导读
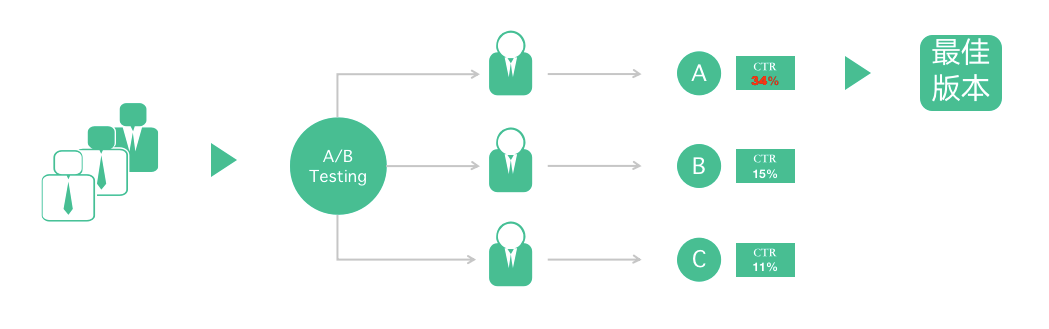
在数据驱动时代,不管是在产品功能迭代还是策略决策时都需要数据的支撑。那么,当我们准备上线一个新功能或者策略时,如何评估新老版本优劣,即数据的可量化就成了问题。这个时候就需要引入 A/B Test 了。
一、A/B Test 是什么?
A/B Test 的概念来源于生物医学的双盲测试,双盲测试中病人被随机分成两组,在不知情的情况下分别给予安慰剂和测试用药,经过一段时间的实验后再来比较这两组病人的表现是否具有显著的差异,从而决定测试用药是否有效。
在互联网行业中,在产品正式迭代发版之前,将 Web 或 App 界面或流程以同一个目的制定两个或多个方案,在同一时间维度,将流量对应分成若干个组,在保证每组用户特征相同(相似)的前提下,展示给用户不同的设计方案,收集各组的用户体验数据和业务数据,最后分析评估出最好版本,科学的进行决策。
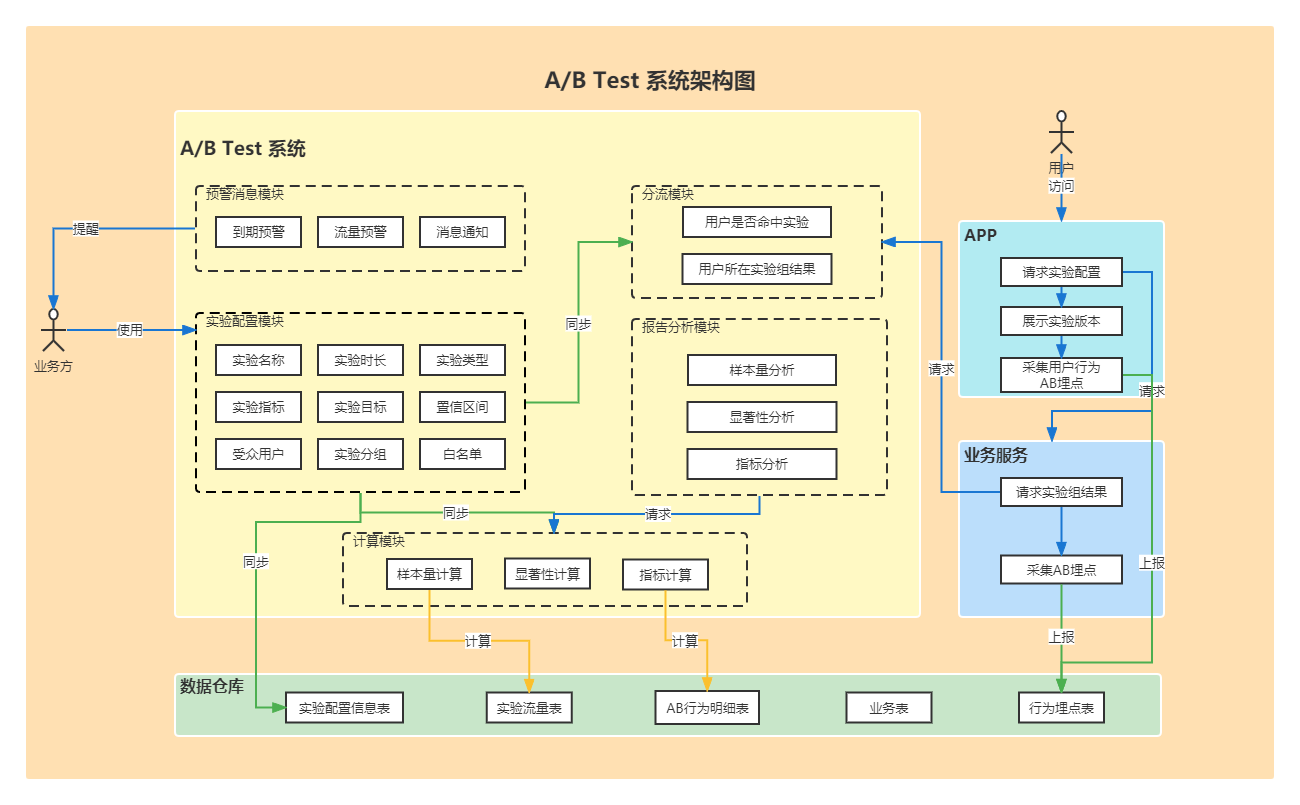
二、AB 系统设计与实现
2.1 系统介绍
转转 AB Test 系统的核心功能主要包含五个部分:
- 实验管理:实验配置、上下线等操作。
- 指标管理:分业务线创建与管理数据指标,数据指标分为「事件指标」和「复合指标」。
- 白名单管理:各种分流标识的白名单创建与管理。
- 数据报告:总实验用户数、流量概览、关注指标图表和实验结论数据。
- 分流服务:供业务方调用获取实验分组结果的 RPC 服务。
2.2 系统架构
2.3 系统实现
2.3.1 实验管理
- 实验列表:是所有实验的集合,整个实验列表分为三个区域「筛选/查询区域」、「新建实验」、「列表区域」。

- 新建实验:要求填三个部分信息基础信息、实验配置信息、实验策略配置,状态默认为测试中。
-
实验基本信息
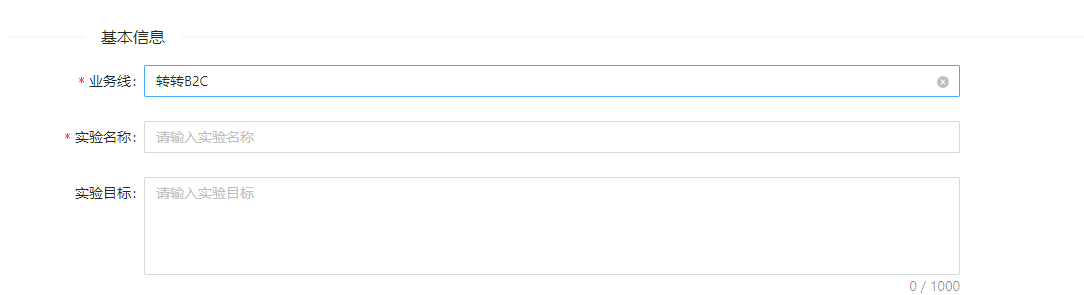
-
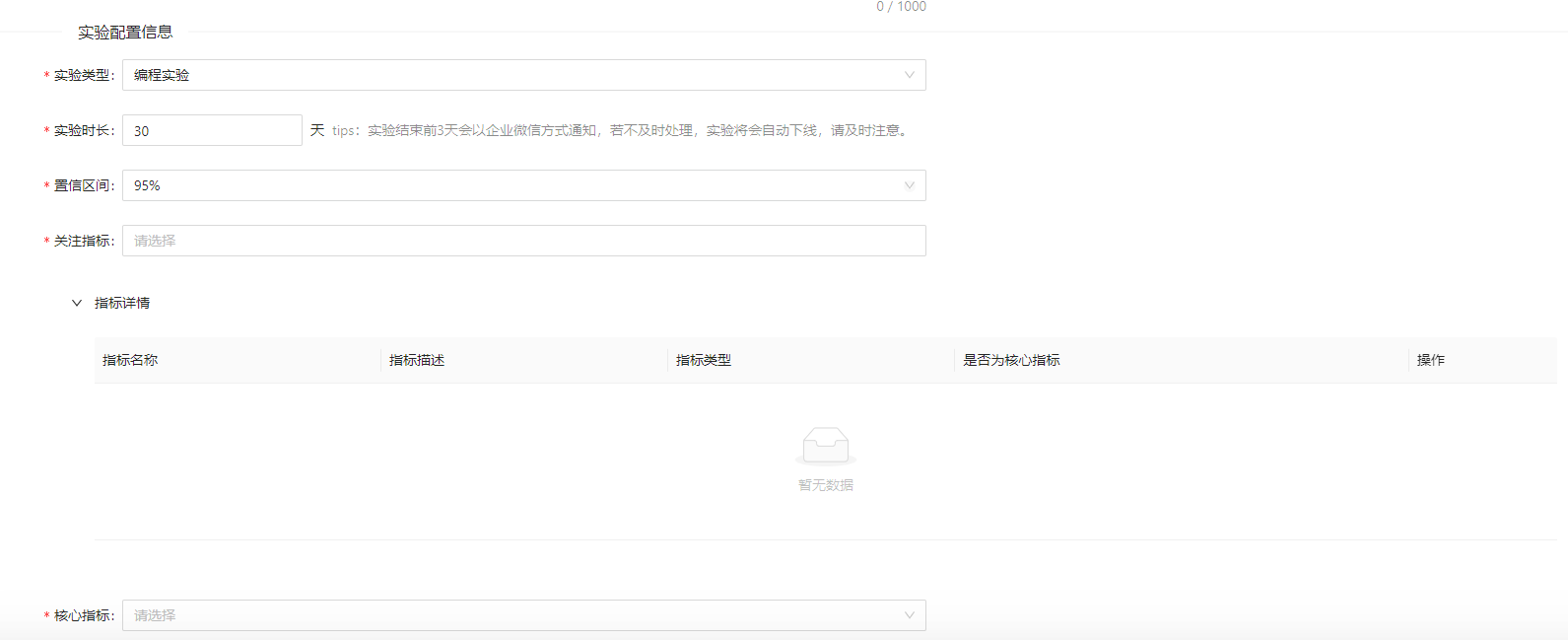
实验配置信息
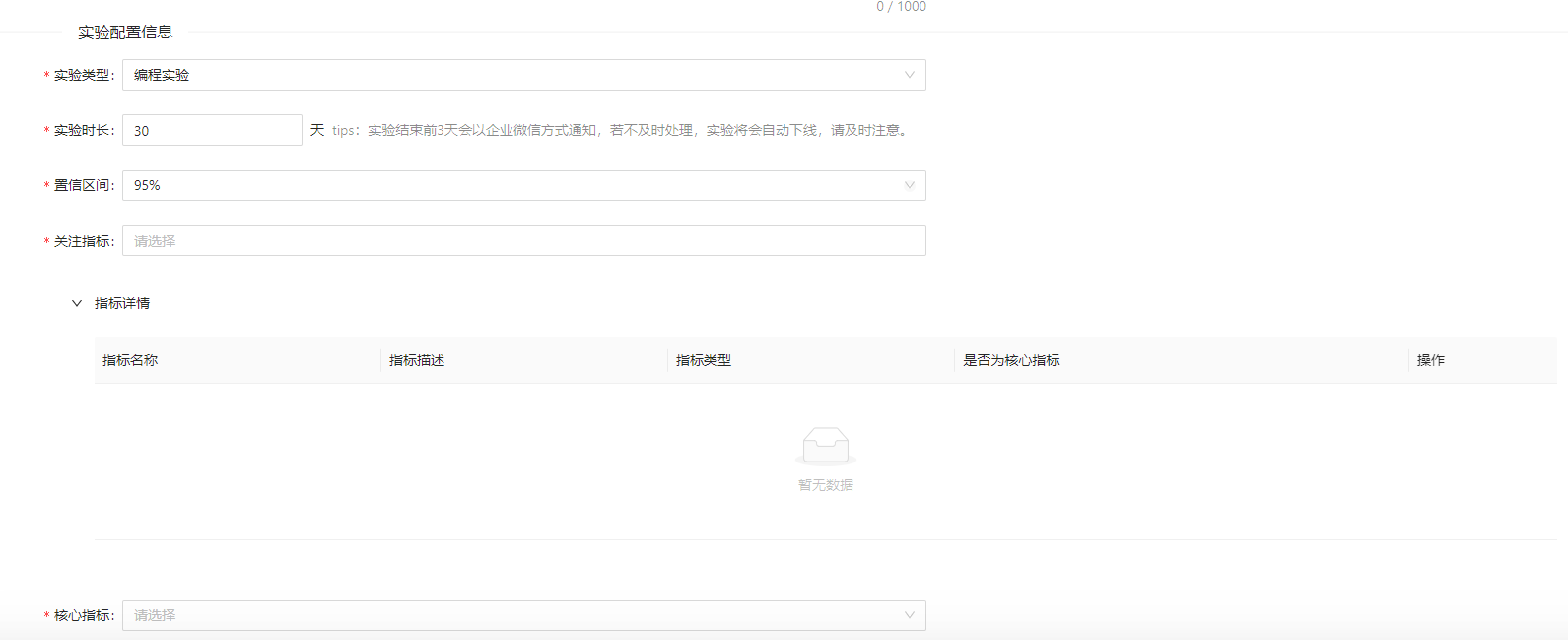
