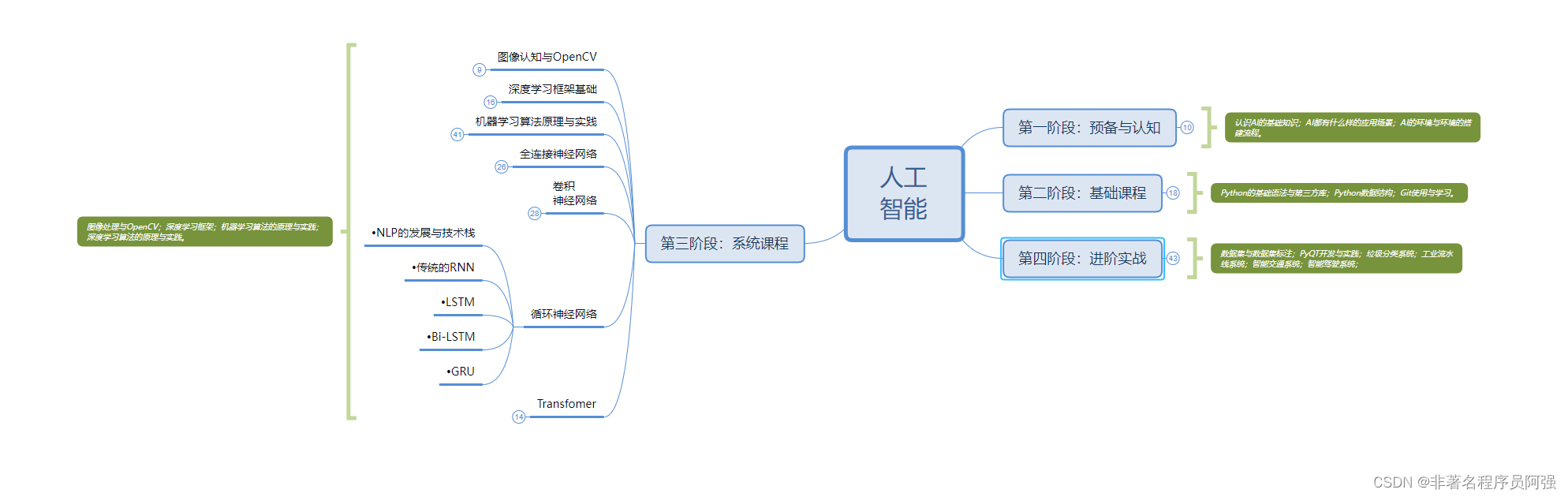
贝叶斯统计学是一种基于贝叶斯定理的概率推理方法,它提供了一种对概率进行建模和更新的框架。贝叶斯方法在机器学习中得到了广泛的应用,特别是在分类问题中,如垃圾邮件过滤、文本分类等。与传统的频率主义方法相比,贝叶斯方法具有更好的数学基础和更灵活的建模能力。
Scikit-learn是Python中流行的机器学习库之一,它提供了丰富的机器学习算法和工具。在Scikit-learn中,贝叶斯模型也得到了很好的支持和实现。本文将以贝叶斯分类为例,介绍如何在Scikit-learn中实践贝叶斯分类算法。
1. 数据准备:
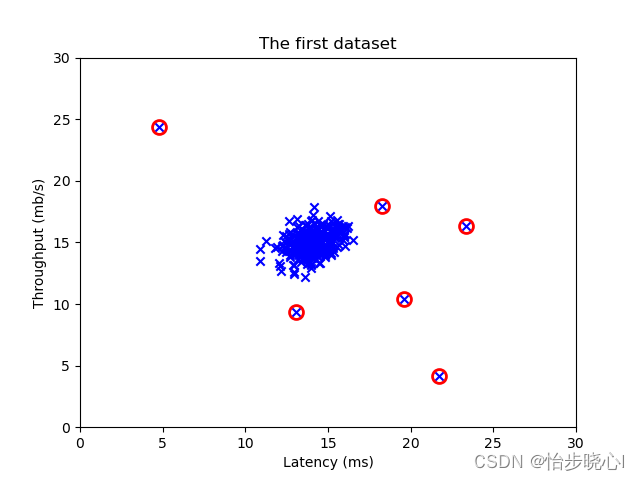
首先,我们需要准备数据集。贝叶斯分类是一种监督学习算法,因此我们需要有标记的训练数据集。通常情况下,我们将数据集划分为特征和标签两部分,其中特征是描述数据的属性,标签是数据的类别或结果。
2. 特征工程:
在数据准备之后,我们需要进行特征工程,以提取对分类任务有用的特征。特征工程可以包括特征选择、特征变换和特征构建等过程。Scikit-learn提供了一系列的特征工程方法和工具,如特征选择方法SelectKBest,特征变换方法StandardScaler等。
3. 模型选择和训练:
在进行特征工程之后,我们可以选择相应的贝叶斯分类模型进行训练。Scikit-learn提供了多种贝叶斯分类模型的实现,包括朴素贝叶斯(Naive Bayes)、高斯朴素贝叶斯(Gaussian Naive Bayes)、多项式朴素贝叶斯(Multinomial Naive Bayes)等。以Gaussian Naive Bayes为例,我们可以使用以下代码进行模型的选择和训练:
from sklearn.naive_bayes import GaussianNB
# 创建Gaussian Naive Bayes模型
model = GaussianNB()
# 拟合模型
model.fit(X_train, y_train)在拟合模型的过程中,我们将训练数据集的特征和标签传递给模型的fit()方法,从而进行模型的训练。
4. 模型评估和优化:
在训练完成后,我们需要对模型进行评估。Scikit-learn提供了多种评估指标和方法,如准确率(Accuracy)、精确率(Precision)、召回率(Recall)等。通过评估指标,我们可以了解模型在训练数据集上的表现。
此外,我们还可以进一步优化模型。例如,我们可以调整模型的超参数,选择更合适的特征集合,或者使用交叉验证等方法进行模型选择和调优。
5. 模型应用:
在完成模型评估和优化后,我们可以将训练好的模型应用到实际问题中。对于新的未标记数据,我们可以使用模型的predict()方法进行预测。例如:
# 预测新数据的类别
y_pred = model.predict(X_new)在预测过程中,我们将新的特征数据传递给模型的predict()方法,从而得到预测的类别标签。
结论:
贝叶斯分类是机器学习中常用的分类算法之一,它基于贝叶斯统计原理,通过概率推理进行分类任务。Scikit-learn是Python中强大的机器学习库,提供了丰富的贝叶斯分类算法和工具,方便开发者进行贝叶斯分类任务的实践。
在实践中,我们需要对数据进行准备和特征工程,选择适当的贝叶斯分类模型,并进行模型的训练、评估和优化。最后,我们可以将训练好的模型应用到实际问题中,进行新数据的预测和分类。
通过Scikit-learn中贝叶斯分类的实践,我们可以更好地理解和使用贝叶斯统计学在机器学习中的应用,为解决实际问题提供更可靠的方法和工具。
人工智能的学习之路非常漫长,不少人因为学习路线不对或者学习内容不够专业而举步难行。不过别担心,我为大家整理了一份600多G的学习资源,基本上涵盖了人工智能学习的所有内容。点击下方链接,0元进群领取学习资源,让你的学习之路更加顺畅!记得点赞、关注、收藏、转发哦!扫码进群领资料