前言
前面Android性能优化 - 从SharedPreferences跨越到DataStore一文主要介绍了DataStore的实现原理,以及DataStore相对于SharedPreferences的提升,本文主要简述MMKV相对于SharedPreferences存储的使用及优劣势,以及MMKV原理,以及三者对比之下各自的优缺点和使用场景。
浅谈SharedPreferences
SharedPreferences(以下使用SP简称)是在Android中的一种轻量级的存储方式,支持开发者将基本类型数据以键值对的形式进行存储。SP具有在应用内数据可以共享,使用简单方便的优点。
SP会将数据以文件的形式进行存储,具体路径:
/data/data/<packagename>/shared_prefs/
下面对于SP的使用进行简单说明。
- 首先获取SP对象
使用SP首先需要需要获取SP对象,可以通过Context.getSharedPreferences(key, Context.MODE_PRIVATE)获取到SP对象。
注意⚠️:Mode目前只有Context.MODE_PRIVATE,表示此文件是私有数据,只能够被应用本身访问,写入覆盖。其余的在新版API中均已废弃。
- 存储数据
var sp = this.getSharedPreferences("test",Context.MODE_PRIVATE)
var edit = sp.edit()
edit.putBoolean("flag",true)
edit.putInt("temp",1) //统一put完数据再提交,否则可能会空异常
edit.apply() //edit.commit()
commit()和apply()都可以提交SP存储,但是两者有所区别:
1. apply()立刻更改内存中的SP值,但是会异步的将更新写入磁盘,无返回值
2. commit()则是会同步的写入的磁盘,需要注意其调用的线程(不要放在主线程),有返回值,返回是否成功的写入存储。
- 取数据
获取到SP对象之后直接get即可:
var sp = this.getSharedPreferences("test",Context.MODE_PRIVATE)
var result = sp.getBoolean("flag",false) //第二个参数是没有获取到数据的默认值
走进MMKV
MMKV是腾讯开源的一款基于mmap内存映射的键值对组件,底层序列化次用了prorobuf实现,性能高且稳定性良好,能够很好的取代SP存储。
1. SP和MMKV优缺点对比
SP虽然简单易用,但是在开发过程中依然存在不少缺点,具体如下:
- 多进程共享。系统自带的SP存储对于多进程几乎不支持,并且官方文档上明确指出SP不能使用在多进程上,如果要实现SP存储支持多进程,必须由我们手动去封装ContentProvider实现,实现较复杂并且性能低下。
- 数据加密。SP存储实际上是将键值对数据放到本机文件中进行存储,如果需要数据安全需要自己加密。
- 效率一般。SP是以xml进行存储的,大量数据不能使用该方式存储。
- 只支持基本数据类型,支持存储的数据类型有booleans, floats, ints, longs, and strings。
针对如上的几个缺点,MMKV都进行了改进:
- MMKV支持多进行共享。MMKV是基于mmap内存映射的方式,而mmap共享内存本质上是多进程共享的,因此MMKV是支持多进行共享并且效率较高。
- 数据加密。MMKV采用了AES CFB-128算法进行加密解密。
- MMKV采用了跨平台的protobuf进行序列化和反序列化,比起SP的xml存放方式更加高效。
- 支持从SP迁移。MMKV对于SP迁移做了很多支持,项目内如果想由SP迁移到MMKV十分方便。
- 支持更多的数据类型,不但支持boolean、int、long、float、double、byte[],还支持String,Set以及实现了Parcelable的类型。
综上所述,MMKV有着速度快,方便易用的优势,下面对其使用进行简单说明。
2. 使用MMKV
1. 包引入及初始化
首先需要引入MMKV包,在buil.gradle中添加如下内容:
implementation 'com.tencent:mmkv:1.2.7'
然后需要在自定义Application中添加初始化:
MMKV.initialize(this)
2. MMKV对象获取
MMKV提供了一个全局的实例,可以直接使用:
var mmkv = MMKV.defaultMMKV()
也可以自定义MMKV对象,设置自定ID
var mmkv2 = MMKV.mmkvWithID("id")
MMKV默认是支持单进程的,如果业务需要多进程访问,需要在初始化的时候添加多进程模式参数:
var mmkv3 = MMKV.mmkvWithID("myId",MMKV.MULTI_PROCESS_MODE)
3. 存取方法
使用MMKV的存取比较简单,方法如下:
//存储方法
mmkv?.encode(key,data)
//获取方法
mmkv?.decodeString(key,"defaultValues")
获取方法需要根据类型进行自己选择。
4. 自定义文件目录
MMKV 默认把文件存放在$(FilesDir)/mmkv/目录。你可以在 MMKV初始化时自定义根目录:
