文章目录
- 一、前言
- 1、硬件配置
- 2、组网拓扑
- 3、总体方案
- 二、软件安装
- 三、集群部署
- 1、配置多路径
- 2、配置高可用集群
- 3、配置zpool
- 4、部署lustre
- 5、配置Lustre角色高可用
- 6、配置Lustre状态监控
- 6.1、Lustre网络状态监控
- 6.2、Lustre集群状态监控
- 6.3、配置优化
- 6.3.1、设置故障恢复不回迁
- 6.3.2、设置资源超时时间
- 四、配置说明
- 五、维护操作
- 1、pcs集群管理
- 2、pcs资源管理
一、前言
参考链接:Category:Lustre_High_Availability
1、硬件配置
| 节点类型 | 主机名 | IP地址 | 硬件配置 |
|---|---|---|---|
| 盘阵 | / | / | 5U84 JBOD盘阵 硬盘:16TB SAS HDD x 70、800GB SAS SSD x 4 io模块:io模块 x 2(单个模块3个SAS接口)SAS线:Mini SAS HD连接线 x 4 |
| 服务器 | test-lustre2 | 千兆:10.1.80.12/16 万兆:172.16.21.12/24 | 4U4路服务器 CPU:Intel Gold 5120 CPU @ 2.20GHz x 4 内存:512GB 网络:1Gb x 1、10Gb x 4(bond4) SAS卡:LSI SAS 9300-8e 双口SAS卡 x 1 系统盘:1.2T SAS SSD * 2(RAID1) |
| 服务器 | test-lustre3 | 千兆:10.1.80.13/16 万兆:172.16.21.13/24 | 4U4路服务器 CPU:Intel Gold 5120 CPU @ 2.20GHz x 4 内存:512GB 网络:1Gb x 1、10Gb x 4(bond4) SAS卡:LSI SAS 9300-8e 双口SAS卡 x 1 系统盘:1.2T SAS SSD * 2(RAID1) |
| 客户端 | test-lustre1 | 千兆:10.1.80.11/16 万兆:172.16.21.11/24 | 4U4路服务器 CPU:Intel Gold 5120 CPU @ 2.20GHz x 4 内存:512GB 网络:1Gb x 1、10Gb x 4(bond4) 系统盘:1.2T SAS SSD * 2(RAID1) |
| 客户端 | test-lustre4 | 千兆:10.1.80.14/16 万兆:172.16.21.14/24 | 4U4路服务器 CPU:Intel Gold 5120 CPU @ 2.20GHz x 4 内存:512GB 网络:1Gb x 1、10Gb x 4(bond4) 系统盘:1.2T SAS SSD * 2(RAID1) |
2、组网拓扑
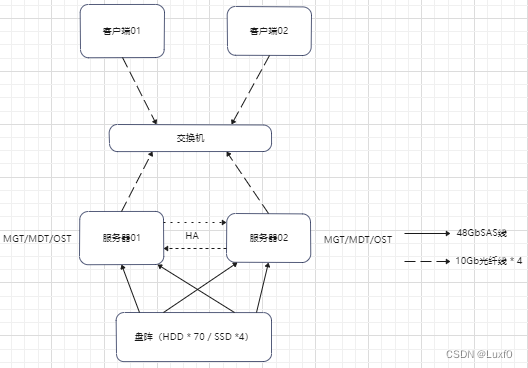
3、总体方案
本篇主要阐述Lustre软raid方案部署说明,总体配置如下:
- a、配置多路径
一台盘阵通过4根SAS线连接至两台服务器双口SAS卡,每台服务器通过multipath对所有硬盘配置主主多路径 - b、配置高可用集群
通过pacemaker配置高可用集群,建立集群节点互信 - c、配置zpool
通过zfs配置软raid,使用10块HDD组raid6(共7组,用于OST数据存储),使用4块SSD组raid10(共1组,用于MGT/MDT数据存储) - d、部署lustre
通过mkfs.lustre对lustre角色(MGT/MDT/OST)raid盘进行格式化操作 - e、配置Lustre角色高可用
通过pcs创建ocf:heartbeat:ZFS、ocf:lustre:Lustre资源,其中ocf:heartbeat:ZFS用于管理zpool池导入导出,ocf:lustre:Lustre用于管理lustre角色挂载 - f、配置Lustre状态监控
通过pcs创建ocf:lustre:healthLNET、ocf:lustre:healthLUSTRE监控规则,应用到所有资源上,其中ocf:lustre:healthLNET用于监测LNet网络连接状态,ocf:lustre:healthLUSTRE用于监测Lustre集群监控状态,当监测到某一节点异常时,将该节点资源转移到另一节点上
二、软件安装
- 安装lustre软件包
# 安装lustre软件包
yum install -y lustre lustre-iokit kmod-lustre lustre-osd-zfs-mount lustre-zfs-dkms
# 安装lustre-resource-agents软件包,为实现pacemaker可管理lustre服务,需要安装资源代理程序,安装完成后会生成/usr/lib/ocf/resource.d/lustre/目录
yum install -y lustre-resource-agents
- 安装zfs软件包
yum install -y zfs
- 安装multipath多路径软件包
yum install -y device-mapper-multipath
- 安装pacemaker高可用软件包
yum install -y pacemaker pcs
三、集群部署
1、配置多路径
-
生成配置文件
执行命令mpathconf --enable,在/etc目录下生成配置文件multipath.conf -
修改配置文件
使用多路径主主配置,修改配置文件/etc/mulipath.conf,添加配置信息如下
defaults {
path_selector "round-robin 0"
path_grouping_policy multibus
user_friendly_names yes
find_multipaths yes
}
devices {
device {
path_grouping_policy multibus
path_checker "tur"
path_selector "round-robin 0"
hardware_handler "1 alua"
prio "alua"
failback immediate
rr_weight "uniform"
no_path_retry queue
}
}
- 设置开机自启动
systemctl restart multipathd
systemctl enable multipathd
- 查看当前配置
