适用于什么场景?
检索比较多的场景,例如学生成绩管理系统,老师对学生的成绩进行排名或查询操作
ArrayList有哪些特点?
1、ArrayList集合底层采用了数组数据结构,是Object类型
2、动态数组。ArrayList的默认初始容量为10,扩容因子为1.5,数组长度随着容量的增长数组长度。但是数组的长度并不会随着ArrayList的容量立即缩小,除非显示的调用 trimToSize 方法
3、建议给定一个预估计的初始化容量,减少数组扩容的次数,这是ArrayList集合比较重要的优化策略.因为在在扩容的同时需要将原来数组中的数据复制到新数组里,但如果要插入大量数据时,赋值数组的形式效率很低,所以大多数情况下会使用带参构造函数,传入一个预估计容量,提前定义好容量。
4、ArrayList是非线程安全的
单独看这些特点我们还是回觉得有些枯燥,结合具体场景我们来分析分析
实战演练
import java.util.ArrayList;
import java.util.List;
public class ListTest {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("b");//第一个,索引下标0
list.add("d");
list.add("c");
list.add("a");
list.add("d"); //允许使用重复元素
System.out.println(list); //输出结果:[b, d, c, a, d]
System.out.println(list.get(2)); //输出指定下标的元素,输出结果:c
list.add(1,"f");//在指定索引下标位置添加元素
System.out.println(list); //输出结果:[b, f, d, c, a, d],原来下标为1和1之后的下标索引位置的元素自动向后移动
List<String> a = new ArrayList<String>();
a.add("123");
a.add("456");
list.addAll(2,a); //在指定索引下标的位置插入集合
System.out.println(list);//输出结果:[b, f, 123, 456, d, c, a, d]
//获取指定元素在集合中第一次出现的索引下标
System.out.println(list.indexOf("d")); //输出结果:4
//获取指定元素在集合中最后一次出现的索引下标
System.out.println(list.lastIndexOf("d"));//输出结果:7
list.remove(2); //根据指定的索引下标移除元素
System.out.println(list); //输出结果:[b, f, 456, d, c, a, d]
list.set(1,"ff"); //根据指定的索引下标修改元素
System.out.println(list); //输出结果:[b, ff, 456, d, c, a, d]
//根据索引下标的起始位置截取一段元素形成一个新的集合,截取的时候,包含开始的索引不包含结束时的索引
List<String> sublist= list.subList(2,4);
System.out.println(sublist);//输出结果:[456, d]
System.out.println(list.size());//输出结果7
}
}import java.util.LinkedList;
import java.util.List;
public class ListTest {
public static void main(String[] args){
List l1 = new LinkedList();
for(int i = 0;i<=5;i++){
l1.add("a"+i);
}
System.out.print(l1);
l1.add(3,"a100");
System.out.println(l1);
l1.set(6,"a200");
System.out.println(l1);
System.out.print((String)l1.get(2)+" ");
System.out.println(l1.indexOf("a3"));
l1.remove(1);
System.out.println(l1);
}
}输出结果:
[a0,a1,a2,a3,a4,a5]
[a0,a1,a2,a100,a3,a4,a5]
[a0,a1,a2,a100,a3,a4,a200]
a2 4
[a0,a2,a100,a3,a4,a200]
底层原理
有几个变量在之后增删改查方法中会反复使用,我们需要注意

注意:
- 数组长度是指当前数组内元素的个数
- 数组容量是指数组所能容纳的长度
①、序列化和反序列化问题
在方法签名上我们看到ArrayList类实现了Serializable接口,说明我们创建的ArrayList数组可以序列化(存储数据库、传输数据等)和反序列化,但是用于存储元素的数组elementData为什么还用transient关键字修饰呢?我们都知道用transient关键字修饰的变量可以不进行序列化和反序列化,那这样做是为什么呢?
大家设想一个场景:此时我的数组长度为15,但实际元素大小为11,是不是剩余4个空间没有用到?如果我们在序列化和反序列化的时候是不是就要多序列化和反序列化4个空间的内容,是不是浪费了无效的操作?所以秉持着高效第一的原则减少无效操作。在ArrayList的底层有两个方法readObject和writeObject用于序列化

