目录
视图
基本语法
视图的更新
视图的作用
存储过程
介绍
存储过程基本语法
存储过程的变量
系统变量
用户自定义变量
局部变量
存储过程的判断逻辑
存储过程的参数
存储过程中的流程控制
存储过程中的循环
while的基本语法
repeat的基本语法
loop的基本语法
游标
条件处理程序
存储函数
触发器
总结
视图
视图(View)是一种虚拟存在的表。视图中的数据并不在数据库中实际存在,行和列数据来自定义视图的查询中使用的表,并且是在使用视图时动态生成的。
通俗的进,视图只保存了查询的SQL逻辑,不保存查询结果。所以我们在创建视图的时候,主要的工作就落在创建这条SQL查询语句上。
基本语法
创建视图语法
CREATE [OR REPLACE] VIEW 视图名称[(列名列表)] AS SELECT语句 [WITH[CASCADED | LOCAL] CHECK OPTION]查询视图语句
# 查看视图创建语句
SHOW CREATE VIEW 视图名称;
# 查看视图数据
SELECT * FROM 视图名称 ……;修改视图语句
# 方式一:
CREATE [OR REPLACE] VEW [视图名称(列名列表)] AS SELECT语句 [WITH[CASCADED | LOCAL] CHECK OPTION]
# 方式二:
ALTER VIEW 视图名称[(列名列表)] AS SELECT语句 [WITH[CASCADED | LOCAL] CHECK OPTION]删除视图语句
DROP VIEW [IF EXISTS] 视图名称; 我们可以操作视图表想操作基本表一样,如果对视图表执行insert或是update语句,实际上都是对基本表进行操作。
当使用WITH CHECK OPTION子句创建视图时,MySQL会通过视图检查正在更改的每个行,例如插入,更新,删除,以使其符合视图的定义。MySQL允许基于另一个视图创建视图,它还会检查依赖视图中的规则以保持一致性。为了确定检查的范围,mysql提供了两个选项:CASCADED 和 LOCAL,默认值为 CASCADED
CASCADED:级联
如果指定了WITH配置项,那么在执行插入,更新,删除时,会进行自身以及依赖的视图表的条件判断,如果满足才会执行成功,不满足执行失败。
LOCAL:本地
如果指定了WITH配置项,那么在执行插入,更新,删除时,只会进行自身以及依赖的视图表中同样添加了WITH配置项的条件判断,如果满足才会执行成功,不满足执行失败。
视图的更新
要使视图可更新,视图中的行与基础表中的行之间必须存在一对一的关系。如果视图包含以下任何一项,则该视图不可更新:
聚合函数或窗口函数(SUM()、 MIN()、MAX()、COUNT()等)
- DISTINCT
- GROUP BY
- HAVING
- UNION 或者 UNION ALL
视图的作用
- 简单
视图不仅可以简化用户对数据的理解,也可以简化他们的操作。那些被经常使用的查询可以被定义为视图,从而使得用户不必为以后的操作每次指定全部的条件。
- 安全
数据库可以授权,但不能授权到数据库特定行和特定的列上。通过视图用户只能查询和修改他们所能见到的数据。
- 数据独立
视图可以帮助用户屏蔽真实表结构变化带来的影响。
存储过程
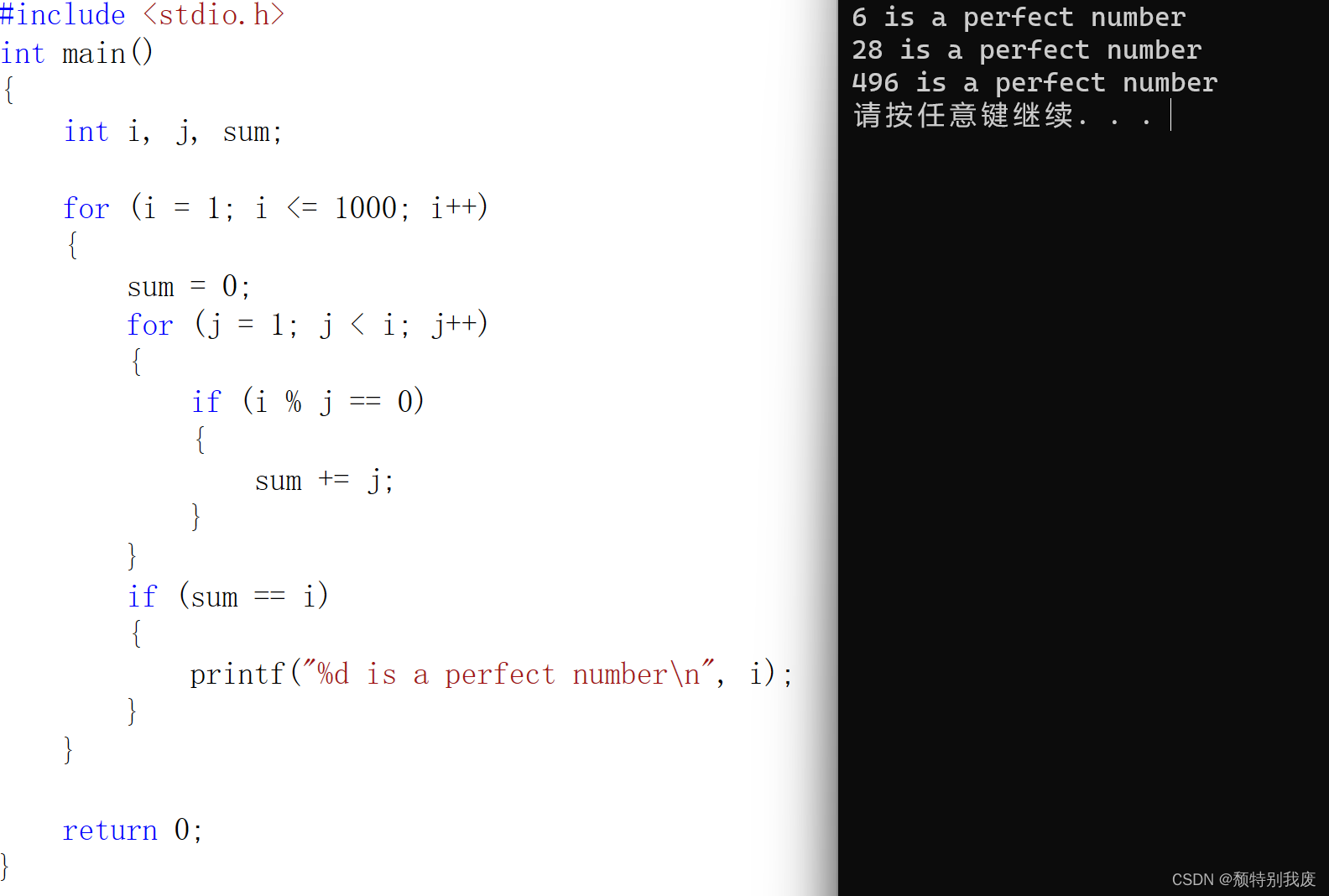
现在存在一个业务,需要查询数据库后,需要对多条数据进行修改。这就意味着,客户端需要发起多次网络请求。而我们可以通过对SQL语句的封装,实现一次请求就实现业务需求。

