文章目录
- 1、KNN分类介绍
- 2、KNN分类核心要素
- 3、KNN分类实例
- 1.1 鸢尾花分类
- 1.2 手写数字识别
1、KNN分类介绍
分类是数据分析中非常重要的方法,是对己有数据进行学习,得到一个分类两数或构造出一个分类模型(即通常所说的分类器(Classifier))。分类是使用已知类别的数据样本,训练出分类器,使其能够对未知样本进行分类。分类算法是最为常用的机器学习算法之一,属于监督学习算法。
KNN分类(K-Nearest-Neighbors Classification)算法是分类算法中的一种,又叫做K近邻算法。该算法于于1987年由 Cover T和 Hart P提出,算法概念较为简单,其核心思想是,如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。虽然该算法中心思想简单,但是分类的效果相当优秀。
下面来简单了解一下其分类过程,例如假设已经获取一些动物的特征,且已知这些动物的类别分别是什么。现在需要识别一只新动物,判断它是哪类动物。首先找到与这个物体最接近的k个动物。令k=3,假设可以找到2只猫和1只狗,由于找到的结果中大多数是猫,则把这个新动物划分为猫类。
2、KNN分类核心要素
KNN没有专门的学习过程,是基于数据实例的一种学习方法,从刚刚介绍的分类过程可以看出,在KNN分类过程中,存在三种核心要素。
第一个核心要素是K值,也就是在上述的分类过程中找到与这个物体最接近的k个动物,如果k取值太小,好处是近似误差会减小。但同时预测结果对近邻的样本点非常敏感,仅由非常近的训练样本决定预测结果。使模型变得复杂,容易过拟合。如果k值太大,学习的近似误差会增大,导致分类模糊,即欠拟合。
例如假设在刚刚的例子中设置k值分别为3和6,当k值等于3是还是可以找到2只猫和1只狗,那么对应的就是属于猫,但是若k取值为6时找到2只猫、1只狗和3只熊,那么对应的类别就属于熊了,所以K值的选取会直接影响到最终的分类效果,而如何进行K值的选取就涉及到第二个核心要素,距离的度量。
是否相似主要是由距离的度量决定,距离决定了哪些物体之间是相似的,哪些是不相似的。距离的度量方法有很多种,不同的距离所确定的近邻点不同。二维上常用的度量方法是欧氏距离,此外还有曼哈顿距离、余弦距离、球面距离等。欧氏距离的计算公式如下:

同样以刚刚的分类过程为例,假设存在三个已知点cat1,cat2以及dog1,它们的位置信息分别为(1,3)、(4,5)、(3,5),存在一个未知类别点(2,2),分别计算该点到三个已知点的欧式距离,按照欧式距离从小到大排序依次是cat1,dog1以及cat2,若设置k为1,则选择最近的一个位置进行分类,即该动物属于猫类。
当k值设置不为1时,分类结果的确定往往由第三个要素,分类决策规则来决定,即多数表决原则,由输入实例的k个最邻近的训练实例中的多数类决定输入实例的类别。
3、KNN分类实例
下面分别通过鸢尾花分类和手写数字识别两个实例介绍KNN分类的具体实现过程。
1.1 鸢尾花分类
鸢尾花数据集最初由科学家Anderson 测量收集而来,1936 年因用于公开发表的Fisher 线性判别分析的示例,在机器学习领域广为人知。
鸢尾花数据集共收集了三类鸢尾花,即Setosa 山鸢尾花、Versicolour 杂色鸢尾花和 Virginica 弗吉尼亚鸢尾花,每类鸢尾花有50条记录,共150 条数据。数据集包括4 个属性特征,分别是花瓣长度、花瓣宽度、花萼长度和花萼宽度。
在对鸢尾花数据集进行操作之前,先对数据进行详细观察。SKlearn 中的iris 数据集有5个key,分别如下:
(1) target_names: 分类名称,包括 setosa、versicolor 和 virginica类。
(2) data:特征数据值。
(3) target:分类(150个)。
(4) DESCR:数据集的简介。
(5) feature_names:特征名称。
首先可以使用sklearn库中的datasets模块导入鸢尾花数据集,同时查看该数据的各方面特征。
from sklearn.datasets import load_iris
iris_dataset = load_iris()
#下面是查看数据的各项属性
print("数据集的Keys:\n",iris_dataset.keys()) #查看数据集的keys。
print("特征名:\n",iris_dataset['feature_names']) #查看数据集的特征名称
print("数据类型:\n",type(iris_dataset['data'])) #查看数据类型
print("数据维度:\n",iris_dataset['data'].shape) #查看数据的结构
print("前五条数据:\n{}".format(iris_dataset['data'][:5])) #查看前5条数据
#查看分类信息
print("标记名:\n",iris_dataset['target_names'])
print("标记类型:\n",type(iris_dataset['target']))
print("标记维度:\n",iris_dataset['target'].shape)
print("标记值:\n",iris_dataset['target'])
#查看数据集的简介
print('数据集简介:\n',iris_dataset['DESCR'][:20] + "\n.......") #数据集简介前20个字符

