慢查询⽇志:⽤于记录执⾏时间超过给定时⻓的命令请求,⽤户可以通过这个功能产⽣的⽇志来监视和 优化查询速度。
布隆过滤器:⼆进制数组进⾏存储,若判断元素存在则可能实际存在,若判断不存在则⼀定不存在。
redis中incr、incrby、decr、decrby属于string数据结构,它们是原⼦性递增或递减操作:
incr 递增1并返回递增后的结果;
incrby 根据指定值做递增或递减操作并返回递增或递减后的结果(incrby递增或递减取决于传⼊值的
正负);
decr 递减1并返回递减后的结果;
decrby 根据指定值做递增或递减操作并返回递增或递减后的结果(decrby递增或递减取决于传⼊值
的正负);
Redis为什么这么快?
完全基于内存,绝⼤部分请求是纯粹的内存操作,⾮常快速;
数据结构简单,对数据操作也简单;
采⽤单线程,避免了不必要的上下⽂切换和竞争条件,也不存在多进程或者多线程导致的切换⽽消
耗 CPU,不⽤考虑各种锁的问题,不存在加锁和释放锁操作。CPU不是Redis的瓶颈,Redis的瓶
颈最有可能是机器内存的⼤⼩或者⽹络带宽;
使⽤多路I/O复⽤模型,⾮阻塞IO;
6.1 基本数据结构(底层实现)
键:字符串对象
值:字符串对象、列表对象、哈希对象、集合对象、有序集合对象
SDS
Redis底层使⽤SDS(简单动态字符串)替代C字符串原因:
1.
常数复杂度获取字符串⻓度。因为有 len 属性记录字符串⻓度(不计算最后⼀个空字符)
2.
杜绝了缓冲区溢出的可能性。因为有 free 属性记录未⽤空间⻓度,并当空间不⾜时 SDS API ⾃动扩容。
3.
⼆进制安全,可存⼊⽂本或者⼆进制数据。所有 SDS API 都会以处理⼆进制的⽅式来处理 SDS 存放在 buf 数组⾥的元素,程序不会对其中的数据做任何限制、过滤或者假设,数据在写⼊时是什么样的,它被读取时就是什么样。因为 SDS 使⽤ len 属性的值⽽不是空字符来判断字符串是否结
束。
SDS 空间预分配:
1.
如果对 SDS 进⾏修改后,SDS 的⻓度(即 len 值)将⼩于 1MB,那么程序分配和 len 属性同样⼤⼩的未使⽤空间,这时 SDS len 属性的值将和 free 属性的值相同。举个例⼦,如果修改后 SDS 的 len 将变成 13 字节,那么程序也会分配 13 字节的未使⽤空间,SDS 的 buf 数组的实际⻓度将变成 13+13+1=27 字节
2.
如果对 SDS 进⾏修改后,SDS 的⻓度将⼤于等于 1MB,那么程序会分配 1MB 的未使⽤空间。举个例⼦,如果修改后,SDS 的 len 将变成 30MB,那么 SDS 的 buf 数组的实际⻓度将为
30MB+1MB+1byte.
