摘 要 基于卷积神经网络的人体行为识别的开发与设计
摘要:随着计算机领域不断的创新、其它行业对计算机的应用需求的提高以及社会对解放劳动力的迫切,人机交互成为人们关注的问题。深度学习的出现帮助了人们实现人机交互,而卷积神经网络是其的代表算法的一种,被普遍应用在计算机视觉领域实现图片识别。人体行为识别是指将一系列数据喂入训练好的神经网络,计算机对数据进行特征提取然后识别分类,其中数据包括视频、图片序列或者传感器数据等。
本文采用的网络结构包括4层卷积层、1层全连接层、1层最大池化层、1层平均池化层,使用了一维卷积、Relu激活函数、Softmax和Dropout技术。
采用的数据集为WISDM实验室的发布的第一版数据集,参与测试的人数共36人,使用加速度传感器,采样率为20HZ,数据集包含的行为类型共6种:Downstairs下楼梯、Jogging慢跑、Sitting坐、Standing站立、Upstairs上楼梯和Wallking走路。
本文的篇首分析了研究人体行为识别的背景和研究意义,介绍国内和国外的研究现状。接着详细介绍ANN相关的知识,及两个简单且具有代表性的网络结构。然后阐述CNN的相关理论知识其中包括传统的卷积神经网络结构,再重点介绍用于本文的CNN神经网络模型结构,以及如何用本文的设计的网络模型在WISDM数据集上实现行为识别。
最后对模型的性能进行分析,得到结论与提出建议,规划展望。
关键词:卷积神经网络、人体行为识别
Development and design of human behavior recognition based on convolutional neural network
Abstract:With the continuous innovation and breakthroughs in the computer field and the increasing demand for computer applications in other fields, human-computer interaction has become a concern of people. The emergence of deep learning has helped people achieve human-computer interaction, and convolutional neural network is one of its representative algorithms, which is widely used in the field of computer vision to realize picture recognition. Human behavior recognition refers to feeding a series of data into a trained neural network, and the computer performs feature extraction on the data and then recognizes and classifies the data, including data such as videos, image sequences, or sensor data.
The network structure used in this paper includes 4 convolutional layers, 1 fully connected layer, 1 maximum pooling layer, and 1 average pooling layer, using one-dimensional convolution, Relu activation function, Softmax and Dropout technology.
The data set used is the first version of the data set released by the WISDM laboratory. A total of 36 people participated in the test. The acceleration sensor is used and the sampling frequency is 20HZ. The data set contains 6 types of behaviors: Downstairs, Jogging Jog, Sitting, Standing, Upstairs and Walking.
The first part of this article analyzes the background and significance of research on human behavior recognition, and introduces the domestic and foreign research status. Next, we introduce ANN and two simple and representative network structures in detail, including related contents of neurons and activation functions. Then elaborate the relevant theoretical knowledge of convolutional neural networks, including the traditional convolutional neural network structure, and then focus on the CNN network model structure used in this article and how to use this neural network model to achieve human behavior recognition on the WISDM data set.
Finally, the performance of the model is analyzed, and conclusions and suggestions are made, and planning prospects.
Keywords:Convolutional neural network, human behavior recognition
目 录
第1章 绪 论 1
1.1 研究背景和意义 1
1.1.1 研究人体行为识别的目的 1
1.1.2 本课题的研究意义 1
1.2 国内外研究现状 2
1.2.1 国内研究 2
1.2.2 国外研究 2
1.3 课题研究方法和内容 3
1.3.1 研究方法 3
1.3.2 研究内容 3
第2章 人工神经网络 4
2.1 人工神经元 4
2.1.1 生物神经元 4
2.1.2 神经元 4
2.1.3 激活函数 5
2.1.4 损失函数 8
2.2 感知器神经网络 8
2.3 BP神经网络 9
第3章 卷积神经网络相关理论知识 11
3.1 前馈神经网络 11
3.2 卷积神经网络 12
3.2.1 卷积层 12
3.2.2 池化层 12
3.2.3 全连接层 13
3.3 传统网络结构 13
第4章 基于卷积网络的人体行为识别系统的实现 15
4.1 处理数据集 15
4.2 4.2处理训练集数据 17
4.3 构建神经网络模型 18
第5章 测试与分析 20
5.1 编译模型 20
5.2 实验结果 20
5.2.1 模型准确率和损失 20
5.2.2 模型识别的正确率 21
5.2.3 混淆矩阵 22
总结与展望 23
参考文献 24
致 谢 26
第1章 绪 论
1.1 研究背景和意义
1.1.1 研究人体行为识别的目的
根据深圳市最新出台的管理条例我们可以了解到,今年深圳市内公共场合将分布多大200万台的各类摄像头。其中,包括10万多台一类摄像头以及190多万台二三类摄像头。如此庞大的数量,再乘上每天24小时,可以想象监控人员的工作量之大,而人体识别系统的出现可以很好的解决为这一问题从而释放劳动力。计算机通过应用此系统从海量的监控视频中对人的行为进行识别、分类,并在其中提取出异常的行为,及时报警!系统将解放监控人员的劳动力,以及为维护社会提供安全和稳定的服务。
人体行为识别可以简单的分为特征提取、特征表示和识别分类[1]三个部分。特征提取是指从视频或图片序列中提取人工特征,如STIP(时空兴趣点)[2],BOVW(视觉词袋)[3-4],HOG(方向梯度直方图)[5-7],和MHI(运动历史图像)[8]等。特征表示,则指将提取的特征构成更加具有区分性的描述子特征,并通过一些变换和聚类等技术来实现,如FTT(傅里叶时态变换)[9-10]和K均值聚类[11]等。识别分类,使用像SVM,Adaboost[12]之类的分类器对描述子特征进行分类识别。而卷积网络较全连接网络来说最大的优势是其在计算机视觉领域中可以实现过滤参数,即保留少量重要的参数以及去掉大量不重要的参数,以此使网络模型达到更好的学习效果!
