MySQL InnoDB Cluster
一、InnoDB Cluster 基本概述
MySQL InnoDB Cluster 为 MySQL 提供了一个完整的高可用解决方案。通过使用 MySQL Shell 提供的 AdminAPI,你可以轻松地配置和管理一组至少由3个MySQL服务器实例组成的 InnoDB 集群。
InnoDB 集群中的每个 MySQL 服务器实例都运行 MySQL Group Replication(组复制),该复制提供了在 InnoDB 集群中复制数据的机制,具有内置的故障切换功能。AdminAPI 使我们避免了直接在 InnoDB 集群中使用组复制。从 MySQL 8.0.27开始,你还可以通过链接一个主 InnoDB 集群及其一个或多个异地(例如不同数据中心)副本来组成 InnoDB ClusterSet,以此来提供异地容灾功能。
MySQL Router 可以根据你部署的集群自动配置自己,并将客户端应用程序透明地连接到 MySQL 服务器实例。如果 MySQL 服务器实例发生意外故障,集群将自动重新配置。在默认的单主模式下,InnoDB 集群只有一个读写服务器实例–主服务器,多个辅助服务器实例是主服务器的副本。如果主服务器故障,辅助服务器将自动升级为主服务器角色。MySQL Router 检测到这一点后,会将客户端应用程序的请求转发到新的 MySQL 主服务器上。高级用户还可以将集群配置为具有多个主节点,但大多情况都不必要这样做。
InnoDB 集群至少由三个 MySQL 服务器实例组成,并提供高可用性和可扩展性功能。将使用到以下 MySQL 技术:
MySQL Shell,它是MySQL官方提供的高级客户端和代码编辑器。
MySQL Server 和 Group Replication(组复制),它们配合工作可以使一组MySQL实例对外提供高可能性。InnoDB Cluster提供了另一种易于使用的编程方式来使用Group Replication(组复制)功能。
MySQL Router,一个能在应用程序和InnoDB集群之间提供透明路由的轻量级中间件,是官方提供的MySQL实例负载均衡器(不再需要借助类似HAProxy的第三方负载均衡器了)。
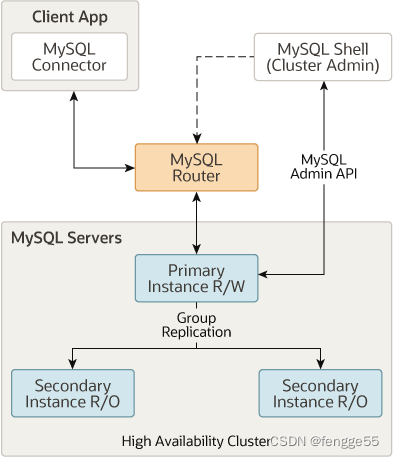
基于MySQL的Group Replication(组复制)构建的集群,可提供自动成员管理、容错、自动故障切换等功能。InnoDB集群通常以单主模式(single-primary)运行,具有一个主实例(primary读写)和多个辅助实例(secondary只读)。高级用户还可以利用多主模式(multi-primary),其中所有实例都是主实例。
你可以使用 MySQL Shell 提供的 AdminAPI 来操作 InnoDB集群。AdminAPI 有 JavaScript 和 Python 两种版本,非常适合通过编写脚本来自动化部署MySQL,以实现高可用性和可扩展性。通过使用 MySQL Shell 的 AdminAPI,你可以避免手动配置许多实例。AdminAPI 为 MySQL 实例集(组)提供了一个高效的现代化接口,可以方便地在一个统一的工具中进行配置、管理和监控部署工作。
InnoDB Cluster支持MySQL Clone(克隆),这使你可以方便地向集群配置新的实例。在过去,一个新的实例加入到MySQL集群实例集之前,你可能需要通过某种方式手动将事务传输到待加入的新实例中。这可能涉及制作文件副本、手动复制它们等等。使用InnoDB Cluster,你只需向集群添加一个实例,它就会被自动配置。类似地,InnoDB Cluster与 MySQL Router 也进行了紧密集成,你可以使用AdminAPI来使它们一起工作。MySQL Router可以基于InnoDB Cluster,通过一个被称为bootstrapping(引导)的过程自动化的配置它自己,你无需手动配置路由。然后 MySQL Router 便可透明地将客户端应用程序连接到InnoDB集群,为客户端连接提供路由和负载平衡。这种集成还允许你使用 AdminAPI 管理基于 InnoDB Cluster 引导的 MySQL Router 的某些方面。InnoDB Cluster 的集群状态信息包含了基于集群引导的 MySQL Router 的详细信息。Operations 使你可以在集群级别创建 MySQL Router 用户,以使用基于集群引导的 MySQL Router 等等。
二、重点知识
2.1 InnoDB集群要求
在进行 InnoDB Cluster 的生产部署安装之前,请确保要使用的 MySQL 服务器实例满足以下要求:
InnoDB Cluster使用组复制,因此你的服务器实例必须满足相同的要求(参考组复制要求)。AdminAPI 提供 dba.checkInstanceConfiguration() 方法来验证某个实例是否满足组复制要求,以及 dba.configureInstance() 方法来配置某个实例以满足要求。(注意:使用沙箱部署时,实例会自动配置为满足这些要求。)