惰性空间释放:
⽤于优化 SDS 字符缩短操作,当缩短 SDS 字符串时,并不⽴即使⽤内存重分配来回收缩后多出来的字节,⽽是使⽤ free 属性将这些字节的数量记录下来,并等待将来使⽤。
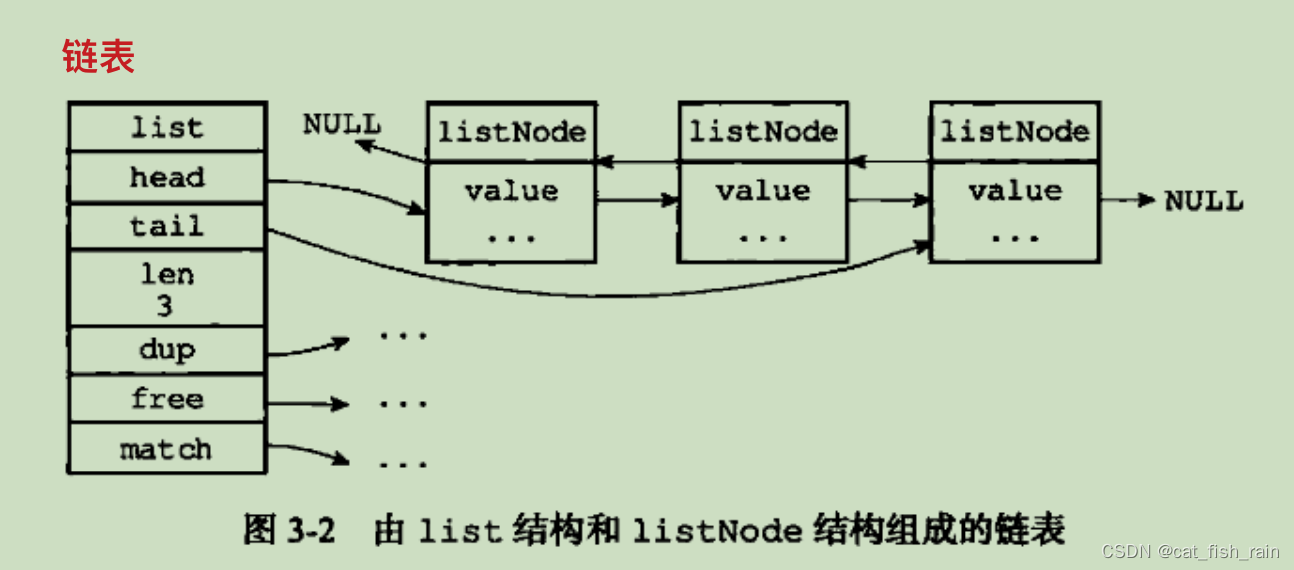
特性:
1.
双向⽆环,链表头尾均有⼀个指针指向空
2.
O(1) 时间复杂度获取表头指针、表尾指针和链表⻓度
3. 多态:链表节点使⽤ void* 指针来保持节点值,并且可以通过 list 结构的 dup(复制)、free(释放)、match(对⽐)三个属性为节点值设置类型特定函数,所以链表可以⽤于保存各种不同类型的值
字典
Redis 的字典使⽤ 哈希表 作为底层实现,⼀个哈希表⾥⾯可以有多个哈希表节点,⽽每个节点就保存了字典中的⼀个键值对。
哈希表结构


type 属性和 privdata 属性是针对不同类型的键值对,为创建多态字典⽽设置的。type 属性是⼀个指
向 dictType 结构的指针,每个 dictType 结构保存了⼀簇⽤于操作特定类型键值对的函数,Redis 会为
⽤途不同的字典设置不同的类型特定函数。privdata 属性则保存了需要传给那些类型特定函数的可选参
数。
ht 属性是⼀个包含两个项的数组,数组中的每个项都是⼀个 dictht 哈希表,⼀般情况下,字典只使⽤ht[0] 哈希表,ht[1] 哈希表只会在对 ht[0] 哈希表进⾏ rehash 时使⽤。另⼀个与 rehash 有关的属性就是 rehashidx,它记录了 rehash ⽬前的进度,如果⽬前没有在进⾏ rehash,那么它的值为 -1。
计算索引:利⽤哈希算法计算哈希值,然后将哈希值与哈希⼤⼩掩码取与运算,得到索引下标。
解决冲突:链地址法,且每次添加到链表表头。
rehash ⽅式:为字典的 ht[1] 哈希表分配空间,这个哈希表的空间⼤⼩取决于要执⾏的操作和 ht[0] 当前包含的键值对数量。当执⾏扩展操作时,ht[1] 的⼤⼩为第⼀个⼤于等于 ht[0].used * 2 的 2^n;当执⾏收缩操作时,ht[1] 的⼤⼩为第⼀个⼤于等于 ht[0].used 的 2^n。之后将 ht[0] 上的所有键值对rehash 到 ht[1] 上。最后释放 ht[0],将 ht[1] 设置为 ht[0],并在 ht[1] 新创建⼀个空⽩哈希表,为下⼀次rehash 做准备。注意 rehash 操作是 渐进式的,即在执⾏增加、删除、查找或更新操作的时候同步进⾏ rehash 操作(trehashidx 记录索引),直到所有 rehash 完成,则置 -1。同时新增加的会加⼊到 ht[1],且外部查找时先查 ht[0],再查 ht[1]。
