文章目录
- MVC与MTV模型
- MVC
- MTV
- Django目录结构
- Django请求生命周期流程图
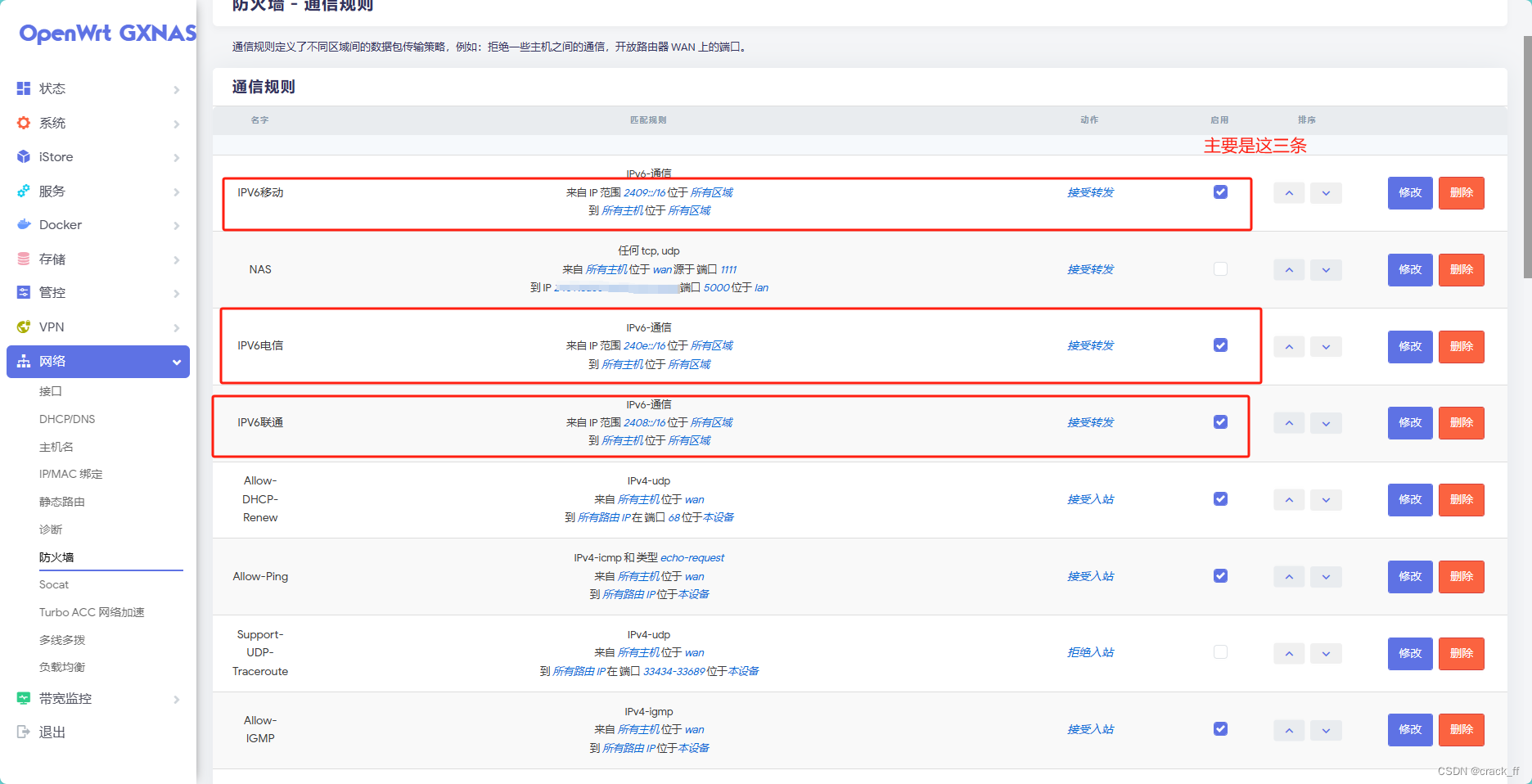
- 路由控制
- 路由是什么
- 路由匹配
- 反向解析
- 路由分发
- 视图层
- 视图函数语法
- reqeust对象属性
- reqeust对象方法
MVC与MTV模型
MVC
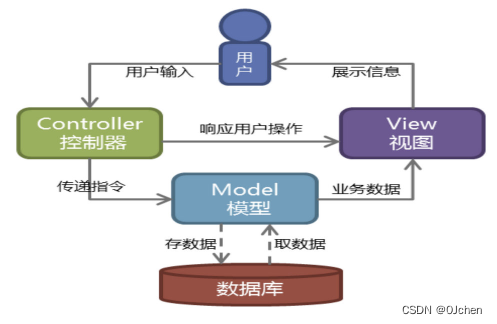
Web服务器开发领域里著名的MVC模式,所谓MVC就是把Web应用分为
模型(M:数据层),控制器(C:逻辑判断)和视图(V:用户所看的)三层,他们之间以一种插件式的、松耦合的方式连接在一起,模型负责业务对象与数据库的映射(ORM),视图负责与用户的交互(页面),控制器接受用户的输入调用模型和视图完成用户的请求,其示意图如下所示:
MTV
Django的MTV模式本质上和MVC是一样的,也是为了各组件间保持松耦合关系,只是定义上有些许不同,Django的MTV分别是值:
- M 代表模型(Model):负责业务对象和数据库的关系映射(ORM)。
(M 就是 MVC 的 M) - T 代表模版(Template):负责如果把页面展示给用户(HTML)。
(T 就是 MVC 的 V) - V 代表视图(View):负责业务逻辑,并在适当时候调用Model和Template
(V+路由 就是 MVC 的 C)
除了以上三层之外,还需要一个URL分发器,它的作用是将一个个URL的页面请求分发给不同的View处理,View再调用相应的Model和Template,MTV的响应模式如下所示:
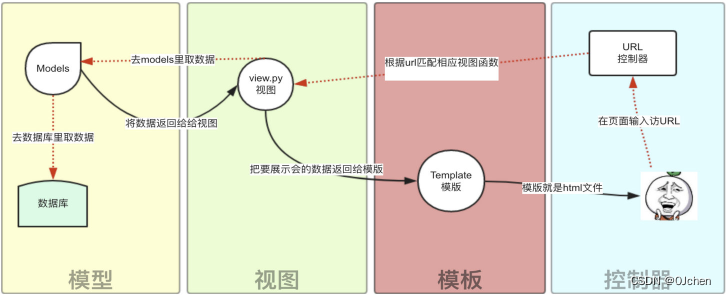
一般是用户通过浏览器向我们的服务器发起一个请求(request),这个请求回去访问视图函数,(如果不涉及到数据调用,那么这个时候视图函数返回一个模版也就是一个网页给用户),视图函数调用模型,模型去数据库查找数据,然后逐级返回,视图函数把返回的数据填充到模版中的空格中,最后返回页面给用户
Django目录结构
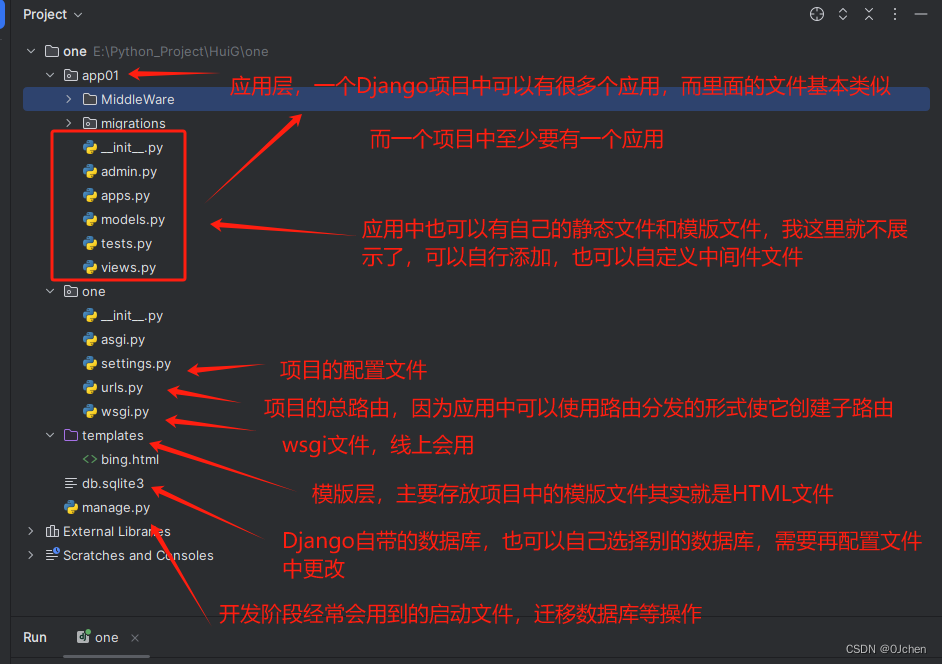
django项目目录
项目同名文件夹
__init__.py 很少用 主要做一些冷门配置
settings.py 项目的全局配置文件
urls.py 路由文件,写地址的后缀和视图函数的对应关系
wsgi.py django服务 基本不用
manage.py django的启动文件、入口文件
templates文件夹 模版文件,存储项目所需的html文件
应用名文件夹(可以有多个)
migrations文件夹 orm相关(数据库打交道的记录)
__init__.py 很少用 主要做一些冷门配置
admin.py django自带的后台管理系统
apps.py 创建应用之后用于应用的注册
models.py 模型层,存储与数据库表相关的类
tests.py 自带的测试文件
