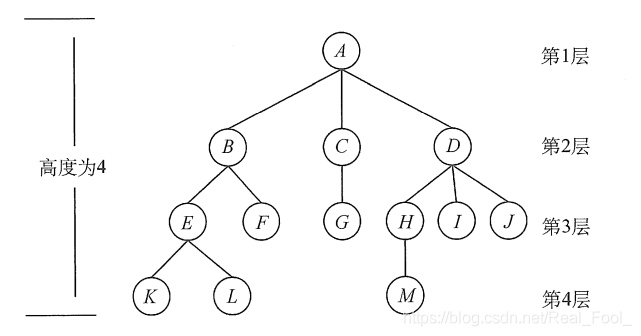
树【Tree】
树是n(n>=0)个结点的有限集。当n = 0时,称为空树。在任意一棵非空树中应满足:
- 有且仅有一个特定的称为根的结点。
- 当n>1时,其余节点可分为m(m>0)个互不相交的有限集T1,T2,…,Tm,其中每个集合本身又是一棵树,并且称为根的子树。
显然,树的定义是递归的,即在树的定义中又用到了自身,树是一种递归的数据结构。树作为一种逻辑结构,同时也是一种分层结构,具有以下两个特点:
- 树的根结点没有前驱,除根结点外的所有结点有且只有一个前驱。
- 树中所有结点可以有零个或多个后继。
因此n个结点的树中有n-1条边。
常用模板
树的运用广泛,除了基本的树外,树的思想也可以经常利用到图等方法中,如回溯算法剪枝算法等都算是树的推广算法
前中后序遍历递归模板
可以适应不同的题目,添加参数、增加返回条件、修改进入递归条件、自定义返回值
class Solution:
def preorderTraversal(self, root: TreeNode) -> List[int]:
def dfs(cur):
if not cur:
return
# 前序递归
res.append(cur.val)
dfs(cur.left)
dfs(cur.right)
# # 中序递归
# dfs(cur.left)
# res.append(cur.val)
# dfs(cur.right)
# # 后序递归
# dfs(cur.left)
# dfs(cur.right)
# res.append(cur.val)
res = []
dfs(root)
return res
回溯算法
# i 和 sum是当前的选择,track 是路径
def backtrack(i,sum,track):
# 路径结束,不满足约束条件
if sum > target or i == n:
return
# 路径结束,满足约束条件
if sum == target:
results.append(track)
return
# 更新选择列表和路径,递归
# 在这个问题中,选择只有两种,是否将当前数字纳入路径
backtrack(i, sum+candidates[i], track+[[candidates[i]])
backtrack(i+1, sum, track)
backtrack(0,0,[])
return results
广度优先遍历
if not root: return []
quene = [root]
ans = []
while quene:
quene_len = len(quene)
# print(quene_len)
temp = []
for i in range(quene_len):
# print(quene_len)
p = quene.pop(0)
temp.append(p.val)
if p.left: quene.append(p.left)
if p.right: quene.append(p.right)
ans.append(temp)
leetcode真题
不同的二叉搜索树 II
给你一个整数 n ,请你生成并返回所有由 n 个节点组成且节点值从 1 到 n 互不相同的不同 二叉搜索树 。可以按 任意顺序 返回答案。

输入:n = 3
输出:[[1,null,2,null,3],[1,null,3,2],[2,1,3],[3,1,null,null,2],[3,2,null,1]]
这道题应该以递归从小解决大的想法去做(题目的实例也提醒了我们可以这么做)
- 确定不同的根结点
- 将根节点左右两边分开成新的子问题,根结点的左边就是左子树,右边就是右子树
- 左子树和右子树重复上述操作
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def generateTrees(self, n: int) -> List[TreeNode]:
def generateTrees(start, end):
if start > end:
return [None,]
allTrees = []
for i in range(start, end + 1): # 枚举可行根节点
# 获得所有可行的左子树集合
leftTrees = generateTrees(start, i - 1)
# 获得所有可行的右子树集合
rightTrees = generateTrees(i + 1, end)
# 从左子树集合中选出一棵左子树,从右子树集合中选出一棵右子树,拼接到根节点上
for l in leftTrees:
for r in rightTrees:
currTree = TreeNode(i)
currTree.left = l
currTree.right = r
allTrees.append(currTree)
return allTrees
return generateTrees(1, n) if n else []
二叉树的中序遍历
给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
输入:root = [1,null,2,3]
输出:[1,3,2]
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def inorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
p = root
ans = []
def tree(p):
if p:
tree(p.left)
ans.append(p.val)
print(p.val)