然后针对鸢尾花数据集进行训练集与测试集的拆分操作,可以使用train_test_split()函数来实现,该函数属于sklearn.model_selection中的交叉验证功能,随机的将样本数据集拆分为训练集和测试集,该函数的语法格式如下:
x_train,x_test,y_train,y_test=cross_validation.train_test_split(train_data,train_target,test_size,random_state)
其中train_data与train_target分别为数据集特征以及标签,test_size表示测试集比例,random_state为随机种子,在要求每次划分数据一致时可以使用。
下面对iris鸢尾花数据集进行拆分,并查看拆分结果。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris_dataset = load_iris()
X_train, X_test, y_train, y_test = train_test_split( iris_dataset['data'], iris_dataset['target'], random_state=2)
print("X_train",X_train)
print("y_train",y_train)
print("X_test",X_test)
print("y_test",y_test)
print("X_train shape: {}".format(X_train.shape))
print("X_test shape: {}".format(X_test.shape))

在训练模型时,可以尽量去选取关联明显的特征进行学习,而特征之间关联度的高低可以通过绘制一组变量的多个散点图来进行观察,绘制时可以使用Pandas的scatter_matrix()函数来实现,该函数的语法格式如下:
scatter_matrix(frame,alpha,c,figsize,ax,diagonal,market,density_kwds,hist_kwds,range_padding,**kwds)
其中frame表示DataFrame对象;alpha表示图像透明度,一般取0到1之间的小数;c表示颜色值;figsize表示以英寸为单位的图像大小,一般以元组(宽度,高度)的形式进行设置;ax为轴向,一般设置为None;diagonal必须且只能在hist和kde中选择一个,hist表示直方图,kde表示核密度估计,该参数为函数的关键参数;market表示可用的标记类型;density_kwds为可选项,表示与kde相关的字典参数;hist_kwds为可选项,表示与hist有关的字典参数;range_padding为可选项,表示图像在x轴、y轴原点附近的留白(padding),该值越大,留白距离越大,图像远离坐标原点;**kwds为可选项,表示与scatter_matrix函数本身相关的字典参数。
对于上述拆分的数据集,使用scatter_matrix()函数显示训练集。
import pandas as pd
iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names)
# 创建一个scatter matrix,颜色值来自y_train
pd.plotting.scatter_matrix(iris_dataframe, c=y_train, figsize=(15, 15), marker='o', hist_kwds={'bins': 20}, s=60, alpha=.8)

