需要完成的目标
- 使用 Trie 树实现动态路由(dynamic route)解析。
- 支持两种模式
:name和*filepath,(开头带有':'或者'*')
这里前缀树的实现修复了Go语言动手写Web框架 - Gee第三天 前缀树路由Router | 极客兔兔 中路由冲突的bug。
Trie树简介
之前,我们用了一个非常简单的map结构存储了路由表,使用map存储键值对,索引非常高效,但是有一个弊端,键值对的存储的方式,只能用来索引静态路由。
如果我们想支持类似于/hello/:name这样的动态路由怎么办呢?所谓动态路由,即一条路由规则可以匹配某一类型而非某一条固定的路由。例如/hello/:name,可以匹配/hello/abc、hello/jack等。
实现动态路由最常用的数据结构,被称为前缀树(Trie树)。看到名字你大概也能知道前缀树长啥样了:每一个节点的所有的子节点都拥有相同的前缀。这种结构非常适用于路由匹配。
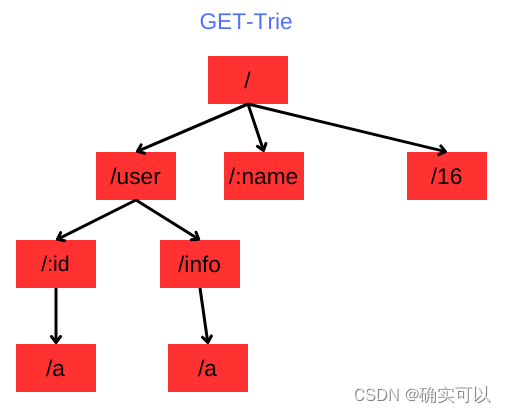
所有路由按照请求 method 分成对应的 method 树,然后将请求根据 `/` 拆封后,组装成树形结构。
接下来我们实现的动态路由具备以下两个功能。
- 参数匹配
:。例如/p/:lang/doc,可以匹配/p/c/doc和/p/go/doc。 - 通配
*。例如/static/*filepath,可以匹配/static/fav.ico,也可以匹配/static/js/jQuery.js,这种模式常用于静态服务器,能够递归地匹配子路径。
Trie树实现
力扣上有前缀树的题目实现 Trie (前缀树),若不懂前缀树的,可以前去查看了解。
首先是需要设置树节点上要存储的信息
节点结构
type node struct {
path string //路由路径 例如 /aa.com/home
part string //路由中由'/'分隔的部分
children []*node //子节点
isWild bool //是否是通配符节点,是为true
}与普通树的不同,为了实现动态路由匹配,加上了isWild这个参数。即是当我们匹配 /a/b/c/这个路径时。假如当前有个节点的path是 /a/:name,这时候a精准匹配到了a,b模糊匹配到了:name,那么会将name这个参数赋值为b,继续下一层的匹配。
那么前缀树的操作基本是插入和查找
那么讲解前需要了解下这一节的路由router结构
type router struct {
handers map[string]HandlerFunc
root map[string]*node //key是GET,POST等请求方法
}插入
那就要和router.go文件中的插入操作一起来讲解。
该插入的实现与极客兔兔的教程会有所不同。
举个例子:要插入GET方法的/user/info/a。要结合开头的前缀树那图片来想象。
1.先判断该路由中是否有GET方法的树,若是没有就需要创建该树,即是创建一个头结点。
2.接着调用parsePath函数,这个函数就是把/user/info/a组成一个切片,切片有三个元素
[]string{"user","info","a"}之后就调用节点的插入方法insert。
一层一层往下插入数据。
parts中第一个是user,当前的children[part]是空,所以需要新建一个结点。之后就cur = cur.children[part],这样就可以一层一层往下走。
到最后就是把path赋值给当前结点的路径。
//在router.go文件中
func (r *router) addRoute(method string, path string, handler HandlerFunc) {
// r.handers[key] = handler
if _, ok := r.root[method]; !ok {
r.root[method] = &node{}
}
parts := parsePath(path)
r.root[method].insert(path, parts)
key := method + "-" + path
r.handers[key] = handler
}
//在trie.go文件中
func (n *node) insert(path string, parts []string) {
tmpNode := n
for _, part := range parts {
var tmp *node
for _, child := range tmpNode.children { //一个for循环就是一层,一层一层查找
if child.part == part {
tmp = child
break
}
}
//表示没有找到该节点,需要创建新节点
if tmp == nil {
tmp = &node{
part: part,
isWild: part[0] == ':' || part[0] == '*',
}
tmpNode.children = append(tmpNode.children, tmp)
}
tmpNode = tmp
}
tmpNode.path = path
}
//在router.go文件中
func parsePath(path string) (parts []string) {
par := strings.Split(path, "/")
for _, p := range par {
if p != "" {
parts = append(parts, p)
//如果p是以通配符*开头的
if p[0] == '*' {
break
}
}
}
return
}
查找
先看getRoute方法,要是没有对应的方法树,直接返回空即可。
接着调用parsePath函数。最后调用前缀树的search方法。
search方法是递归查找的。
有一点需要注意,例如:/user/:id/a只有在第三层节点,即a节点,path才会设置为/user/:id/a。user和:id节点的path属性皆为空。
因此,当匹配结束时,我们可以使用n.path == ""来判断路由规则是否匹配成功。
例如,/user/th虽能成功匹配到/user/:id,但/user/:id的path值为空,因此匹配失败。查询功能,同样也是递归查询每一层的节点,退出规则是,匹配到了*,匹配失败,或者匹配到了第len(parts)层节点。
matchChildren有点重要,可以对比下和极客兔兔教程的matchChildren函数有何不同。
//在router.go文件中
func (r *router) getRoute(method, path string) (*node, map[string]string) {
root, ok := r.roots[method]
if !ok {
return nil, nil
}
searchParts := parsePath(path)
