Buffer的功能需求:
Buffer类的设计目的是再创造一层应用层缓冲区。
其对外表现为一块连续的内存(char* p, int len),以方便客户代码的编写。
size() 可以自动增长,以适应不同大小。
内部以 std::vector<char>来保存数据,并提供相应的访问函数。
Buffer类的结构:
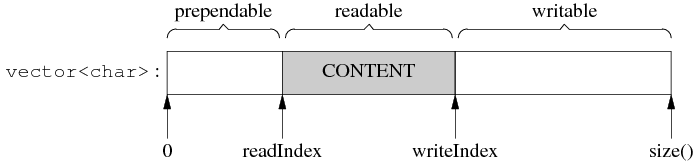
Buffer类有三个成员变量,一个 std::vector<char>,和两个size_t的readerIndex,writerIndex用来表示读写的位置。
构造函数:
Buffer::Buffer(size_t initialSize):buffer(initialSize),readerIndex(0),writerIndex(0)
{
assert(readableBytes() == 0);
assert(writableBytes() == initialSize);
assert(prependableBytes() == 0);
}依据上图结构,得出三个基础的成员函数:
//可读bytes数
size_t Buffer::readableBytes() const
{
return writerIndex - readerIndex;
}
//可写bytes数
size_t Buffer::writableBytes() const
{
return buffer.size() - writerIndex;
}
//预留bytes数
size_t Buffer::prependableBytes() const
{
return readerIndex;
}此外,buffer类应模仿平时使用的容器,提供访问数据元素的迭代器:
char* begin()
{
return &*buffer.begin();
}
//常量默认调用此重载函数
const char* begin() const
{
return &*buffer.begin();
}
char* Buffer::beginWrite()
{
return begin() + writerIndex;
}
//常量默认调用此重载函数
const char* Buffer::beginWrite() const
{
return begin() + writerIndex;
}这里提供两个重载,一个由变量调用,返回可修改内部元素的可写迭代器;
一个由常量调用,返回不可修改内部元素的只读迭代器。
还应提供可以直接访问CONTENT区域的迭代器:
const char* Buffer::peek() const
{
return begin() + readerIndex;
}向buffer中写入数据和从buffer中读出数据都需要修改readerIndex与writerIndex的大小:
//向buffer中写入len bytes数据
void Buffer::hasWritten(size_t len)
{
writerIndex += len;
}
//撤销向buffer中写入的len bytes数据
void Buffer::unwrite(size_t len)
{
assert(len <= readableBytes());
writerIndex -= len;
}
//从buffer中读取len bytes数据
void Buffer::retrieve(size_t len)
{
assert(len <= readableBytes());
if(len<readableBytes())
{
readerIndex += len;
}
else//len == readableBytes(),全部读取
{
retrieveAll();
}
}
//从buffer中读取全部可读数据
void Buffer::retrieveAll()
{
bzero(&buffer[0], buffer.size());
readerIndex = 0;
writerIndex = 0;
}
//读至指定结尾end
void Buffer::retrieveUntil(const char* end)
{
assert(peek() <= end);
assert(end <= beginWrite());
retrieve(end - peek());
}
获得从buffer中读出数据的副本:
//读取全部可读数据
std::string Buffer::retrieveAllAsString()
{
return retrieveAsString(readableBytes());
}
//读取指定字节数
std::string Buffer::retrieveAsString(size_t len)
{
assert(len <= readableBytes());
std::string res(peek(), len);
retrieve(len);
return res;
}扩大buffer的大小:
buffer的 size() 可以自动增长,以适应不同大小。而有时候,经过若干次读写,readIndex 移到了比较靠后的位置,留下了巨大的 prependable 空间。Buffer 在这种情况下不会重新分配内存,而是先把已有的数据移到前面去,腾出 writable 空间。
void makeSpace(size_t len)
{
//剩余空间不足len,则直接扩大buffer大小
if (writableBytes() + prependableBytes() < len)
{
buffer.resize(writerIndex + len + 1);
}
else//剩余空间大于等于len,则移动可读数据至最前面,腾出空间
{
size_t readable = readableBytes();
std::copy(begin() + readerIndex, begin() + writerIndex, begin());