此时我们会发现在遍历的范围是0到实际数组的大小,拿上面的场景来说就是0-10的范围,序列化数组中0-10的元素,这样没有用到的4个空间是不是就没有被序列化和反序列化。
②、添加元素——add()
思想:

创建一个Object类型的空数组(注意:当第一次add添加元素的时候,才指定默认容量为10)
ensureCapacityInternal方法先判断容量值是否大于当前ArrayList的容量,如果大于当前集合容量,则需要调用grow方法进行扩容;反之,不用操作


③、grow扩容——ArrayList扩容机制
ArrayList的使用前不需要像数组一样提前定义大小空间,容量是随着使用时自动增长的,那为什么在使用ArrayList的add方法添加元素的时候底层还需要判断集合的容量是否能够放下要添加的元素呢?又没有定义固定大小直接放进去不就好了吗?
add方法添加分为三步:
①、判断集合容量是否满足添加的元素
②、添加元素
③、集合长度+1
什么时候需要扩容?
如果当前容量+ 1超过数组长度

用户不需要提前定义大小,那是因为底层默认已经定义好了大小。其实是有一个边界值的,并不是无限增长的。使用时增加,是因为底层有扩展因子(扩容因子是1.5),当数量达到数组的百分之多少的时候就会扩容。ArrayList默认的初始大小是10,其实在一开始new完之后的数组容量并不是10,而且一个空的数组,当添加第一个元素的时候会进行第一次扩容,数组容量变为10
ArrayList扩容的时候会将原来的数组复制到一个新的数组中,为什么这么做?那原来的数组什么时候回收?
当 ArrayList 需要扩容时,会创建一个新的更大的数组,并将原来的数组中的元素复制到新数组中。这样做的原因是为了确保数组的连续性,以便能够快速地访问和修改元素。如果不进行数组复制,而是直接在原数组上进行扩容,可能会因为内存不连续而导致性能下降。
原来的数组会在扩容后变得多余,不再被使用。原来的数组会在没有任何引用指向它时变为不可达,即没有任何变量指向原数组时,原数组会成为垃圾对象。一旦原数组成为不可达的垃圾对象,垃圾回收器就会在适当的时候将其回收,释放其占用的内存空间。这个过程是由垃圾回收器自动管理的,程序员不需要显式地释放原数组。
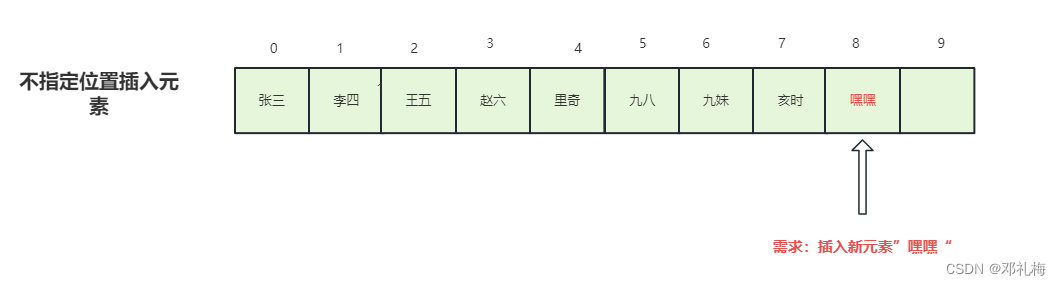
④、在指定位置插入新元素——add()


当我们在指定位置插入元素的时候,要插入下标的后面元素会整体向后移动一位,增加了系统额外的系统开销,如上面的图片例子来说:如果要插入位置越靠近数组前面,我们会发现数组的移动变得很大
⑤、更新元素——set()