n := root.search(searchParts, 0)
if n == nil {
return nil, nil
}
params := make(map[string]string)
parts := parsePath(n.path)
for i, part := range parts {
//这些操作是为了可以找到动态路由的参数
//例如添加了路由 /user/:id/a,
//那用户使用/user/my/a来访问的时候,其参数id就是my
if part[0] == ':' {
params[part[1:]] = searchParts[i]
}
if part[0] == '*' && len(part) > 1 {
params[part[1:]] = strings.Join(searchParts[i:], "/")
break
}
}
return n, params
}
//在trie.go文件中
func (n *node) search(searchParts []string, height int) *node {
if len(searchParts) == height || strings.HasPrefix(n.part, "*") {
if n.path == "" {
return nil
}
return n
}
part := searchParts[height]
childern := n.matchChildren(part)
for _, child := range childern {
result := child.search(searchParts, height+1)
if result != nil {
return result
}
}
return nil
}
func (n *node) matchChildren(part string) (result []*node) {
nodes := make([]*node, 0)
for _, child := range n.children {
if child.part == part {
result = append(result, child)
} else if child.isWild {
nodes = append(nodes, child)
}
}
return append(result, nodes...)
}Router
前缀树的算法实现后,接下来就需要把该树应用到路由中。我们使用root来存储每中请求方法的前缀树根结点。使用hander来存储每种请求方式的处理方法HandlerFunc。
代码也在Trie实现中讲解了。
getRoute 函数中,解析了:和*两种匹配符的参数,返回一个 map 。例如前缀树有/p/:lang/doc和/static/*filepath。
路径/p/go/doc匹配到/p/:lang/doc,解析结果为:{lang: "go"};路径/static/css/geektutu.css匹配到/static/*filepath,解析结果为{filepath: "css/geektutu.css"}。
这个匹配就是通过getRoute函数中for range获取的。
Contex和Router.handle的变化
Context有了些许变化。在 HandlerFunc 中,希望能够访问到解析的参数,因此,需要对 Context 对象增加一个属性和方法,来提供对路由参数的访问。我们将解析后的参数存储到Params中,通过c.Param("lang")的方式获取到对应的值。
type Context struct {
Wrtier http.ResponseWriter
Req *http.Request
Path string
Method string
Params map[string]string //新添加的
//响应的状态码
StatusCode int
}
func (c *Context) Param(key string) string {
value, _ := c.Params[key]
return value
}Router.handle方法
在调用匹配到的handler前,将解析出来的路由参数赋值给了c.Params。这样就能够在handler中,通过Context对象访问到具体的值了。
func (r *router) handle(c *Context) {
n, params := r.getRoute(c.Method, c.Path)
if n != nil {
c.Params = params
//key := c.Method + "-" + c.Path 这样写是错误的,是要+n.path
key := c.Method + "-" + n.path
r.handers[key](c)
} else {
c.String(http.StatusNotFound, "404 NOT FOUND: %s\n", c.Path)
}
//上一节的实现
// key := c.Method + "-" + c.Path
// if hander, ok := r.handers[key]; ok {
// hander(c)
// } else {
// c.String(http.StatusNotFound, "404 NOT FOUND: %s\n", c.Path)
// }
}修复的路由冲突BUG
主要是对比极客兔兔的教程,这节的路由有两部分不同。
一在node的insert函数中,这里只是判别child.part == part,没有判别child.isWild==true。
这样当出现要先后插入/:name,/16时候,/:name是没有的,那就是直接创建插入。
而到插入/16时候,若是也判别child.isWild==true的话,这时是true的,那么就不会创建part是16的结点。所以不进行判断child.isWild==true,只判断child.part是否等于所给的part,这样就可以创建part是16的结点。
二是在node的matchChildren函数中。
还是/:name,/16的例子,这时用户通过/16来访问,那肯定是想返回/16对应的处理函数。假如matchChildren返回的[]*node第一个元素:name,那么这个是符合条件的,那就会执行:name对应的处理函数了。
func (n *node) matchChildren(part string) (result []*node) {
nodes := make([]*node, 0)
for _, child := range n.children {
if child.part == part {
result = append(result, child)
} else if child.isWild {
nodes = append(nodes, child)
}
}
return append(result, nodes...)