-
实验策略配置
-
2.3.2 指标管理
指标分为「事件指标」和「复合指标」两种类型。事件指标通过埋点事件配置统计,复合指标通过基础的事件指标进行四则运算生成。
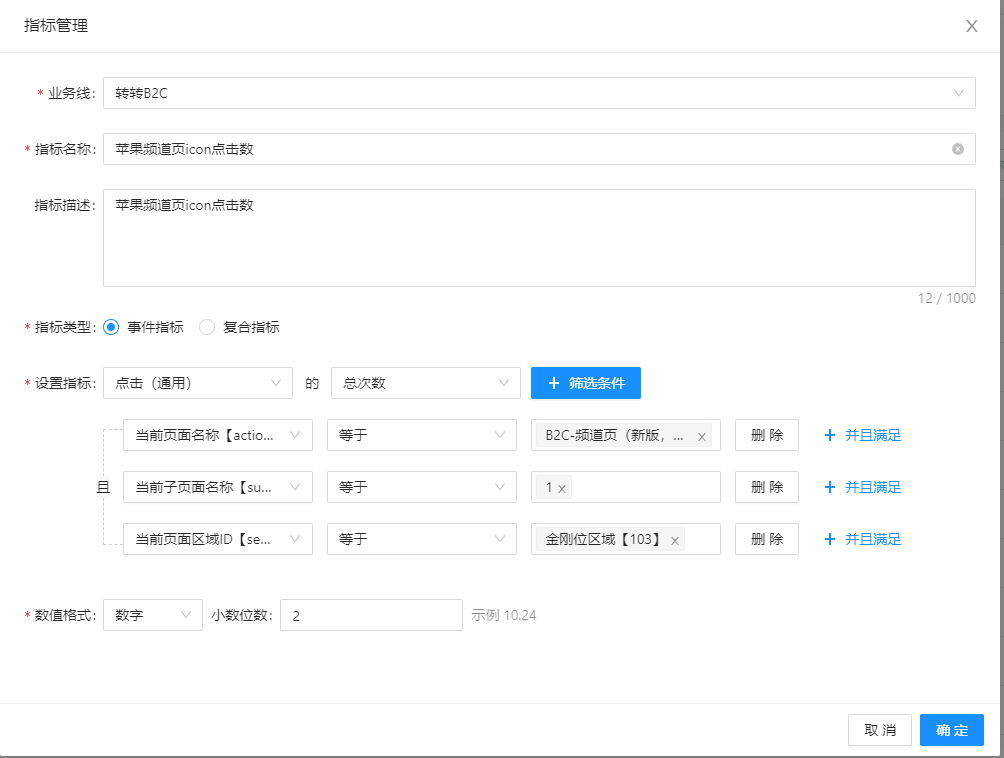

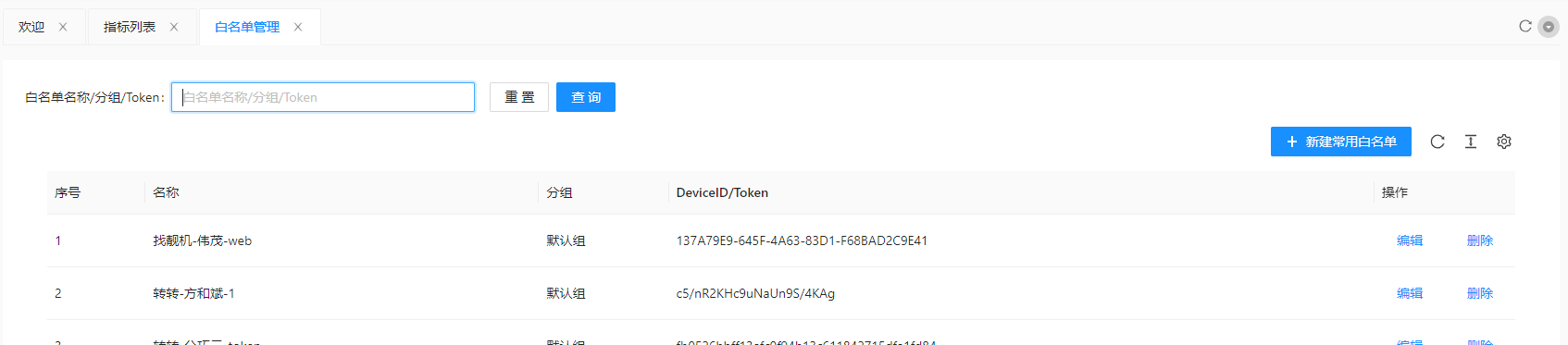
2.3.3 白名单管理
白名单功能提供统一的白名单创建与管理,用于实验配置时给相关实验组添加白名单,作用与分流服务,方便业务实验开发测试时通过配置白名单直接进入相应的实验组。
2.3.4 数据报告
实验报告是针对单个实验,配置的核心指标以及相关指标一个统计性的数据报告说明。
- 基本信息
- 实验ID:该实验的实验ID。
- 实验名称:该实验的实验名称。
- 开始时间:该实验正式上线的时间。
- 运行天数:该实验从上线至今/结束前的运行天数。
- 操作记录:记录这个实验的操作变化记录,包含流量分配、核心指标修改、实验暂停/上线等。
- 查看配置:查看这个实验的配置信息。

- 核心数据
- 整体-总实验用户数:实验上线至今/结束前共参与实验的用户数,按照分流标识进行统计。
- 分组-总实验用户数:各个分组实验上线至今/结束前共参与实验的用户数,按照分流标识进行统计。
- 总实验用户占比:「分组-总实验用户数」 / 「整体 - 总实验用户数」* 100%。
- 流量分配:创建实验时,流量的分配比例。
- 核心指标值:创建实验时,配置的「核心指标」对应的数值,这里会根据【指标管理】中配置的数值方式与小数位数进行显示。
- 统计学校验:用于描述试验组指标相比于对照组的提升范围。随着参与试验的样本量逐渐增加,数据指标波动趋于稳定,置信区间会逐渐收窄。一般来说,置信区间选择 95%。
- 统计功效:统计功效用于描述通过试验能检测出试验结果真实可靠的概率;一般用于衡量实验不显著时,是否需要继续扩大样本继续实验。一般当差异不显著时,统计功效小于 80%,需要继续做实验,当差异不显著是,统计功效大于 80%,说明基本对照组与实验组没有差异。