views.py 视图文件。存储业务相关的逻辑代码(函数、类)
db.sqlite3 自带的小型数据库
urls.py 路由层
views.py 视图层
templates 模板层
models.py 模型层
更多Django基本操作可以去看我的这篇博客https://blog.csdn.net/achen_m/article/details/134296792?spm=1001.2014.3001.5501
Django请求生命周期流程图

django的生命周期是从用户发送HTTP请求数据到网站响应的过程。
整个过程的流程:
1.首先,用户在浏览器输入一个URL,发送一个请求
2.在django中有一个封装的socket的方法模块wsgiref,监听端口接收request请求,并且封装传送到中间件中。
3.在由中间件传输到路由系统中进行路由分发,匹配相对应的视图函数
4.将reqeust请求传输到视图函数中进行逻辑处理。
5.调用models中表对象,然后通过ORM操作数据库拿到数据,同时去templates中去相应的模版文件中进行渲染
6.然后返回到中间件中,进行response响应返回数据到wsgiref中进行封装后再返回给浏览器展示给用户
路由控制
此处只做补充知识,想看更多可查看我的这篇博客了解https://blog.csdn.net/achen_m/article/details/134377889?spm=1001.2014.3001.5501
路由是什么
URL配置(URLconf)就像Django 所支撑网站的目录。它的本质是URL与要为该URL调用的视图函数之间的映射表;你就是以这种方式告诉Django,对于客户端发来的某个URL调用哪一段逻辑代码对应执行
(请求路径和要执行的视图函数的关系)
路由匹配
此处只说2.X版本以上使用的关键字path,想看1.X的可以前去上面标题处的连接
在django2.x及以上版本:path第一个参数写什么就匹配什么(精准匹配),匹配到直接执行对应的视图函数
path('admin/',函数名), '这种写法不支持正则表达式'
当然2.x版本也有可以使用正则匹配的方式:
re_path(正则表达式,函数名) '其作用和django1.x的url使用效果一模一样'
'但是因为有转换器,基本就用不上re_path这个关键字,而且正则匹配本就不是那么的安全'
path的详细使用
urlpatterns = [
path('admin/', views.admin),
]
等价于:_path(route, view, kwargs=None, name=None)
第一个参数:
精准路径,字符串
可以使用转换器:'<int:pk>' '<str:name>'
例子:
path('index/<int:year>/<str:info>/',views.index)
转换器有几个名字,那么视图函数的形参就必须对应
视图层:
def index(request,year,info):
print(year,info)
return HttpResponse('from index')