介绍
存储过程是事先经过编译并存储在数据库中的一段 SQL 语句的集合,调用存储过程可以简化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效率是有好处的。
存储过程思想上很简单,就是数据库SQL语言层面的代码封装与重用。
特点如下:
- 封装,复用。
- 可以接受参数,也可以返回数据。
- 减少网络交互,效率提升。
存储过程基本语法
创建存储过程
CREATE PROCEDURE 存储过程名称([参数列表])
BEGIN
--SQL语句
END;调用存储过程
CALL 名称([参数]);查看存储过程
--查询指定数据库的存储过程及状态信息
SELECT * FROM INFORMATION_SCHEMA.ROUTINES WHERE ROUTINE_SCHEMA = '数据库名';
-- 查询某个存储过程的定义
SHOW CREATE PROCEDURE 存储过程名称;删除存储过程
DROP PROCEDURE [IF EXISTS] 存储过程名;需要配注意的是,如果使用命令行创建存储过程,那么在输入SQL语句后添加分号后会认为语句已经输出完毕,不会再记录END;命令。因此我们需要修改MySQL的结束符
delimiter 指定结束符号存储过程的变量
系统变量
系统变量是MySQL服务器提供,不是用户定义的,属于服务器层面。分为全局变量 (GLOBAL)、会话变量(SESSION)
全局变量的生效范围,两个查询控制台都可以访问到。
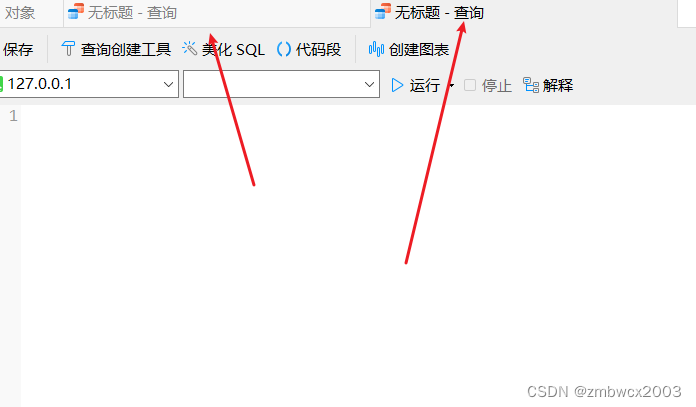
会话变量的生效范围,只能在当前控制台进行访问。
查看系统变量
-- 查看所有系统变量
SHOW [SESSION | GLOBAL] VARIABLES;
-- 可以通过LIKE模糊匹配方式查找变量
SHOW [SESSION | GLOBAL] VARIABLES LIKE '......';
-- 查看指定变量的值
SELECT @@[SESSION | GLOBAL] 系统变量名;设置系统变量
SET [SESSION | GLOBAL] 系统变量名 = 值;
SET @@[SESSION | GLOBAL] 系统变量名 = 值;注意:
- 如果没有指定SESSION | GLOBAL,默认是SESSION会话变量。
- mysql服务重新启动之后,所设置的全局参数会失效要想不失效,可以在 /etc/my.cnf 中配置
用户自定义变量
用户定义变量 是用户根据需要自己定义的变量,用户变量不用提前声明,在用的时候直接用“@变量名”使用就可以。其作用域为当前连接。
赋值语句
# 推荐使用:= 因为可以与比较符号区分开
SET @var_name = expr [,@var_name = expr];
SET @var_name := expr [, @var name := expr];
SELECT @var_name := expr [, @var name := expr];
SELECT 字段名 INTO @var_name FROM 表名; -- 将表中查找的值赋值给该变量使用语句
SELECT @var_name;局部变量
局部变量是根据需要定义的在局部生效的变量,访问之前,需要DECLARE声明。可用作存储过程内的局部变量和输入参数,局部变量的范围是在其内声明的BEGIN... END块。