}
//极客兔兔教程的
func (n *node) matchChildren(part string) []*node {
nodes := make([]*node, 0)
for _, child := range n.children {
if child.part == part || child.isWild {
nodes = append(nodes, child)
}
}
return nodes
}而这里,是把/16放在返回的[]*node中的第一个位置。那么就会先把 /16来进行判别是否符合条件,而/16是符合条件的,那就会执行/16对应的处理函数。
基本就是这样。若有不同意见或有更好的想法,欢迎在评论区讨论。
Router单元测试
当前框架的文件结构
创建router_test.go文件来进行测试router。
进入到gee文件夹,执行命令 go test -run 要测试的函数。
例如测试TestGetRoute,执行命令 go test -run TestGetRoute
后面添加-v,可以查看具体的情况,例如: go test -run TestGetRoute -v
func newTestRouter() *router {
r := newRouter()
r.addRoute("GET", "/", nil)
r.addRoute("GET", "/hello/:name", nil)
r.addRoute("GET", "/hello/b/c", nil)
r.addRoute("GET", "/hi/:name", nil)
r.addRoute("GET", "/assets/*filepath", nil)
return r
}
func TestParsePattern(t *testing.T) {
ok := reflect.DeepEqual(parsePath("/p/:name"), []string{"p", ":name"})
ok = ok && reflect.DeepEqual(parsePath("/p/*"), []string{"p", "*"})
ok = ok && reflect.DeepEqual(parsePath("/p/*name/*"), []string{"p", "*name"})
if !ok {
t.Fatal("test parsePattern failed")
}
}
func TestGetRoute(t *testing.T) {
r := newTestRouter()
n, ps := r.getRoute("GET", "/hello/li")
if n == nil {
t.Fatal("nil shouldn't be returned")
}
if n.path != "/hello/:name" {
t.Fatal("should match /hello/:name")
}
if ps["name"] != "li" {
t.Fatal("name should be equal to 'li'")
}
fmt.Printf("matched path: %s, params['name']: %s\n", n.path, ps["name"])
}
func TestGetRoute2(t *testing.T) {
r := newTestRouter()
n1, ps1 := r.getRoute("GET", "/assets/file1.txt")
ok1 := n1.path == "/assets/*filepath" && ps1["filepath"] == "file1.txt"
if !ok1 {
t.Fatal("pattern shoule be /assets/*filepath & filepath shoule be file1.txt")
}
n2, ps2 := r.getRoute("GET", "/assets/css/test.css")
ok2 := n2.path == "/assets/*filepath" && ps2["filepath"] == "css/test.css"
if !ok2 {
t.Fatal("pattern shoule be /assets/*filepath & filepath shoule be css/test.css")
}
}测试
func main() {
fmt.Println("hello web")
r := gee.New()
r.GET("/:name", func(c *gee.Context) {
name := c.Param("name")
c.String(http.StatusOK, "name is %s", name)
})
r.GET("/16", func(c *gee.Context) {
c.String(http.StatusOK, "id is 16")
})
r.GET("/user/info/a", func(c *gee.Context) {
c.String(http.StatusOK, "static is %s", "sdfsd")
})
r.GET("/user/:id/a", func(c *gee.Context) {
name := c.Param("id")
c.String(http.StatusOK, "id is %s", name)
})
r.Run("localhost:10000")
}完整代码:https://github.com/liwook/Go-projects/tree/main/gee-web/3-trie-router