目录
一、安装redis-py库
二、连接Redis数据库
三、执行操作
1、设置和获取键值对
2、删除键值对
3、获取列表数据
四、处理数据
1、使用哈希表(Hash)处理关联数据
2、使用列表(List)处理有序数据
3、使用集合(Set)处理唯一数据
4、使用有序集合(ZSet)处理带有排序的数据
五、使用管道(Pipeline)和事务(Transaction)处理复杂操作
1、使用管道(Pipeline)处理多个操作
2、使用事务(Transaction)处理具有原子性的操作
六、使用发布/订阅(Pub/Sub)模式实现消息通信
总结
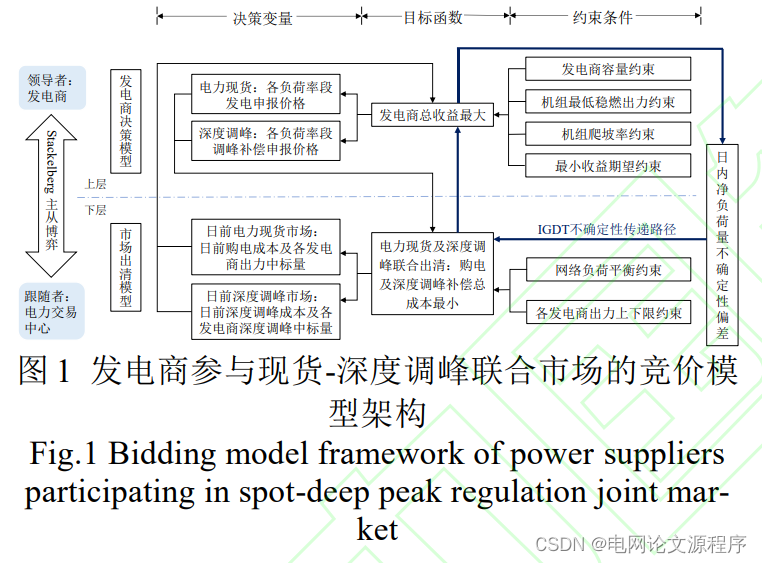
在Python中操作Redis数据库需要使用Redis Python客户端库,其中最常用的是redis-py库。下面我们将介绍如何在Python中使用redis-py库来连接Redis数据库,执行各种操作,以及处理数据。

一、安装redis-py库
首先,需要安装redis-py库。可以使用pip命令来安装:
pip install redis
二、连接Redis数据库
在Python中连接Redis数据库需要使用redis-py库中的Redis类。可以通过以下代码来连接Redis数据库:
import redis
# 创建Redis客户端对象
r = redis.Redis(host='localhost', port=6379, db=0)在上面的代码中,我们创建了一个Redis客户端对象,指定了Redis数据库的host和port参数,以及使用的数据库编号。
三、执行操作
在连接Redis数据库之后,可以执行各种操作,例如设置和获取键值对、删除键值对、获取列表数据等。下面是一些常见的Redis操作示例:
1、设置和获取键值对
可以使用Redis对象的set()方法来设置键值对,使用get()方法来获取键值对的值。例如:
# 设置键值对
r.set('name', 'Alice')
r.set('age', 20)
# 获取键值对的值
name = r.get('name').decode('utf-8')
age = int(r.get('age'))
print(name, age) # Alice 202、删除键值对
可以使用Redis对象的delete()方法来删除一个键值对。例如:
# 删除键值对
r.delete('age')
3、获取列表数据
可以使用Redis对象的lrange()方法来获取列表中的数据。例如:
# 在列表中添加数据
r.rpush('books', 'book1')
r.rpush('books', 'book2')
r.rpush('books', 'book3')
# 获取列表中的数据
books = r.lrange('books', 0, -1) # 获取列表中的所有数据,返回一个列表对象
for book in books: # 遍历列表对象并输出每个元素的值
print(book.decode('utf-8')) # book1 book2 book3除了以上示例之外,还有很多其他的Redis操作,可以根据实际需求选择不同的操作方法。需要注意的是,在使用Redis对象执行操作之后,需要使用close()方法关闭连接,释放资源。例如:
r.close()
四、处理数据
在Redis中处理数据的方式非常灵活,可以通过使用不同的数据类型和操作符来实现不同的需求。下面是一些常见的Redis数据处理方式:
1、使用哈希表(Hash)处理关联数据
Redis的哈希表可以用来存储多个键值对,每个键值对都是一个键和一个值。通过使用哈希表,可以轻松地存储和检索多个关联数据。例如:
# 设置哈希表中的键值对
r.hmset('user', {'name': 'Alice', 'age': 20})
# 获取哈希表中的数据
name = r.hget('user', 'name').decode('utf-8')
age = int(r.hget('user', 'age'))
print(name, age) # Alice 202、使用列表(List)处理有序数据
Redis的列表可以用来存储多个有序的数据项。通过使用列表,可以轻松地存储和检索一组有序的数据。例如:
# 在列表中添加数据
r.rpush('scores', 80, 90, 85)
# 获取列表中的数据
scores = r.lrange('scores', 0, -1) # 获取列表中的所有数据,返回一个列表对象
for score in scores: # 遍历列表对象并输出每个元素的值