1.1.2 本课题的研究意义
随着我国社会、经济的显著提高,老百姓不再只担心温饱问题,人身安全得到了前所未有的关注,人们对于视频监控系统的需求直线上升。监控设备我们的日常生活中可谓如影随形,出现在几乎所有的公共场合,无论是小区、超市、商场、饭店甚至城市街道。但是这些监控设备常常只是记录发生的事情,并无法主动的保护人们的安全。因此,人们对于智能监控设备迫切渴望,它不仅能够实时监控24小时内发生的事情,还能通过分析人类行为,判断情况,自动报警,从而避免一些危险的事情发生!本课题的实现对于维护社会安全以及打击犯罪等具有重大的意义。
1.2 国内外研究现状
1.2.1 国内研究
人体行为识别在中国的研究开展地较晚但是经过与日俱增的发展取得了关键性的研究。隶属于中国科学院自动化所的CBSR(生物识别与安全技术研究中心)和微软亚洲研究院(MAR)都是较早在中国投入运营的研究所,较早研究人体行为识别的中国本土大学有:清华大学、北京大学和浙江大学。王喜昌等人设计一种基于三维加速度传感器的上肢动作识别系统[13] ,具有理想的识别准确率。田国会等人利用Kinect体感设备获取人体的关节数据[14] ,较好的解决识别问题,取得较为理想的结果。衡霞等人提出运用手机加速度传感器来获得数据,从而实现人体行为识别[15]。
1.2.2 国外研究
国外大学和研究机构较对人体行为识别的研究开展的比较早,1973年心理学家Johansson通过二维模型研究三维的人体运动感知开展了移动光斑的运动感知实验[16]。其实验表明,人体上光斑的数量和分布与运动感知有关。特别是,发现随着光点数量的增加,运动理解中的模糊性减少了[17]。实验还表明人类视觉即能够检测运动方向还能够检测不同类型的肢体运动模式,包括识别活动的速度和不同运动模式[18] 。1977年,D.Marr基于计算机科学,结合数学、心理物理学和神经生理学提出了视觉计算理论[19-20]。D.Marr的视觉计算理论创建后,计算机视觉研究的进程得到突飞猛进的提高,研究机构如雨后春笋般开始致力于人体运动分析。美国在1997年设立了以战场为主要应用领域的VSAM项目(视觉监控项目)。随后IVPL实验室(图像和视频处理实验室)、AIRVL实验室(人工智能、机器人与视觉实验室)和LPAC实验室(感知,行动与认知实验室)相继开展了人体行为识别的研究。英国雷丁大学先后推出两个项目来参与人体行为识别的研究:REASON(监视和了解公共场所人员项目)和ISCAPs(治安密集地区综合监视项目)。
1.3 课题研究方法和内容
1.3.1 研究方法
本文在撰写的过程中主要运用了如下两种方法进行研究:
文献研究法。根据本文的课题去确定文献需求,有计划性地去查阅与本文课题相关的文献,以此获得相关资料去增加自己去课题的认识,从而全面、客观、正确地了解本文的研究题目,启发思考。
理论研究法。通过实践,即实际设计与开发出基识别系统,然后将整个开发的过程及结果进行分析、总结,形成自己的见解看法。
1.3.2 研究内容
本文共有6章来循序渐进地阐述人体行为识别这个课题,具体内容的结构和安排如下:
第1章。以论题的背景与研究目的为中心展开进行说明,分析并阐述人体行为识别的实现对社会有怎样的意义。同时,收集大量人体识别的相关文献资料并进行综述,介绍国内外研究现况。
第2章。分别从ANN的结构、常用的激活函数来介绍ANN的相关理论知识。然后介绍再介绍基础的感知器神经网络,以此扩展对ANN的了解。
第3章。在上一章节的基础上过渡讲述CNN相关理论知识。首先介绍前馈神经网络,其次介绍包括卷积层、池化层、全连接层在内的卷积网络的结构构成,以Lenet-5为例子加深理解。
第4章。详细说明处理数据集以及搭建、训练神经网络,包括代码和结果展示。
第5-6章。首先编译上文所构建的神经网络并分析结果,然后根据前文内容进行总结,同时规划展望。
第2章 人工神经网络
ANN是一种由许多的神经元之间联接而构成的计算模型,它将生物神经元处理信息的过程进行抽象、建立模型,不一样的联接方式组成的网络也不同。
2.1 人工神经元
2.1.1 生物神经元
深度学习实际就是模拟生物神经元接收处理信息的过程。一个完整的生物神经元的可以分为细胞体和突起,其中突起又包括树突和轴突两种,轴突末端呈树状且没有细胞核的为神经末梢。一个完整的生物神经元的结构如图2-1所示:
图2-1 生物神经元结构示意图
树突:电信号从这些交叉部分进入,接受其他神经元轴突传入的电信号传给细胞体。
细胞核:电信号进入到细胞核后,细胞核会将多个电信号联合在一起进行运算最后得到唯一的电信号。
