《麻省理工技术评论》曾在官网发表文章表示,随着ChatGPT等大模型的持续火热,对训练数据的需求越来越大。大模型就像是一个“网络黑洞”不断地吸收,最终会导致没有足够的数据进行训练。
而知名AI研究机构Epochai直接针对数据训练问题发表了一篇论文,并指出,到2026年,大模型将消耗尽高质量数据;到2030年—2050年,将消耗尽所有低质量数据;
到2030年—2060年,将消耗尽所有图像训练数据。(这里的数据指的是,没有被任何标记、污染过的原生数据)
论文地址:https://arxiv.org/pdf/2211.04325.pdf

事实上,训练数据的问题已经显现。OpenAI表示,缺乏高质量训练数据将成为开发GPT-5的重要难题之一。这就像人类上学一样,当你的知识水平达到博士级别时,再给你看初中的知识对学习毫无帮助。
所以,OpenAI为了增强GPT-5的学习、推理和AGI通用能力,已建立了一个“数据联盟”,希望大面积搜集私密、超长文本、视频、音频等数据,让模型深度模拟、学习人类的思维和工作方式。
目前,冰岛、Free Law Project等组织已加入该联盟,为OpenAI提供各种数据,帮助其加速模型研发。
此外,随着ChatGPT、Midjourney、Gen-2等模型生成的AI内容进入公共网络,这对人类构建的公共数据池将产生严重污染,会出现同质化、逻辑单一等特征,加速高质量数据消耗的进程。
高质量训练数据,对大模型研发至关重要
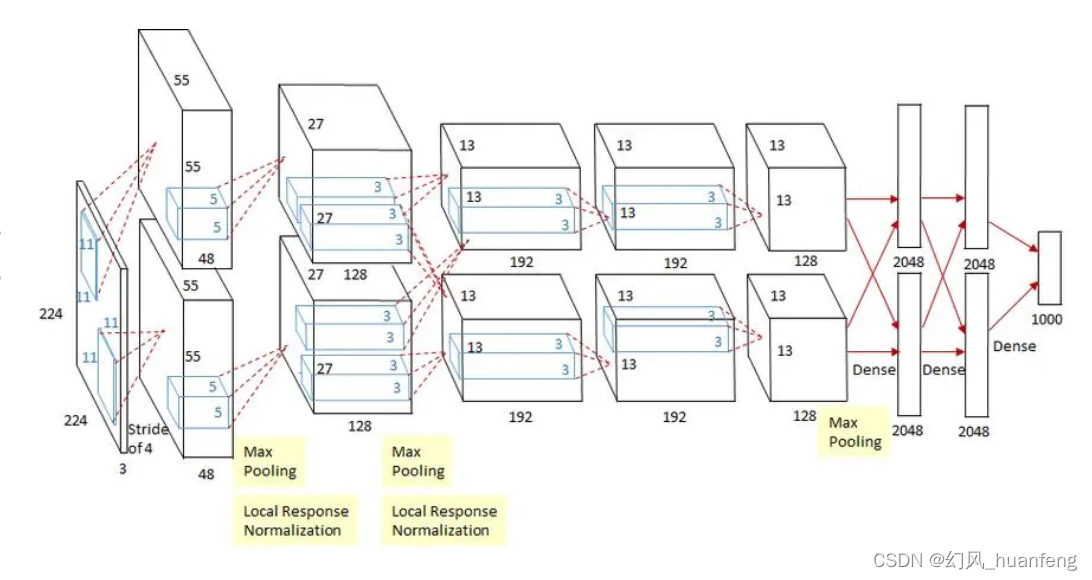
从技术原理来看,可以把大语言模型看成“语言预测机器”, 通过学习大量文本数据,建立起单词之间的关联模式,然后利用这些模式来预测文本的下一个单词或句子。
Transformer便是最著名、应用最广泛的架构之一,ChatGPT等借鉴了该技术。
简单来说,大语言模型就是“照葫芦画瓢”,人类怎么说它就怎么说。所以,当你使用ChatGPT等模型生成文本时,会感觉这些文本内容的叙述模式在哪里见过。
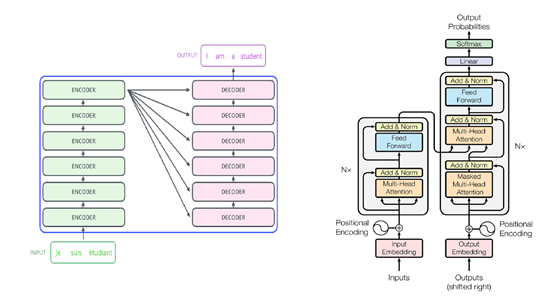
因此,训练数据的质量直接决定了大模型学习的结构是否准确。如果数据中包含了大量语法错误、措辞不当、断句不准、虚假内容等,那么模型预测出来的内容自然也包含这些问题。
例如,训练了一个翻译模型,但使用的数据都是胡编乱造的低劣内容,AI翻译出来的内容自然会非常差。
这也是为什么我们经常会看到很多参数很小,性能、输出能力却比高参数还强的模型,主要原因之一便是使用了高质量训练数据。
大模型时代,数据为王
正因数据的重要性,高质量的训练数据成为OpenAI、百度、Anthropic、Cohere等厂商必争的宝贵资源,成为大模型时代的“石油”。
早在今年3月,国内还在疯狂炼丹研究大模型时,百度已经率先发布了对标ChatGPT的生成式AI产品——文心一言生。