- 实验结论:实验结论根据「核心指标」与「统计功效」得出实验结论。

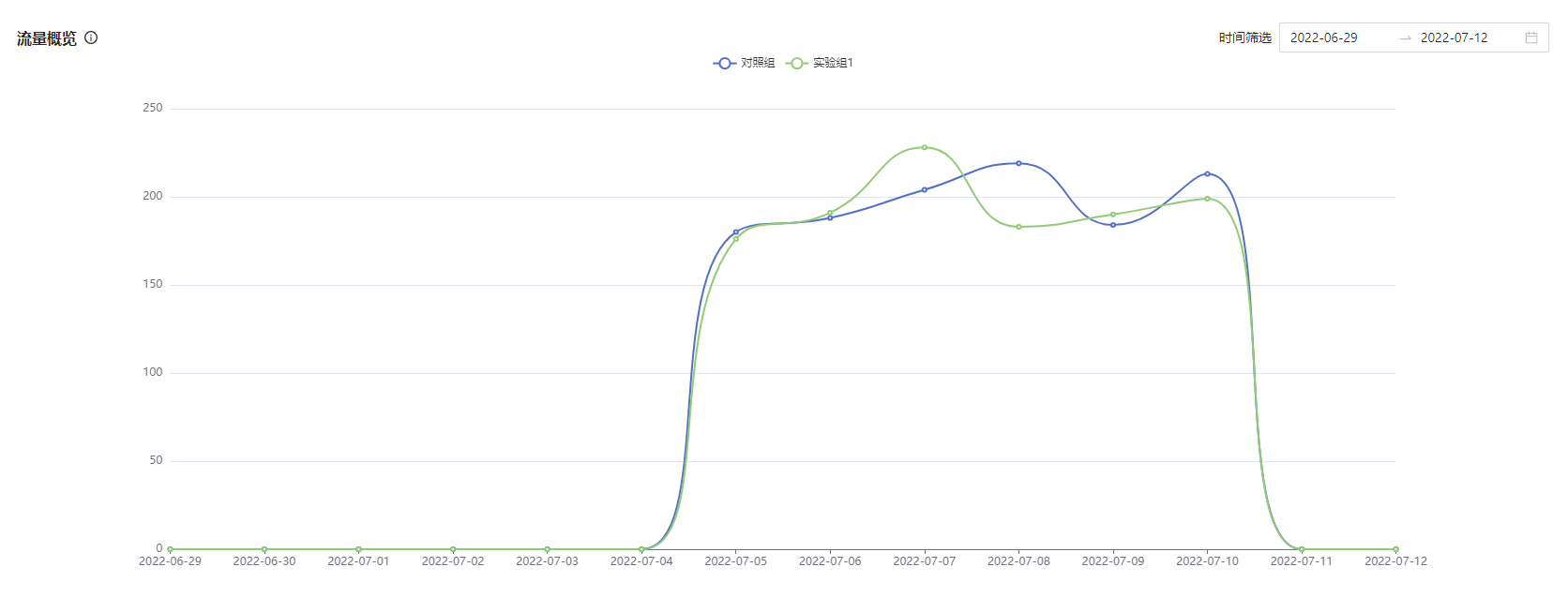
- 流量概览
主要目的衡量流量分配是否均匀,指标为「新进组用户数」:当天第一次参与实验的用户数。
- 关注指标(包含核心指标)
- 实验UV:同「分组-总实验用户数」,各个分组实验上线至今/结束前共参与实验的用户数,按照分流标识进行统计。
- 指标名称:所选的指标对应的名称。
- 差异绝对值:该分组对应对照组在该指标上的差异的值,举例:如对照组订单数为 50,实验组为 100, 这里的差异绝对值为 100 - 50 = 50。
- 差异相对值:该分组对应对照组在该指标上的差异的百分比,举例:如对照组订单数为 50,实验组为 100, 这里的差异绝对值为(100 - 50)/ 50 = 100%。
- 置信区间:核心指标通过实验配置的置信水平统计计算。

2.3.5 分流服务
- 分流逻辑
分流服务实时同步已上线运行的实验配置,业务调用方通过实验ID+分流标识获取实验的分组结果,具体实现逻辑如下:
if (白名单判断) {
return "白名单组";
}
if (实验下线判断) {
return "决策组";
}
if (进组不出组) {
if (缓存结果判断) {
return "缓存结果组";
}
}
// 分桶分组,用实验id + 分流标识进行hash取模100得到桶号,同一用户在不同实验中的桶号不完全一样,确保实验之间的独立性
int bucketNum = BucketNumUtil.getBucketNum(testId + "_" +tokenId);
// 根据桶号获取对应的实验组
String groupName = getGroupName(test, bucketNum);
if (进组不出组) {
redisCache.set(testId, tokenId, groupName, exAt);
}
return groupName;
- 分流方案