第二个参数:视图函数的内存地址,不要加括号
1.路由一旦匹配成功,就会执行,你写的这个视图函数(request),并且会把request对象传入
2.如果有分组的参数[有名分组、无名分组],或者转换器的参数,都会被传递到视图函数中作为参数
'''
总结:需要放视图函数内存地址------》视图函数的第一个参数是固定的,必须是reqeust,后续的参数取决于
写没写转换器或者写没写有名分组、无名分组
'''
第三个参数:kwargs 是给视图函数传递默认参数
第四个参数:是路径的别名---》主要用于反向解析得到该路径
而
re_path除了第一个参数不一样以外,其他完全和path是一样的。re_path第一个参数是正则表达式
现在基本很少使用
re_path,因为危险性比较大,原来之所以使用就是为了使用正则匹配分组出参数,现在path可以通过转换器就能完成这个操作,所以基本不使用re_path
反向解析
在使用Django 项目时,一个常见的需求是获得URL 的最终形式,以用于嵌入到生成的内容中(视图中和显示给用户的URL等)或者用于处理服务器端的导航(重定向等)。人们强烈希望不要硬编码这些URL(费力、不可扩展且容易产生错误)或者设计一种与URLconf 毫不相关的专门的URL 生成机制,因为这样容易导致一定程度上产生过期的URL。
反向解析为的就是防止路由经常变动,这样我们页面的链接、或者函数的重定向就能动态获取到路由可接收的URL。
此处也仅用path来讲述
'反向解析,用于视图函数中、用于模版中'
1.没有转换器的情况:
path('index/', views.index,name='index'),
'视图函数'
from django.shortcuts import HttpResponse,reverse
def index(request):
reverse('index') # 定义路径传入的name参数对应的字符串
2.有转化器的情况:
path('index/<str:name>', views.index,name='index'),
'视图函数'
from django.shortcuts import HttpResponse,reverse
def index(request):
reverse('index',kwargs={'name':'jack'})
'最后生成的路径:URL/index/jack'
路由分发
django是专注于开发应用的,当一个django项目特别庞大的时候所有的路由与视图函数映射关系全部写在总的urls.py很明显太冗余不便于管理,其实django中的每一个app应用都可以有自己的urls.py、static文件夹、templates文件夹,基于上述特点,使用django做分组开发非常的简便。
可以分开写多个app应用,最后再汇总到一个空的Django项目然后使用路由分发将多个app应用关联起来。
未使用路由分发前:所有请求都由主路由转发到对应视图函数,全部都在一个urls.py文件内。