负载因⼦ = 哈希表已有节点数量 / 哈希表⼤⼩
扩展操作需满⾜:当没有创建当前服务的⼦进程时,负载因⼦⼤于等于 1;当创建当前服务的⼦进程时,负载因⼦⼤于等于 5。因为⼤多数操作系统都采⽤写时复制技术来优化⼦进程的使⽤效率,所以在
⼦进程存在期间,服务器会提⾼执⾏扩展操作所需的负载因⼦,从⽽尽可能避免在⼦进程存在期间进⾏
哈希表扩展操作,可以避免不必要的内存写⼊操作,最⼤限度地节约内存。
收缩操作需满⾜:负载因⼦⼩于 0.1。
跳跃表
跳跃表是⼀种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从⽽达到快速访问节点的⽬的。在⼤部分情况下,跳跃表的效率可以和平衡树相媲美,并且跳跃表的实现⽐平衡树更简单。跳跃表是作为有序集合键的底层实现之⼀。

其中每个节点层⾼(最⼤层⾼ level)是 1——32 随机⽣成的,length 是除表头外节点的数量。每个节点有层属性(前进指针和跨度)、后退指针、分值(⽤来排序)和成员对象(唯⼀存在)四部分,其中表头节点不使⽤后⾯三部分但是有。
整数集合
集合中不包含任何重复的元素,且数组中的元素按升序排列。数组中元素的真实类型由 encoding 决定。当有更⼤⻓度的元素时将发⽣(类型)升级,整数集合不⽀持降级。

压缩列表
当⼀个哈希键只包含少量键值对,并且每个键值对的键和值要么是⼩整数值,要么是⻓度⽐较短的字符串时,Redis 就会⽤压缩列表来做哈希键的底层实现。
压缩列表是 Redis 为了节约内存 ⽽开发的,是由 连续内存块 组成的顺序型数据结构。⼀个压缩列表可以包含任意多个节点,每个节点保存⼀个字节数组或者⼀个整数值。
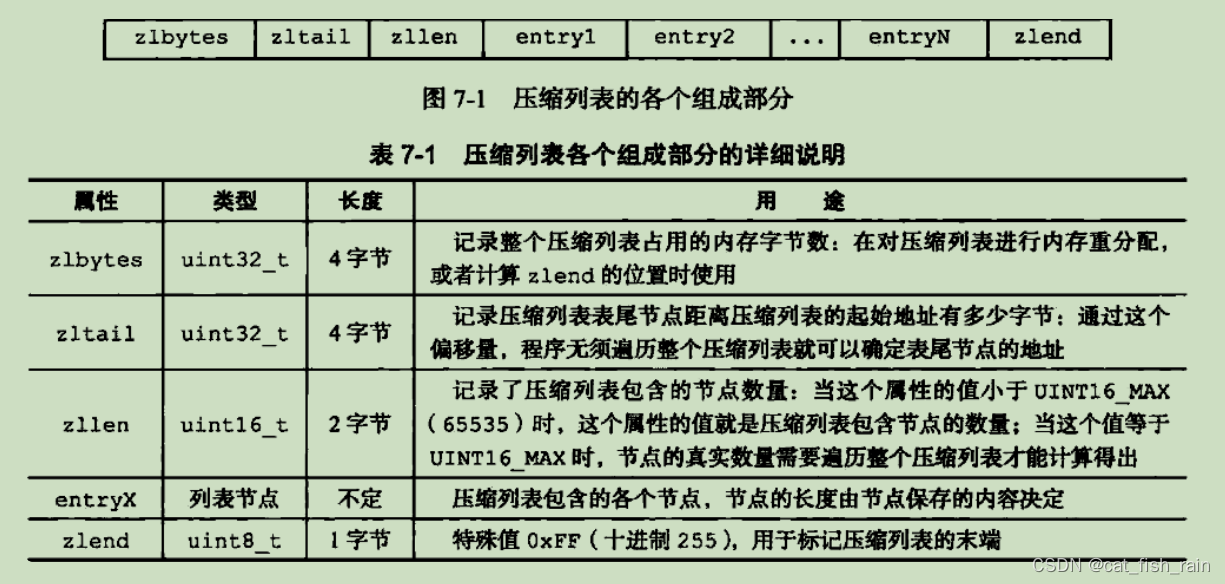
压缩列表节点 的第⼀部分是上⼀个节点的⻓度(⽤于由当前位置计算得到上⼀个节点的位置),第⼆部分是当前节点的类型和⻓度,第三部分是当前节点的内容。由于第⼀部分会根据上个节点的⻓度动态确定存储位数⼤⼩,因此当插⼊或删除节点时可能(只有当连续多个⼤字节节点存在时)会出现连锁更新,但是其⼏率较低。

6.2 对象
共五类,包含字符串对象、列表对象、哈希对象、集合对象和有序集合对象。