结合转转业务的特点,使用了无层方案。所谓无层,就是每个实验都是单独一层,使用实验 id 作为种子将 1-100 的桶号进行洗牌打乱,具体实现方法如下:
// 生成1-100的桶号,并使用testId作为种子洗牌打乱(相同的种子洗牌结果一样,从而保证同一ABTest的桶号List不变,且可根据testId预测,不同实验的桶号分布的随机性,确保实验之间的独立性)
List<Integer> list = Stream.iterate(1, item -> item + 1).limit(100).collect(Collectors.toList());
Random rnd = new Random(testId);
Collections.shuffle(list, rnd);
// 根据组流量比例将桶号分配到各组
for (int i = 0; i < groups.size(); i++) {
// TODO 按照流量占比分配相同数量的桶号
}
如此一来确保了每个实验都单独占有所有流量,可以取任意组的流量进行实验,但是又引进了新的问题,无层会导致同一个用户命中多个实验,即使这些实验是互斥的。
为了解决实验需要互斥的需求,后期将引入互斥实验组的概念,将互斥实验放在同一个组中,共享所有流量。具体实现逻辑如下:
新分流逻辑
if (白名单判断) {
return "白名单组";
}
if (实验下线判断) {
return "决策组";
}
int groupBucketNum = BucketNumUtil.getBucketNum(groupId + "_" +tokenId);
if (!互斥组流量判断(groupInfo, groupBucketNum)) {
// 不在互斥组流量中实验时,返回对照组
return "对照组";
}
if (进组不出组) {
if (缓存结果判断) {
return "缓存结果组";
}
}
// 分桶分组,用实验id + 分流标识进行hash取模100得到桶号,同一用户在不同实验中的桶号不完全一样,确保实验之间的独立性
int bucketNum = BucketNumUtil.getBucketNum(testId + "_" +tokenId);
