一文整理了方差分析的全部内容,包括方差分析的定义(基本思想、检验统计量的计算、前提条件)、方差分析分类(单因素、双因素、多因素、事后多重比较、协方差分析、重复测量方差分析)、方差分析流程(数据格式、前提条件检验、进行方差分析、结果解读)、方差分析的应用(回归模型整体显著性检验、回归模型筛选变量、方差齐检验、正交试验选择最优组合)、参数检验与非参数检验(基本说明、对比、常用方法对比、差异性分析的其他方法),5大部分的内容。

一、方差分析定义
1、基本思想
方差分析(Analysis of Variance,简称ANOVA),是由R.A.Fisher发明的,,由英国统计学家R.A.Fisher首创,为纪念Fisher故以F命名,所以方差分析又称“F检验”。用于两个及两个以上样本均数差异的显著性检验。方差分析的基本思想是分解变异,即将数据总的变异分解为处理因素引起的变异和随机误差引起的变异,通过对两者进行比较作出处理因素有无作用的统计推断。
2、检验统计量F值的计算
上面提到方差分析的基本思想是分解变异,实验数据之间共有3个不同的变异。
(1)总变异
全部观测值大小不同,这种变异称为总变异。总变异的大小因离均差平方和表示,即各观测值Xij与总均数\overline{X}差值的平方和,记为SS_总。总变异SS_总反应了所有观测值之间总的变异程度,计算公式为:

(SS_总=\sum_{i=1}^{g}\sum_{j=1}^{n_i}(X_{ij}-\overline{X})^{2})
(2)组间变异
各处理组的样本均数\overline{X_i}大小也不等,这种变异称为组间变异,其大小用各组均数与总均数的离均差平方和来表示,记为SS_组间,计算公式为:

(SS_{\text{组间}} = \sum _ { i = 1 }^{g}n_{i}(\overline{X}_{i}-\overline{X})^{2})式中n_i为各组样本数。各组均数\overline{X_i}之间相差越悬殊,他们与总均数\overline{X}的差值越大,SS_组间就越大,反之SS_组间越小。
(3)组内变异
每个组内的数据大小不等,称为组内变异,用SS_组内表示,其大小可用各组内部所有数据X_ij与该组均数\overline{X_i}的离均差平方和来表示,计算公式为:

(SS_{\mathrm{组内}}=\sum_{i=1}^{g}\sum_{j=1}^{n_{i}}(X_{ij}-\overline{X}_{i})^{2})
可以证明,上述三种变异的关系为SS_总=SS_组间+SS_组内
三种变异的自由度计算公式分别为:
V_总=N-1,V_组间=g-1,V_组内=N-g
相应的,总自由度可分解为组间自由度与组内自由度之和,即
V_总= V_组间+V_组内
变异程度除与离均差平方和的大小有关外,还与其自由度有关,由于各部分自由度不相等,因此各部分离均差平方和不能直接比较,需将各部分离均差平方和除以相应的自由度,其比值称为均方差,简称均方(MS),组间均方与组内均方的计算公式为:

(MS_\text{组间}=\frac{SS_\text{组间}}{ \nu _\text{组间}})

(MS_\text{组内}=\frac{SS_\text{组内}}{ \nu _\text{组内}})
如果各组样本的总体均数相等(H_{0}\colon\mu_{1}=\mu_{2}=\cdots=\mu_{g}),则组间变异与组内变异一样,只反映随机误差作用的大小,组间均方与组内均方的比值称为F统计量

(F=\frac{MS_\text{组间}}{ M S _\text{组内}} \quad \nu _ 1 = \nu _\text{ 组间},\nu_2=\nu_\text{组内})
若F值接近于1,就没有理由拒绝H_0,;反之F值越大,拒绝H_0的理由越充分。若对应p值<0.05,则拒绝H_0,认为各样本总体均数不全相等,存在显著差异;否则无差异。

