植性更好,在某些 Unix 系统上不支持 poll。
2)select 对于超时值提供了更好的精度:微秒,而 poll 是毫秒。
(2)poll() 函数的优点:
1)poll 不要求开发者计算最大文件描述符加一的大小。
2)poll 在应付大数目的文件描述符的时候相比于 select 速度更快。
3)它没有最大连接数的限制,原因是它是基于链表来存储的。
// 使用select()
fd_set read_fds;
FD_ZERO(&read_fds);
FD_SET(socket1, &read_fds);
FD_SET(socket2, &read_fds);
select(max_socket + 1, &read_fds, NULL, NULL, NULL);
// 使用poll()
struct pollfd fds[2];
fds[0].fd = socket1;
fds[0].events = POLLIN;
fds[1].fd = socket2;
fds[1].events = POLLIN;
poll(fds, 2, timeout_in_milliseconds);