当前已生成多路径主主配置,每个磁盘都有两条主路径
[root@test-lustre2 ~]# multipath -ll
mpathbp (35000c500d75452bb) dm-71 SEAGATE ,ST16000NM004J
size=15T features='0' hwhandler='0' wp=rw
`-+- policy='round-robin 0' prio=1 status=active
|- 1:0:77:0 sdca 68:224 active ready running
`- 1:0:160:0 sdew 129:128 active ready running
2、配置高可用集群
- 所有集群节点配置如下,启动pcsd服务,关闭防火墙及SELinux
systemctl restart pcsd
systemctl enable pcsd
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i s#SELINUX=enforcing#SELINUX=disabled#g /etc/selinux/config
- 所有集群节点配置如下,使用集群网配置hosts文件解析
[root@test-lustre2 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.16.21.12 test-lustre2
172.16.21.13 test-lustre3
[root@test-lustre3 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.16.21.12 test-lustre2
172.16.21.13 test-lustre3
- 所有集群节点配置如下,为
hacluster用户设置相同的密码
[root@test-lustre2 ~]# echo "123456" |passwd --stdin hacluster
[root@test-lustre3 ~]# echo "123456" |passwd --stdin hacluster
- 任一集群节点配置如下,配置集群互信,创建双机pacemaker集群(使用双心跳网络,否则容易出现脑裂),启动所有集群节点corosync和pacemaker服务
注:双机pacemaker集群时忽略节点quorum功能,禁用STONITH组件功能
[root@test-lustre2 ~]# pcs cluster auth 172.16.21.12 172.16.21.13 -u hacluster -p 123456
[root@test-lustre2 ~]# pcs cluster setup --start --name my_cluster 172.16.21.12,10.1.80.12 172.16.21.13,10.1.80.13 --force --transport udpu --token 7000
[root@test-lustre2 ~]# pcs cluster start --all
[root@test-lustre2 ~]# pcs property set no-quorum-policy=ignore
[root@test-lustre2 ~]# pcs property set stonith-enabled=false
- 所有集群节点配置如下,禁用掉pacemaker/corosync服务开机自启动,通过rc.local延时启动pacemaker服务
[root@test-lustre2 ~]# pcs cluster disable 172.16.21.12
[root@test-lustre2 ~]# pcs cluster disable 172.16.21.13
[root@test-lustre2 ~]# cat /etc/rc.local | tail -n 2
sleep 20
systemctl start pacemaker
[root@test-lustre2 ~]# chmod +x /etc/rc.d/rc.local
[root@test-lustre3 ~]# cat /etc/rc.local | tail -n2
sleep 20
systemctl start pacemaker
[root@test-lustre3 ~]# chmod +x /etc/rc.d/rc.local
3、配置zpool
任一集群节点配置如下,完成所有zpool创建
- 创建mdtpool1,使用4块ssd组raid10,用于mdt、mgt数据存储
zpool create -O canmount=off -o cachefile=none -f mdtpool1 mirror /dev/disk/by-id/dm-uuid-mpath-35000c500a19bb39b /dev/disk/by-id/dm-uuid-mpath-35000c500a19b9c0f mirror /dev/disk/by-id/dm-uuid-mpath-35000c500a19b9ce7 /dev/disk/by-id/dm-uuid-mpath-35000c500a19b9db3
- 创建ostpool1、ostpool2、ostpool3、ostpool4、ostpool5、ostpool6、ostpool7,分别使用10块hdd组raid6,用于ost数据存储
zpool create -O canmount=off -o cachefile=none -f ostpool1 raidz2 /dev/disk/by-id/dm-uuid-mpath-35000c500d75452bb /dev/disk/by-id/dm-uuid-mpath-35000c500d75aac43 /dev/disk/by-id/dm-uuid-mpath-35000c500d75a6ebb /dev/disk/by-id/dm-uuid-mpath-35000c500d75a9c57 /dev/disk/by-id/dm-uuid-mpath-35000c500d7618177 /dev/disk/by-id/dm-uuid-mpath-35000c500d75eb73f /dev/disk/by-id/dm-uuid-mpath-35000c500d7547f2b /dev/disk/by-id/dm-uuid-mpath-35000c500d75a6f8b /dev/disk/by-id/dm-uuid-mpath-35000c500d758dc9f /dev/disk/by-id/dm-uuid-mpath-35000c500d761a0bf