3、前提条件
上述变异分解、均方估计及F统计量都是基于正态分布理论,进行方差分析时同样要求资
料满足正态分布且方差相等的基本假设。故方差分析的前提条件有以下3个:
1、各样本组内观察值相互独立;
2、各样本服从正态分布;
3、各样本组内观察值总体方差相等,即方差齐性。
二、方差分析分类
方差分析从使用频率来讲可分为以下6类:单因素方差分析、双因素方差分析、多因素方差分析、事后多重比较、协方差分析、重复测量方差分析,接下来分别进行简单介绍。
1、单因素方差分析
用于分析一类定类数据与定量数据之间的差异性,且定类数据通常为多分类数据。比如分析不同班级(1班、2班、3班)学习成绩之间的差异,就可以使用单因素方差分析进行3个班级学习成绩均值的差异性分析(独立样本t检验只能进行2组数据之间均值差异的比较)。
- SPSSAU位置:【通用方法】模块->【方差分析】

2、双因素方差分析
用于分析2类定类数据与定量数据之间的差异性,比如分析不同班级(1,2,3班)、不同性别(男女)学习成绩之间的差异,此时可使用双因素方差分析。当主效应存在,即方差分析结果显示存在显著差异时(p<0.05),要具体对比两两组别的差异(如1班和2班,2班和3班,1班和3班),需要进行事后多重比较。双因素方差还可以分析二阶交互效应。如班级*性别这个交互项是否存在显著差异,如果进行二阶效应且呈现出显著性,此时可进一步进行简单效应分析。后面在第3部分方差分析流程中会详细进行说明。
- SPSSAU位置:【进阶方法】模块->【双因素方差】

3、多因素方差分析
三因素及以上统称为多因素方差分析,用于分析多类定类数据与定量数据之间的差异。如三因素方差分析,可同时进行二阶效应分析和三阶效应分析。当主效应存在时,可进行事后多重比较;当交互效应存在时,需要进行简单效应分析。后面第3部分将详细进行说明。
SPSSAU位置:【进阶方法】模块->【三/多因素方差】

4、事后多重比较
事后多重比较是基于方差分析进行的,当某一定类数据呈现出显著差异,要具体对比该类别下两两组别之间的差异性时,就需要进行事后多重比较。
- SPSSAU位置:【进阶方法】模块->【事后多重比较】
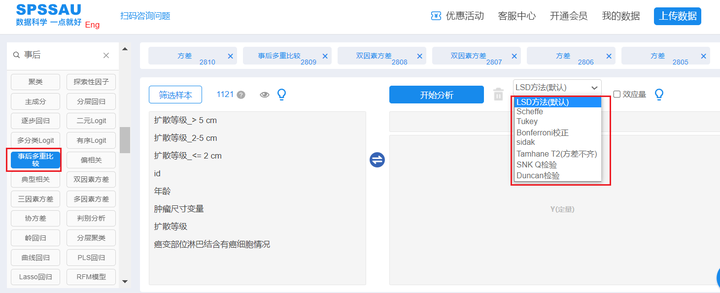
事后多重比较的方法有很多种,但功能均一致,仅在个别点或使用场景上有小区别,当前SPSSAU共提供LSD,Scheffe,Tukey,Bonferroni校正,Sidsk,Tamhane T2,SNK Q检验、Duncan检验,共8种事后多重比较方法,该8种方法如何选择说明如下表格所示:

其中,LSD法使用最广泛。LSD法又称最小有意义差异t检验,用于多组中两两组在专业上有特殊意义的均数进行比较。检验统计量LSD-t的界值是一般的t界值,统计量计算公式为:

(LSD-t=\frac{\left|\overline{X}_i-\overline{X}_j\right|}{S_{\bar{X}_i-\bar{X}_j}}=\frac{\left|\overline{X}_i-\overline{X}_j\right|}{\sqrt{MS_{\text{误差}\left(\frac1{n_i}+\frac1{n_j}\right)}}},\nu=\nu_{\text{误差}})
5、协方差分析
如果在方差分析过程中,会有干扰因素;比如“减肥方式”对于“减肥效果”的影响,年龄很可能是影响因素;同样的减肥方式,但不同年龄的群体,减肥效果却不一样;年龄就属于干扰项,因此在分析的时候需要把它纳入到考虑范畴中。如果方差分析时需要考虑干扰项,此时就称之为协方差分析,而干扰项也称着协变量。
- SPSSAU位置:【进阶方法】模块->【协方差分析】