// 根据桶号获取对应的实验组
String groupName = getGroupName(testInfo, bucketNum);
if (进组不出组) {
redisCache.set(testId, tokenId, groupName, exAt);
}
return groupName;
新分流方案
// 互斥组内流量分配
List<Integer> groupBucketNumList = Stream.iterate(1, item -> item + 1).limit(100).collect(Collectors.toList());
Random rnd = new Random(groupId);
Collections.shuffle(groupBucketNumList, rnd);
// 根据互斥组流量比例将桶号分配到各实验
for (int i = 0; i < groups.size(); i++) {
// TODO 按照流量占比分配相同数量的桶号
}
// 实验内部实验组桶号生成分配逻辑不变
List<Integer> testBucketNumList = Stream.iterate(1, item -> item + 1).limit(100).collect(Collectors.toList());
Random rnd = new Random(testId);
Collections.shuffle(testBucketNumList, rnd);
// 根据组流量比例将桶号分配到各组
for (int i = 0; i < groups.size(); i++) {
// TODO 按照流量占比分配相同数量的桶号
}
三、A/B Test 实施指南
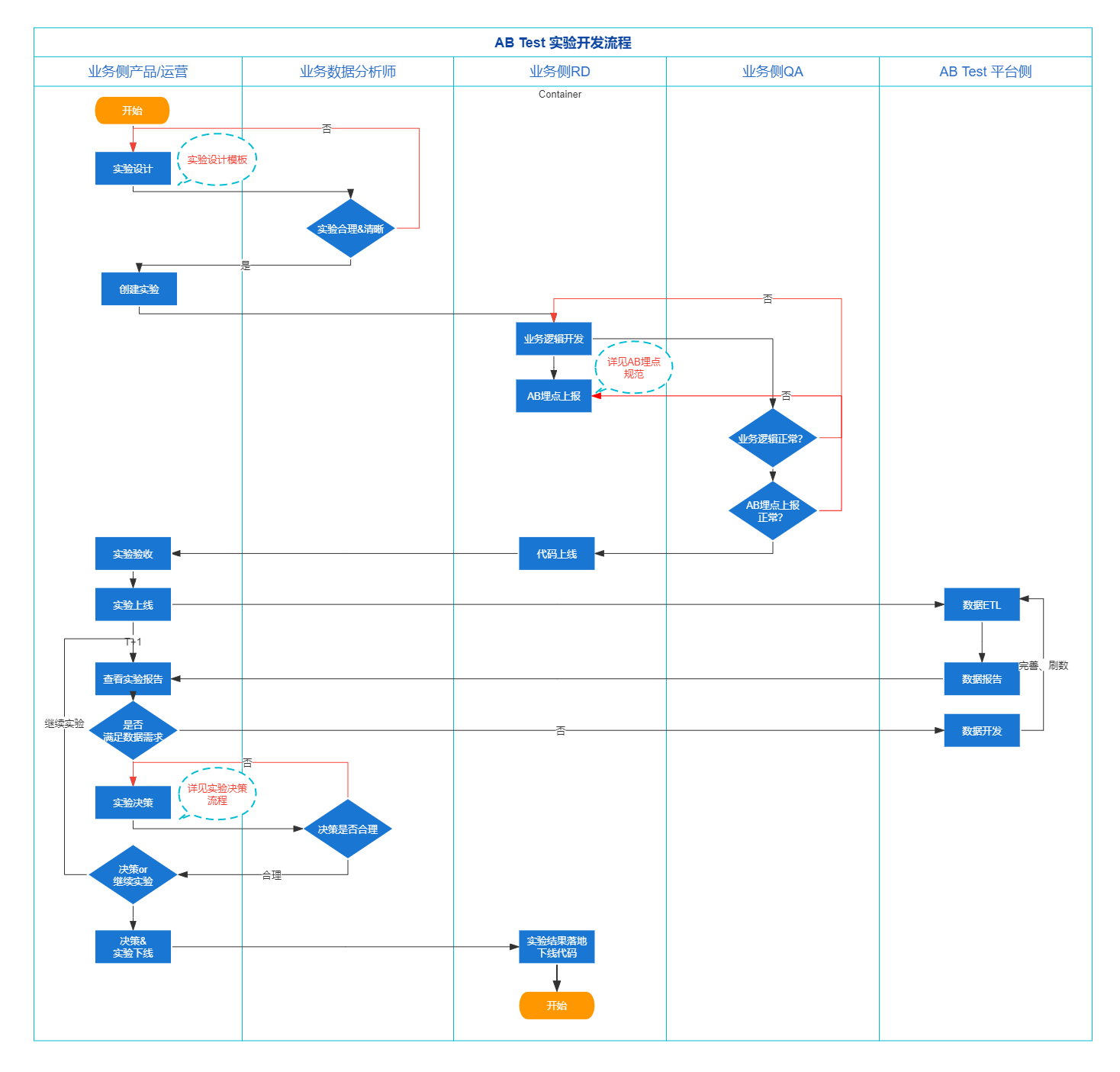
实验的每个流程与节点都至关重要,拒绝为做实验而做实验,用心用科学来做实验,整体实验实施流程图如下图。
3.1 实验设计
3.1.1 实验设计初衷