轴突:唯一的电信号通过轴突传送。
神经末梢:将轴突传来的电信号分解成若干个部分,以每个分叉传递给外面的神经元。
2.1.2 神经元
神经元是NNs(神经网络)最核心也是基本的部分,它是模拟生物神经元的一种数学模型,单个神经元可以接收多个输入数据。两个神经元之间的联接强度决定信号传递的强弱,且联接强度不是固定不变的,它可以伴随训练轮数发生变化。一个基本的神经元模型如图2-2所示:
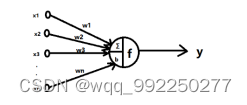
图2-2人工神经元结构示意图
图2-2的计算结果为:
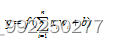
其中为输入信号,为每个输入信号所对应的的权值,为偏置值,为激活函数。
2.1.3 激活函数
激活函数在ANN模型中起到至关重要的作用,它将非线性激活因素拉入到我们的模型中,提高了模型的表达力,使得诸多非线性模型可以应用在神经网络中。如果模型中没有引入函数,那每层网络都相当于只进行了矩阵相乘,输入输出都是线性组合。以下三种函数是平时使用的最多的:
(1)激活函数Relu
Relu函数,函数数学图形如图2-3所示,因其计算简单且有效,是一种常用于ANN中的激活函数。
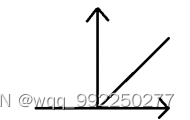
图2-3 relu函数数学图形
Relu函数通常指数学中的斜坡函数,其数学表达式为:
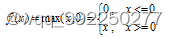
由公式可见,其实Relu函数就是分段线性函数,它将所有小于0的数即负数都变为0,而正数和0的不变。这表示如果输入是一个负数,那么激活函数将输出0,则神经元不会被激活。所以同一时间只有部分的神经元被激活,使得神经元具有稀疏激活性,提高计算的效率。
(2)激活函数Sigmoid
函数在定义域内单调递增,其反函数在定义域内也是单调递增。函数的数学图形如2-4所示。
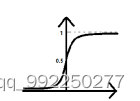
图2-4 Sigmoid函数数学图形
从图2-4可以看到函数的曲线平滑,则表明函数易于求导,其数学表达式为:
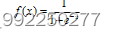
其求导为:
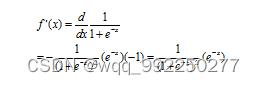
再将结果用表示:
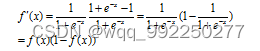
由公式和数学图形可知,Sigmoid函数在x轴上单调连续、值域为{y|0<y<1}。这意味着此函数可以将任意一个实数映射到(0,1)的区间内,所以当遇到二分类的情况下可以使用函数。但是当函数的输出值接近0或接近1时,输出就不会发生明显变化了,这称为函数接近线性变换。所以函数在特征之间比较相似或者相差较大的情况下实现的效果比较好。
(3)激活函数Tanh
双曲正切函数其实属于Sigmoid型函数的一种,两个函数的数学图形曲线相似。如果将Sigmoid函数的对称点在y轴上向下移到0,将得到双曲正切函数。函数的数学图形如2-5所示。
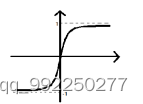
图2-5. Tanh函数数学图形
其数学表达式为:
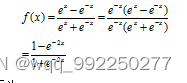
与Sigmoid函数的关系为:
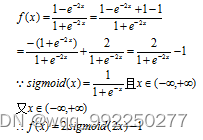
求导为:
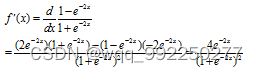
再将结果用表示:
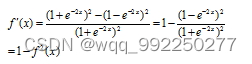
由TanH函数数学图形和数学表达式可知,其值域为(-1,1),以0为中心反对称,且原点近似恒等。但是,在输入数据很大或很小时,输出曲线接近线性变换,不利于权重更新容易出现梯度消失和饱和的问题。在遇到二分类问题时,构建的网络模型的隐藏层一般用双曲正切函数,而输出层则用Sigmoid函数。
2.1.4 损失函数
损失函数一般指预测值与已知标准答案两者之差,可以通过它了解模型的优劣。损失函数越小,表示网络模型的准确率越高。要想提高模型的准确率、缩小损失函数,只能通过在神经网络的训练过程中改变网络中的参数。
下面将详细讲解以下三种最常被使用的函数(loss function):
1、均方误差
