要求:获取下图指定网站的指定数据
空气质量状况报告-中国环境监测总站
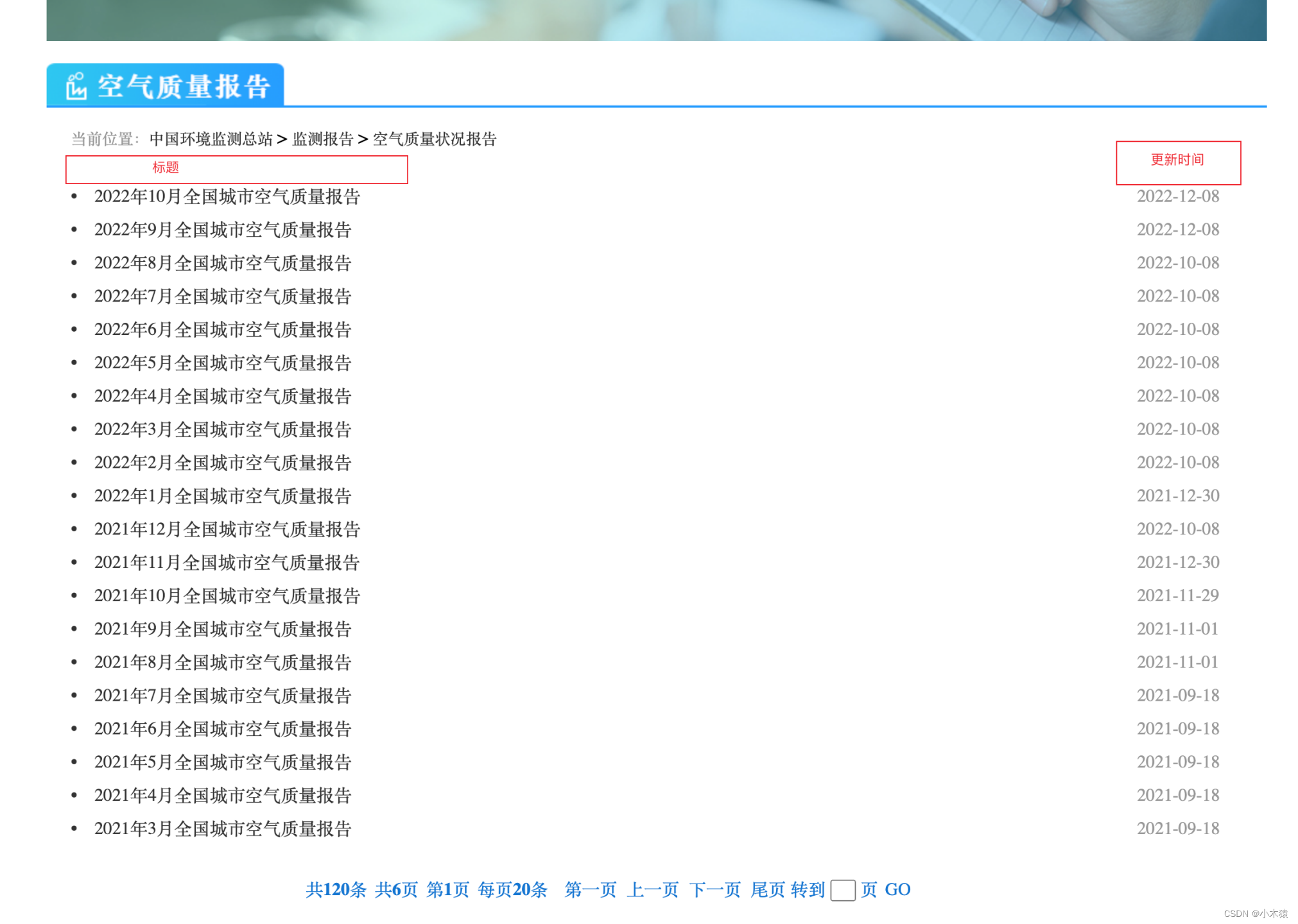
输入:用户输入下载时间范围,格式为2022-10
输出:将更新时间在2022年10月1日到31日之间的文件下载到本地目录(可配置),并将下载的标题列表逐行打印在控制台console中
完成标准:
程序正常运行
import requests
from lxml import etree
from urllib.parse import urljoin
from datetime import datetime
def download_files(start_date,end_date):
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
}
base_url = "http://www.cnemc.cn/jcbg/kqzlzkbg/index"
page=0
while True:
if page==0:
url=f"{base_url}.shtml"
else:
url=f"{base_url}_{page}.shtml"
# url = "http://www.cnemc.cn/jcbg/kqzlzkbg/index.shtml"
response = requests.get(url, headers=headers)
if response.status_code!=200:
break
response.encoding = response.apparent_encoding
page_text = response.text
html = etree.HTML(page_text)
divs = html.xpath('//*[@id="contentPageData"]/li')
for i in divs:
# 使用 XPath 定位到 <a> 标签并提取文本
title = i.xpath('.//a/text()') # 获取第一个匹配元素的文本
# 使用 XPath 定位到 <span class="txt_time"> 标签并提取文本
date_str = i.xpath('.//span[@class="txt_time"]/text()')
if title and date_str:
title = title[0].strip()
date = datetime.strptime(date_str[0].strip(),'%Y-%m-%d')
if start_date <= date <= end_date:
a_tag = i.find('.//a')
link = a_tag.get('href') if a_tag is not None else None
print(f'下载标题:{title}')
print(link)
base_link='http://www.cnemc.cn/jcbg/kqzlzkbg/'
full_link=urljoin(base_link,link)
print(full_link)
response_son = requests.get(full_link, headers=headers)
response_son.encoding = response_son.apparent_encoding
page_text_son=response_son.text
# print(page_text_son)
html_son = etree.HTML(page_text_son)
divs_son=html_son.xpath('/html/body/div[1]/div[5]/div/div[1]')[0]
# print(divs_son) #/html/body/div[1]/div[5]/div/div[1]
a_tag_son = divs_son.find('.//a')
link_file = a_tag_son.get('href') if a_tag_son is not None else None
print(link_file)
if "http://www.cnemc.cn/" not in link_file:
link_file="http://www.cnemc.cn/jcbg/kqzlzkbg/"+str(start_date.year)+str(start_date.month)+'/'+link_file.lstrip('./')
print(link_file)
file_path=f"./downloads/{title}.pdf"
response_file=requests.get(link_file)
if response_file.status_code==200:
with open(file_path,'wb') as f:
f.write(response_file.content)
print("文件下载成功,保存至:", file_path)
else:
print("下载失败,状态码:", response_file.status_code)
page+=1
if __name__=="__main__":
start_date=datetime(2016,4,1)
end_date=datetime(2016,4,30)
download_files(start_date,end_date)