tree(p.right)
tree(p)
return ans
不同的二叉搜索树
给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树 有多少种?返回满足题意的二叉搜索树的种数。
输入:n = 3
输出:5
这道题考虑动态规划的方法。和II类似,左右子树又可以变成单独的一棵树来思考,那么我们需要的是当前节点数会产生的树,由左子树可能产生的树*右子树可能产生的树。
利用一个数组记录n个节点会产生树的数量
class Solution:
def numTrees(self, n: int) -> int:
dp = [0]*(n+1) # 储存对应n个节点可能会出现的二叉搜索树的数目
dp[0] = 1
dp[1] = 1
# 总结点数
for i in range(2,n+1):
# 左边有多少个节点
for j in range(1,n+1):
dp[i] += dp[j-1]*dp[i-j]
return dp[n]
相同的树
给你两棵二叉树的根节点 p 和 q ,编写一个函数来检验这两棵树是否相同。
如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的
输入:p = [1,2,3], q = [1,2,3]
输出:true
简单的递归和树的判断
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def isSameTree(self, p: Optional[TreeNode], q: Optional[TreeNode]) -> bool:
def df(cur1,cur2):
# 如果两边都为null,就证明遍历到底了,合格
if not cur1 and not cur2:
return True
# 如果只有一边为null,就不行
elif not cur1 or not cur2:
return False
# 如果都不为null,但不相等
elif cur1.val != cur2.val:
return False
# 没遍历到最后继续遍历
else:
return df(cur1.left,cur2.left) and df(cur1.right,cur2.right)
# return and
return df(p,q)
对称二叉树
给你一个二叉树的根节点 root , 检查它是否轴对称。
输入:root = [1,2,2,3,4,4,3]
输出:true
这道题其实是相同树的变式,主要是将左右子树分开,判断他们是否对称
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def isSymmetric(self, root: Optional[TreeNode]) -> bool:
def df(p1,p2):
if not p1 and not p2:
return True
elif not p1 or not p2:
return False
elif p1.val != p2.val:
return False
else:
return df(p1.left,p2.right) and df(p1.right,p2.left)
return df(root.left,root.right)
二叉树的层序遍历
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
输入:root = [3,9,20,null,null,15,7]
输出:[[3],[9,20],[15,7]]
经典的广度优先遍历
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def levelOrder(self, root: Optional[TreeNode]) -> List[List[int]]:
if not root: return []
quene = [root]
ans = []
while quene:
quene_len = len(quene)
# print(quene_len)
temp = []
for i in range(quene_len):
# print(quene_len)
p = quene.pop(0)
temp.append(p.val)
if p.left: quene.append(p.left)
if p.right: quene.append(p.right)
ans.append(temp)
return ans
二叉树的锯齿形层序遍历
给你二叉树的根节点 root ,返回其节点值的 锯齿形层序遍历 。(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行)。
输入:root = [3,9,20,null,null,15,7]
输出:[[3],[20,9],[15,7]]
上一题的变式,可以在原基础上,加上一个flat阀开关改变层级方向
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def zigzagLevelOrder(self, root: Optional[TreeNode]) -> List[List[int]]:
if not root: return []
quene = [root]
ans = []
flat = 1
while quene:
quene_len = len(quene)
# print(quene_len)
temp = []
for i in range(quene_len):
# print(quene_len)
p = quene.pop(0)