均方误差是最常被使用的函数,它是n个样本的预测值y与已知答案y’之差的平方和,再求平均值。公式如下
2、自定义
自定义是损失函数要指根据实际问题来定制,也就是说函数要符合问题的实际情况。比如当需要预测某个商品的销量时,如果预测的销量大于实际的销量,则会损失成本,反之损失利润,所以这时使用均方误差则明显不适合。这时我们应该自定义一个函数,公式如下:
上述公式中,y表示预测结果,y’表示标准答案。当y小于y’时,利润profit乘以y与y’之差作为损失函数。反之,当y大于y’时,成本cost乘以y与y’之差作为损失函数。这样分段定义损失函数才能够有效解决预测商品销量的问题且最大程度缩小损失,而且使loss值达到最小。
3、交叉熵
交叉熵用来表示两个概率之间的差异,即两个概率分布之间的举例。交叉熵的值与差异、距离成正比,值越小距离越近越相似。公式如下:
2.2 感知器神经网络
感知器神经网络是最简单的一种人工神经网络结构,使用线性函数为激活函数,常被应用于解决二分类。模型如图2-6所示,其数学表达式为:
其中,为输入数据,为所对应的的权重向量,为偏置。
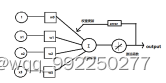
图2-6 感知器模型
可以把感知器是当作一个二分类模型,其特点是预测的数据是可以线性分割的。它就是在一个2D空间中找到一条线将不同的点进行分割,这要求数据必须是可以独立分割的,所以输入数据必须要满足于图2-6中的①,也就是说预测的数据特点可以在它们之间拉出一条线把数据分成两个部分;即要求我们必须找到这条虚线。而②中,我们找不到这条线,所以是线性不可分割。
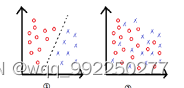
图2-7 数据分布图
2.3 BP神经网络
BP神经网络是最传统的神经网络,也是使用的最运频繁的神经网络,其结构为一层输入层,一层或多层隐含层,一层输出层。它使用了BP反向传播算法,其核心特点是信号前向传播,误差反向传播。所以我们可以将整个神经网络的过程拆分为两段,第一段过程是信号从输入层到隐含层,又从隐含层到达输出层的整个过程,即前向传播。第二段过程是误差从输出经过隐含层到达输出层,期间调节权重和偏置,即反向传播。模型如图2-8所示。
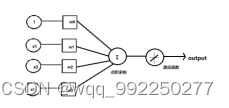
图2-8 BP神经网络模型
BP神经网络能够有效的解决感知器神经网络不能解决的异或,并且BP神经网络的神经元激活函数既可以使用线性激活函数,又可以使用非线性激活函数。
第3章 卷积神经网络相关理论知识
CNN是多层感知器的一种扩展,能够有效地帮助我们解决图像识别,接下来将详细阐述与其相关的理论知识。
3.1 前馈神经网络
前馈神经网络,又称为前向神经网络,是最简易的网络结构之一。多个神经元排列组成一层,多个层组成前馈神经网络。其中,每个神经元只接受前一层输出的信息,并作为下一层的输入进行传递。
图3-1的神经元 接受n=4个输入(x1,x2,x3,x4),其输出为
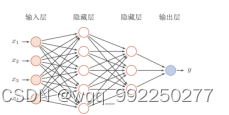
图3-1前馈神经网络结构示意图
其中为输入向量,为权重向量,为偏置,函数为激活函数。
图3-1中的神经网络,包含了1层输入层,2层隐藏层和1层输出层,该神经网络的层数为3层。所有参数w的个数余所有参数b的之和为总参数的个数,第一层用四行五列的二阶张量表示,第二层用五行三列的二阶张量,第三层用三行一列的二阶张量。总参数 = 4×5+5 + 5×3+3 +3×1+1 = 47。
一个前馈神经网络有一个输入层,然后接零个或多个隐藏层,最后接一个输出层。输入层接受待处理的数据,经过层层隐藏层,神经元进行计算,输出层输出结果。
前向神经网络,以神经元为基本单位,结构简单,大部分都是学习网络。常用的网络有:感知器网络、BP网络和RBF网络。
3.2 卷积神经网络
CNN是前馈神经网络其中一种,但不同的是其能够进行卷积计算且具有深度结构。对于图像识别来说,CNN更加有效的过滤了不重要、不完整的输入参数。
3.2.1 卷积层
卷积层内包含多个卷积核,实现对输入数据进行有效特征提取。每一个卷积核如图3-2所示,都要遍历图片上的每一个像素点。图片与卷积核重合区域内对应的每一个像素值乘以卷积核相对应点的权重之和、加上偏置为图片的一个像素值。
如图3-2所示,结果应为:
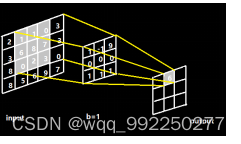
图3-2 卷积过程
