这里写目录标题
- 深度学习之前的网络
- AlexNet
- AlexNet得到了竞赛冠军
- AlexNet架构
- Alex net更多细节
- 数据增强
- VGG
- NiN
- 知识补充
- flop
- 暂退法 drop_out
深度学习之前的网络
1、核方法
机器学习
SVM现在还是很广泛的使用,因为对调参的需求不那么大,对调参不太敏感
特征抽取
卷积神经网络 通常运用在图片上,
计算机视觉问题 描述成几何问题,从几何学而来
计算机视觉中 曾见最重要的是特征工程
如果特征抽取的好,直接用简单的多分类模型SVM
硬件的发展趋势
样本大小,内存,CPU
内存放不下数据集
计算能力 增长速度大于 数据集的增长速度,构造更深的神经网络,算力换精度
因为采用随机梯度下降,内存要求不那么高
Min list手写数字识别
imageNet
AlexNet
AlexNet得到了竞赛冠军
1、丢弃法 模型的控制
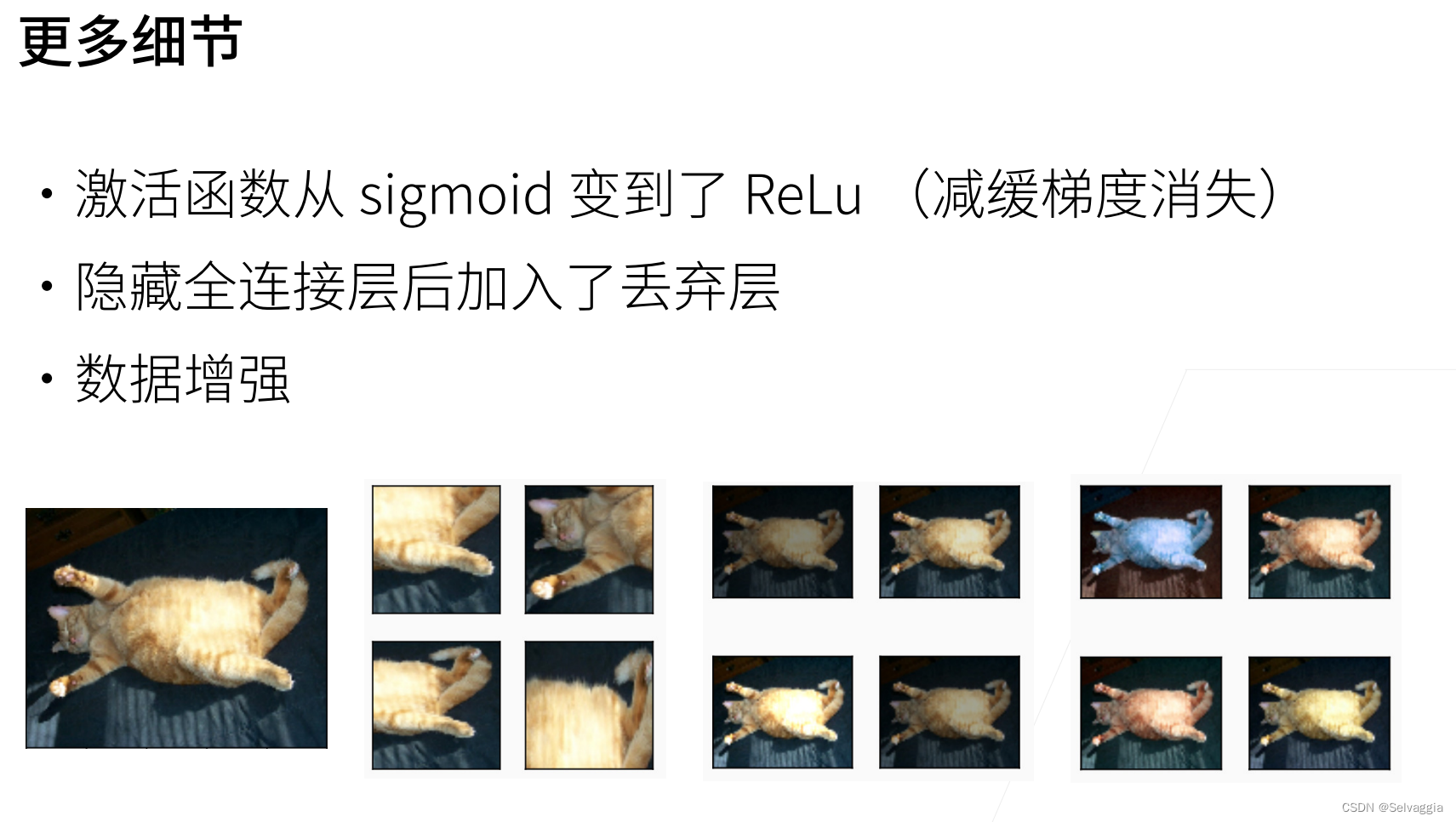
2、letnet激活函数由sigmoid换成relu之后,效果有提升(从数值稳定性来理解,relu算梯度快,而且不容易出现梯度消失和梯度爆炸的现象)