temp.append(p.val)
if p.left: quene.append(p.left)
if p.right: quene.append(p.right)
if flat == -1:
temp = temp[::-1]
ans.append(temp)
flat = -flat
return ans
二叉树的最大深度
给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
说明: 叶子节点是指没有子节点的节点。
很简单的深度遍历即可解决,注意我们每一层的递归需要返回左子树和右子树中最大深度值,如果他是叶子节点就是1嘛
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def maxDepth(self, root: Optional[TreeNode]) -> int:
if not root :return 0
def df(p):
# print(p.val,depth)
left_depth,right_depth = 0,0
if p.left: left_depth = df(p.left)
if p.right: right_depth = df(p.right)
return max(left_depth,right_depth)+1
return df(root)
从前序与中序遍历序列构造二叉树
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
输入: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
输出: [3,9,20,null,null,15,7]
先序遍历的特点:
- 左边第一个是根节点
中序遍历特点:
- 根据先序遍历确定的根节点判断左子树的先序遍历和中序遍历与右子树的先序遍历和中序遍历
递归
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def buildTree(self, preorder: List[int], inorder: List[int]) -> Optional[TreeNode]:
if not preorder and not inorder:
return None
# 根据先序遍历获得的根节点
root = TreeNode(preorder[0])
root_idx = inorder.index(preorder[0])
# 左右子树的中序遍历
left_inorder = inorder[0:root_idx]
right_inorder = inorder[root_idx+1:]
# print(left_inorder,right_inorder)
# 左右子树的先序遍历
left_preorder = preorder[1:len(left_inorder)+1]
right_preorder = preorder[len(left_inorder)+1:]
# print(left_preorder,right_preorder)
root.left = self.buildTree(left_preorder,left_inorder)
root.right = self.buildTree(right_preorder,right_inorder)
return root
从中序与后序遍历序列构造二叉树
给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历,postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
输入:inorder = [9,3,15,20,7], postorder = [9,15,7,20,3]
输出:[3,9,20,null,null,15,7]
与上题类似
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def buildTree(self, inorder: List[int], postorder: List[int]) -> Optional[TreeNode]:
if len(postorder) == 0:
return None
root = TreeNode(postorder[-1])
# 节省空间
if len(postorder) == 1:
return root
index_root = inorder.index(root.val)
# 左右子树的中序遍历
inorder_left, inorder_right = inorder[: index_root], inorder[index_root+1:]
# 左右子树的后续遍历
post_left, post_right = postorder[0: len(inorder_left)], postorder[-len(inorder_right)-1: -1]
# 递归
root.left, root.right = self.buildTree(inorder_left, post_left), self.buildTree(inorder_right, post_right)
return root
将有序数组转换为二叉搜索树
给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 高度平衡 二叉搜索树。
高度平衡 二叉树是一棵满足「每个节点的左右两个子树的高度差的绝对值不超过 1 」的二叉树
输入:nums = [-10,-3,0,5,9]
输出:[0,-3,9,-10,null,5]