对于互联网产品而言,每次上线新版本都尤为慎重,为了衡量与判断「新上线的版本」/「现有版本」哪个版本的策略更优,通过事实的数据结合统计学原理进行科学、合理的进行决策。
实验的设计是实验最重要的一环,实验设计的好坏决定了最终实验的成功与否。
3.1.2 实验设计模板

3.1.3 实验设计的结构
整体实验的设计分为四个部分:
实验基本信息
- 业务线归属,可分为「B2C」、「C2B」、「C2C」,根据具体业务进行选择即可。(为什么要区分业务线? 不同业务线进行指标隔离,提升实验人员更好更快进行指标选择,底层数据处理效率与指标也更高效,数据响应更快。)
- 实验名称,实验具体的名称。
- 实验编号,在具体「AB Test 平台」在创建实验后即可获得,唯一标识了一个实验。
- 实验目标,在实验设计的初期,上线新版本的目的是什么,希望您能用「核心指标」的提升程度来衡量;如:新版本「优化下单流程」,核心指标「订单转化率」希望提升 0.8%。
实验配置信息
- 实验类型,目前包含了「编程实验」,「策略实验」。
- 预期上线时间,预期的实验上线的时间。
- 预期上线天数,根据实验受众群体的样本数量,简单估测上线的时长,单位天。业界的实验时长一般是 2-3 周,最短时长建议不要少于 7 天。因为不同日期活跃的用户群体可能不一样,所以最好要覆盖一个周期,如 7 天、14 天、21 天。那实验时长是不是越长越好呢,也不是的,实验时间过长会把各版本的区别拉平了,不同时期用户对不同策略的反应不一样,一般不超过 30 天。
- 实验指标,通常可被统计学检验的指标分为以下三类:人均类指标、次均类指标、转化率类指标。
- 核心指标(人均类指标、次均类指标、转化率类指标):实验目标直接相关,且决定实验结果的关键指标。
- 相关指标:该实验需要关注的其他指标,用于辅助试验结果的解读。
- 护栏指标:实际上是相关指标比较特殊的一种,通常是能反映用户体验受到伤害的指标,常常拥有“一票否决权”,帮助我们平衡实验决策。
- 注意:
- 对于少部分比较重要的相关指标/护栏指标来说,他们是有“一票否决权”的,他们也需要符合可被统计学检验的要求(判断这些数值差异到底是出自偶然,还是有确凿的判定把握)。
