解决在SwingBench压测时出现一些问题
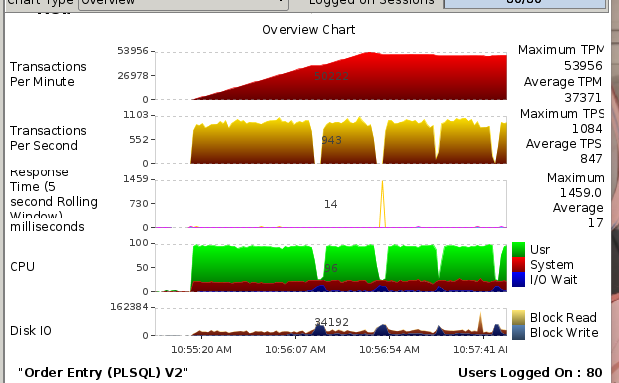
压测时断层
1.问题来由:在进行swingbench压测的时候会出现断断续续的情况
2.导致原因:
我们通过查看日志文件,看看是什么情况
tail -100 /u01/app/oracle/diag/rdbms/orcl/orcl/trace/alert_orcl.log
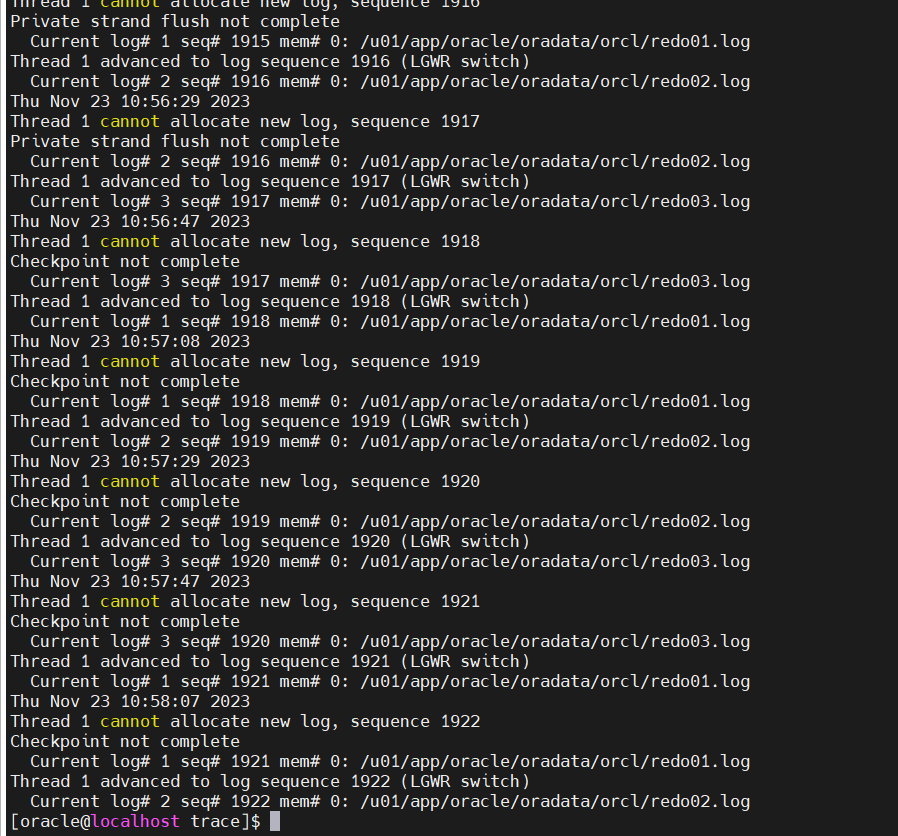
通过查看分析是redo文件切换太过于频繁,
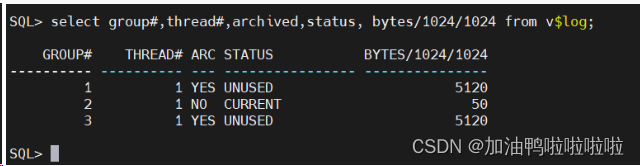
我们试着查看一下redo的大小
select group#,thread#,archived,status, bytes/1024/1024 from v$log;
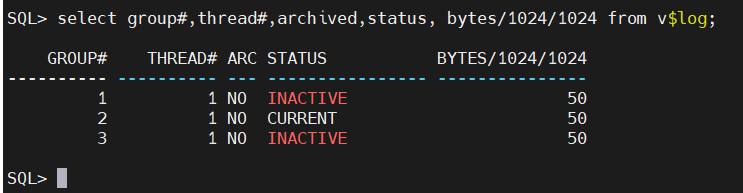
通过查找发现redo的大小只有50M,太小了,读写的速度过快,会导致redo切换的太频繁,使得压测的时候性能跟不上,而且出现断层
我们试着修改redo的大小,由于oracle没用提供修改log file大小的命令,所以只能以删除后再重新创建的方法达到修改大小的目的。又由于oracle要求最少有两组日志文件在使用,所以不能直接删除原日志组,我的做法是依次删除,依次创建。我们需要观察当前是哪个redo没有在工作,我们就先删掉没有在工作的日志中的其中一个,然后再依次创建删除。
1.删除日志组3
alter database drop logfile group 3;
2.然后在物理删除对应的redo03.log
找到路径
select group#,type, member from v$logfile;
rm -rf "xxx.log"
3.重新创建rodo03.log
alter database add logfile group 3 ('/u01/app/oracle/oradata/orcl/redo03.log'
) size 5G;
1.删除日志组1
alter database drop logfile group 1;
2.然后在物理删除对应的redo01.log
找到路径
select group#,type, member from v$logfile;
rm -rf "xxx.log"
3.重新创建rodo01.log
alter database add logfile group 1 ('/u01/app/oracle/oradata/orcl/redo01.log'