解释:[0,-10,5,null,-3,null,9] 也将被视为正确答案:
已经排好序了,简单的递归
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def sortedArrayToBST(self, nums: List[int]) -> Optional[TreeNode]:
if len(nums) < 1:
return None
mid = int(len(nums)/2)
root = TreeNode(nums[mid])
left_nums = nums[:mid]
right_nums = nums[mid+1:]
root.left = self.sortedArrayToBST(left_nums)
root.right = self.sortedArrayToBST(right_nums)
return root
求根节点到叶节点数字之和
给你一个二叉树的根节点 root ,树中每个节点都存放有一个 0 到 9 之间的数字。
每条从根节点到叶节点的路径都代表一个数字:
- 例如,从根节点到叶节点的路径
1 -> 2 -> 3表示数字123。
计算从根节点到叶节点生成的 所有数字之和 。
叶节点 是指没有子节点的节点。
输入:root = [1,2,3]
输出:25
解释:
从根到叶子节点路径 1->2 代表数字 12
从根到叶子节点路径 1->3 代表数字 13
因此,数字总和 = 12 + 13 = 25
十分熟悉的回溯算法哈哈哈,树就是一个最常见的回溯剪枝
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def sumNumbers(self, root: Optional[TreeNode]) -> int:
res = 0
def dfs(root,val):
nonlocal res
if not root:
return
if not root.left and not root.right:
print(val)
res += int(''.join(map(str,val)))
if root.left:
dfs(root.left,val + [root.left.val])
if root.right:
dfs(root.right,val + [root.right.val])
dfs(root,[root.val])
return res
二叉树的最近公共祖先
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出:3
解释:节点 5 和节点 1 的最近公共祖先是节点 3 。
这题我承认是我菜了,我起初的想法是利用两次回溯剪枝,找到两条出现target的线路,开始出现不重复的元素的上一个点就是公共祖先,按原理是可行的,但是太复杂了,下面看看别人的解法吧
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode':
# 当前节点为空,直接返回空
if root == None:
return None
# 如果 root 等于 p 或者 q,那最近公共祖先一定是 p 或者 q
if root == p or root == q:
return root
# 递归左右子树,保存递归结果,直至找到满足其中一个target或者是叶子节点
left = self.lowestCommonAncestor(root.left, p, q)
right = self.lowestCommonAncestor(root.right, p, q)
# 如果 left 和 right 都非空,那证明 p 和 q 一边一个,那么最近公共祖先就是 root
if left and right:
return root
# 如果 right 为空,只需要看 left
if left and right == None:
return left
# 如果 left 为空,只需要看 right
if left == None and right:
return right
# 如果都为空,返回空
if left == None and right == None:
return None
二叉树最大宽度
给你一棵二叉树的根节点 root ,返回树的 最大宽度 。
树的 最大宽度 是所有层中最大的 宽度 。
每一层的 宽度 被定义为该层最左和最右的非空节点(即,两个端点)之间的长度。将这个二叉树视作与满二叉树结构相同,两端点间会出现一些延伸到这一层的 null 节点,这些 null 节点也计入长度。
题目数据保证答案将会在 32 位 带符号整数范围内。
输入:root = [1,3,2,5,3,null,9]
输出:4
解释:最大宽度出现在树的第 3 层,宽度为 4 (5,3,null,9)
最大宽度,我们应该想到的是广度优先遍历。但如何计算他的宽度呢,这时我们需要为每一个节点给予一个序号,最后我们只需要记录每一层队首和队尾序号的距离,然后取最大值即可
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def widthOfBinaryTree(self, root: Optional[TreeNode]) -> int:
if not root: return []
quene = [[root,1]]
res = 1
ans = []
while quene:
quene_len = len(quene)
# print(quene_len)
temp = []
for i in range(quene_len):
# print(quene_len)
p = quene.pop(0)
