前言
年底了,整理了下过去做的一些项目,希望能够给大数据行业的同学提供些大数据平台建设的思路。内容大致分五部分:数据采集,数据存储、数据计算、基础平台以及数据治理篇。由于涉及到的内容较多,打算分成两篇文章,本文主要介绍前四部分,也就是大数据平台相关。文章以介绍思路为主,部分技术细节可以参照文章的链接(后续会逐步完善)。
先来看下整体的大数据架构图:

数据采集篇
我们的数据来源主要有三部分:业务数据库,后端日志、客户端/前端日志。这三种数据我们都采用实时处理的方式进行入仓。接下来一起看下不同数据源我们是如何处理的。
业务库数据
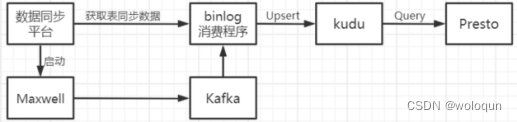
业务数据库中的数据,我们使用自研的binlog消费工具实时同步到kudu表中。在同步数据之前,我们需要将业务数据库的连接信息(地址,用户,密码)维护到数据同步平台,并创建maxwell实例监听业务库的binlog,并将数据投递到Kafka中。
在这些工作准备就绪后,接下来就是在数据同步平台选择需要同步表。依次选取数据源,库名、表名、字段列表以及字段的处理方式(脱敏,转换)、唯一主键以及是否需要初始化。选择初始化,会将对历史数据进行同步,不初始化则同步增量数据。
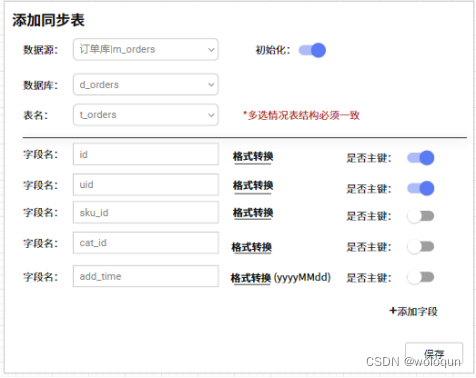
信息保存后,数据平台会按照固定模板自动创建kudu表。除此之外,对于业务库中分表的情况,我们可以选择将多张表合并写入同一张kudu表中,其中表名将当成主键的一部分。
binlog实时消费程序会根据数据平台记录的同步策略,将binlog实时同步到kudu中的表。这些kudu表将被当成数仓ods层的一部分,presto将直接连接kudu进行读取。
客户端/前端日志
客户端/前端上报的日志从业务用途大致可以分为两大类:用户行为日志,基础性能日志。
用户行为日志:主要包含用户主动触发的一些数据,这类数据也是最具业务价值的核心数据。例如:点击,曝光,时长,浏览等。业务分析人员通过这些数据对用户行为进行挖掘分析,进而优化产品设计,提升产品与用户的交互效率。当然业务分析人员在使用这些数据之前,需要数据开发预先对数据的清洗、建模。
基础性能日志:这类数据主要辅助研发定位问题的基础日志,跟业务本身没有相关性。包括一些错误日志,性能监控日志等。
业务行为日志通常结构比较复杂,有统一的上报格式,并且数据的结构描述等元数据信息维护在埋点平台。而基础性能日志则没有固定格式,通常就是一个json字符串,我们也不会去维护它的元数据信息。
(埋点平台设计链接待补充)
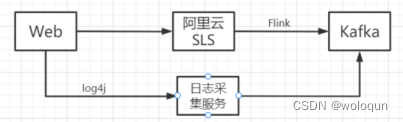
对于客户端/前端上报的日志,我们有统一的收集服务logcollector。一份新的日志上报,我们需要在日志采集服务里进行注册,录入的信息包括:日志标识、描述、负责人,邮件、监控阈值等信息。日志采集服务会根据日志标识在kafka中创建对应的topic,并且生成日志上报接口地址。除此之外,日志采集服务还提供了通用的监控看板,并且支持异常监控报警。

后端日志
早期后端日志通过在各个后端节点部署filebeat,统一上报到kafka。随着后端服务的拆分并且容器化部署后。后端的日志统一通过阿里云的日志服务SLS收集。数据开发同学使用Flink实时消费并转投到kafka中,也有部分后端日志通过log4j的方式投递到自研的数据采集服务logcollector中。