readerIndex = 0;
writerIndex = readerIndex + readable;
assert(readable == readableBytes());
}
}向buffer中直接添加新的数据:
//添加string类型数据
void Buffer::append(const std::string& str)
{
append(str.data(), str.length());//转至c风格字符串
}
//添加c风格字符串
void Buffer::append(const char* str, size_t len)
{
ensureWriteableBytes(len);//确保buffer的可写大小足够添加新数据
std::copy(str, str + len, beginWrite());
hasWritten(len);
}
//添加void*类型字串
void Buffer::append(const void* data, size_t len)
{
append(static_cast<const char*>(data), len);
}向buffer中添加从套接字fd中读取的数据:
这里为了实现线程安全,选择传入 值—结果参数int *Errno;
此外,由于希望减少系统调用,一次读的数据越多越划算,那么似乎应该准备一个大的缓冲区,而另一方面,我们又希望系统减少内存占用。Buffer类使用 readv(分散读) 结合栈区空间,解决了这个问题。
具体做法是:在栈上准备一个 65536 字节的 extrabuf,然后利用 readv() 来读取数据,iovec 有两块,第一块指向 Buffer 中的 writable 字节,另一块指向栈上的 extrabuf。这样如果读入的数据不多,就全部都读到 Buffer 中去了;如果长度超过 Buffer 的 writable 字节数,就会读到栈上的extrabuf 里,然后再把 extrabuf 里的数据 append 到 Buffer 中。
ssize_t Buffer::readFd(int fd, int* Errno)
{
char extrabuf[65536];
struct iovec vec[2];
const size_t writable = writableBytes();
//分散读,buffer内的 writable字节(堆区)+ 固定的 extrabuf(栈区)
vec[0].iov_base = begin() + writerIndex;
vec[0].iov_len = writable;
vec[1].iov_base = extrabuf;
vec[1].iov_len = sizeof(extrabuf);
//如果writable已经很大了,就无需将第二块内存分配出去
const int iovcnt = (writable < sizeof(extrabuf)) ? 2 : 1;
const ssize_t len = readv(fd, vec, iovcnt);
if (len < 0)
{
*Errno = errno;
}
else if (static_cast<size_t>(len) <= writable)//长度未超过buffer的writable字节数
{
writerIndex += len;
}
else//长度超过buffer的writable字节数
{
writerIndex = buffer.size();
append(extrabuf, len - writable);
}
return len;
}Buffer.h (Buffer类内的声明均在上述描述中给出定义)
class Buffer
{
public:
Buffer(size_t initialSize = 1024);
~Buffer() = default;
size_t readableBytes() const;
size_t writableBytes() const;
size_t prependableBytes() const;
const char* peek() const;
char* beginWrite();
const char* beginWrite() const;
void ensureWriteableBytes(size_t len);
void hasWritten(size_t len);
void unwrite(size_t len);
void retrieve(size_t len);
void retrieveUntil(const char* end);
void retrieveAll();
std::string retrieveAllAsString();
std::string retrieveAsString(size_t len);
void append(const std::string& str);
void append(const char* str, size_t len);
void append(const void* data, size_t len);
ssize_t readFd(int fd, int* Errno);
private:
char* begin()
{
return &*buffer.begin();
}
//常量默认调用此重载函数
const char* begin() const
{
return &*buffer.begin();
}
void makeSpace(size_t len);
std::vector<char> buffer;
size_t readerIndex;
size_t writerIndex;
};参考资料:
Muduo 设计与实现之一:Buffer 类的设计_陈硕的博客-CSDN博客
http://code.google.com/p/muduo/source/browse/trunk/muduo/net/Buffer.cc#36