声明语法
DECLARE 变量名 变量类型[DEFAULT ...];变量类型就是数据库字段类型:INT、BIGINT、CHAR、VARCHAR、DATE、TIME等。
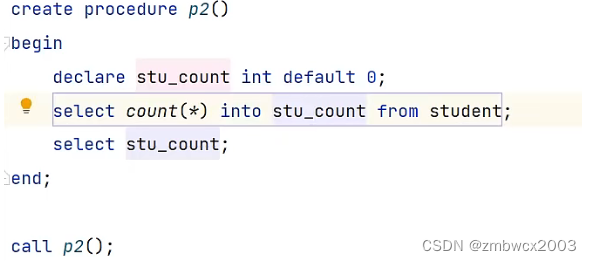
存储过程的判断逻辑
if判断基本语法
IF 条件1 THEN
……
ELSEIF 条件2 THEN
……
ELSE
……
END IF;存储过程的参数
| 类型 | 含义 |
| IN(默认) | 该类参数作为输入,也就是需要调用时传入值 |
| OUT | 该类参数作为输出,也就是该参数可以作为返回值 |
| INOUT | 既可以作为参数,也可以作为输出参数 |
使用语法
CREATE PROCEDURE 存储过程名称([IN/OUT/INOUT 参数名 参数类型])
BEGIN
--SQL语句
END;
传入参数为score,返回参数为result

调用参数,并使用自定义变量接收,查询返回结果。
存储过程中的流程控制
case的基本语法
-- 语法一
CASE case_value
WHEN when_value1 THEN statement_list1
[WHEN when_value2 THEN statement_list2] …
[ELSE statement_list]
END CASE;
-- 语法二
CASE
WHEN search_condition1 THEN statement_list1
[WHEN search_condition2 THEN statement_list2]…
[ELSE statement_list]
END CASE;存储过程中的循环
while的基本语法
WHILE 条件 DO
SQL逻辑
EDN WHILE;repeat的基本语法
-- 与WHILE的区别在于,满足条件退出循环,相当于do……while
REPEAT
SQL逻辑…
UNTIL 条件
END REPEAT;loop的基本语法
LOOP实现简单的循环:如果不在SQL逻辑中增加退出循环的条件,可以用其来实现简单的死循环。LOOP可以配合一下两个语句使用
- LEAVE:配合循环使用,退出循环。
- ITERATE:必须用在循环中,作用是跳过当前循环剩下的语句,直接进入下一次循环
[begin_label:]LOOP
SQL逻辑…
END LOOP[end_label];
-- label相当于给循环起名字
游标
游标(CURSOR)是用来存储查询结果集的数据类型,在存储过程和函数中可以使用游标对结果集进行循环的处理。游标的使用包括游标的声明、OPEN、FETCH 和CLOSE,其语法分别如下
-- 声明游标
DECLARE 游标名称 CURSOR FOR 查询语句;
-- 打开游标
OPEN 游标名称;
-- 获取游标记录
FETCH 游标名称 INTO 变量[,变量];
-- 关闭游标
CLOSE 游标名称;案例
从emp表中,获取sal>=2000的数据集。
创建一个新表,并将获取到的数据集存放到新表中
create procedure p(in usvl double)
begin
-- 声明变量,必须在游标之前声明
declare e_ename varchar(10);
declare e_sal double;
-- 声明游标
declare e_cursor cursor for select ename,sal from emp where sal >=2000;