temp.append([p[0].val,p[1]])
if p[0].left: quene.append([p[0].left,p[1]*2])
if p[0].right: quene.append([p[0].right,p[1]*2+1])
res = max(temp[-1][-1] - temp[0][-1] + 1 ,res)
ans = temp
print(ans)
return res
两棵二叉搜索树中的所有元素
给你 root1 和 root2 这两棵二叉搜索树。请你返回一个列表,其中包含 两棵树 中的所有整数并按 升序 排序。.
输入:root1 = [2,1,4], root2 = [1,0,3]
输出:[0,1,1,2,3,4]
中序遍历+排序
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def getAllElements(self, root1: TreeNode, root2: TreeNode) -> List[int]:
res = []
def dfs(root):
if not root:
return
dfs(root.left)
print(root.val)
res.append(root.val)
dfs(root.right)
dfs(root1)
dfs(root2)
res.sort()
return res
验证二叉搜索树
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
有效 二叉搜索树定义如下:
- 节点的左子树只包含 小于 当前节点的数。
- 节点的右子树只包含 大于 当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
输入:root = [5,1,4,null,null,3,6]
输出:false
解释:根节点的值是 5 ,但是右子节点的值是 4 。
输入:root = [2,1,3]
输出:true
方法一(简单的运用大小值和递归法):作者第一次就用的这种方法
class Solution:
def isValidBST(self, root: Optional[TreeNode]) -> bool:
def isValid(node,maxs = None,mins = None):
if node == None: return True # 如果是叶子节点就证明判断结束了
if mins != None and mins >= node.val: return False # 如果有最小值,但这个最小值不是最小值就出问题了
if maxs != None and maxs <= node.val: return False # 如果有最大值,但这个最大值不是最大值也是有问题
return isValid(node.left, node.val, mins) and isValid(node.right, maxs, node.val) # 左右子树递归下去直到是叶子节点为止
return isValid(root) # 返回函数结果
方法二(因为题目给出的前序遍历,转成中序遍历后,如果是递增的就满足二叉搜索数的性质)
class Solution:
def isValidBST(self, root: Optional[TreeNode]) -> bool:
mid = []
def dfs(cur):
if not cur: return
dfs(cur.left)
mid.append(cur.val)
dfs(cur.right)
dfs(root)
print(mid)
for item in range(1,len(mid)):
if mid[item] <= mid[item-1]: return False
return True
路径总和
给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。
叶子节点 是指没有子节点的节点。
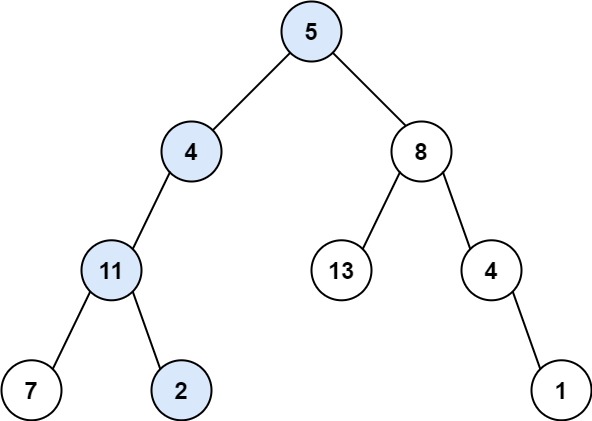
输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22
输出:true
解释:等于目标和的根节点到叶节点路径如上图所示。
这道题可以利用简单的回溯做,但需要注意一下几点
- 一定要是叶子节点,才能算做完整路径总和
- 注意如果targetSum为0,所以初始条件不能设置为0
- 可以采用减法的方式,一层一层减少targetSum
不断变化root和targetSum递归最终得到结果
class Solution:
def hasPathSum(self, root: Optional[TreeNode], targetSum: int) -> bool:
def dfs(cur,target):
if not cur : return False
if not cur.left and not cur.right:
return target == cur.val
return dfs(cur.left,target-cur.val) or dfs(cur.right,target-cur.val)
return dfs(root,targetSum)
路径总和 II
给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。
叶子节点 是指没有子节点的节点。
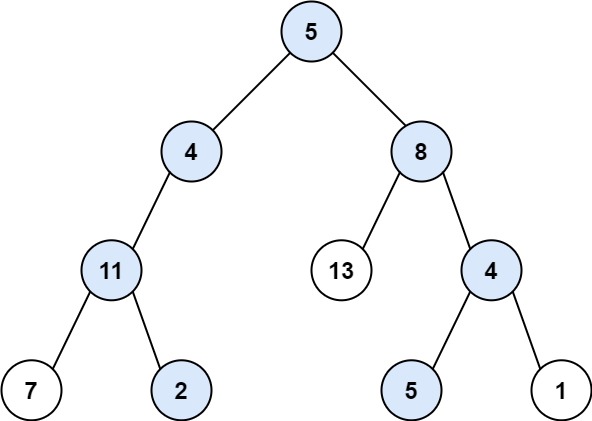
输入:root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22