zpool create -O canmount=off -o cachefile=none -f ostpool2 raidz2 /dev/disk/by-id/dm-uuid-mpath-35000c500d7554ea3 /dev/disk/by-id/dm-uuid-mpath-35000c500d752814b /dev/disk/by-id/dm-uuid-mpath-35000c500d7601487 /dev/disk/by-id/dm-uuid-mpath-35000c500d76175ef /dev/disk/by-id/dm-uuid-mpath-35000c500d761b28f /dev/disk/by-id/dm-uuid-mpath-35000c500d761d31f /dev/disk/by-id/dm-uuid-mpath-35000c500d75b238f /dev/disk/by-id/dm-uuid-mpath-35000c500d752d64b /dev/disk/by-id/dm-uuid-mpath-35000c500cb28ca87 /dev/disk/by-id/dm-uuid-mpath-35000c500d7616417
zpool create -O canmount=off -o cachefile=none -f ostpool3 raidz2 /dev/disk/by-id/dm-uuid-mpath-35000c500cac14f1b /dev/disk/by-id/dm-uuid-mpath-35000c500d758d977 /dev/disk/by-id/dm-uuid-mpath-35000c500d758186b /dev/disk/by-id/dm-uuid-mpath-35000c500cadd3ce7 /dev/disk/by-id/dm-uuid-mpath-35000c500d75a99ef /dev/disk/by-id/dm-uuid-mpath-35000c500d75a9bb7 /dev/disk/by-id/dm-uuid-mpath-35000c500d75c37bf /dev/disk/by-id/dm-uuid-mpath-35000c500d7587f7b /dev/disk/by-id/dm-uuid-mpath-35000c500d75aa373 /dev/disk/by-id/dm-uuid-mpath-35000c500ca90ab77
zpool create -O canmount=off -o cachefile=none -f ostpool4 raidz2 /dev/disk/by-id/dm-uuid-mpath-35000c500d75a9b7b /dev/disk/by-id/dm-uuid-mpath-35000c500d753adbf /dev/disk/by-id/dm-uuid-mpath-35000c500cadab52b /dev/disk/by-id/dm-uuid-mpath-35000c500ca84573b /dev/disk/by-id/dm-uuid-mpath-35000c500d75b1b1b /dev/disk/by-id/dm-uuid-mpath-35000c500d75901ab /dev/disk/by-id/dm-uuid-mpath-35000c500d75fd637 /dev/disk/by-id/dm-uuid-mpath-35000c500d755544f /dev/disk/by-id/dm-uuid-mpath-35000c500d75fdea7 /dev/disk/by-id/dm-uuid-mpath-35000c500d75dbd9b
zpool create -O canmount=off -o cachefile=none -f ostpool5 raidz2 /dev/disk/by-id/dm-uuid-mpath-35000c500d7529d23 /dev/disk/by-id/dm-uuid-mpath-35000c500d75dc3b7 /dev/disk/by-id/dm-uuid-mpath-35000c500d76137fb /dev/disk/by-id/dm-uuid-mpath-35000c500d75fceaf /dev/disk/by-id/dm-uuid-mpath-35000c500cb267be7 /dev/disk/by-id/dm-uuid-mpath-35000c500d75204fb /dev/disk/by-id/dm-uuid-mpath-35000c500d75e9d1b /dev/disk/by-id/dm-uuid-mpath-35000c500d7588383 /dev/disk/by-id/dm-uuid-mpath-35000c500cb310e3b /dev/disk/by-id/dm-uuid-mpath-35000c500d75f32c3
zpool create -O canmount=off -o cachefile=none -f ostpool6 raidz2 /dev/disk/by-id/dm-uuid-mpath-35000c500ae3fe1df /dev/disk/by-id/dm-uuid-mpath-35000c500ae415cfb /dev/disk/by-id/dm-uuid-mpath-35000c500ae43608f /dev/disk/by-id/dm-uuid-mpath-35000c500ae409607 /dev/disk/by-id/dm-uuid-mpath-35000c500ae42344b /dev/disk/by-id/dm-uuid-mpath-35000c500ae412df3 /dev/disk/by-id/dm-uuid-mpath-35000c500ae3fcfeb /dev/disk/by-id/dm-uuid-mpath-35000c500ae2aca6b /dev/disk/by-id/dm-uuid-mpath-35000c500ae3fd05f /dev/disk/by-id/dm-uuid-mpath-35000c500ae42288f