卷积层参数包括卷积核大小、步长和填充,卷积核越大,可提取的输入特征越复杂。每进行一次卷积,图像都会缩小,所以为了图像被缩小到消失,我们采取填充。即在每次卷积前,在图像周围补上空白,这样图像被缩小后还是跟原图大小一样。填充padding又分为SAME和VALID两种。
3.2.2 池化层
也称下采样层,此层能够保留主要特征、减少参数和计算量,提高计算速度防止过拟合。池化模型一般表示形式为:
其中,为步长,为像素,为预设参数。当=1时,得到均值,所以称为平均池化。当时,得到最大值,所以称为最大池化。在实际应用中,最大池化应用的比较多。
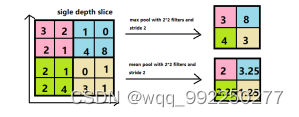
图3-3 最大池化和平均池化
在图3-3的例子中,如果使用最大池化,每个22的四宫格中选出最大值作为输出矩阵的值,如输入矩阵第一个22四宫格中最大值是3,那么输出矩阵的第一个元素就是6,如此类推。如果使用平均池化,则就计算每个2*2的四宫格的平均值作为输出矩阵的值。
3.2.3 全连接层
全连接层实际相当于“分类器”,全连接的核心操作就是矩阵向量乘积 y = Wx,即把之前的局部特征重新通过权值矩阵成为完整的特征。当网络模型在此层找到全部局部特征时,神经元被激活,将重组特征然后输出给输出层,经过softmax函数最后得到识别结果。一般来说,只用一层全连接层优势解决不了非线性问题,所以一般都使用两层以上。
3.3 传统网络结构
在CNN网络结构的演化上,出现了许多经典的卷积神经网络模型,如Lenet-5、Alenet、VGGNet和ResNet等。每一种网络结构都是基于卷积、激活、池化、全连接四个操作上进行不同的扩展。
Lenet-5[21]是由Lecun团队提出的,是最早出现的卷积神经网络,它能有效的解决手写数字识别的问题。它的输入为32×32×1,经过6个5×5×1的卷积核,步长为1,采用非全零填充模式。卷积后将结果输入到Relu非线性激活函数。接着经过第一层池化大小为2×2的池化层,采用非零填充,步长为2。再进行第二次卷积,16个5×5×6的卷积核,步长为1,采用非全零填充模式,再次将卷积后的结果通过Relu非线性激活函数。经过第二层池化层,参数与第一层池化层相同。最后将输出拉直后送入下一层,即全连接层。
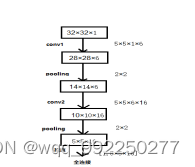
图3-4 Lenet神经网络结构图
Mnist数据集内的每张图都为大小28×28的单通道灰度图片,所以只需对输入为28×28×1的Lenet神经网络进行微调就可以应用到Mnist数据集继而实现手写数字识别。识别结果如图3-5所示。
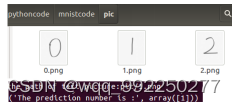
图3-5 Lenet在Mnist的识别结果
第4章 基于卷积网络的人体行为识别系统的实现
本章将详细介绍如何实现在Tensorfolw平台上构建CNN结构实现人体行为识别。数据集使用的是3轴加速度传感数据对36位志愿者进行采样数据,共六个动作。
4.1 处理数据集
下载WISDM实验室发布的数据集后,只使用其中的WISDM_ar_v1.1_raw.txt。WISDM数据集内的数据格式如图4-1所示:

图4-1. WISDM数据集
从图4-1可以看到每条数据后面都有一个“;”,如果直接加载数据集会导致报错,所以首先要去掉分号,实现代码如图4-1所示:

图4-2 去分号实现代码
当加载数据集到模型中,从图4-3,我们可以看到数据集前20条记录,包括用户id,行为名称,时间戳,加速器x轴、y轴、z轴的数据。
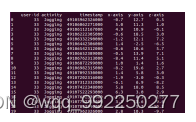
图4-3 WISDM数据集前20条数据
用matplotlib工具画出数据集中的行为数量和用户数量的柱状图,从图4-4中可以知道,整个数据集中共有六个行为,分为Walking、Jogging、Upstairs、Downstairs、Sitting、Standing,且Walking和Jogging两个的数据多于其他行为的数据。从图4-5知,一共有36个人参与了此次试验。
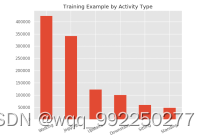
图4-4 训练集行为数量分布
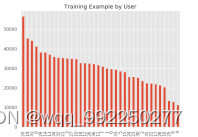
图4-5 训练集用户分布
将数据集分割成训练集(Training Set)和测试集(Test Set),使训练集用于模型的训练,测试集用于验证。在这个数据集中,可以以用户名为依据来进行分割,这样就不会导致测试集的数据渗入到训练集中。一般训练集的数据越多模型训练效果的越好,所以将用户名1到28用于训练集,大于28的则用于测试集。实现代码如图4-6所示:

图4-6 分割数据集实现代码
4.2 处理训练集数据
在将数据喂入神经网络前,要归一化数据集中的特征,值在0到1之间。要注意的是,传感器x、y、z三轴的数据要用同样的规范化方法,实现代码如图4-7所示:

图4-7 归一化特征实现代码
为了使用keras框架,要将数据reshape。定义一个函数接收dataFrame和标签名、每个记录的长度。将一次分割的的步数设置为80,采样率为20hz,所以时间间隔为:time_step=。reshape数据实现代码如图4-8所示:
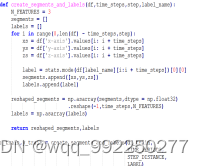
图4-8 reshape数据实现代码
将数据分段后,得到x_train、y_train。从图4-9可知,x_train、y_train分别都有20868条记录,其中x_train中20868条记录中的每一条都是803的二维矩阵。
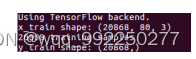
图4-9 数据分段后的shape
将特征数据和标签数据转换成keras可以接受的类型,且对标签进行一次热编码。实现编码如图4-10所示,结果如图4-11所示。
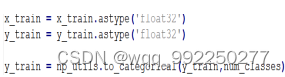
图4-10 热编码实现代码

图4-11 热编码后y_train的shape
4.3 构建神经网络模型
神经网络采用六层结构,包括四个卷积层,一层全连接层,一个输出层(不包括下采样层和输入层)。其中下采样层有两层,一层采用最大下采样,一层采用平均采样。下面详细描述网络结构。
第一层是卷积层,keras要求第一层输入shape,所以输入的input_shape为803的二维数组。有100个卷积核去卷积,使用的是conv1d一维卷积,卷积时只看纵列卷积核的尺寸为10。使用relu非线性激活函数,padding默认为vaild,strade默认为1。所以输出shape为(None,71,100),一共有3100个参数。
第二层也是卷积层,同样有100个卷积核去卷积,卷积核的尺寸为10,使用relu非线性激活函数,padding默认为vaild。输出shape为(None,62,100),一共100100个参数。
下一层是一个最大采样层,在纵列的维度上,进行尺度为3的下采样,所以输出shape为(None,20,100)。
第三层是卷积层, 有160个卷积核去卷积,卷积核的尺寸为10。使用relu非线性激活函数,padding默认为vaild,strade默认为1。输出shape为(None,11,160),共160160个参数。
第四层还是卷积层,160个尺寸为10的卷积核。相关参数与第三层一样。输出shape为(None,2,160),共256160个参数。
下一层为平均下采样层,输出为(None,160)。
接下来是dropout层,设定概率为0.5,防止过拟合。
最后,把全连接层的输出参数放入到一个sofmax分类其中。
CNN结构示意图如图4-13所示,实现代码如图4-12所示:

图4-12 构建网络模型实现代码
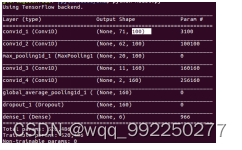
图4-13 神经网络结构示意图
第5章 测试与分析
这一章将针对上一章构建的神经网络在WISDM数据集上验证的结果进行全面的分析,其中包括神经网络的性能和识别的正确率。
5.1 编译模型
为了更好的检测模型的训练过程,创建一个回调函数,模型训练过程中任意时间都会调用此函数。它将保存最佳模型到filepath中,实现代码如图5-1所示:
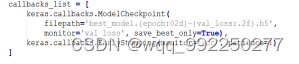
图5-1 回调函数实现代码
接下来就是编译模型,实现代码如图5-2所示:
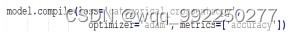
图5-2 编译模型实现代码
模型训练,以x_train个样本为一个batch进行迭代。每个batch包含400个样本数,训练达到50时停止,实现代码如图5-3所示

图5-3 训练模型实现代码
5.2 实验结果
5.2.1 模型准确率和损失
使用matplotlib可视化工具,实现函数可视化,画出模型准确率的损失,如图5-4所示。使用validation data代替test data是为了防止过度拟合。