输出:[[5,4,11,2],[5,8,4,5]]
本题与上一题类似,需要的是将原来的成功条件处,记录路径即可
class Solution:
def pathSum(self, root: Optional[TreeNode], targetSum: int) -> List[List[int]]:
result = []
def dfs(cur,target,path):
if not cur : return
if not cur.left and not cur.right and target == cur.val:
# print(path.copy().append(cur.val))
temp = path.copy()
temp.append(cur.val)
result.append(temp)
path.append(cur.val)
dfs(cur.left,target-cur.val,path)
dfs(cur.right,target-cur.val,path)
path.pop()
path = []
dfs(root,targetSum,path)
return result
二叉树展开为链表
给你二叉树的根结点 root ,请你将它展开为一个单链表:
- 展开后的单链表应该同样使用 TreeNode ,其中 right 子指针指向链表中下一个结点,而左子指针始终为 null 。
- 展开后的单链表应该与二叉树 先序遍历 顺序相同。
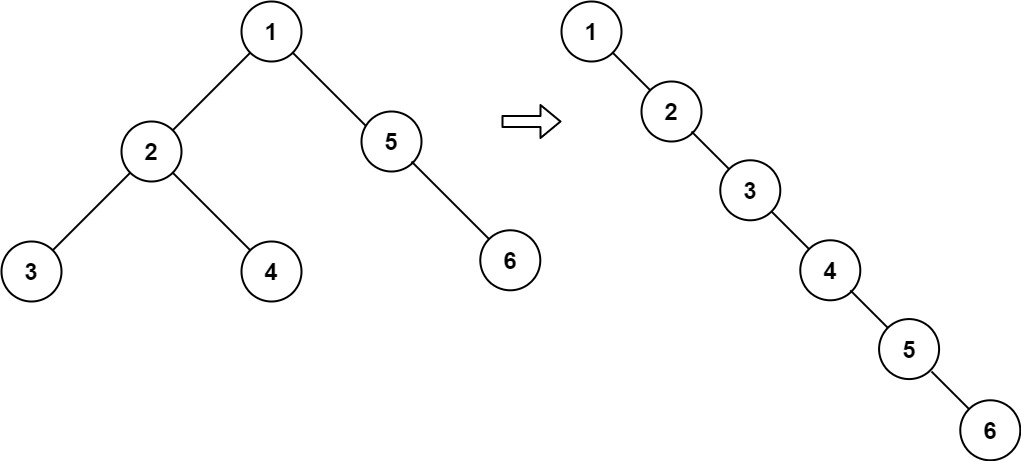
输入:root = [1,2,5,3,4,null,6]
输出:[1,null,2,null,3,null,4,null,5,null,6]
储存前序遍历的结果,直接根据前序遍历的顺序修改每一个节点的左右节点
class Solution:
def flatten(self, root: Optional[TreeNode]) -> None:
"""
Do not return anything, modify root in-place instead.
"""
l = []
def dfs(cur):
if not cur:return
# print(cur.val)
l.append(cur)
dfs(cur.left)
dfs(cur.right)
dfs(root)
for i in range(1,len(l)):
prev, curr = l[i-1], l[i]
prev.right = curr
prev.left = None
二叉树中的最大路径和
路径 被定义为一条从树中任意节点出发,沿父节点-子节点连接,达到任意节点的序列。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。
路径和 是路径中各节点值的总和。
给你一个二叉树的根节点 root ,返回其 最大路径和 。
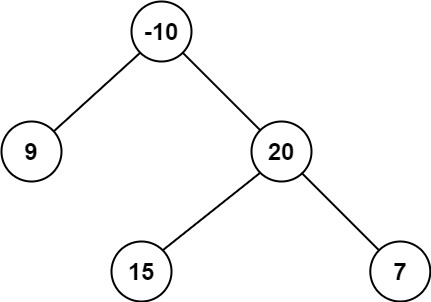
输入:root = [-10,9,20,null,null,15,7]
输出:42
解释:最优路径是 15 -> 20 -> 7 ,路径和为 15 + 20 + 7 = 42

class Solution:
def __init__(self):
self.maxSum = float("-inf")
def maxPathSum(self, root: Optional[TreeNode]) -> int:
def dfs(cur):
# 如果为空就当作0
if not cur: return 0
# 如果左子树的递归结果对路径和起副作用,就设置为0
left = max(0,dfs(cur.left))
# 如果右子树的递归结果对路径和起副作用,就设置为0
right = max(0,dfs(cur.right))
# 路径和就等于左子树+右子树有效路径+当前数值的总和
mid = left + right + cur.val
# 更新最大路径值
self.maxSum = max(self.maxSum, mid)
# 选择一边作为作用最大的值
return cur.val + max(left,right)
dfs(root)
return self.maxSum
最大二叉树
给定一个不重复的整数数组 nums 。 最大二叉树 可以用下面的算法从 nums 递归地构建:
- 创建一个根节点,其值为 nums 中的最大值。
- 递归地在最大值 左边 的 子数组前缀上 构建左子树。
- 递归地在最大值 右边 的 子数组后缀上 构建右子树。
返回 nums 构建的 最大二叉树 。
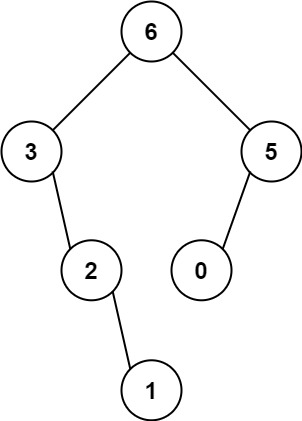
输入:nums = [3,2,1,6,0,5]
输出:[6,3,5,null,2,0,null,null,1]
解释:递归调用如下所示:
- [3,2,1,6,0,5] 中的最大值是 6 ,左边部分是 [3,2,1] ,右边部分是 [0,5] 。
- [3,2,1] 中的最大值是 3 ,左边部分是 [] ,右边部分是 [2,1] 。
- 空数组,无子节点。
- [2,1] 中的最大值是 2 ,左边部分是 [] ,右边部分是 [1] 。
- 空数组,无子节点。
- 只有一个元素,所以子节点是一个值为 1 的节点。
- [0,5] 中的最大值是 5 ,左边部分是 [0] ,右边部分是 [] 。
- 只有一个元素,所以子节点是一个值为 0 的节点。
- 空数组,无子节点。
直接递归解决问题
class Solution:
def constructMaximumBinaryTree(self, nums: List[int]) -> Optional[TreeNode]:
if not nums:
return None
cur = max(nums)
i = nums.index(cur)
node = TreeNode(cur)
node.left = self.constructMaximumBinaryTree(nums[:i])
node.right = self.constructMaximumBinaryTree(nums[i+1:])
return node
二叉搜索树中的插入操作
给定二叉搜索树(BST)的根节点 root 和要插入树中的值 value ,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。 输入数据 保证 ,新值和原始二叉搜索树中的任意节点值都不同。
注意,可能存在多种有效的插入方式,只要树在插入后仍保持为二叉搜索树即可。 你可以返回 任意有效的结果 。
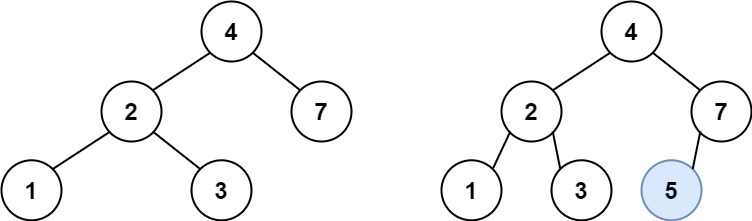
输入:root = [4,2,7,1,3], val = 5
输出:[4,2,7,1,3,5]
根据值的大小分到左右子树,找到叶子节点后插入
class Solution:
def insertIntoBST(self, root: Optional[TreeNode], val: int) -> Optional[TreeNode]:
if not root:
return TreeNode(val)
cur = root
while cur:
if val < cur.val:
if not cur.left:
cur.left = TreeNode(val)
break
else:
cur = cur.left
else:
if not cur.right:
cur.right = TreeNode(val)
break
else:
cur = cur.right
return root
组合总和
给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。
candidates 中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。
对于给定的输入,保证和为 target 的不同组合数少于 150 个。
输入:candidates = [2,3,6,7], target = 7
输出:[[2,2,3],[7]]
解释:
2 和 3 可以形成一组候选,2 + 2 + 3 = 7 。注意 2 可以使用多次。
7 也是一个候选, 7 = 7 。
仅有这两种组合。
回溯算法直接秒杀
class Solution:
def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:
ans, path = [], []
def dfs(arr,target,path):
if sum(path) == target:
temp = path.copy()
temp.sort()
if temp not in ans: ans.append(temp)
return
elif sum(path) > target:
return
else:
for i in arr:
path.append(i)
dfs(arr,target,path)
path.pop()
dfs(candidates,target,path)
print(ans)
return ans
组合总和 II
给定一个候选人编号的集合 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的每个数字在每个组合中只能使用 一次 。
注意:解集不能包含重复的组合。
输入: candidates = [10,1,2,7,6,1,5], target = 8,
输出:
[
[1,1,6],
[1,2,5],
[1,7],
[2,6]
]
这道题与上一题的区别是:
- candidates中的元素不唯一;
- 每个元素仅能使用一次
class Solution:
def combinationSum2(self, candidates: List[int], target: int) -> List[List[int]]:
def dfs(begin, path, residue):
if residue == 0:
res.append(path[:])
return
for index in range(begin, size):
# 当前的值超过了剩余的值,加上会超过target,就不要了,而因为经过了排序,他后面的也不要了,所以break
if candidates[index] > residue:
break
# 跳过重复值
if index > begin and candidates[index - 1] == candidates[index]:
continue
# 因为每个元素只能用一次,所以记录用用过的往后的就行
path.append(candidates[index])
dfs(index + 1, path, residue - candidates[index])
path.pop()
size = len(candidates)
if size == 0:
return []
candidates.sort()
res = []
dfs(0, [], target)
return res
下面是根据上一题的结果改版的版本
class Solution:
def combinationSum2(self, candidates: List[int], target: int) -> List[List[int]]:
ans, path = [], []
def dfs(arr,target,path):
if sum(path) == target:
if path not in ans: ans.append(path[:]) # path[:]同样起到copy的作用
return
else:
for i in range(len(arr)):
if arr[i] + sum(path) > target:
break
if i > 0 and arr[i-1] == arr[i]:
continue
path.append(arr[i])
dfs(arr[i+1:],target,path)
path.pop()
candidates.sort()
dfs(candidates,target,path)
print(ans)
return ans
全排列
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
target = len(nums)
ans = list()
def dfs(nums,path):
if len(path) == target:
ans.append(path[:])
return
for i,item in enumerate(nums):
path.append(item)
dfs(nums[:i]+nums[i+1:],path)
path.pop()
dfs(nums,[])
return ans
全排列 II
给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
输入:nums = [1,1,2]
输出:
[[1,1,2],
[1,2,1],
[2,1,1]]
直接path not in ans保证了不会出现了重复值,但这个效率比较低
class Solution:
def permuteUnique(self, nums: List[int]) -> List[List[int]]:
target = len(nums)
ans = list()
def dfs(nums,path):
if len(path) == target and path not in ans:
ans.append(path[:])
return
for i,item in enumerate(nums):
path.append(item)
dfs(nums[:i]+nums[i+1:],path)
path.pop()
dfs(nums,[])
return ans
因为是为了防止重复值,所以可以在for中加入这个条件if i > 0 and arr[i-1] == arr[i]:continue这样就跳过了重复值导致的重复结果,效率高一些
class Solution:
def permuteUnique(self, nums: List[int]) -> List[List[int]]:
if not nums: return []
nums.sort()
res = []
def backtrack(nums, tmp):
if not nums:
res.append(tmp[:])
return
for i in range(len(nums)):
if i > 0 and nums[i] == nums[i - 1]:
continue
backtrack(nums[:i] + nums[i + 1:], tmp + [nums[i]])
backtrack(nums, [])
return res
字符串的排列
输入一个字符串,打印出该字符串中字符的所有排列。
你可以以任意顺序返回这个字符串数组,但里面不能有重复元素。
输入:s = "abc"
输出:["abc","acb","bac","bca","cab","cba"]
此题与上一题有异曲同工之妙
class Solution:
def permutation(self, s: str) -> List[str]:
s = list(s)
if not s: return []
s.sort()
res = []
def backtrack(nums, tmp):
if not nums:
res.append(''.join(tmp[:]))
return
for i in range(len(nums)):
if i > 0 and nums[i] == nums[i - 1]:
continue
backtrack(nums[:i] + nums[i + 1:], tmp + [nums[i]])
backtrack(s, [])
return res
字符串的排列
输入一个字符串,打印出该字符串中字符的所有排列。
你可以以任意顺序返回这个字符串数组,但里面不能有重复元素。
输入:s = "abc"
输出:["abc","acb","bac","bca","cab","cba"]
此题与上一题有异曲同工之妙
class Solution:
def permutation(self, s: str) -> List[str]:
s = list(s)
if not s: return []
s.sort()
res = []
def backtrack(nums, tmp):
if not nums:
res.append(''.join(tmp[:]))
return
for i in range(len(nums)):
if i > 0 and nums[i] == nums[i - 1]:
continue
backtrack(nums[:i] + nums[i + 1:], tmp + [nums[i]])
backtrack(s, [])
return res