实现了引⽤计数、对象共享(通过引⽤计数实现)、最后访问时间记录(当内存占⽤超过阈值将⾃动回收空转时间⻓的对象)等信息。
字符串对象

其中 raw 即为 SDS,⽽ embstr 是 SDS 的改版(核⼼结构⼀样),仅需⼀次内存分配(SDS 需要两次:创建 RedisObject 和 SDS 对象),且创建的对象是在连续内存内,更好利⽤缓存。
列表对象
列表对象的编码可以是 ziplist 或者 linkedlist。
当列表对象可以同时满⾜以下两个条件时,列表对象使⽤ ziplist 编码:
1.
列表对象保存的所有字符串元素的⻓度都⼩于 64 字节
2.
列表对象保存的元素数量⼩于 512 个
不能满⾜这两个条件的列表对象需要使⽤ linkedlist 编码
哈希对象
哈希对象的编码可以是 ziplist 或者 hashtable。
ziplist 编码的哈希对象使⽤压缩列表作为底层实现,当有新键值对要加⼊时,依次放⼊键和值。
hashtable 编码的哈希对象使⽤字典作为底层实现,哈希对象中的每个键值对都是⽤⼀个字典键值对来保存。
对于使⽤何种编码,与列表对象的两条规则类似。
集合对象 set
集合对象的编码可以是 intset 或者 hashtable(值设置为NULL)。
当集合对象中的所有元素都是整数且数量不超过 512 时,使⽤ intset 编码实现。
有序集合对象 zset
有序集合的编码可以是 ziplist 或者 skiplist。
ziplist 内的集合元素按分值从⼩到⼤进⾏排序。
skiplist 编码的有序集合对象使⽤ zset 结构作为底层实现,⼀个 zet 结构同时包含⼀个字典和⼀个跳跃表。zset 结构中的跳跃表按分值从⼩到⼤保存了所有集合元素,每个跳跃表节点都保存了⼀个集合元素,通过跳跃表,程序可以对有序集合进⾏ 范围型操作。此外,zset 结构中的 dict 字典为有序集合创建了⼀个从成员到分值的映射,字典中的每个键值对都保存了⼀个集合元素:字典的键保存了元素的成员,⽽字典的值则保存了元素的分值。
有序集合每个元素的成员都是⼀个字符串对象,⽽每个元素的分值都是⼀个 double 类型的浮点数。虽然 zset 结构同时使⽤了跳跃表和字典来保存有序集合元素,但这两种数据结构都会 通过指针来共享 相同元素的成员和分值,因此不会浪费额外的内存。
当有序集合对象同时满⾜以下两个条件时,对象使⽤ ziplist 编码:
1.