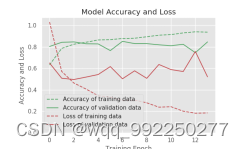
图5-4 模型准确率
从图5-4可以看到,训练数据的准确率比较好,而测试数据的准确率仅达到80%以上。训练数据的损失率在0.2左右,测试数据的损失率在0.5左右。模型还有很大的提升空间,要将测试数据的准确率提高,和降低测试数据的损失率。
5.2.2 模型识别的正确率
数据集共有六类行为,在测试阶段对所有测试样本进行测试,并得到分类结果。再将分类结果与测试样本的标签进行比较,相同则正确,反之则错误。图5-5中,得到测试数据的准确率、损失率、宏平均、微平均、样本权重平均,以及每个行为的准确率、召回率、F值。
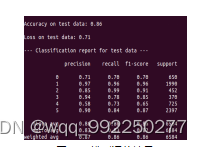
图5-5 模型评估结果
从图5-5,可以得到模型对Downstairs的识别准确率仅为71%,对Jogging识别的准确率却高达97%,对Sitting识别的准确率为85%,对Standing识别的准确率达到94%,对Walking的识别准确率也达到90%,但是对Upstairs识别的准确率为58%。测试数据集的识别准确率为86%,损失率为71%。准确率的微平均为86%,宏平均为83%,权重平均为87%。
5.2.3 混淆矩阵
混淆矩阵就是每一类的测试数据被分到不同类的情况,我们可以看到哪个行为容易在网络结构中混淆。矩阵的行代表测试样本的正确标签,行代表数据的类别。列代表测试样本在实际测试中被神经网络分到了哪一类。如果主对角线的数字和真实的值一样的个数,即代表网络对了。主对角线以外的就是代表网络犯的错,也就是让网络感到混淆的地方。混淆矩阵的主对角线的数字越大,代表神经网络的分类越好。
图5-6为生成混淆矩阵的实现代码,图5-7为混淆矩阵的结果示意图:
图5-76混淆矩阵实现代码
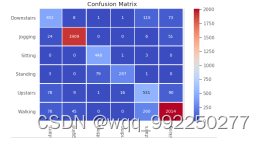
图5-7 混淆矩阵
从图5-7可以大致看出来,Jogging和Walking主对角线的值较大,Standing的混淆区域的总值最小,实际这三个行为的识别准确率也最高,都为90%以上。
总结与展望
行为识别是指计算机从包含人的视频或图片序列中提取人体行为特征,对人的行为进行理解和分类,是计算机视觉领域中应用广泛的方向。随着社会对实现人工智能的日趋迫切,机器学习成为必经的途径,而深度学习作为其代表方向被普遍学习应用。本文基于Tensorflow使用CNN来实现识别,数据来源WISDM实验室。
本文主要以基于卷积网络的行为识别这一论题为中心进行研究与介绍,主要结论如下:
(1)阐述了基本ANN的相关理论知识,CNN是其派生物,要掌握CNN就得先了解ANN。以ANN为基础自然地衔接了CNN相关的知识,层层递进,更好的了解CNN以及两者之间的差别。
(2)设计了一种卷积网络用于识别行为,基于Tensorflow平台用Python来实现网络,并且卷积层使用的是一维卷积技术。
(3)使用WISDM数据集来实验本文网络,并对实验结果进行了分析。
本文设计的神经网络得到的准确率在86%左右,应该再提升这个正确率到90%以上。对Jogging识别的准确率高达97%,对Sitting坐、Standing站立、Walking行走三个行为的识别准确率也达到85%以上,但是对Upstairs和Downstairs的识别准确率却连低于80%,尤其对Downstairs下楼梯这个行为的识别准确率只有57%。所以后续应该将模型对上、下楼梯两个行为的识别准确率进行提升。WISDIM中Jogging的数据最多最后得到的准确率也最高,所以增加数据集中上、下楼梯数据的数量是最优先考虑的方法。其次改进网络的结构也是比较优先考虑的方法,包括对激活函数的改进、使用二维或者三维卷积、以及增加网络的层数。而更改数据集也是可考虑的方法,本文使用的数据集基于三维传感器,可更换成基于视频的数据集,或者通过获取局部关节位置来实现识别。以上提出的问题和方法,都值得思考和尝试。
参考文献
[1]邢健飞, 罗志增, 席旭刚. 基于深度神经网络的实时人脸识别[J]. 杭州电子科技大学学报, 2013(6).
[2]Peng X, Qiao Y, Peng Q. Motion boundary based sampling and 3d co-occurrence descriptors for action recognition[J]. Image and Vision Computing, 2014, 32(9): 616–628.