zpool create -O canmount=off -o cachefile=none -f ostpool7 raidz2 /dev/disk/by-id/dm-uuid-mpath-35000c500ae40855f /dev/disk/by-id/dm-uuid-mpath-35000c500ae34d007 /dev/disk/by-id/dm-uuid-mpath-35000c500ae408dfb /dev/disk/by-id/dm-uuid-mpath-35000c500ae42ea27 /dev/disk/by-id/dm-uuid-mpath-35000c500ae40363b /dev/disk/by-id/dm-uuid-mpath-35000c500ae2b39d3 /dev/disk/by-id/dm-uuid-mpath-35000c500ae41b827 /dev/disk/by-id/dm-uuid-mpath-35000c500ae40c133 /dev/disk/by-id/dm-uuid-mpath-35000c500ae42ddb7 /dev/disk/by-id/dm-uuid-mpath-35000c500ae40b6d7
- 查看zpool信息
[root@test-lustre2 ~]# zpool list
NAME SIZE ALLOC FREE EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
mdtpool1 1.45T 408K 1.45T - 0% 0% 1.00x ONLINE -
ostpool1 145T 1.20M 145T - 0% 0% 1.00x ONLINE -
ostpool2 145T 1.20M 145T - 0% 0% 1.00x ONLINE -
ostpool3 145T 1.23M 145T - 0% 0% 1.00x ONLINE -
ostpool4 145T 1.20M 145T - 0% 0% 1.00x ONLINE -
ostpool5 145T 1.20M 145T - 0% 0% 1.00x ONLINE -
ostpool6 145T 1.44M 145T - 0% 0% 1.00x ONLINE -
ostpool7 145T 1.15M 145T - 0% 0% 1.00x ONLINE -
4、部署lustre
- 所有集群节点配置如下,配置Lustre集群网络,生成spl_hostid,加载模块启动服务
echo "options lnet networks=tcp0(bond0)" > /etc/modprobe.d/lustre.conf
genhostid
depmod -a
systemctl restart lustre
- 任一集群节点配置如下,部署mgt、mdt、ost角色
#部署mgt/mdt
mkfs.lustre --mgs --mdt --index=0 --fsname=lustrefs --mgsnode=172.16.21.12@tcp0 --mgsnode=172.16.21.13@tcp0 --servicenode 172.16.21.12@tcp0 --servicenode 172.16.21.13@tcp0 --backfstype=zfs mdtpool1/mdt1
#部署ost
mkfs.lustre --ost --index=0 --fsname=lustrefs --mgsnode=172.16.21.12@tcp0 --mgsnode=172.16.21.13@tcp0 --servicenode 172.16.21.12@tcp0 --servicenode 172.16.21.13@tcp0 --backfstype=zfs ostpool1/ost1 --mkfsoptions "recordsize=1024K"
mkfs.lustre --ost --index=1 --fsname=lustrefs --mgsnode=172.16.21.12@tcp0 --mgsnode=172.16.21.13@tcp0 --servicenode 172.16.21.12@tcp0 --servicenode 172.16.21.13@tcp0 --backfstype=zfs ostpool2/ost2 --mkfsoptions "recordsize=1024K"
mkfs.lustre --ost --index=2 --fsname=lustrefs --mgsnode=172.16.21.12@tcp0 --mgsnode=172.16.21.13@tcp0 --servicenode 172.16.21.12@tcp0 --servicenode 172.16.21.13@tcp0 --backfstype=zfs ostpool3/ost3 --mkfsoptions "recordsize=1024K"
mkfs.lustre --ost --index=3 --fsname=lustrefs --mgsnode=172.16.21.12@tcp0 --mgsnode=172.16.21.13@tcp0 --servicenode 172.16.21.12@tcp0 --servicenode 172.16.21.13@tcp0 --backfstype=zfs ostpool4/ost4 --mkfsoptions "recordsize=1024K"
mkfs.lustre --ost --index=4 --fsname=lustrefs --mgsnode=172.16.21.12@tcp0 --mgsnode=172.16.21.13@tcp0 --servicenode 172.16.21.12@tcp0 --servicenode 172.16.21.13@tcp0 --backfstype=zfs ostpool5/ost5 --mkfsoptions "recordsize=1024K"
mkfs.lustre --ost --index=5 --fsname=lustrefs --mgsnode=172.16.21.12@tcp0 --mgsnode=172.16.21.13@tcp0 --servicenode 172.16.21.12@tcp0 --servicenode 172.16.21.13@tcp0 --backfstype=zfs ostpool6/ost6 --mkfsoptions "recordsize=1024K"