⑥、删除元素——remove()
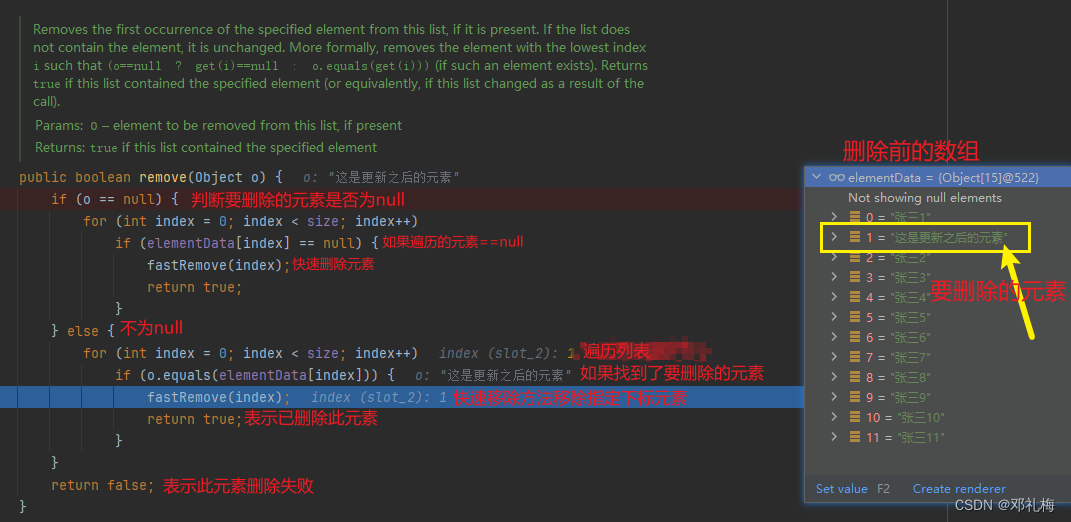
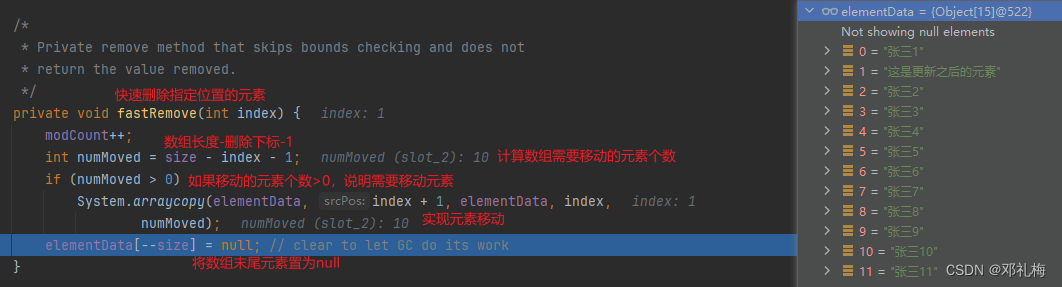
不管是删除指定位置元素和直接删除元素都涉及到了数组元素的移动,所以我们要删除的元素如果越靠近数组的前面,所消耗的性能越大
注意:不要遍历集合删除元素,会出现数据不一致问题,个别元素没有删除成功
⑦、查找元素——indexOf()