open e_cursor;
-- 创建新表
drop table if exists tb_emp;
create table tb_emp(
id int primary key auto_increment,
name varchar(10),
sal double
);
while true do
-- 将游标中值赋值给变量
fetch e_cursor into e_ename,e_sal;
insert into tb_emp values(null,e_ename,e_sal);
end while;
close e_cursor;
end;
call p(2000);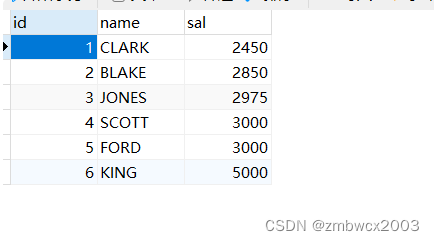
可以正常存放,但存在一个问题就是,上述的代码中,while是死循环,我们没有给其结束循环的逻辑。该问题我们在下面讲解handler后解决。
条件处理程序
条件处理程序(Handler)可以用来定义在流程控制结构执行过程中遇到问题时相应的处理步骤。
具体语法为
DECLARE handler_action HANDLER FOR condition_value [, condition_value] ... statement ;handler_action
- CONTINUE:继续执行当前程序
- EXIT:终止执行当前程序
condition_value
- SQLSTATE sglstate_value:状态码,如 02000
- SQLWARNING:所有以01开头的SQLSTATE代码的简写
- NOT FOUND:所有以02开头的SQLSTATE代码的简写
- SQLEXCEPTION:所有没有被SQLWARNING 或 NOT FOUND捕获的SQLSTATE代码的简写
根据handler我们可以解决上面游标的while死循环的问题
create procedure p(in usvl double)
begin
-- 声明变量,必须在游标之前声明
declare e_ename varchar(10);
declare e_sal double;
-- 声明游标
declare e_cursor cursor for select ename,sal from emp where sal >=2000;
-- 创建handler
declare exit handler for sqlstate '02000' close e_cursor;
open e_cursor;
-- 创建新表
drop table if exists tb_emp;
create table tb_emp(
id int primary key auto_increment,
name varchar(10),
sal double
);
while true do
-- 将游标中值赋值给变量
fetch e_cursor into e_ename,e_sal;
insert into tb_emp values(null,e_ename,e_sal);
end while;
close e_cursor;
end;
call p(2000);存储函数
存储函数是有返回值的存储过程,存储函数的参数只能是IN类型的。具体语法如下:
CREATE FUNCTION 存储函数名称([参数列表])
RETURNS type [characteristic...]