mkfs.lustre --ost --index=6 --fsname=lustrefs --mgsnode=172.16.21.12@tcp0 --mgsnode=172.16.21.13@tcp0 --servicenode 172.16.21.12@tcp0 --servicenode 172.16.21.13@tcp0 --backfstype=zfs ostpool7/ost7 --mkfsoptions "recordsize=1024K"
5、配置Lustre角色高可用
- 所有集群节点配置如下,配置ZFS资源高可用,创建lustre集群挂载目录
wget -P /usr/lib/ocf/resource.d/heartbeat https://raw.githubusercontent.com/ClusterLabs/resource-agents/master/heartbeat/ZFS
chmod 755 /usr/lib/ocf/resource.d/heartbeat/ZFS
chown root:root /usr/lib/ocf/resource.d/heartbeat/ZFS
mkdir -p /lustrefs
mkdir -p /lustre/mdt1
mkdir -p /lustre/ost1
mkdir -p /lustre/ost2
mkdir -p /lustre/ost3
mkdir -p /lustre/ost4
mkdir -p /lustre/ost5
mkdir -p /lustre/ost6
mkdir -p /lustre/ost7
- 任一集群节点配置如下,对luster角色创建挂载服务,由pcs控制角色挂载
注:默认情况下,pcs会平均将所有挂载分到两个节点下
以mdt角色挂载服务举例:
a、创建zfs-mdtpool1资源,用于管理mdtpool1 zpool存储池导入
b、创建mdt1资源,用于管理mdt1角色挂载
c、通过指定--group group_mdt1将zfs-mdtpool1、mdt1资源分到同一个资源组group_mdt1下,从而控制先导入zpool存储池,再执行挂载zpool存储池
pcs resource create zfs-mdtpool1 ocf:heartbeat:ZFS pool="mdtpool1" --group group_mdt1
pcs resource create mdt1 ocf:lustre:Lustre target="mdtpool1/mdt1" mountpoint="/lustre/mdt1/" --group group_mdt1
pcs resource create zfs-ostpool1 ocf:heartbeat:ZFS pool="ostpool1" --group group_ost1
pcs resource create ost1 ocf:lustre:Lustre target="ostpool1/ost1" mountpoint="/lustre/ost1/" --group group_ost1
pcs resource create zfs-ostpool2 ocf:heartbeat:ZFS pool="ostpool2" --group group_ost2
pcs resource create ost2 ocf:lustre:Lustre target="ostpool2/ost2" mountpoint="/lustre/ost2/" --group group_ost2
pcs resource create zfs-ostpool3 ocf:heartbeat:ZFS pool="ostpool3" --group group_ost3
pcs resource create ost3 ocf:lustre:Lustre target="ostpool3/ost3" mountpoint="/lustre/ost3/" --group group_ost3
pcs resource create zfs-ostpool4 ocf:heartbeat:ZFS pool="ostpool4" --group group_ost4
pcs resource create ost4 ocf:lustre:Lustre target="ostpool4/ost4" mountpoint="/lustre/ost4/" --group group_ost4
pcs resource create zfs-ostpool5 ocf:heartbeat:ZFS pool="ostpool5" --group group_ost5
pcs resource create ost5 ocf:lustre:Lustre target="ostpool5/ost5" mountpoint="/lustre/ost5/" --group group_ost5
pcs resource create zfs-ostpool6 ocf:heartbeat:ZFS pool="ostpool6" --group group_ost6
pcs resource create ost6 ocf:lustre:Lustre target="ostpool6/ost6" mountpoint="/lustre/ost6/" --group group_ost6
pcs resource create zfs-ostpool7 ocf:heartbeat:ZFS pool="ostpool7" --group group_ost7
pcs resource create ost7 ocf:lustre:Lustre target="ostpool7/ost7" mountpoint="/lustre/ost7/" --group group_ost7
- 客户端使用多个mgs nid地址挂载集群目录
注:当出现一个mgs故障后,客户端会自动连接另外一个mgs访问集群目录
mount -t lustre 172.16.21.12@tcp0:172.16.21.13@tcp0:/lustrefs /lustrefs/
- 查看当前pcs集群状态
[root@test-lustre2 ~]# pcs status
Cluster name: my_cluster
WARNINGS:
Corosync and pacemaker node names do not match (IPs used in setup?)