相比于lenet的average pooling,这里用maxpooling,使得输出值更大,梯度相对更大,训练比较容易一点
不仅更大更深,观念上的改变
之前的传统机器学习:人工特征提取和SVM相当于分开的两个过程
现在的AlexNet分类器和CNN一起训练,CNN学到的很可能就是分类器想要的
构造CNN相对简单,不需要太多计算机视觉相关的知识来进行人工特征提取
端到端的学习,原始的序列到最后的结果
AlexNet架构
卷积层
图片变大,需要更大的核窗口
输出通道数变大,6变成96,图片模式比较多需要去识别
stride够大,减轻计算负担
池化层
池化窗口也稍稍增大
conv是重叠的,pool不重叠
**pad=1,输入和输出的尺寸是一样的??输入和输出得高宽是一样的 **
都是两个隐藏层
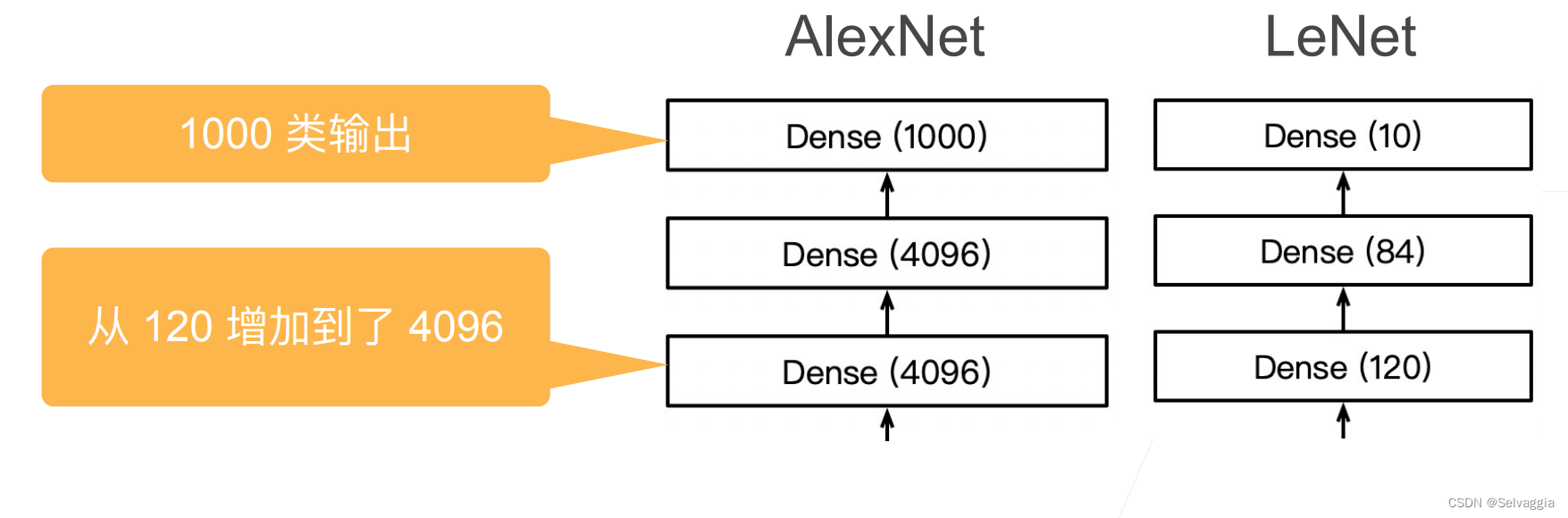
Dense层就是所谓的全连接神经网络?就是全连接层
稠密层,也称全连接层,就是把特征提取成一维帮助最后分类
Alex net更多细节
加入dropout层做模型的正则化??