BEGIN
-- SQL语句
RETURN ...;
END ;characteristic说明
- DETERMINISTIC:相同的输入参数总是产生相同的结果
- NO SQL:不包含 SQL 语句。
- READS SQL DATA:包含读取数据的语句,但不包含写入数据的语句
通常我们使用存储过程,而不使用存储函数。因为使用不方便。因此不多叙述
触发器
触发器是与表有关的数据库对象,指在 insert/update/delete 之前或之后,触发并执行触发器中定义的SQL语句集合。触发器的这种特性可以协助应用在数据库端确保数据的完整性,日志记录,数据校验等操作。
使用别名 OLD 和NEW 来引用发器中发生变化的记录内容,这与其他的数据库是相似的。现在触发器还只支持行级触发,不支持语句级触发。
- 行级触发:一条update语句修改了五条数据,那么触发器触发五次
- 语句触发:相同的update语句只触发一次。
| 触发器类型 | NEW和OLD |
| INSERT型触发器 | NEW表示将要或是已经新增的数据 |
| UPDATE型触发器 | OLD表示修改之前的数据,NEW表示将要或是已经修改的数据 |
| DELETE型触发器 | OLD表示将要或是已经删除的数据 |
基本语法
创建触发器
CREATE TRIGGER trigger_name
BEFORE/AFTER INSERT/UPDATE/DELETE
ON tbl_name FOR EACH ROW -- 行级触发器
BEGIN
trigger_stmt ;
END;查看触发器
SHOW TRIGGERS;删除触发器
DROP TRIGGER [schema_name.]trigger_name; -- 如果没有指定 schema_name,默认为当前数据库。接下来测试日志记录
-- 创建日志表
create table user_logs(
id int(11) not null auto_increment,
operation varchar(20) not null comment '操作类型, insert/update/delete',
operate_time datetime not null comment '操作时间',
operate_id int(11) not null comment '操作的ID',
operate_params varchar(500) comment '操作参数',
primary key(`id`)
)engine=innodb default charset=utf8;
-- 创建更新触发器测试
CREATE TRIGGER emp_update_trigger
AFTER UPDATE ON `emp` FOR EACH ROW
BEGIN
INSERT INTO user_logs(id,operation,operate_time,operate_id,operate_params) VALUES
(NULL,'update',NOW(),old.empno,CONCAT('更新前的数据:id=',old.EMPNO,',ename=',old.ename,
'||更新后的数据:id=',new.EMPNO,',ename=',new.ename));
END;
-- 更新表
UPDATE emp SET ENAME = '张三' WHERE ename = 'SMITH';
日志表中成功插入信息。
总结
视图
- 虚拟存在的表,不保存查询结果,只保存查询的SQL逻辑
- 简单、安全、数据独立
存储过程
- 事先定义并存储在数据库中的一段SQL语句的集合
- 减少网络交互,提高性能、封装重用
- 变量、if、case、参数(in/out/inout)、while、repeat、loop、cursor、handler
存储函数
- 存储函数是有返回值的存储过程,参数类型只能为IN类型
- 存储函数可以被存储过程替代
触发器
- 可以在表数据进行INSERT、UPDATE、DELETE之前或之后触发
- 保证数据完整性、日志记录、数据校验