Stack: corosync
Current DC: test-lustre2 (version 1.1.23-1.el7-9acf116022) - partition with quorum
Last updated: Thu Jun 8 18:17:39 2023
Last change: Thu Jun 8 18:15:39 2023 by root via cibadmin on test-lustre2
2 nodes configured
16 resource instances configured
Online: [ test-lustre2 test-lustre3 ]
Full list of resources:
Resource Group: group_mdt
zfs-mdtpool (ocf::heartbeat:ZFS): Started test-lustre2
mgt (ocf::lustre:Lustre): Started test-lustre2
Resource Group: group_ost1
zfs-ostpool1 (ocf::heartbeat:ZFS): Started test-lustre3
ost1 (ocf::lustre:Lustre): Started test-lustre3
Resource Group: group_ost2
zfs-ostpool2 (ocf::heartbeat:ZFS): Started test-lustre2
ost2 (ocf::lustre:Lustre): Started test-lustre2
Resource Group: group_ost3
zfs-ostpool3 (ocf::heartbeat:ZFS): Started test-lustre3
ost3 (ocf::lustre:Lustre): Started test-lustre3
Resource Group: group_ost4
zfs-ostpool4 (ocf::heartbeat:ZFS): Started test-lustre2
ost4 (ocf::lustre:Lustre): Started test-lustre2
Resource Group: group_ost5
zfs-ostpool5 (ocf::heartbeat:ZFS): Started test-lustre3
ost5 (ocf::lustre:Lustre): Started test-lustre3
Resource Group: group_ost6
zfs-ostpool6 (ocf::heartbeat:ZFS): Started test-lustre2
ost6 (ocf::lustre:Lustre): Started test-lustre2
Resource Group: group_ost7
zfs-ostpool7 (ocf::heartbeat:ZFS): Started test-lustre3
ost7 (ocf::lustre:Lustre): Started test-lustre3
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
6、配置Lustre状态监控
6.1、Lustre网络状态监控
通过lctl ping监控LNet网络状态,当出现异常时,将资源强制切换到另一集群节点上
- 任一集群节点配置如下,创建Lustre网络状态监控规则
pcs resource create healthLNET ocf:lustre:healthLNET lctl=true multiplier=1000 device=bond0 host_list="172.16.21.12@tcp0 172.16.21.13@tcp0" --clone
- 任一集群节点配置如下,将规则应用到所有Lustre资源下
pcs constraint location zfs-mdtpool1 rule score=-INFINITY pingd lte 0 or not_defined pingd
pcs constraint location mdt1 rule score=-INFINITY pingd lte 0 or not_defined pingd
pcs constraint location zfs-ostpool1 rule score=-INFINITY pingd lte 0 or not_defined pingd
pcs constraint location ost1 rule score=-INFINITY pingd lte 0 or not_defined pingd
pcs constraint location zfs-ostpool2 rule score=-INFINITY pingd lte 0 or not_defined pingd
pcs constraint location ost2 rule score=-INFINITY pingd lte 0 or not_defined pingd
pcs constraint location zfs-ostpool3 rule score=-INFINITY pingd lte 0 or not_defined pingd
pcs constraint location ost3 rule score=-INFINITY pingd lte 0 or not_defined pingd
pcs constraint location zfs-ostpool4 rule score=-INFINITY pingd lte 0 or not_defined pingd
pcs constraint location ost4 rule score=-INFINITY pingd lte 0 or not_defined pingd
pcs constraint location zfs-ostpool5 rule score=-INFINITY pingd lte 0 or not_defined pingd
pcs constraint location ost5 rule score=-INFINITY pingd lte 0 or not_defined pingd
pcs constraint location zfs-ostpool6 rule score=-INFINITY pingd lte 0 or not_defined pingd
pcs constraint location ost6 rule score=-INFINITY pingd lte 0 or not_defined pingd
pcs constraint location zfs-ostpool7 rule score=-INFINITY pingd lte 0 or not_defined pingd
pcs constraint location ost7 rule score=-INFINITY pingd lte 0 or not_defined pingd
6.2、Lustre集群状态监控
通过lctl get_param health_check监控Lustre集群健康状态,当出现异常时,将资源强制切换到另一集群节点上
- 任一集群节点配置如下,创建Lustre集群状态监控规则
pcs resource create healthLUSTRE ocf:lustre:healthLUSTRE --clone
- 任一集群节点配置如下,将规则应用到所有Lustre资源下
pcs constraint location zfs-mdtpool1 rule score=-INFINITY lustred lte 0 or not_defined lustred
pcs constraint location mdt1 rule score=-INFINITY lustred lte 0 or not_defined lustred
pcs constraint location zfs-ostpool1 rule score=-INFINITY lustred lte 0 or not_defined lustred
pcs constraint location ost1 rule score=-INFINITY lustred lte 0 or not_defined lustred
pcs constraint location zfs-ostpool2 rule score=-INFINITY lustred lte 0 or not_defined lustred
pcs constraint location ost2 rule score=-INFINITY lustred lte 0 or not_defined lustred