数据存储篇
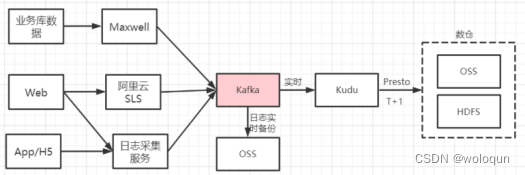
目前我们使用的数据存储大致有四种,分别是:Kafka,HDFS,OSS,Kudu。
从数据采集章节,我们可以知道所有采集到的数据都会流向Kafka,而Kafka作为数据总线,是数据流入大数据平台的第一个关卡。通常我们会使用Flink将数据进行实时清洗并写入kudu中,然后通过presto 以T+1的方式写入到HDFS或者OSS中,kudu作为数据清洗的中间存储,通常我们会保留最近7天的数据。除此之外,kudu还能满足一些分钟甚至秒级别的实时olap查询场景。kafka中的数据除了实时清洗写入到kudu外,我们还会实时备份到OSS中。
早期我们的数仓最开始是基于HDFS搭建的,随着业务的发展,现有的大数据平台(CDH)在数据量,用户激增的环境下,由于存储和计算耦合,很难做到低成本的按需扩容的。随着共有云的大数据解决方案不断涌现,存算分离已经是一个比较成熟的方案。基于此背景,我们调研了市面上主流的公有云存储方案,经过多方面考量,我们最终选择了阿里云的OSS,并在OSS上搭建了数仓。从HDFS迁移到到OSS,存储成本下降了70%+。
数据计算篇
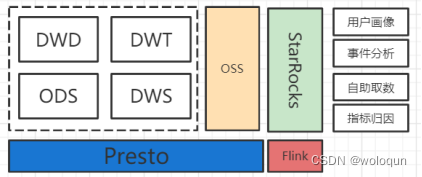
我们使用的计算引擎和绝大部分公司都差不多。离线计算方面,除了部分特征处理的任务采用Spark外,90%以上的离线任务都是使用Presto执行。实时计算统一使用的Flink。除此之外我们还引入了Starrocks,充当数仓加速层。接下来主要介绍Presto,Flink,Starrocks的使用方式及场景。
Presto是一个开源的基于内存的分布式SQL查询引擎,是我们数据平台最核心的计算引擎,数据平台的基础建设也主要是围绕Presto搭建的。Presto集群最初采用物理机部署,之后短暂使用过on yarn模式(通过Slider),考虑到运维、版本管理以及集群伸缩成本,最终采用了k8s方式部署。
用户的查询请求并不会直接提交到presto集群,而是先提交给请求代理层Presto-proxy,Presto-proxy对请求的用户进行身份认证,并对请求的数据进行鉴权。身份认证通过且权限没问题的请求,Presto-proxy会转发给Presto集群。Presto-proxy转发请求时,会对请求头进行改写(携带Presto集群能够识别的请求头),Presto集群接受到请求后,会对请求头进行甄别,如果请求中未携带特定请求头则认定为非法请求,并返回非法访问错误。
请求代理层presto-proxy除了对用户的请求进行用户认证和数据鉴权外,还有一个重要功能:集群伸缩。Presto的任务大多在00:00-08:00这个时间段,这个时间段集群的负载比较高。而08:00-24:00这个时间段,集群的负载相对较低。我们希望在夜间对集群增加节点,降低集群压力,同时在白天减少节点,控制集群成本。问题在于如果简单的对集群缩容,集群上正在运行的任务会报错。所以我们想了一个办法,也就是部署两个集群:”忙时集群”和”闲时集群”。”忙时集群”运行时间段为:23:50-08:00,”闲时集群”运行时间为:07:50-23:59。在07:55-23:55这个时间段,Presto-proxy将请求转发到”闲时集群”,在23:55-07:55这个时间段,将请求转发到”忙时集群”。在集群切换过程中,未执行完的任务还会在老集群继续执行,通常任务都会在集群下线之前执行完。通过这种请求路由的方式我们实现了集群的伸缩,有效提升资源利用率。