用于组复制的数据以及用于 InnoDB 集群的数据,必须存储在 InnoDB 事务存储引擎中。使用其他存储引擎(包括临时内存存储引擎)可能会导致组复制错误。在使用组复制和 InnoDB 集群之前,需要将使用其他存储引擎的所有表转换为使用 InnoDB 引擎。你可以通过在MySQL服务器实例上设置 disabled_storage_engines 系统变量来防止使用其他存储引擎,例如:disabled_storage_engines=“MyISAM,BLACKHOLE,FEDERATED,ARCHIVE,MEMORY”
在安装配置集群时,任何MySQL服务器实例都不能有入站复制通道(到达型)。在一个复制组上,由Group Replication(组复制)自动创建的通道才允许被采用(group_replication_applier 和 group_replication_recovery)。InnoDB 集群不支持手工配置的异步复制通道,使用 AdminAPI 管理的除外。如果要将现有复制拓扑迁移到一个InnoDB集群部署,并且需要在安装过程中暂时跳过此验证,则可以在创建集群时使用force选项绕过它。
必须在要与 InnoDB Cluster 一起使用的所有实例上启用Performance Schema。
MySQL Shell 用于配置 InnoDB 集群中的服务器时使用到的配置脚本需要访问Python。Windows版本的 MySQL Shell 中已经包含了 Python,不需要用户再做配置。在类 Unix 系统上,Python 必须配置为 shell 环境的一部份。要检查你的 Unix 类系统是否正确配置了Python,请执行以下操作:$ /usr/bin/env python ,如果Python解释器启动,则无需进一步操作。如果前面的命令失败,请在你的 Unix类系统上安装正确版本的Python,并在 /usr/bin/python 和你安装的 Python 二进制可执行文件之间创建一个软链接。
从8.0.17版开始,MySQL实例必须在 InnoDB 集群中使用唯一的 server_id 。当你使用 Cluster.addInstance(instance) 操作时,如果 instance 的 server_id 已经被集群中的其他实例使用,那么该操作将失败并报错。
从8.0.23版开始,应将MySQL实例配置为使用并行复制申请者(applier)。
在配置 InnoDB 集群的某个MySQL实例过程中,实例要使用的绝大部分系统变量都已经被配置好了。但是 AdminAPI 不会进行 transaction_isolation 系统变量的配置,这意味着它将保持默认值 REPEATABLE READ 。这不会影响单主模式(single-primary)集群,但是如果你使用的是多主模式(multi-primary)集群,那么除非你的应用程序确实依赖默认值 REPEATABLE READ ,否则我们强列建议将值设置为 READ COMMITTED 隔离级别。
实例的相关配置项,尤其是组复制配置项,必须位于单个 option 文件中。InnoDB Cluster只支持服务器实例的单个 option 文件,不支持使用–defaults-extra-file 选项指定附加的 option 文件。对于任何使用实例 option 文件的 AdminAPI 操作,必须指定主文件。 如果你想为与 InnoDB Cluster 无关的配置项使用多 option 文件,你必须手动配置这些文件,并考虑多 option 文件的使用优先规则,确保它们被正确更新,并确保与 InnoDB Cluster 相关的设置没有错误地被一个未被认可的额外 option 文件中的选项覆盖。
2.2 InnoDB集群限制
由于InnoDB Cluster使用了Group Replication(组复制),所以除了下面列的限制外,还要考虑组复制的限制:
InnoDB 集群不管理手动配置的异步复制通道。Group Replication(组复制)和 AdminAPI 不确保异步复制仅在主服务器上处于活动状态,并且不跨实例复制状态。这可能会导致复制不再工作的各种情况,并且可能导致集群出现脑裂。只有从 MySQL 8.0.27 版本开始可用的 InnoDB ClusterSet 才支持在一个 InnoDB 集群与另一个集群之间的复制,它管理着从一个活动的主读写 InnoDB 集群到多个只读副本集群的复制工作。
InnoDB Cluster 被设计为在局域网中部署。在广域网上部署单个 InnoDB 集群对写性能有显著影响。稳定且低延迟的网络对于InnoDB 集群成员服务器使用底层 Group Replication(组复制)技术相互通信以达成事务共识非常重要。然而,InnoDB ClusterSet 是被设计为跨多个数据中心部署的,每个 InnoDB 集群部署在单个数据中心中,通过异步复制通道将它们连接起来。