pcs constraint location zfs-ostpool3 rule score=-INFINITY lustred lte 0 or not_defined lustred
pcs constraint location ost3 rule score=-INFINITY lustred lte 0 or not_defined lustred
pcs constraint location zfs-ostpool4 rule score=-INFINITY lustred lte 0 or not_defined lustred
pcs constraint location ost4 rule score=-INFINITY lustred lte 0 or not_defined lustred
pcs constraint location zfs-ostpool5 rule score=-INFINITY lustred lte 0 or not_defined lustred
pcs constraint location ost5 rule score=-INFINITY lustred lte 0 or not_defined lustred
pcs constraint location zfs-ostpool6 rule score=-INFINITY lustred lte 0 or not_defined lustred
pcs constraint location ost6 rule score=-INFINITY lustred lte 0 or not_defined lustred
pcs constraint location zfs-ostpool7 rule score=-INFINITY lustred lte 0 or not_defined lustred
pcs constraint location ost7 rule score=-INFINITY lustred lte 0 or not_defined lustred
- 查看当前资源状态
[root@test-lustre2 ~]# pcs resource
Resource Group: group_mdt
zfs-mdtpool (ocf::heartbeat:ZFS): Started test-lustre2
mdt (ocf::lustre:Lustre): Started test-lustre2
Resource Group: group_ost1
zfs-ostpool1 (ocf::heartbeat:ZFS): Started test-lustre3
ost1 (ocf::lustre:Lustre): Started test-lustre3
Resource Group: group_ost2
zfs-ostpool2 (ocf::heartbeat:ZFS): Started test-lustre2
ost2 (ocf::lustre:Lustre): Started test-lustre2
Resource Group: group_ost3
zfs-ostpool3 (ocf::heartbeat:ZFS): Started test-lustre3
ost3 (ocf::lustre:Lustre): Started test-lustre3
Resource Group: group_ost4
zfs-ostpool4 (ocf::heartbeat:ZFS): Started test-lustre2
ost4 (ocf::lustre:Lustre): Started test-lustre2
Resource Group: group_ost5
zfs-ostpool5 (ocf::heartbeat:ZFS): Started test-lustre3
ost5 (ocf::lustre:Lustre): Started test-lustre3
Resource Group: group_ost6
zfs-ostpool6 (ocf::heartbeat:ZFS): Started test-lustre2
ost6 (ocf::lustre:Lustre): Started test-lustre2
Resource Group: group_ost7
zfs-ostpool7 (ocf::heartbeat:ZFS): Started test-lustre3
ost7 (ocf::lustre:Lustre): Started test-lustre3
Clone Set: healthLNET-clone [healthLNET]
Started: [ test-lustre2 test-lustre3 ]
Clone Set: healthLUSTRE-clone [healthLUSTRE]
Started: [ test-lustre2 test-lustre3 ]
6.3、配置优化
6.3.1、设置故障恢复不回迁
how-can-i-set-resource-stickiness-in-pacemaker
Redhat-6.4.资源元数据选项
使用pcs创建pcs双机高可用,出现A节点故障时,A节点资源会自动迁移至B节点启动,此时集群恢复正常
当A节点故障恢复之后,默认情况下会触发重平衡操作,B节点会再次将部分正常的资源迁移到A节点,以此将资源平均分配到两个节点上
pcs提供resource-stickiness选项设置资源粘性值,这是一个资源元数据选项,用于指定给定资源偏好保持在原位的程度(默认值为0),此处可设置参数值为100,当节点故障恢复之后,资源不会发生回迁操作,避免资源来回切换导致集群无法恢复正常
注:集群恢复正常之后,为保证资源负载可均摊到所有节点上,可选择一个割接时间窗口,手动move资源到另一个空闲节点上
# 设置pcs资源resource-stickiness默认参数值,该参数值只对后面新建的资源有效
pcs resource defaults resource-stickiness=100
# 设置已有资源group_ost3 resource-stickiness参数值
pcs resource meta group_ost3 resource-stickiness=100
6.3.2、设置资源超时时间
默认情况下,ost挂载启动超时时间为300s,考虑到在极端情况下,可能会出现启动超时情况,可执行pcs resource update <resource-id> op start interval=0s timeout=600s命令适当延长启动超时时间
# 默认情况下,ost挂载超时时间为300s
[root@test-lustre2 ~]# pcs resource show group_ost4
Group: group_ost4
Resource: zfs-ostpool4 (class=ocf provider=heartbeat type=ZFS)
Attributes: pool=ostpool4
Operations: monitor interval=5s timeout=30s (zfs-ostpool4-monitor-interval-5s)
start interval=0s timeout=60s (zfs-ostpool4-start-interval-0s)
stop interval=0s timeout=60s (zfs-ostpool4-stop-interval-0s)
Resource: ost4(class=ocf provider=lustre type=Lustre)
Attributes: mountpoint=/lustre/ost4/ target=ostpool4/ost4
Operations: monitor interval=20s timeout=300s (ost4-monitor-interval-20s)
start interval=0s timeout=300s (ost4-start-interval-0s)
stop interval=0s timeout=300s (ost4-stop-interval-0s)
# 故障切换测试中,出现ost4启动挂载超时,导致资源未成功启动
Jun 16 14:55:02 Lustre(ost4)[40028]: INFO: Starting to mount ostpool4/ost4
Jun 16 15:00:02 [9194] test-lustre2 lrmd: warning: child_timeout_callback: ost4_start_0 process (PID 40028) timed out
Jun 16 15:00:02 [9194] test-lustre2 lrmd: warning: operation_finished: ost4_start_0:40028 - timed out after 300000ms
....