协方差分析有一个重要的假设即“平行性检验” :平行性是指自变量X与协变量对于因变量Y的影响时,自变量X与协变量之间保持独立性。
如果交互项(即有*号项)的p 值>0.05则说明平行,满足平行性检验,可进行分析。如果协方差分析不满足平行性,交互项(即有*号项)的p 值< 0.05则说明不平行,不满足平行性检验,此时应该将协变量项移出。
6、重复测量方差分析
重复测量方差分析(Repeated analysis of measurement variance)常见于医学实验中。当我们需要对同一因变量进行重复测量,如果仍然使用一般的方差分析就会出现问题,因为在重复测量时,观测对象的测量结果之间存在一定程度的相关,这违背了方差分析数据独立性的要求,所以在进行分析时就需要选择重复测量方差分析。
重复测量设计在医学、生物学研究中较为常见,即在给予一种或多种处理后,在多个时间点上从同一个受试对象重复获得指标的观察值。重复测量研究的目的是探讨同一研究对象在不同时间点某指标的变化情况,例如患者在治疗后(或手术后)1天、2天、1周、2周等,各时间点上某指标的变化。
重复测量方差分析时涉及两个重要的术语名词,分别是组内和组间。比如有这样一项关于抑郁症的研究,共有12名患者,分别6名患者使用新药或者旧药;并且分别测试12名患者用药后分别第1周,第4周和第8周时的抑郁程度。因此数据中涉及到时间点的记录,和组别的记录。时间点则称之组内项,组别称为组间项。
- SPSSAU 位置:【实验/医学研究】模块->【重复测量方差】

有关重复测量方差的部分可查看SPSSAU帮助手册,本文主要探讨通用方差分析的部分。
https://spssau.com/helps/medicalmethod/repeatedAnova.html
三、方差分析流程
第3大部分将结合一个双因素方差分析的案例,介绍方差分析的流程,包括数据格式、前提条件检验、软件操作以及结果解读。这部分将具体介绍差异幅度的效应量指标、事后多重比较、交互效应以及简单效应分析的内容。
案例:假设有甲乙丙三种施肥方式,A、B、C三种小麦品种,现在想要研究不同施肥方式和不同品种小麦之间产量是否有差异,以及施肥方式和品种的交互作用对水稻产量是否有影响。使用双因素方差分析进行研究,收集到部分数据如下:

1、数据格式
第2部分提到的6种方差分析方法的数据格式可大概分为2类,一类为常规格式,一类为重复测量方差分析的数据格式。
(1)常规格式
不论是单因素方差、双因素方差、多因素方、协方差,其均是研究X对于Y的差异,1个X均占用1列,1个Y也占用1列,如果有协变量那么1个协变量占用1列。数据格式类似如下:

(2)重复测量方差格式
重复测量数据是指同一批样本(病例)在不同的时间点测量了多次数据,因此重复测量数据的特殊之处在于一定会有ID号(即样本或者病例号),以及时间点数据,如下图。同一个ID会有多个时间点的数据,比如下面有12个样本(12个ID号),并且测量5个时间点。那么就一定会有12*5=60行数据。同一个ID号会重复5次,同一个时间点会重复12次。

2、前提条件检验
使用方差分析需要满足独立性、正态性、方差齐性的前提条件。接下来本案例数据进行前提条件检验。
(1)独立性检验
方差分析独立性是指各组数据之间相互独立,通常独立性与试验设计有关,主观判断即可。因为各组小麦施肥方式与品种之间不存在相互影响,因此满足独立性假设。
(2)正态性检验
正态性检验的方法有很多种,包括统计检验法(Kolmogorov-Smirnov检验、Shapiro-Wilk检验、Jarque-Bera检验)、描述法(峰度绝对值小于10并且偏度绝对值小于3,则说明数据基本可接受为正态分布)、图示法查看直方图、P-P图或Q-Q图等。
其中,统计检验法最为严格,如果对数据正态性要求很严格时,可以使用该种方法。但当对数据正态性要求不是特别严格时,可以使用图示法进行正态性检验,如果直方图近似呈现为“中间高,两头低”的钟形或者P-P图和Q-Q图近似呈一条对角直线,则可认为数据近似满足正态分布。
本案例使用统计检法对各组样本数据的正态性检验,分别对不同品种、不同施肥方式的产量进行正态性检验,操作如下图:

分别得到正态性检验结果如下:


小样本(n<50)时建议使用Shapiro-Wilk检验,分析各组正态性检验结果可知,p值均大于0.05,说明数据满足正态性特质(原假设为数据满足正态分布)。
当数据不满足正态分布时,可以尝试进行数据转换。或者因为方差分析对数据正态性不是特别敏感,若数据不是那么严重偏态,仍然可以进行方差分析。
接下来验证方差齐性。
(3)方差齐性
各组数据的方差齐性,用于检验各个组别数据的波动情况(标准差)是否有明显的差异,可通过SPSSAU【通用方法】模块的方差分析中的方差齐检验进行分析,SPSSAU操作如下图:

得到方差齐结果如下:


分析方差齐结果可知,不同品种的产量均满足方差齐性(p>0.05),但是不同施肥方式的产量不满足方差齐性。一般来讲如果不满足方差齐条件,方差分析的检验性能也较好,因而多数时候并没有进行方差齐检验直接就使用方差分析。所以本案例将继续进行双因素方差分析(演示使用)。
当数据不满足方差齐性时,可使用非参数检验,同时还可使用welch 方差,或者Brown-Forsythe方差进行分析。
3、进行方差分析
前提条件检验完成后,接下来进行双因素方差分析。同时研究效应量大小、二阶效应、简单效应以及事后多重比较,在分析前,勾选SPSSAU的方框即可,操作如下图:

SPSSAU得到双因素方差分析结果如下:
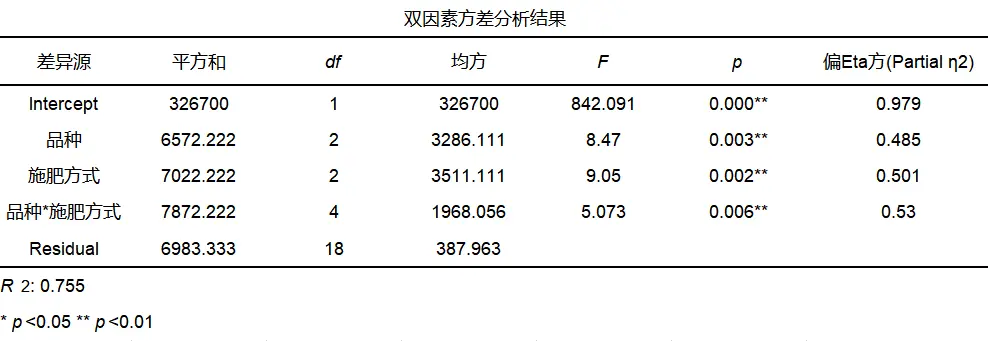
4、结果解读
(1)先看p值
分析双因素方差分析结果可知,品种呈现出显著性(F=8.470,p=0.003<0.05) ,说明主效应存在,品种会对产量产生差异关系,可对品种进行事后多重比较,比较两两品种之间产量的差异。施肥方式呈现出显著性(F=9.050,p=0.002<0.05) ,说明主效应存在,施肥方式会对产量产生差异关系,同理可进行事后多重比较。品种和施肥方式的交互项呈现出显著性(F=5.073,p=0.006<0.05),可进一步分析二阶效应和简单效应。
(2)具体差异对比
当自变量呈现出显著差异(p<0.05),可通过以下3种方式进行具体差异对比。
方法1:对比平均值
主效应存在时具体差异可通过单因素方差分析进行均值对比,比如对施肥方式的产量进行单因素方差分析,得到结果如下:

具体对比平均值差异可知,施肥方式甲的平均产量为94.444,明显低于施肥方式乙产量103.333和丙产量132.222。同理可对品种进行单因素方差分析,在此不在进行赘述。
方法2:可视化图形
表格形式不够直观,可通过折线图的形式对品种和施肥方式的均值进行直观展示,SPSSAU单因素方差分析自动输出可视化图形如下:

方法3:效应量指标
还可以通过效应量指标描述差异幅度,常用的包括偏Eta方(Partial η2)和Cohen's d值。偏Eta方值介于0~1之间,该值越大说明差异幅度越大,比如偏Eta方为0.1,即说明数据的差异有10%是来源于不同组别之间的差异。使用偏Eta方表示效应量大小时,效应量小、中、大的区分临界点分别是:0.01,0.06和0.14。
与此同时,事后多重比较中会提供Cohen's d值这一效应量值,通常情况下Cohen's d 值表示效应量大小时,效应量小、中、大的区分临界点分别是:0.20,0.50和0.80。

分析上表输出的偏Eta方(Partial η2)值,品种、施肥方式、品种*施肥方式的效应量值分别为0.485,0.501,0.53,说明这3类变量组内存在很大程度的差异。
3、事后多重比较
当主效应存在时,我们想知道具体是哪两组之间存在差异,这就涉及到因素的不同水平之间两两差异比较,称为事后多重比较。事后多重比较的方法有多种,其中最常用的为LSD法,本案例使用该方法进行事后多重比较。
比如在本案例中,我们知道施肥方式的主效应存在,那么说明不同施肥方式的产量之间存在显著差异。但是施肥方式有3种,如果想知道具体哪两种施肥方式之间存在显著差异,那就需要进行事后多重比较。SPSSAU输出施肥方式的事后多重比较结果如下:

分析上表可知,施肥方式甲-乙的产量未呈现出显著差异(p>0.05),施肥方式甲-丙、乙-丙之间均呈现出显著差异(p<0.05),且对应Cohen's d值的绝对值均大于0.8,差异幅度非常大。

同理不同品种之间进行事后多重比较,品种B-C之间未呈现出显著差异(p>0.05),品种A-B、A-C间呈现出显著差异(p<0.05),且对应Cohen's d值的绝对值均大于0.8,差异幅度非常大。
4、交互效应分析
(1)二阶效应
双因素方差分析中,我们将两个自变量的搭配对因变量产生的差异称为交互效应(也称二阶效应)。施肥方式和品种的交互项呈现出显著性((F=5.073,p=0.006<0.05),说明施肥方式和品种的交互效应对产量的影响是显著的,即二阶效应存在。
如果二阶效应存在(且前提是存在一阶主效应),则可结合品种和施肥方式的均值对比图和均值对比表进行具体分析研究。SPSSAU输出结果如下:


从上图可明显看出,施肥方式丙和品种C的组合产量176.67明显高于其他8种组合。而方式甲和品种A的组合产量83.33最低。
(2)简单效应
当交互效应呈现出显著性时,可以进一步进行简单效应分析;当交互效应没有呈现出显著性时,一般不进行简单效应分析。简单效应是指一个自变量在某个水平时,另一个自变量在不同水平下因变量差异的比较。
下表为固定某种施肥方式,进行两两小麦品种之间的简单效应分析。

分析上表可知,当施肥方式为甲时,品种A-B、A-C、B-C之间的产量均未呈现出显著差异(p值均>0.05),同理施肥方式乙下各品种产量也未呈现出显著差异。而在施肥方式丙下,品种A-B和A-C之间的产量呈现出显著差异(p值均<0.05)。
同理可分析固定品种,不同施肥方式之间产量的差异,结果如下表:

至此,有交互效应的双因素方差分析结束。
补充:有交互效应的双因素方差分析计算过程:

各平方和计算公式:

四、方差分析应用
方差分析除可进行不同样本均数之间的差异性分析,还有很多其他的应用。比如回归模型整体显著性检验、回归模型筛选变量、方差齐检验、正交试验选择最优组合等,接下来进行简单介绍。
1、回归模型整体显著性检验
构造回归模型时,显著性检验包括两部分内容:对多个自变量与因变量这个整体的显著性检验(F检验),以及每个自变量对因变量影响的显著性检验(t检验),二者都是对线性回归的显著性检验,但是检验目的不同。模型总体显著性检验,是使用F检验进行的,可以判断回归模型是否有意义。如果加入模型的自变量回归系数全为0,则Y与各个自变量没有任何关系,这就失去了建立回归方程的意义,故当检验结果为拒绝H0时,称该回归模型是有统计学意义的。
回归模型F检验结果如下(以多元线性回归模型为例):