val dir = filesDir.absolutePath + "/mmkv_2"
val rootDir = MMKV.initialize(dir)
5. SP迁移
MMKV可以调用importFromSharedPreferences方法进行SP的数据迁移,示例代码如下:
MMKV实现了SharedPreferences,Editor两个接口,所以在迁移之后SP的操作代码可以不用更改。
val mmkv = MMKV.mmkvWithID("myData")
val olderData = DemoApplication.mContext?.getSharedPreferences("myData", MODE_PRIVATE)
mmkv?.importFromSharedPreferences(olderData)
olderData?.edit()?.clear()?.apply()
MMKV优势及实现原理
为了能够理清MMKV的优势,我们首先需要先了解SP的工作原理。
1. SP的工作原理
SP是采用的IO写入数据的,Linux中存在有虚拟内存概念:用户空间和内核空间。
用户空间是用户程序代码运行的地方,内核空间是内核代码运行的地方。为了减小程序崩溃影响,两个控件时隔离的,也就是说即使运行在用户控件的用户程序崩溃,内核也不会受到影响。
SP采用了IO读写的操作,以read为例子说明,具体步骤如下:
- 从磁盘读取数据,将文件内从硬盘拷贝到内核空间的缓存区。
- 然后再将数据拷贝到用户控件供程序使用。
从上面两步中我们可以拷贝过程进行了两次,如果数据量比较大,性能损耗也会随之提升。

2. MMKV实现原理
MMKV的实现原理是mmap(内存映射),它是共享内存的一种(另一种是System V,可用于跨进程),原理如图所示:

在Linux中,每个进程都有着属于自己的进程控制块(PCB)和地址空间,通过页面将进程的虚拟地址和物理地址进行映射。mmap方法会把文件内容映射到一段虚拟内存上,通过对此段内存的读取和修改,实现对文件的读取和修改。
在mmap之后,并不会将文件内容直接加载到物理页上,只是在虚拟内存中分配了地址空间,当首次访问这段地址时,才会去通过查找页表,但是此时虚拟内存对应的页上没有在物理内存中缓存,则会造成“缺页”,将文件对应内容加载到物理内存上。
相对于普通的IO读写,mmap具有如下优势:
- 对文件的读取操作跨过了页缓存,减少了数据的拷贝次数,操作内存就相当于操作文件,提高了文件读取效率。
- 实现了用户空间和内核空间的高效交互方式,修改能够直接反映在映射的区域内,从而被对方空间及时获取。
- 内存准备:通过 mmap 内存映射文件,提供一段可供随时写入的内存块,App 只管往里面写数据,由操作系统负责将内存回写到文件,不必担心 crash 导致数据丢失。
- 数据组织:数据序列化方面我们选用 protobuf 协议,pb 在性能和空间占用上都有不错的表现。
- 写入优化:考虑到主要使用场景是频繁地进行写入更新,我们需要有增量更新的能力。我们考虑将增量 kv 对象序列化后,append 到内存末尾。
当然还有如下的缺点:
- 即使文件很小,甚至于只有几个字节,但是内存的最小粒度是页,因此会占用整页的大小,在连续mmap小文件,会造成内容空间的浪费。
- 对于变长文件不适合,文件无法完成拓展。
- 空间增长:使用 append 实现增量更新带来了一个新的问题,就是不断 append 的话,文件大小会增长得不可控。我们需要在性能和空间上做个折中。
3. 了解Protobuf协议
SP存储采用的是xml文件的形式去存储键值对,而MMKV是通过protobuf协议来实现的,存储方式为增量更新,也就是不需要每次修改数据都要重新将所有的数据写入文件,速度上和大小上都优于xml。
protobuf是Google开源的一个序列化框架,类似于xml,json,最大的特点是基于二进制,比一般的xml表示同样的内容要短小的多。想要了解学习的朋友可以在Protobuf官网学习一下,在此不再做更多的说明。
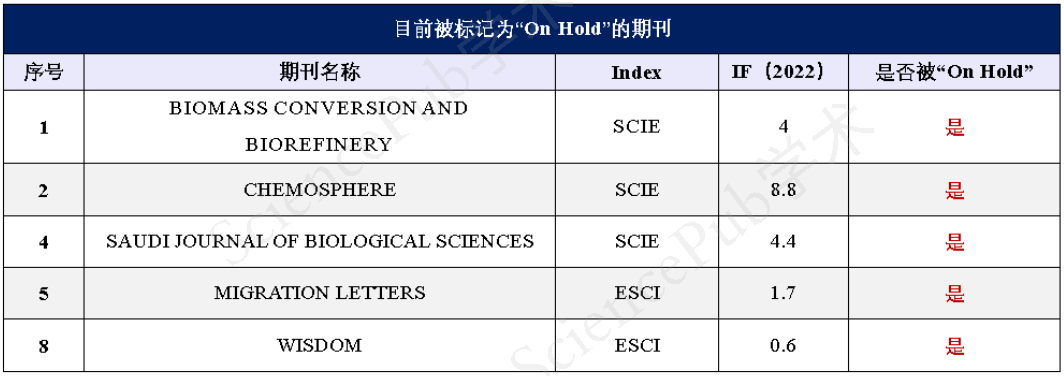
三种方案对比以及各自使用场景
到这里,SP存储,MMKV存储的实现原理已经讲的差不多了,前面一文讲SP存储过渡到DataStore存储所带来的性能优化已经对比过DataStore和SP存储,下面就来一个汇总,对这三种存储做一个综合对比。
| 功能描述 | MMKV | DataStore | SP |
|---|---|---|---|
| 是否阻塞主线程 | 否 | 否 | 是 |
| 是否线程安全 | 是 | 是 | 是 |
| 是否支持跨进程 | 是 | 否 | 否 |
| 是否支持protocol-buffers | 是 | 是 | 否 |
| 是否类型安全 | 否 | 是 | 否 |
| 是否能监听到数据变化 | 否 | 是 | 是 |
我们可以更具具体使用场景选择合适的存储方式:
多进程,跨进程通信,高频同步写入
推荐:MMKV
防止数据丢失,要求搞性能
优先推荐DataStore, 其次sp
防止数据丢失,未使用kotlin协程
推荐sp
总结
相对于SP而言,MMKV和DataStore无论是在速度上还是在文件大小上都更具有优势,是一个很方便易用的框架。但是各自有着各自的优缺点,我们要结合他们各自的优缺点以及使用场景灵活选取,切记没有最好的框架,只有用好的框架。