Jun 16 15:00:04 Lustre(ost4)[44092]: INFO: Starting to unmount ostpool4/ost4
Jun 16 15:00:04 Lustre(ost4)[44092]: INFO: ostpool4/ost4 unmounted successfully
# 手动更新ost4启动超时时间为600s
[root@test-lustre2 ~]# pcs resource update ost4 op start interval=0s timeout=600s
[root@test-lustre2 ~]# pcs resource show ost4
Resource: ost1 (class=ocf provider=lustre type=Lustre)
Attributes: interval=0s mountpoint=/lustre/ost1/ target=ostpool1/ost1 timeout=600s
Operations: monitor interval=20s timeout=300s (ost1-monitor-interval-20s)
start interval=0s timeout=600s (ost1-start-interval-0s)
stop interval=0s timeout=300s (ost1-stop-interval-0s)
四、配置说明
参考链接:
Creating_Pacemaker_Resources_for_Lustre_Storage_Services
[root@node93 ~]# pcs resource list ocf:lustre
ocf:lustre:healthLNET - LNet connectivity
ocf:lustre:healthLUSTRE - lustre servers healthy
ocf:lustre:Lustre - Lustre management
五、维护操作
1、pcs集群管理
-
查看pcs集群状态:
pcs cluster status -
停止pcs集群所有节点/指定节点:
pcs cluster stop [--all | <node-ip> ] -
启动pcs集群所有节点/指定节点:
pcs cluster start [--all | <node-ip> ] -
禁用pcs集群所有节点/指定节点开机自启动:
pcs cluster disable [--all | <node-ip> ] -
启用pcs集群所有节点/指定节点开机自启动:
pcs cluster enable [--all | <node-ip> ]
2、pcs资源管理
-
查看pcs资源状态:
pcs resource show [resource -id]
注:当不指定resource-id时,可列出所有pcs资源状态;当指定resource-id时,可查看具体资源属性信息(如启动超时时间、资源粘性设置等); -
查看所有可用的资源代理:
pcs resource list -
允许集群启用指定pcs资源:
pcs resource enable <resource-id> -
停止、禁止集群启用指定pcs资源:
pcs resource disable <resource-id> -
手动将运行的资源转移到另外一个节点:
pcs resource move <resource-id> <destination-node> -
手动启动某一资源:
pcs resource debug-start <resource-id> -
手动停止某一资源:
pcs resource debug-stop <resource-id> -
清除所有资源失败操作记录,重新执行资源分配:
pcs resource cleanup [resource-id]
注:当不指定resource-id时,可重新分配所有资源;当指定resource-id时,可重新分配指定资源;
当pcs资源出现FAILED test-lustre2 (blocked)状态时,可手动对指定资源进行cleanup操作,如操作失败,可查看/var/log/cluster/corosync.log日志检查操作失败原因
# 参考示例如下,对group-ost5资源进行cleanup操作,其中zfs-ostpool5资源停止失败,此时需检查test-lustre2节点zpool状态
Jun 16 14:25:17 test-lustre2 pengine[94332]: warning: Processing failed stop of zfs-ostpool5 on test-lustre2: unknown error
Jun 16 14:25:17 test-lustre2 pengine[94332]: warning: Processing failed stop of zfs-ostpool5 on test-lustre2: unknown error
Jun 16 14:25:17 test-lustre2 pengine[94332]: warning: Forcing zfs-ostpool5 away from test-lustre2 after 1000000 failures (max=1000000)
Jun 16 14:25:17 test-lustre2 pengine[94332]: notice: Scheduling shutdown of node test-lustre2
Jun 16 14:25:17 test-lustre2 pengine[94332]: notice: * Shutdown test-lustre2
Jun 16 14:25:17 test-lustre2 pengine[94332]: crit: Cannot shut down node 'test-lustre2' because of zfs-ostpool5: unmanaged failed (zfs-ostpool5_stop_0)
Jun 16 14:25:17 test-lustre2 pengine[94332]: notice: Calculated transition 3, saving inputs in /var/lib/pacemaker/pengine/pe-input-154.bz2
# 如执行zpool list查看zpool状态处于SUSPENDED(正常状态为ONLINE)时,则需手动执行zpool clear ostpool5恢复异常存储池,之后再对资源进行cleanup操作