[3]Roshtkhari M J, Levine M D. Human activity recognition in videos using a single example[J]. Image and Vision Computing, 2013, 31(11): 864–876
[4]O’Hara S, Lui Y M, Draper B A. Using a product manifold distance for unsupervised action recognition[J]. Image and Vision Computing, 2012, 30(3): 206–216.
[5]Yang X, Zhang C, Tian Y L. Recognizing actions using depth motion maps-based histograms of oriented gradients[C]//ACM International Conference on Multimedia. NewYork: ACM, 2012: 1057-1060.
[6]Oreifej O, Liu Z. HON4D: Histogram of oriented 4D normals for activity recognition from depth sequences[C]//Computer Vision and Pattern Recognition. NewYork: IEEE, 2013: 716-723
[7]Laptev I, Marszalek M, Schmid C, et al. Learning realistic human actions from movies[C]//Computer Vision and Pattern Recognition, 2008, IEEE Conference on. NewYork: IEEE, 2008: 1-8.
[8]Davis J W, Bobick A F. The representation and recognition of human movement using temporal templates[C]// Conference on Computer Vision and Pattern Recognition. Washington, D.C: IEEE Computer Society, 1997: 928.
[9]Wu Y. Mining actionlet ensemble for action recognition with depth cameras[C]//IEEE Conference on Computer Vision and Pattern Recognition. Washington, D.C: IEEE Computer Society, 2012: 1290-1297.
[10]Vemulapalli R, Arrate F, Chellappa R. Human action recognition by representing 3D skeletons as points in a lie group[C]//Computer Vision and Pattern Recognition. NewYork: IEEE, 2014: 588-595.
[11]Li W, Zhang Z, Liu Z. Action recognition based on a bag of 3D points[C]// Computer Vision and Pattern Recognition Workshops. NewYork: IEEE, 2010: 9-14.
[12]刘智, 冯欣, 张杰. 基于深度卷积神经网络和深度视频的人体行为识别[J]. 重庆大学学报, 2017, 40(11): 99-106.
[13]王昌喜, 杨先军, 徐强, et al. Motion Recognition System for Upper Limbs Based on 3D Acceleration Sensors%基于三维加速度传感器的上肢动作识别系统[J]. 传感技术学报, 2010, 023(006):816-819.
[14]田国会, 尹建芹, 韩旭, et al. 一种基于关节点信息的人体行为识别新方法[J]. 机器人, 2014(03):31-38.
[15]衡霞, 王忠民. Human activity recognition based on accelerometer data from a mobile phone%基于手机加速度传感器的人体行为识别[J]. 西安邮电学院学报, 2014, 019(006):76-79.
[16]JOHANSSON,G. Visual perception of biological motion and a model for its analysis[J]. Perception & Psychophysics, 1973, 14.
[17]田国会, 尹建芹, 韩旭, et al. 一种基于关节点信息的人体行为识别新方法
[18]Presti L L , Cascia M L . 3D Skeleton-based Human Action Classification: a Survey[J]. Pattern Recognition, 2015, 53.
[19]姚国正, 汪云九. D.Marr及其视觉计算理论[J]. 国外自动化, 1984(06):57-59.
[20]Marr D. A Theory of Vision. (Book Reviews: Vision)[J]. Science, 1982, 218(4576):991-992.
[21]Lécun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11):2278-2324.
致 谢
从2016年的初秋到2020年的暮春,开学的迷茫与兴奋彷如昨日般,分别离校的瞬间即将来临。四年的大学生活,有因付出努力而无回报的酸,有因与同学开心畅聊带来的甜,有因学业无法解惑带来的苦,有因生活压力带来的辣,如昨日般历历在目。2020年的开始,疫情悄然来临,回到校园已不如从前般容易,这无不提醒我们珍惜现在,珍惜身边人。
四年的学习生活,离不开任何一位老师的教诲与指导。我的毕业设计,都是每一位老师所教的知识才使我完成。桃李之恩,没齿难忘。其次我要感谢学校,让我每次归校都能感受如同回家般的温暖。“进德修业,勤思知行”,八字校训我将永记于心,作为人生的一块指引牌。
我感谢陪伴我四年的同学们,尤其是226的五位姑娘,世界之大,人海茫茫,我们的相遇是我的幸运。愿各位走出属于自己的康庄大道,再相见时我们仍是少年!
最后,我要感谢我的父母。你们从不问我为何,只会默默支持我,我无时无刻无不庆幸你们是我的父母!虽然不善言辞,但是你们的支持是我前进的最大动力。
论文的完成,也标志着大学生活已画上句点。感谢人生道路遇到的各位,你们的陪伴、聆听,帮助我度过迷茫、挥走阴霾。一饭之恩,无以回报,只能更加严于律己,不辜负各位的期望!