因为数组有一个特点是可以根据下标查找元素,如果按照指定下标查找元素,ArrayList的性能会很高,但是根据上图的源码我们不难发现:如果是根据元素查找下标,会从头到尾遍历整个数组,如果数组的位置特别靠近末尾,那整个查询会非常耗时
出现的问题:
线程安全问题:当多线程环境下同时对集合操作(添加、删除、修改元素),可能导致数据不一致问题(数组越界、数据丢失等)
解决方案:
- 使用CopyOnWriteArrayList线程安全集合
- 使⽤ Collections.synchronizedList 包装 ArrayList,然后操作包装后的 list
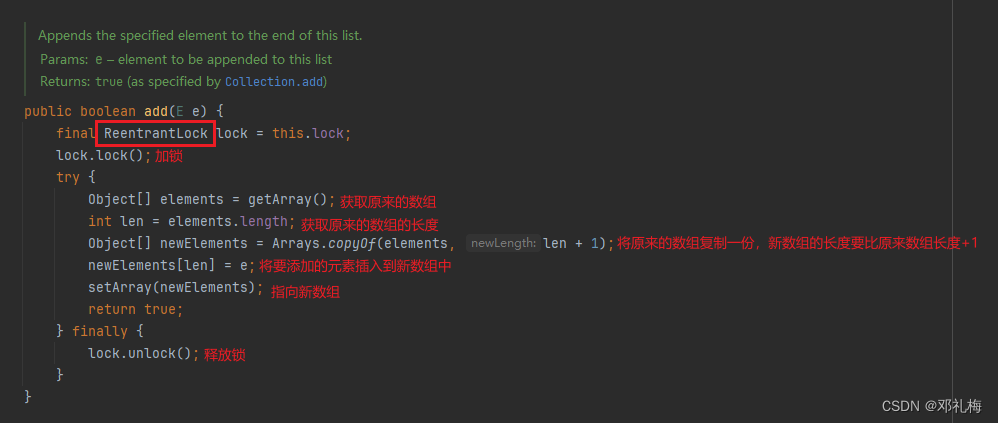
CopyOnWriteArrayList
CopyOnWrite — —写时复制
读操作是⽆锁的,性能较⾼;写操作的时候先将当前容器复制一份,然后在新数组上执行写操作,结束之后再将原容器的引用指向新容器
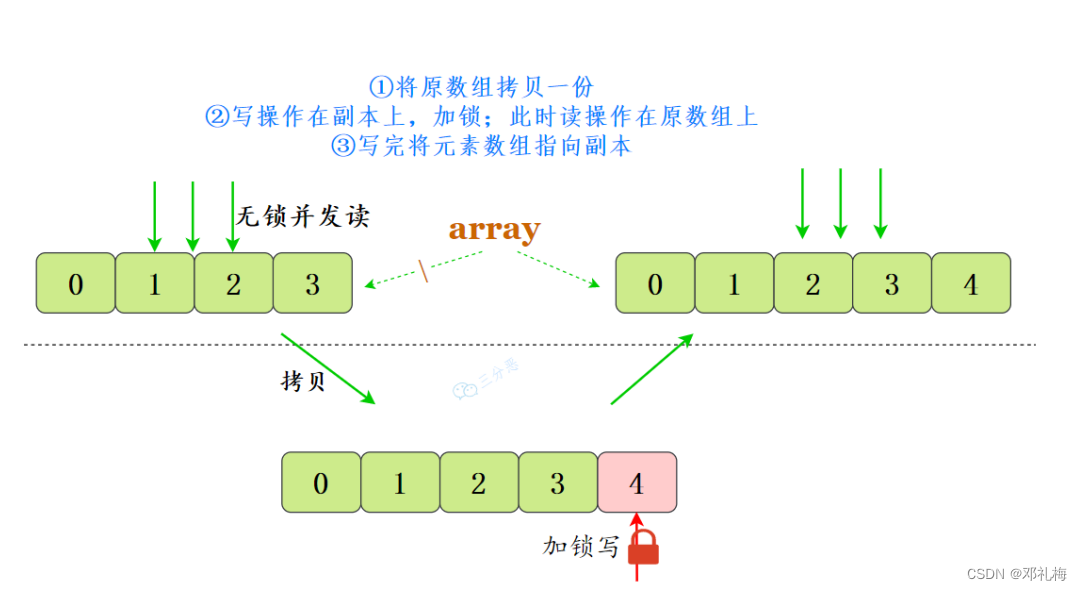
备:参考网上图片