(代理层实现连接:https://blog.csdn.net/woloqun/article/details/84334818)
Flink在2020年我们才开始在公司推广使用,相对于其他互联网公司是比较晚的。因为Flink的本身的一些特性和优势,flink很快就在公司推广开来,并逐渐替代spark,成为实时计算的标准引擎。最开始Flink任务运行在yarn集群,随着存算分离架构的推进,存储和计算资源都需要慢慢的从CDH集群剥离出去(最终目的是下线CDH),大致的思路是要将flink作业迁移到k8s上去,目前有两种方案:在现有的k8s集群去运行flink任务,另外一种就是直接使用阿里云的flink计算服务,这两种方案我们都有在用。可能有人会疑惑:阿里云已经有现成的服务,为什么还要直接在k8s部署?主要是考虑到后续对实时任务的个性化的需求(监控、报警、任务重试、持续集成等),以及更好的和自研的调度系统适配。
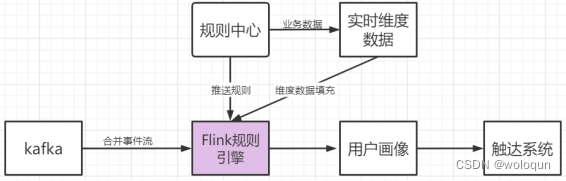
在我们公司Flink使用场景大致可以分成四大类:实时日志清洗、实时统计、算法策略、行为规则匹配。
在这里我们主要介绍下”行为规则匹配”这个场景。在日常工作中我们经常收到一些诸如此类需求:“用户给点击了开屏广告,给用户下发私信”、“用户进入了推荐线,但在60秒内没有任何点击操作,弹框引导用户选择感兴趣的内容”、“用户点赞了某位作者的两篇以上的内容,但并没有关注过此作者,则弹框引导用户关注作者”、“用户点击了活动入口,进入了活动页、发生了点赞、收藏等交互操作,引导用户进入活动下一流程”。这些需求大致可以分为如下三大类:
- 完成事件A,触发运营动作。
- 在固定时间内完成事件A,但未完成事件B,触发运营动作。
- 依次完成事件A,B,C,触发运营动作。
这些需求从开发角度来看,代码有很高的相似性,所以我们对这些需求进行了抽象,基于flink开发了一套行为规则引擎,并在规则引擎之上将常用的运营动作模块化,真正做到十分钟上线一个运营策略,相对之前天级别的交付时间,效率大幅提升。这个智能运营系统内部代号为IFTTT(if this then that),关于这个系统实现的技术细节,后续会有单独的文章介绍(待补充链接)。
StarRocks是目前比较火的OLAP计算引擎,兼容Mysql协议,支持高并发查询、多种数据模型(明细模型、聚合模型、更新模型、以及主键模型),并且在数仓加速和多维分析有非常好的表现,在我们公司有非常多的应用场景:用户画像、埋点事件分析系统、指标归应分析、自助取数平台。相对于同样是Olap计算引擎的Presto来说,Starrocks更多是直接使用Presto清洗的数据,面向上层数据应用的计算引擎。
用户画像(https://blog.csdn.net/woloqun/article/details/128478981)
指标归因思路(https://blog.csdn.net/woloqun/article/details/127266875)