分析上表可知,F=133.02,p=0.007<0.05,所以拒绝原假设H0,即回归模型有统计学意义。
2、回归模型筛选变量
方差分析还可用于回归模型筛选变量。当模型自变量非常多时,方差分析可以判断出各个自变量对因变量的影响程度,从而筛选出对因变量影响显著的变量。然后再放入模型中。
3、方差齐检验
方差齐性是很多方法需要满足的前提条件,比如方差分析、t检验、回归分析等。方差齐检验也是通过F检验进行的。在本文的前提条件检验部分已经讲过,不再赘述。
4、正交试验选择最优组合
正交试验后,通常会进行方差分析或者极差分析找到最优组合。极差分析原理简便,通俗易懂,在分析数据中起到了一定的作用,但这种分析方法的局限性很强。虽然我们可以将所有考查的因素进行主次的排序,得到主要因素,但这种因素对试验的影响是否显著,在何种水平上显著都无法得知,所以可以使用方差分析解决这一问题。
五、参数检验与非参数检验
方差分析是典型的参数检验方法,下面补充参数检验与非参数检验的部分内容。
1、基本说明
参数检验是假定样本总体为某一已知分布的情况下,对总体参数如均值或者方差进行估计和检验的方法。与参数检验相对的是非参数检验,非参数检验并不对总体的分布形态做假定,此时不能进行参数间的比较,而是做分布间的比较。
2、对比

(1)检验指标对比
参数检验:假设数据服从某种特定的分布,例如正态分布,并且总体参数是已知的。因此,参数检验通常关注的是样本均值与总体均值的差异,以检验样本数据是否符合预期的分布。
非参数检验:不需要数据符合特定的分布,而是基于数据本身的分布来推断总体参数。非参数检验通常关注的是数据的次序而不是具体的值,例如中位数、四分位数等。
(2)优缺点对比
参数检验:优点在于符合条件时,检验效率高。然而,它对数据的要求较为严格,如等级数据、非确定数据不能使用参数检验,而且要求数据的分布型已知和总体方差相等。此外,参数检验不适用于样本量较小且分布未知的情况。当样本量足够大时,参数检验的方法对非正态分布的数据也能够很好地进行处理,因为样本均值的分布根据中心极限定理是近似正态分布。
非参数检验:优点在于不受总体分布的限制,对数据的要求不严格,应用范围广、简便、易掌握。缺点在于若对符合参数检验条件的数据用非参数检验,则检验效率低于参数检验。非参数检验主要使用等级或者符号秩,而不是使用原始数据,会损失部分信息,降低统计检验效率,导致犯第二类错误的概率比参数检验大。此外,当样本量较小且分布未知时,通常会考虑使用非参数检验。
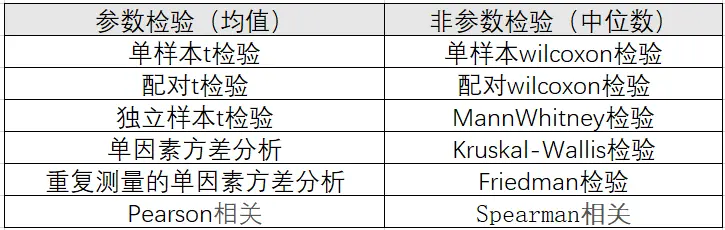
3、常用方法对比
常用方法对比如下:
4、差异性分析的其他方法
方差分析用于分析定类数据与定量数据之间的差异性,同样的还可以使用t检验进行分析。二者的区别在于t检验只能对比两组数据之间的差异,而方差分析可对比多组。如果同样为两组数据是,通常小样本(n<100)使用t检验进行分析较好,大样本时使用方差分析。若要研究定类数据与定类数据之间的差异性,应该使用卡方检验进行分析。对比说明如下:

参考文献:
[1]孙振球,徐勇勇.医学统计学.第4版[M].人民卫生出版社,2014
[2]颜红,徐勇勇.医学统计学.第3版[M].人民卫生出版社,2015