对于 AdminAPI 操作,你只能使用 TCP/IP 连接和经典的 MySQL 协议连接到InnoDB集群中的服务器实例。AdminAPI操作不支持使用 Unix sockets 和 named pipes(命名管道),AdminAPI 操作也不支持使用 X 协议。同样的限制也适用于MySQL 服务器实例本身之间的连接。(注意:客户端应用程序可以使用 X 协议、Unix sockets 和 named pipes(命名管道)连接到InnoDB集群中的实例,这些限制仅适用于使用 AdminAPI 命令的管理操作,以及集群内实例之间的连接)
AdminAPI 和 InnoDB Cluster支持 MySQL Server 5.7 版本的实例。但是对这些实例会有一些限制,并且有一些功能在这版本上不支持。
使用多主模式时,不支持针对同一对象但在不同服务器上发出的并发DDL语句和DML语句。在某个对象上发出数据定义语句(DDL)期间,在同一对象上但从不同服务器实例发出并发数据操作语句(DML),可能会导致在不同实例上执行的DDL冲突风险而未被检测到。(参考组复制的限制)
2.3 InnoDB集群的用户账户
InnoDB集群中的成员服务器使用三种类型的用户帐户。一个 InnoDB 集群服务器配置帐户用于为集群配置服务器实例。可以为管理员创建一个或多个 InnoDB 集群管理员帐户,以便在集群安装后管理服务器实例。可以为 MySQL Router 实例创建一个或多个 MySQL Router 帐户,用于连接到集群。这些用户帐户必须存在 InnoDB 集群中的所有成员服务器上都存在,并且使用相同的用户名和密码。
2.3.1 InnoDB 集群服务器配置帐户
此帐户用于创建和配置 InnoDB 集群的成员服务器。每个成员服务器只有一个服务器配置帐户。集群中的每个成员服务器必须使用相同的用户帐户名和密码。为此,你可以在服务器上使用 root 帐户,但如果这样做,集群中每个成员服务器上的 root 帐户必须具有相同的密码。出于安全原因,不建议这样做。
首选方法是使用 clusterAdmin 选项中的 dba.configureInstance()命令创建一个 InnoDB集群服务器配置账号。为提高安全性,请在交互提示下指定密码,也可以使用 clusterAdminPassword 选项指定密码。在将成为 InnoDB 集群一部分的每个服务器实例上以相同的方式创建相同的帐户,使用相同的用户名和密码——包括你连接以创建集群的实例,以及之后将加入集群的实例。
dba.configureInstance()命令会自动授予帐户所需的权限(你也可以手动设置该帐户并授权,但不建议这么做)。除了完整的 MySQL 管理员权限外,该帐户还需要对 InnoDB 集群元数据表拥有完整的读写权限。
使用 dba.configureInstance()命令创建一个 InnoDB集群服务器配置账号不会复制到集群内的其他服务器上。MySQL Shell 禁用了 dba.configureInstance()命令的二进制日志记录。这意味着你必须在每个 MySQL 服务器实例上单独创建该帐户。
2.3.2 InnoDB 集群管理员帐户
这些帐户在你完成集群配置之后,可用于管理 InnoDB 集群。你可以设置多个,每个帐户必须存在于 InnoDB 集群中的每个成员服务器上,并具有相同的用户名和密码。
为了给 InnoDB ClusterSet 创建 InnoDB 集群管理员账号,你需要在将所有实例添加到集群后执行 cluster.setupAdminAccount()命令。该命令将使用你给定的用户名和密码创建账号,并赋予必要的权限。使用cluster.setupAdminAccount()创建一个账号的事务将被写入到二进制日志,并发送到集群内所有其他服务器实例上,用于在这些服务器上创建相同的账号。(备注:如果主InnoDB 集群是在MySQL Shell 8.0.20之前版本部署的,cluster.setupAdminAccount()命令可能与 update 选项一起使用,以更新 InnoDB集群服务器配置帐户的权限,这是未写入二进制日志的命令的特殊用法)
2.3.3 MySQL Router 帐户
这些账号被 MySQL Router 用于连接到 InnoDB 集群中的MySQL服务器实例。你可以设置多个此类账号,每个帐户必须存在于InnoDB 集群中的每个成员服务器上,并具有相同的用户名和密码。创建 MySQL Router 帐户的过程与创建 InnoDB 群集管理员帐户相同,但使用的是 cluster.setupRouterAccount() 命令。(也会写binary log 进行同步创建)
2.3.4 InnoDB集群创建的内部用户帐户
作为使用组复制的一部分,InnoDB 集群会创建内部恢复用户