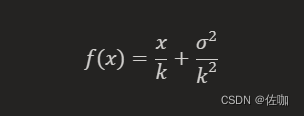Title:<Data Boost: Text Data Augmentation Through Reinforcement Learning Guided Conditional Generation>
期刊:EMNLP (顶级国际会议)
作者 Ruibo Liu; Guangxuan Xu; Chenyan Jia; Weicheng Ma; Lili Wang; et al
出版日期 2020-11-01
网址 https://doi.org/10.18653/v1/2020.emnlp-main.726
摘要
数据扩充在许多NLU任务中被证明是有效的,特别是对于那些遭受数据稀缺的任务。在本文中,我们提出了一个强大且易于部署的文本增强框架Data Boost,它通过强化学习指导的条件生成来增强数据。我们在五种不同的分类器架构下,在三种不同的文本分类任务上评估数据提升。结果表明,数据增强可以提高分类器的性能,尤其是在低资源数据的情况下。例如,当只给定全部数据的10%用于训练时,数据增强将三个任务的F1平均提高了8.7%。我们还比较了数据增强与六种现有的文本增强方法。通过人工评估(N=178),我们确认数据增强增强在可读性和类一致性方面具有与原始数据相当的质量。
1.介绍
数据扩充是分类任务中广泛使用的技术。在计算机视觉(CV)领域,通过翻转、裁剪、倾斜和改变原始图像的RGB通道来扩充数据(Krizhevsky等人,2012;Chatfield等人,2014年;Szegedy等人,2015);然而,类似的直观和简单的策略在NLP任务中并没有获得同样的成功。现有方法倾向于产生可读性低或语义一致性不令人满意的增强(Yang et al,2020)。

表1给出了一些流行的文本增强方法的输出样本。朴素方法模仿CV中的像素操作,通过添加拼写错误( Xie et al . , 2017)或随机删除和交换令牌( Wei和Zou , 2019)来扩充句子。由于语序被打乱(例如, "宝宝很好! "),这类增强方法的输出结果往往难以辨认;更糟糕的是,关键特征词(例如,可爱这个词,它是情感检测的信号携带词)可能会通过随机删除的方式被误删。
一种更高级的方法是同义词插入或替换(张杰等, 2015 ;王永进、杨志刚, 2015),它使用Word2Vec (米科洛夫等, 2013)将单词替换为其同义词。这种方法尊重原文的句子结构,但没有考虑语境。它有时用同义词来代替在句子的整个语境中显得笨拙的词。例如,用寓言代替可爱,得到"宝贝是寓言! "这句话。最近的工作倾向于基于翻译的( Fadaee et al , 2017 ;西尔弗贝里et al , 2017)增强方法。
特别地,Yu等人( 2018 )提出了一种先将文本翻译成法语再翻译成英语的回译方法,使用带噪声的输出作为增强数据。虽然回译具有直观性和有效性,但其生成偏向于高频词( e.g . , cute , lovely都回译为可爱),不仅会造成重复,而且会导致增广数据的词汇收缩。总之,现有的技术还很不完善,部分原因是文本数据中的句法和语义特征具有很强的相互依赖关系。
增强样本应该表现出目标类的特征。现成的LM(langue model)不能直接用于数据增强;由于它们不是针对特定的语境进行训练的,因此它们的生成是无向的和随机的。条件LM可以根据一定的条件(例如,目标类)生成文本,但它需要从头开始训练一个LM,并且数据覆盖所有的条件。例如,Keskar等人( 2019 )训练了一个16亿参数的LM,该LM条件为各种控制代码。培训成本较高;然而,收集足够的数据用于训练也是繁琐的,尤其是在低资源任务( Waseem , 2016)中。
优点
Data Boost的优势有三点:第一,Data Boost功能强大。与6个相关工作相比,我们在5个不同分类器的3个任务上取得了显著的进步。第二,Data Boost生成句子级增强。与先前的方法进行单词级别或短语级别的替换(小林, 2018 ; Wei and Zou , 2019)不同,我们的增强数据在词汇和句子结构方面具有更多的多样性。人的评价也验证了我们的增强具有较高的可读性和标签一致性。第三,Data Boost易于部署。它不需要外部数据集,也不需要单独训练系统(像机器翻译模型中的回译方法)。取而代之的是现成的GPT2语言模型,在不改变其架构的前提下,对其解码阶段进行修改.
2.数据增强
2.1条件生成器
给定符号 = {
}和在时间步长t之前的累积隐状态
<
,训练一个普通的自回归语言模型( LM )来最大化下一步符号( xt )的概率.通常情况下,模型会选择具有最高概率
的符号作为t步解码的输出:

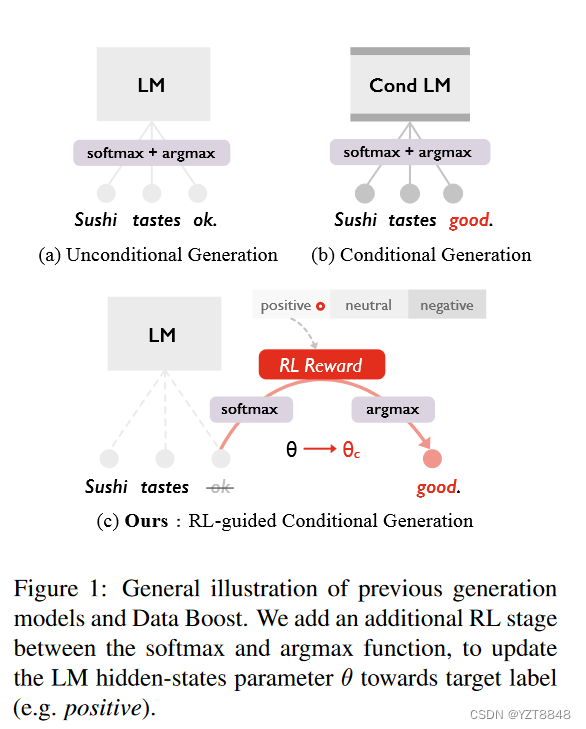
2.2强化学习优化

Reward
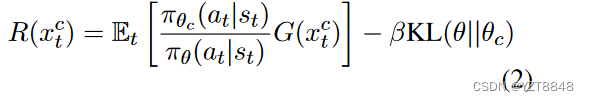
PPO (近端政策优化)
Salience Score:

其中| x∈c |是指类标号为c的样本中词x的个数,| V |是总词汇量,GM是这两个词的几何平均。这两个分数都试图保证一个词被标记为显著的概率P ( c | x )和P ( x | c )都很高。我们计算每个单词的显著性得分,并选择前N个最高的单词2作为类别标签c (记为wc)的显著性词典。与其他方法如训练鉴别器(达特赫里等, 2020)或导出控制代码( Keskar et al , 2019)相比,我们发现基于频率的方法相对简单但有效,特别是在数据饥饿的情况下,由于训练数据很少,鉴别器的性能可能受到限制。
Salience Gain:
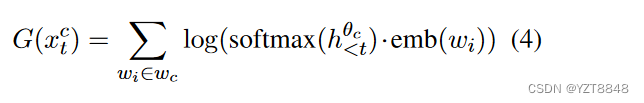
对于以目标类c为条件的第t步令牌xtc,我们将显著性增益计算为与显著词库wc中每个词的余弦相似度的对数求和:
优化:策略梯度进行优化
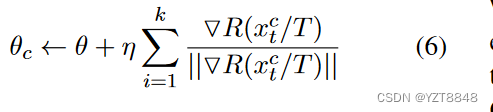
式中:η为学习率,θ c为条件隐状态的参数。总的来说,我们遵循经典的SGD更新规则,但做了两个主要的改变:( 1 )在令牌解码( Keskar et al , 2019)的过程中,我们使用温度参数T来控制随机采样。T→0近似一种贪婪解码策略,放大了vocab分布中的峰值,而T→∞使得分布更加均匀。( 2 )我们对k步奖励的归一化梯度进行求和。k可以作为条件生成的控制强度。结合以上所有定义,在算法1中总结了Data Boost的策略梯度。