有序集合保存的元素数量⼩于 128 个;
2.
有序集合保存的所有元素成员的⻓度都⼩于 64 字节;
不满⾜任意⼀个条件,有序集合对象将使⽤ skiplist 编码。
6.3 数据库
服务器默认创建 16 个数据库,客户端默认连接第⼀个数据库(0 号数据库)。
SELECT 命令切换数据库原理:修改 redisClient.db 指针,指向⽬标数据库。
每个数据库对象中包含 字典属性(所有键值对) 和 过期字典属性(设置过期时间的键值对) 等。
过期键删除策略:
1.
惰性删除:所有读写数据库的命令前都将进⾏过期键检测,若过期则删除否则继续执⾏;
2.
定期删除:在规定时间内,分多次遍历服务器中的各个服务器,并从过期字段属性中随机检查指定。
数量的键是否过期,并删除过期键。
RDB 持久化
Redis 是内存数据库,数据库状态存储在内存⾥,可通过 RDB 持久化将数据库状态保存到 RDB ⽂件 (⼆进制⽂件,保存键值对)中。 SAVE、BGSAVE 都是保存 RDB ⽂件的命令,后者 fork ⼦线程达到可边保存边执⾏其他命令的不阻塞处理。RDB ⽂件载⼊是在服务器启动时⾃动执⾏的,没有相关命令。因为 AOF ⽂件的更新频率通常⽐RDB ⽂件的更新频率⾼,所以如果服务器开启了 AOF 持久化功能,那么服务器会优先使⽤ AOF ⽂件 来还原数据库状态。只有在 AOF 持久化功能处于关闭状态时,服务器才会使⽤ RDB ⽂件来还原数据库状态。
间隔性数据保存实现原理:利⽤ BGSAVE 命令,通过设置每隔多少时间⾄少保存多少次,会⾃动
(100ms)检查是否满⾜保存条件并进⾏保存操作。(记录了已保存次数以及上次保存的时间戳)
RDB ⽂件结构:
1.
标明这是⼀个 RDB ⽂件
2.
数据库版本号
3.
数据库键值对内容(若为空数据库则⽆该字段),可以保存任意多个⾮空数据库
4.
数据库状态结束符
5.
校验和字段

其中 每个⾮空数据库 在 RDB ⽂件中都可以保存为如下三个部分:

1.
⻓度 1 字节,当读⼊程序遇到这个值的时候,它知道接下来将读⼊的是⼀个数据库号码
2.
保存数据库号码,⻓度不定。当程序读⼊ db_number 部分之后,服务器会调⽤ SELECT 命令,根据读⼊的数据库号码进⾏数据库切换,使得之后读⼊的键值对可以载⼊到正确的数据库中
3.
保存数据库中所有键值对数据,如果键值对带有过期时间,那么过期时间也会和键值对保存在⼀
起。
AOF 持久化
与 RDB 持久化通过保存数据库中的键值对来记录数据库状态不同,AOF 持久化是通过保存 Redis 服务器所执⾏的写命令来记录数据库状态的。
AOF 持久化功能的实现可以分为:
1.
命令追加:服务器在执⾏完⼀个写命令之后,会把写命令追加到服务器状态的 AOF 缓存区的末尾
2.