数据增强
随机截取一块,调整亮度,对原始图片基础上增加一些变种
VGG
不规则,变大的lenet但是变大得很随意,这里加一点那里加一点
需要更好的设计思想,框架更加regular一些

占内存,计算量大不便宜
不规则
组成卷积块,再把卷积块拼上去
VGG就是模块化得Alexnet,用块的方式使代码变得很简洁
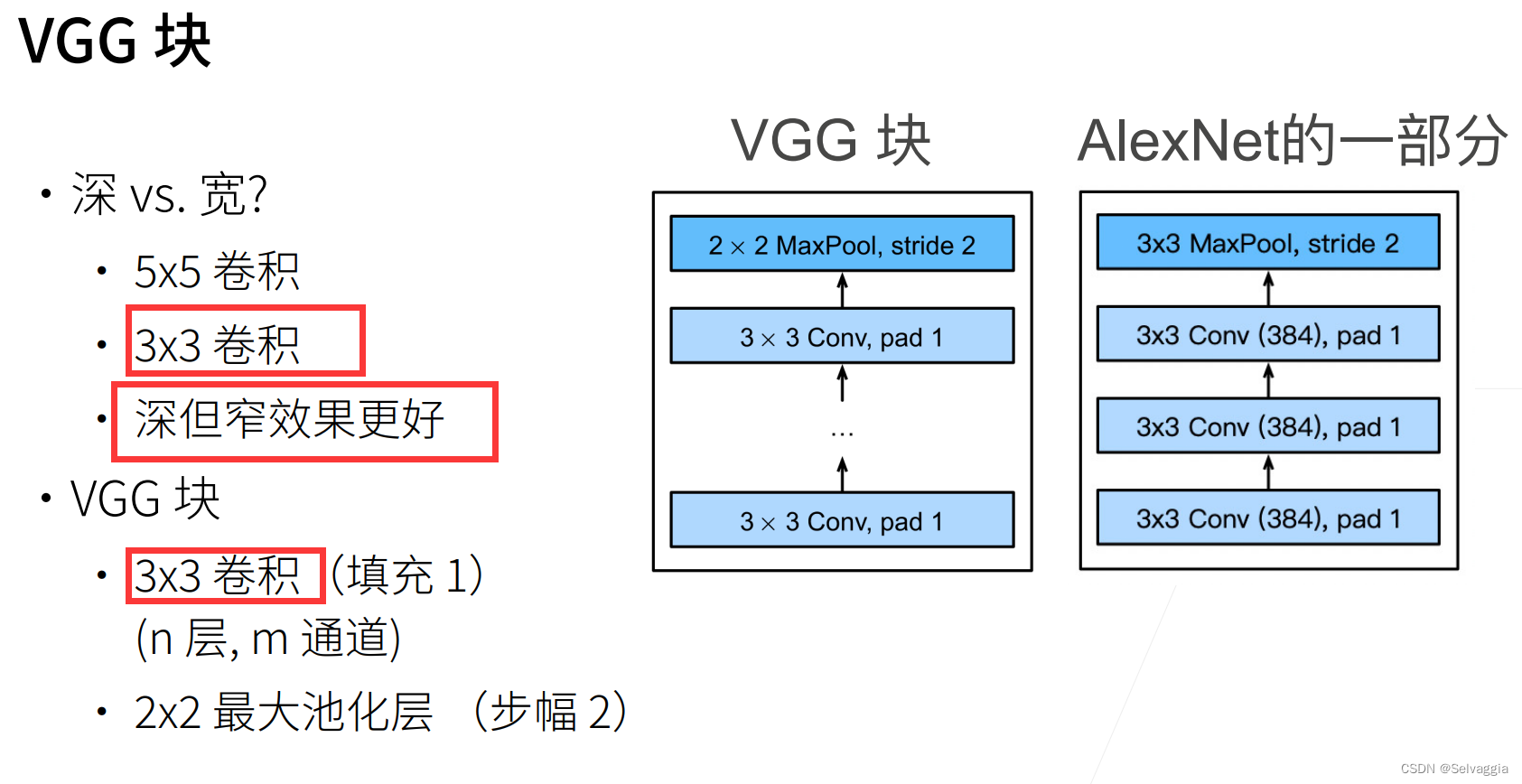
选择3*3,神但是窄,效果更好
替换成n个重复的VGG块
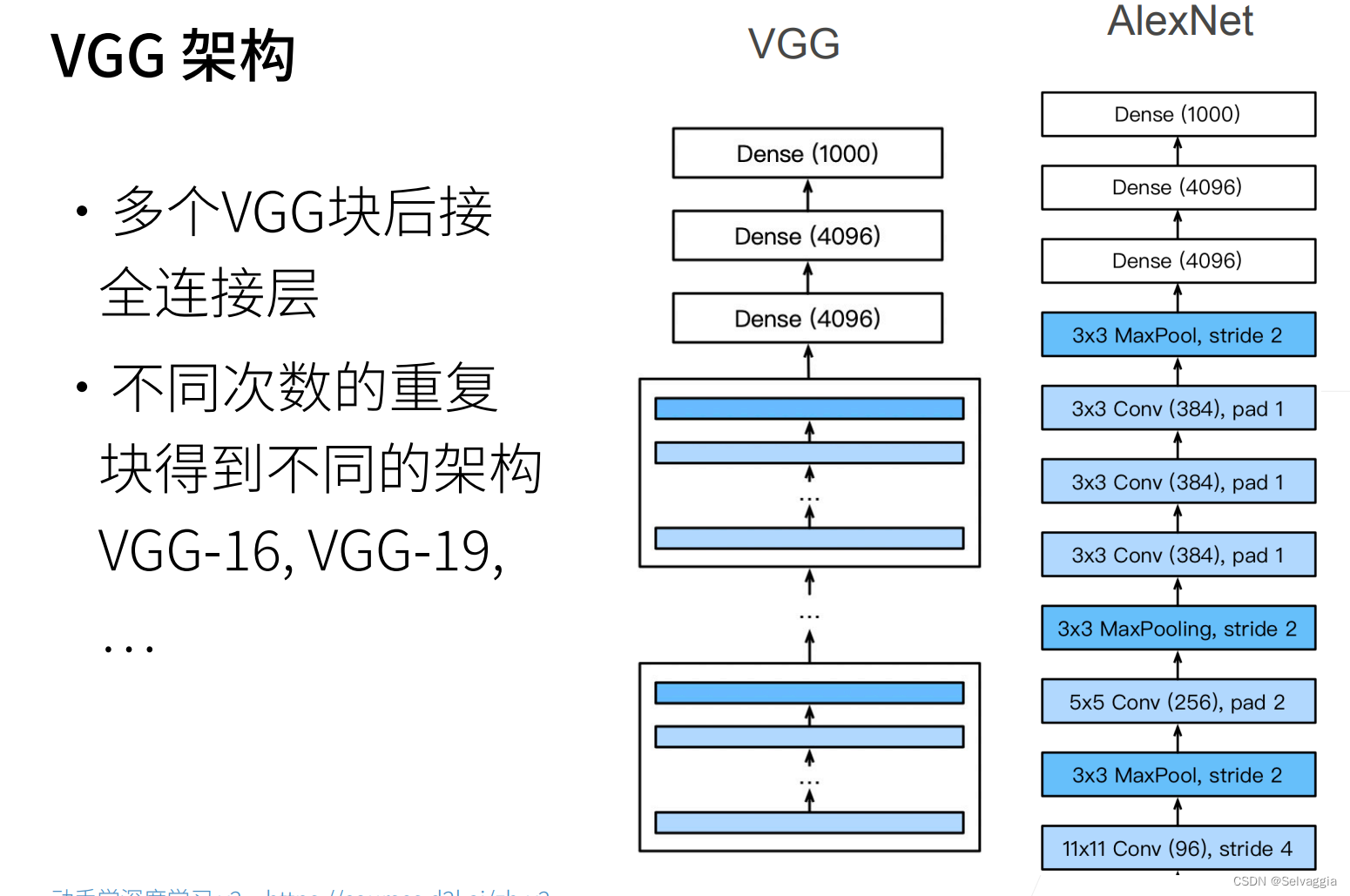
11,16,19指的是 含有可训练参数的层的总数,也就是不包括激活层,池化层这种不含训练参数的层
NiN
知识补充
flop
(Floating Point Operations Per Second,浮点操作/秒)计算CPU浮点能力的一个单位
暂退法 drop_out
Dropout具体工作流程
假设我们要训练这样一个神经网络,如图2所示。
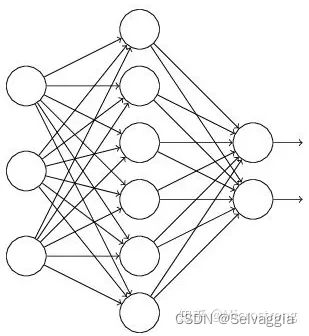
输入是x输出是y,正常的流程是:我们首先把x通过网络前向传播,然后把误差反向传播以决定如何更新参数让网络进行学习。使用Dropout之后,过程变成如下:
(1)首先 随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变(图3中虚线为部分临时被删除的神经元)
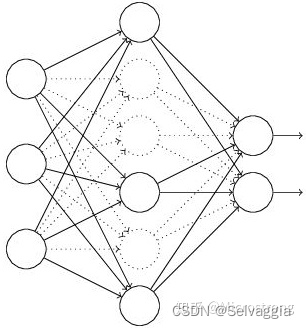
(2) 然后把输入x通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b)。
(3)然后继续重复这一过程:
恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新)
从隐藏层神经元中随机选择一个一半大小的子集临时删除掉(备份被删除神经元的参数)。
对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b) (没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)。
不断重复这一过程。
深度学习中Dropout原理解析







![[python]离线加载fetch_20newsgroups数据集](https://img-blog.csdnimg.cn/5e92a81936fc410ba62a8449b748ddba.png)