print(score.decode('utf-8')) # 80 90 853、使用集合(Set)处理唯一数据
Redis的集合可以用来存储多个唯一的数据项。通过使用集合,可以轻松地存储和检索一组唯一的数据。例如:
# 在集合中添加数据
r.sadd('fruits', 'apple', 'banana', 'orange')
# 获取集合中的数据
fruits = r.smembers('fruits') # 获取集合中的所有数据,返回一个集合对象
for fruit in fruits: # 遍历集合对象并输出每个元素的值
print(fruit.decode('utf-8')) # apple banana orange4、使用有序集合(ZSet)处理带有排序的数据
Redis的有序集合可以用来存储多个带有排序的数据项。每个数据项都有一个关联的分数,根据分数进行排序。通过使用有序集合,可以轻松地存储和检索一组带有排序的数据。例如:
# 在有序集合中添加数据
r.zadd('scores', {'Alice': 80, 'Bob': 90, 'Charlie': 85})
# 获取有序集合中的数据
scores = r.zrange('scores', 0, -1) # 获取有序集合中的所有数据,返回一个列表对象
for score in scores: # 遍历列表对象并输出每个元素的值
print(score.decode('utf-8')) # Alice 80 Charlie 85 Bob 90(按照分数从小到大排序)五、使用管道(Pipeline)和事务(Transaction)处理复杂操作
在处理复杂的Redis操作时,可以使用管道(Pipeline)和事务(Transaction)来提高效率和安全性。
1、使用管道(Pipeline)处理多个操作
Redis管道可以用来将多个Redis操作打包成一个批次操作,并一次性发送到服务器上执行。通过使用管道,可以减少网络通信的开销,提高处理多个操作的效率。例如:
pipe = r.pipeline()
pipe.set('name', 'Alice')
pipe.set('age', 20)
pipe.execute() # 一次性执行所有操作2、使用事务(Transaction)处理具有原子性的操作
Redis事务可以用来将多个Redis操作打包成一个原子性操作,并一次性发送到服务器上执行。通过使用事务,可以确保多个操作在执行过程中的原子性,避免在执行过程中被其他客户端干扰。例如:
with r.transaction():
r.set('name', 'Alice')
r.set('age', 20)在上面的代码中,使用了Redis的事务功能,将两个设置键值对的操作打包成一个原子性操作,确保它们被一次性执行完毕,不会被其他客户端干扰。
六、使用发布/订阅(Pub/Sub)模式实现消息通信
Redis的发布/订阅模式可以用来实现消息通信,让多个客户端之间实现实时消息传递。通过使用发布/订阅模式,可以实现消息的广播和订阅功能。例如:
# 创建一个发布者对象,发布消息到channel1频道
publisher = redis.StrictRedis(host='localhost', port=6379, db=1)
publisher.publish('channel1', 'Hello World!')
# 创建一个订阅者对象,订阅channel1频道的消息并处理接收到的消息
subscriber = redis.StrictRedis(host='localhost', port=6379, db=2)
pubsub = subscriber.pubsub()
pubsub.subscribe('channel1')
for message in pubsub.listen():
if message['type'] == 'message':
print(message['data']) # Hello World!在上面的代码中,创建了一个发布者对象,它向channel1频道发布了一条消息。然后创建了一个订阅者对象,它订阅了channel1频道的消息,并循环监听接收到的消息。当接收到消息时,它会打印出消息的内容。
总结
Redis是一个功能强大的内存数据存储系统,提供了丰富的数据类型和操作命令,可以满足各种数据处理需求。
在使用过程中,需要根据具体的业务场景和需求来选择合适的Redis数据类型和操作命令,并进行合理的配置和优化。同时,还需要注意Redis的安全性和可靠性,采取相应的措施来保护数据的安全性和完整性。总之,Redis是一个强大的工具,可以帮助我们更好地处理和管理数据,提高系统的性能和可用性。