- 对于核心指标,必须是可以直接关联到实验中的变量,否则无法推测实验整体的差异性(即实验有差异性,但是通过数据无法观测出来)。
- 用户分流标识,目前分为 token/deviceId 与 uid,用于埋点上报和数据统计的区分。
- 受众群体,与用户画像进行打通,针对圈定用户人群的部分用户开展精准实验。
实验策略设计
- 实验分组,默认按照字母顺序来, A/B/C/D/E…
- 版本描述,各个版本的描述性文字,描述清晰各个版本的情况。
- 流量分配,最多分配 100% 流量,最细粒度为 1%。
实验结论
- 决策分组,最终实验下线的决策分组。
- 统计数据,各个版本之前的核心数据(核心指标_均值,置信区间,统计功效)。
- 实验结论描述,整体实验结果描述。
3.2 实验埋点上报规范
“实验ID”:实验的id标识,用于实验数据统计。
“实验分组”:实验分组结果,用于实验版本展示的标识。
“分流用户类型” :用于实验分流的标识类型,便于精准统计 UV 类指标数据。
埋点上报格式举例:
{
"埋点事件名":"ab",
"埋点内容":{
"实验页面":"XXXX",
"实验id":"XXXX",
"实验分组":"XXXC",
"分流用户类型":"XXXX"
}
}
3.3 实验决策指南
3.3.1 实验决策流程
当我们的实验在线上已经运行了一段时间之后,我们需要衡量实验整体的效果,整体实验决策的流程如下图。
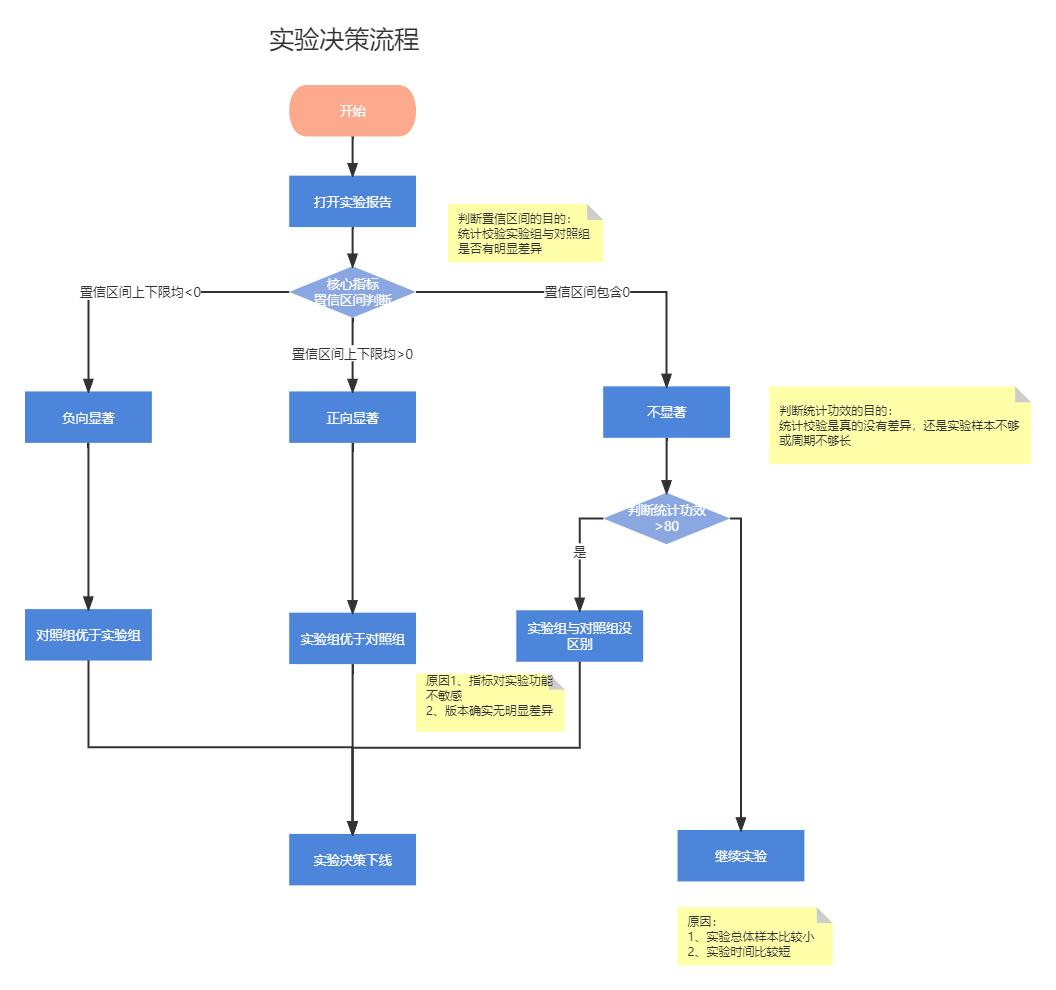
实验报告:包含了整体实验总用户在每个实验组的流量分配情况以及「核心指标」、「相关指标」的统计学检验结果,根据实验组的核心指标相对于对照组的核心指标变化率情况、置信区间及统计功效来评估试验效果。
「核心指标」的提升/下降决定了整体实验的效果,一般我们用置信区间和统计功效来整体判断实验的结果。
注意:对于少部分比较重要的相关指标/护栏指标来说,他们是有“一票否决权”的,需要进行整体评估,平衡试验决策。
3.3.2 置信区间&统计功效计算
什么是置信区间?