除了超强的研发能力之外,百度通过搜索引擎积累的20多年庞大的中文语料数据帮了大忙,并在文心一言的多个迭代版本中发挥重要作用,遥遥领先国内其他厂商。
高质量数据通常包括出版书籍、文学作品、学术论文、学校课本、权威媒体的新闻报道、维基百科、百度百科等,经过时间、人类验证过的文本、视频、音频等数据。
但研究机构发现,这类高质量数据的增长非常缓慢。以出版社书籍为例,需要经过市场调研、初稿、编辑、再审等繁琐流程,耗费几个月甚至几年时间才能出版一本书,这种数据产出速度,远远落后大模型训练数据需求的增长。
从大语言模型过去4年的发展趋势来看,其年训练数据量的增速超过了50%。也就是说,每过1年就需要双倍的数据量来训练模型,才能实现性能、功能的提升。
所以,你会看到很多国家、企业严格保护数据隐私以及制定了相关条例,一方面,是保护用户的隐私不被第三方机构搜集,出现盗取、乱用的情况;
另一方面,便是为了防止重要数据被少数机构垄断和囤积,在技术研发时无数据可用。
到2026年,高质量训练数据可能会用光
为了研究训练数据消耗问题,Epochai的研究人员模拟了从2022年—2100年,全球每年产生的语言和图像数据,然后计算这些数据的总量。

又模拟了ChatGPT等大模型对数据的消耗速率。最后,比较了数据增长速度和被消耗的速度,得出了以下重要结论:
在当前大模型的高速发展趋势下, 到2030年—2050年将消耗尽所有低质量数据;高质量数据,极有可能在2026年就会消耗完。
到2030年—2060年,将消耗尽所有图像训练数据;到2040年,由于缺乏训练数据,大模型的功能迭代可能会出现放缓的迹象。
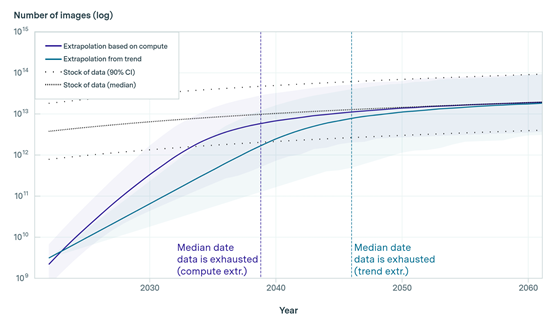
研究人员使用了两个模型进行了计算:第一个模型,通过大语言和图像模型两个领域实际使用的数据集增长趋势,再利用历史统计数据进行外推,预测它们何时会达到消耗峰值和平均消耗。
第二个模型:预测未来每年全球范围内将产生多少新数据。该模型基于三个变量,全球人口数量、互联网普及率和平均每个网民每年产生的数据。
同时研究人员使用联合国数据拟合出人口增长曲线,用一个S型函数拟合互联网使用率,并做出每人每年产数据基本不变的简单假设,三者相乘即可估算全球每年的新数据量。
该模型已经准确预测出Reddit(知名论坛)每个月产出的数据,所以,准确率很高。
最后,研究人员将两个模型进行相结合得出了以上结论。
研究人员表示,虽然这个数据是模拟、估算出来的,存在一定的不确定性。但为大模型界敲响了警钟,训练数据可能很快成为制约AI模型扩展和应用的重要瓶颈。
AI厂商们需要提前布局数据再生、合成的有效方法,避免在发展大模型的过程中出现断崖式数据短缺。
本文素材来源麻省理工科技评论官网、Epochai论文,如有侵权请联系删除