基础平台建设篇
这章节介绍下我们在建设大数据平台过程中涉及的一些比较核心的系统:调度系统,用户账号权限体系,数据服务。
调度系统
早期我们采用airflow调度任务,airflow通过编写python脚本描述任务的DAG,使用上还是有一定的学习成本。由于我们绝大多数的任务都是sql,而且业务迭代非常快,如果所有的任务都采用airflow方式调度,效率太低了。所以在大数据平台搭建的初期就规划了调度系统,第一版调度系统的目标很明确:提升数仓建设以及报表开发效率,让数据开发专注于业务逻辑的开发。基于此背景,第一版调度平台(仅支持SQL)很快就上线了。平台上线后,数仓开发通过简单配置sql任务,就能很快的完成报表开发上线,报表开发效率大幅提升。依靠SQL调度平台,数仓团队前期在人力不足的情况下,依旧能够准时交付公司全业务线的数据需求。
随着业务发展,调度平台陆陆续续维护了3000+任务。同时问题也显现出来,SQL调度平台在最初设计时只维护了局部的任务依赖,并没有维护全局依赖。如果一份底层数据出现了问题,没有全局任务依赖,意味着所有下游受影响的任务,都得按照调度顺序挨个手动执行一遍,而且修复过程极容易出现依赖错误。
基于老调度平台的一些问题,重新设计了调度平台,我们做了如下改进:
-
自动构建数据血缘,构建全局任务依赖。
任务创建后,调度系统会分析SQL逻辑,提取目标表(Insert)和查询表,然后创建目标表和查询表的依赖关系。同时调度系统会保存目标表和任务的对应关系,并通过表与任务的对应关系,自动创建任务依赖,这样自然而然就把全局任务依赖维护起来了。 -
自动添加基础数据质量监控(掉零、迟到)。
早期数据的质量监控,需要单独配置监控任务,而绝大多数监控都有固定模板,例如:数据是否正常产出、环比数据量波动。对于这些比较固定的监控场景,在任务创建时,自动绑定了监控模板,任务执行后会自动执行监控任务,这样也也就省去了基础监控开发工作量。 -
任务依赖,支持一键修复所有下游依赖任务。
过去一个任务失败了,我们需要按照调度顺序手动执行下游依赖任务,对于底层任务失败,往往涉及到数千任务的修复,这个过程简直时灾难。有了全局任务依赖后,我们只要在失败的任务节点重新执行,就会自动重跑下游所有依赖任务。 -
支持flink,spark等jar包任务,并支持项目、版本管理、K8s运行环境。
-
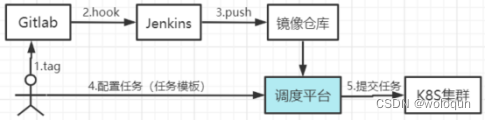
用户账号权限体系
大数据组件以及周边服务众多且都有自己的账号体系,由于整个生态体系的账号不统一,数据的权限就无法集中管理。为了解决这个问题我们引入了 LDAP,通过LDAP统一了大数据组件及周边服务的账号。并在此基础上搭建了大数据权限体系(RBAC),整个安全体系做到了:数据有权限,查询可追溯,有效的保护了数据安全。
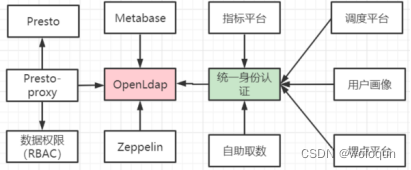
数据服务
数据服务作为数据中台的最后一公里,其重要性不言而喻,这部分内容参照之前写的一篇文章https://blog.csdn.net/woloqun/article/details/127537482。因为早期数据应用不多,使用方式也较简单,考虑到短期内收益较低,所以数据服务这个模块,我们规划的较晚,目前也处于摸索阶段。
(数据平台建设指南上END)