置信区间是一种常用的区间估计方法,所谓置信区间就是分别以统计量的置信上限和置信下限为上下界构成的区间 。对于一组给定的样本数据,其平均值为 μ,标准偏差为 σ,则其整体数据的平均值的 100(1 - α)% 置信区间为 (μ - Ζα/2σ, μ + Ζα / 2σ) ,其中 α 为非置信水平在正态分布内的覆盖面积 ,Ζα / 2 即为对应的标准分数。
为什么要计算置信区间?
在「A/B测试」的场景下,主要通过某个指标或留存的实验版本均值变化值以及置信区间来判断,在当前指标或用户留存上,实验版本是否比对照版本表现得更好。
置信水平,也称置信水平、置信系数、统计显著性,指实验组与对照组之间存在真正性能差异的概率,实验组和对照组之间衡量目标(即配置的指标)的差异不是因为随机而引起的概率。置信度使我们能够理解结果什么时候是正确的,对于大多数企业而言,一般来说,置信度高于 95% 都可以理解为实验结果是正确的。因此,默认情况下,「A/B测试」将置信区间参数值设置为 95%。
| 置信水平 | Z值 |
|---|---|
| 99% | 2.58 |
| 95% | 1.96 |
| 90% | 1.645 |
| 80% | 1.28 |
- 如果置信区间上下限均为正值,则表明试验结果为正向显著。
- 如果置信区间上下限均为负值,则表明试验结果为负向显著。
- 如果置信区间一正一负,则表明试验结果差异不显著。
计算逻辑


- 均值类
举例:实验核心指标是「人均支付金额」,需要计算 2022-06-01~2022-06-10;区间内「实验组」相对「对照组」置信区间范围,数据如下所示:
对照组: 参与实验用户 239 个,累积支付金额 121392 元。
实验组:参与实验用户 640 个,累积支付金额 504795 元。

- 比率类
例如:某个区间内

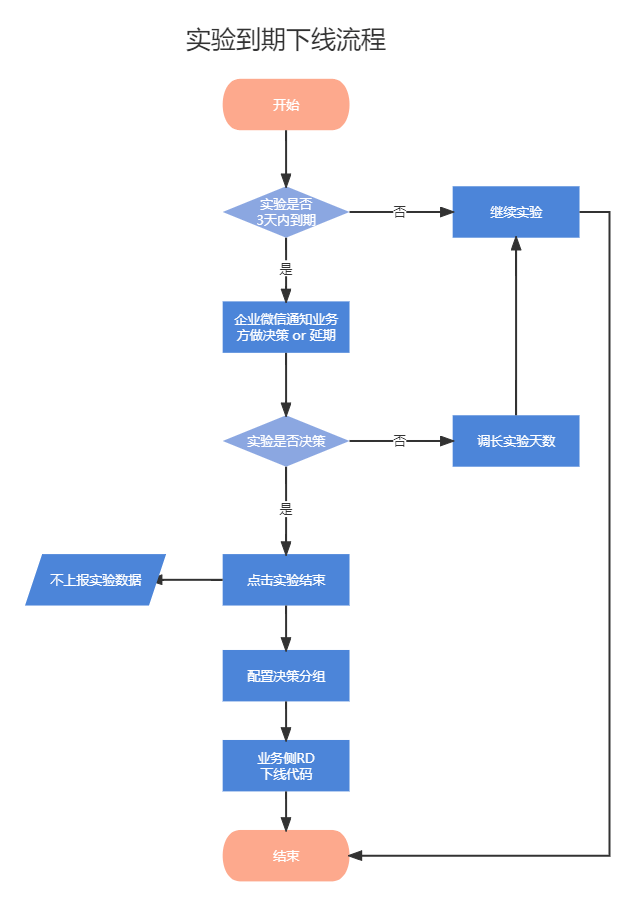
3.4 实验到期下线
实验到期下线分为两种情况:未到期决策下线、到期自动下线。
- 未到期决策下线,核心指标的统计功效已经很明显,可以直接分出实验各组的效果,则可以直接以优胜组进行决策下线,全量决策组,后期业务代码逻辑进行下线,落地实验结果。
- 到期自动下线,当实验设定的实验周期已结束,实验各组的核心指标的统计功效不明显,则自动以对照组下线,全量对照组,后期业务代码逻辑进行下线,落地实验结果。
四、未来规划与展望
-
实验类型多样化。提供更多、更丰富的实验类型,根据业务场景选择最合适的实验类型,更科学有效的进行实验。
-
数据报告丰富化。目前只有单指标维度的看数图表,留存分析、漏斗分析和归因分析将是后期的功能迭代点。
-
数据与监控告警实时化。目前的数据是离线数仓 T + 1 清洗打宽,有待提高数据的实时性,能快速发现问题,调整实验方案。
五、总结
本文主要分享了:
- A/B Test 是什么?
- AB 系统设计与实现
- A/B Test 实施指南
- 未来规划与展望
从了解 AB、如何开发 AB 平台、如何实施 AB 实验和未来的规划迭代四个方面介绍了 A/B Test 在转转的落地与应用。在互联网产品玲琅满目下,如何吸引新用户,留住老用户以及试错成本越来越高的场景下,如何通过 A/B Test 小流量、多方案,快速迭代、决策、优化产品变得越来越重要。AB 平台的建设还有很长的路要走。
未来转转会针对痛点与不足进行持续优化,输出更多的技术实践给大家,一起进步成长。
关于作者
王志远,转转数据智能部高级数据研发工程师,主要负责公司大数据相关基础平台建设,埋点规范设计和实时数据开发。
“保持一颗学习的心,才不会落后被淘汰。”
转转研发中心及业界小伙伴们的技术学习交流平台,定期分享一线的实战经验及业界前沿的技术话题。
关注公众号「转转技术」(综合性)、「大转转FE」(专注于FE)、「转转QA」(专注于QA),更多干货实践,欢迎交流分享~`