) size 5G;
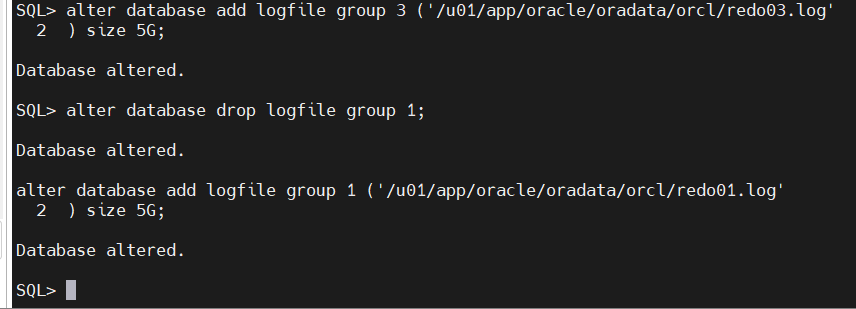
查看一下
select group#,thread#,archived,status, bytes/1024/1024 from v$log;
切换当前日志到新的日志组
alter system switch logfile;
查看,这个过程比较缓慢,可能大概要几分钟
select group#,thread#,archived,status, bytes/1024/1024 from v$log;
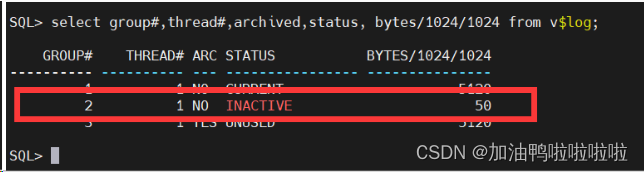
接着删除日志组2
1.删除日志组2
alter database drop logfile group 2;
2.然后在物理删除对应的redo02.log
找到路径
select group#,type, member from v$logfile;
rm -rf "xxx.log"
3.重新创建rodo02.log
alter database add logfile group 2 ('/u01/app/oracle/oradata/orcl/redo02.log'
) size 5G;
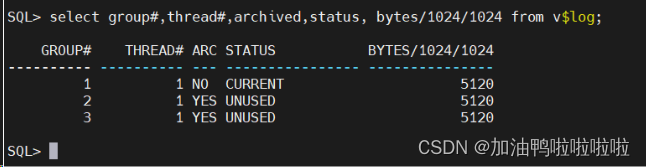
重建完毕
压测就不会出现断层啦
如果压测的时候遇到锯齿状,很不平整
如果压测的数据量有点小可以修改SGA,PGA的大小
ALTER SYSTEM SET sga_target=4G scope=spfile;
ALTER SYSTEM SET pga_aggregate_target=1500M scope=spfile;
检查参数设置是否生效。执行以下命令确认参数设置是否正确:
SHOW PARAMETER sga_target;
SHOW PARAMETER pga_aggregate_target;

如果是想提高一些processes(进程用户)数量可以修改一下processes
alter system set processes=400 scope=spfile;
查看
select * from v$parameter where name='processes';
总结:
swingbench的压测在设置好各种参数之后,压测的值和你的cpu和内存也有很大的关联,通过对不同参数的调整是可以压测到自己的一个极限,这个过程需要很多时间去尝试和修改参数,找到你对应的·参数,我上面提供的参数是针对我自己电脑调整的一个参数,也只能提供一个参考,具体的实施还得自己摸索。