为什么默认路由匹配能匹配到urls.py文件呢?是因为在settings配置文件中配置了ROOT_URLCONF = 'django_项目名.urls'
路由分发需要使用到关键字include
from django.urls. import path,include
主路由:
urlpatterns = [
path('admin/', admin.site.urls),
path('app01/', include('app01.urls')),
]
然后需要再应用里面建立一个urls.py文件
充当子路由
from django.urls import path
from app01 import views
urlpatterns = [
path('index/',views.index),
]
视图层
django视图层:Django项目下的views.py文件,它的内部是一系列的函数或者是类,用来处理客户端的请求后处理并返回相应的数据
视图层,熟练掌握两个对象即可:请求对象(request)和响应对象(HttpResponse)
视图函数语法
'视图函数必须要有一个reqeust参数,并且必须要返回一个HttpResponse对象'
def index(reqeust):
return HttpResponse('hello,world')
reqeust对象属性
django将请求报文中的请求行、首部信息、内容主体封装成 HttpRequest 类中的属性。 除了特殊说明的之外,其他均为只读的
'它是http请求(数据包----》字符串形式)-----》拆分成了django中的reqeust对象'
request对象常用的属性:
request.GET 一个类似于字典的对象,包含 HTTP GET 的所有参数。详情请参考 QueryDict 对象。
reqeust.POST 一个类似于字典的对象,如果请求中包含表单数据,则将这些数据封装成 QueryDict 对象。
reqeust.body
一个字符串,代表请求报文的主体。在处理非 HTTP 形式的报文时非常有用,例如:二进制图片、XML,Json等。
但是,如果要处理表单数据的时候,推荐还是使用 HttpRequest.POST 。
request.path 一个字符串,表示请求的路径组件(不含域名)。例如:"/music/bands/the_beatles/"
request.method 一个字符串,表示请求使用的HTTP 方法。必须使用大写。例如:"GET"、"POST"
reqeust.FILES 一个类似于字典的对象,包含所有的上传文件信息。
request对象不常用的属性:
request.cookie
reqeust.session
reqeust.content_type:提交的编码格式:'urlencoded(form表单),json,form-data,text/plain(一般不用,浏览器默认格式)'
reqeust.META:请求头中的数据
一个标准的Python 字典,包含所有的HTTP 首部。具体的头部信息取决于客户端和服务器,下面是一些示例:
取值:
CONTENT_LENGTH —— 请求的正文的长度(是一个字符串)。
CONTENT_TYPE —— 请求的正文的MIME 类型。
HTTP_ACCEPT —— 响应可接收的Content-Type。
HTTP_ACCEPT_ENCODING —— 响应可接收的编码。
HTTP_ACCEPT_LANGUAGE —— 响应可接收的语言。
HTTP_HOST —— 客服端发送的HTTP Host 头部。
HTTP_REFERER —— Referring 页面。
HTTP_USER_AGENT —— 客户端的user-agent 字符串。
QUERY_STRING —— 单个字符串形式的查询字符串(未解析过的形式)。
REMOTE_ADDR —— 客户端的IP 地址。
REMOTE_HOST —— 客户端的主机名。
REMOTE_USER —— 服务器认证后的用户。
REQUEST_METHOD —— 一个字符串,例如"GET" 或"POST"。
SERVER_NAME —— 服务器的主机名。
SERVER_PORT —— 服务器的端口(是一个字符串)。
从上面可以看到,除 CONTENT_LENGTH 和 CONTENT_TYPE 之外,请求中的任何 HTTP 首部转换为 META 的键时,
都会将所有字母大写并将连接符替换为下划线最后加上 HTTP_ 前缀。
所以,一个叫做 X-Bender 的头部将转换成 META 中的 HTTP_X_BENDER 键。
'''
用户自定义写的例如:name=jack
取:request.META.get('HTTP_NAME') # 前面加上HTTP_把自定义的转成大写
'''
reqeust对象方法
1.HttpRequest.get_full_path()
返回 path,如果可以将加上查询字符串。
例如:"/music/bands/the_beatles/?print=true"
注意和path的区别:http://127.0.0.1:8001/order/?name=lqz&age=10
2.HttpRequest.is_ajax()
如果请求是通过XMLHttpRequest 发起的,则返回True,方法是检查 HTTP_X_REQUESTED_WITH
相应的首部是否是字符串'XMLHttpRequest'。
大部分现代的 JavaScript 库都会发送这个头部。如果你编写自己的 XMLHttpRequest 调用(在浏览器端),
你必须手工设置这个值来让 is_ajax() 可以工作。
如果一个响应需要根据请求是否是通过AJAX 发起的,并且你正在使用某种形式的缓存例如Django 的 cache middleware,
你应该使用 vary_on_headers('HTTP_X_REQUESTED_WITH') 装饰你的视图以让响应能够正确地缓存。

![合并区间[中等]](https://img-blog.csdnimg.cn/direct/8195d98576d04e398577815215d22856.png)