⽂件写⼊与同步,默认值为下图的 everysec

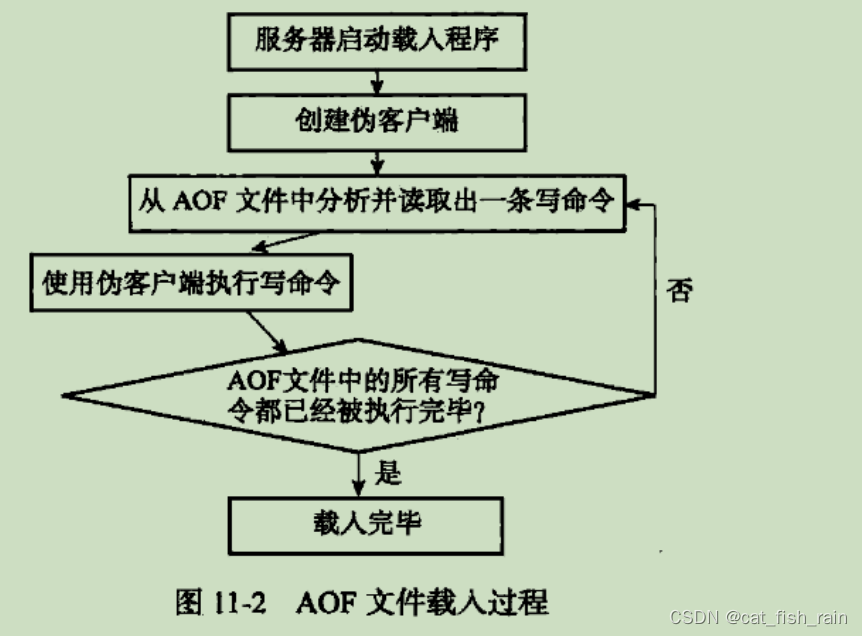
AOF ⽂件载⼊:(使⽤伪客户端是因为写命令只能通过客户端向服务端发送)
AOF ⽂件重写:
实际并不需要对现有的 AOF ⽂件进⾏任何读取、分析或者写⼊操作,这个功能是通过读取服务器当前的数据库状态来实现的。为了防⽌在重写的过程中数据库状态发⽣改变从⽽数据不⼀致,服务器需要执⾏以下三个⼯作:
●
执⾏客户端发来的命令;
●
将执⾏后的写命令追加到 AOF 缓冲区;
●
将执⾏后的写命令追加到 AOF 重写缓冲区。
RDB与AOF区别
●
RDB可以理解为是⼀种全量数据更新机制,AOF可以理解为是⼀种增量的更新机制,AOF重写可以理解为是⼀种全量+增量的更新机制(第⼀次是全量,后⾯都是增量)
●
RDB适合服务器数据库数据量⼩,写命令频繁的场景
●
AOF适合数据量⼤,写命令少的场景
●
AOF重写适合在AOF运⾏了很久的写命令之后执⾏。
数据淘汰策略
Redis 内存数据集⼤⼩上升到⼀定⼤⼩的时候,就会进⾏数据淘汰策略。
●
volatile-lru:从已设置过期时间的数据集中挑选最近最少使⽤的数据淘汰。
●
volatile-ttl:从已设置过期时间的数据集中挑选将要过期的数据淘汰。
●
volatile-random:从已设置过期时间的数据集中任意选择数据淘汰。
●
volatile-lfu 从设置过期时间的数据集(server.db[i].expires)中挑选出使⽤频率最⼩的数据淘汰。
没有设置过期时间的key不会被淘汰,这样就可以在增加内存空间的同时保证需要持久化的数据不
会丢失
●
no-enviction:当内存达到限制的时候,不淘汰任何数据,不可写⼊任何数据集,所有引起申请内存的命令会报错。
●
allkeys-lru:从数据集中挑选最近最少使⽤的数据淘汰。
●
allkeys-random:当内存达到限制的时候,从数据集中任意选择数据淘汰。
●
allkeys-lfu 从数据集(server.db[i].dict)中挑选使⽤频率最⼩的数据淘汰,该策略要淘汰的key⾯
向的是全体key集合,⽽⾮过期的key集合。