可以看到散点矩阵图呈对称结构,除对角上的密度函数图之外,其他子图分别显示了不同特征列之间的关联关系。例如petal_length与petal_width之间近似成线性关系,说明这对特征关联性很强。而有的特征之间分布状态较为杂乱,基本没有规律可寻,说明特征之间的关联度不强。
在对数据集有一定的了解之后,需要选取合适的模型并对模型进行初始化,然后对数据集进行分类学习,得到训练好的模型。即使用Scikit learn中的neighbors包,利用其中的KNeighborsClassifier类。该类的实现思路比较简单,核心操作包括以下三步:
第一步、创建KNeighborsClassifier对象,并对其进行初始化。
基本格式如下:
sklearn.neighbors.KNeighborsClassifier(n_neighbors,weights,algorithm,leaf_size,p,metric,metric_params,n_jobs,**kwds)
其中主要的参数里,n_neighbors表示KNN中的近邻数量k值,默认值是5;weights表示计算距离时使用的权重,默认值是“uniform”,表示平等权重,也可以取值“distance”,表示按照距离的远近设置不用的权重,此外还可以自主设置加权方式;algorithm表示快速k近邻搜索算法,默认参数为auto;leaf_size默认是30,表示构造的kd树和ball树的大小。这个值的设置会影响树构建的速度和搜索速度,同样也影响着存储树所需的内存大小;p表示距离度量公式,默认为2,表示欧氏距离,另外取值为1时表示曼哈顿距离;metric用于距离的计算,默认是“minkowski”。
第二步、调用fit(),对数据集进行训练。
函数格式如下:
fit(x,y)
表示以x为训练集,以y为测试集对模型进行训练。
第三步、调用predict()函数,对测试集进行预测。
函数格式如下:
predict(x)
表示根据给定的数据预测其所属的标签。
结合上述过程使用KNN对鸢尾花数据集进行分类的完整代码如下:
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
#导入鸢尾花数据并查看数据特征
iris = datasets.load_iris()
print('数据集结构:',iris.data.shape)
# 获取属性
iris_X = iris.data
# 获取类别
iris_y = iris.target
# 划分成测试集和训练集
iris_train_X,iris_test_X,iris_train_y,iris_test_y=train_test_split(iris_X,iris_y,test_size=0.2, random_state=0)
#分类器初始化
knn = KNeighborsClassifier()
#对训练集进行训练
knn.fit(iris_train_X, iris_train_y)
#对测试集数据的鸢尾花类型进行预测
predict_result = knn.predict(iris_test_X)
print('测试集大小:',iris_test_X.shape)
print('真实结果:',iris_test_y)
print('预测结果:',predict_result)
#显示预测精确率
print('预测精确率:',knn.score(iris_test_X, iris_test_y))
程序运行结果如下:

从结果中可以看出,拆分的测试集总共有30个样本,其中有1个判断错误,总体精确率约为96.7%,精度较高。
1.2 手写数字识别
文字识别中难度较高的是手写文字识别,因为手写体与印刷体相比,个人风格迥异、图片大小不一。手写数宇识别的目标相对简单,是从图像中识别出数字0~9,经常用于自动邮件分拣等生产领域。在机器学习中,有时将识别问题转换为分类问题。本实验使用的数据集修改自“手写数字光学识别数据集”,该数据集由Alpaydin和Kaynak提供,于1998年发布,共保留了 1600 张图片。通过拆分,其中1068张作为训练集,其余的532张为测试集。图片为长宽都是32px的二值图,为方便处理,将图片预存为文本文件。
本实例中素材文件夹为HWdigits,子目录trainSet下存放训练数据,子目录testSet存放测试数据。使用KNN对训练数据集进行训练,然后对测试数据集进行测试并返回测试结果的相关代码如下:
#coding=utf-8
import numpy as np
#os库中的listdir方法用于返回指定文件夹下的文件或文件列表
from os import listdir
def loadDataSet(): #加载数据集
#获取训练数据集
print("1.Loading trainSet...")
trainFileList = listdir('HWdigits/trainSet')
trainNum = len(trainFileList) #获取训练数据集长度
trainX = np.zeros((trainNum, 32*32)) #保存训练数据集向量,先定义为全0
trainY = [] #保存每条数据标签值
for i in range(trainNum):
trainFile = trainFileList[i]
#将训练数据集向量化
trainX[i, :] = img2vector('HWdigits/trainSet/%s' % trainFile,32,32)
label = int(trainFile.split('_')[0]) #读取文件名的第一位作为标记,文件名的第一位为对应的数字
trainY.append(label) #将标签值即数字保存到训练数据标签中
#获取测试数据集
print("2.Loadng testSet...")
testFileList = listdir('HWdigits/testSet')
testNum = len(testFileList) #获取测试数据集长度
testX = np.zeros((testNum, 32*32)) #保存测试数据集向量,先定义为全0
testY = [] #保存每条数据标签值
for i in range(testNum):
testFile = testFileList[i]
#将测试数据集向量化
testX[i, :] = img2vector('HWdigits/testSet/%s' % testFile,32,32)
label = int(testFile.split('_')[0]) #读取文件名的第一位作为标记
testY.append(label) #将标签值即数字保存到测试数据标签中
return trainX, trainY, testX, testY
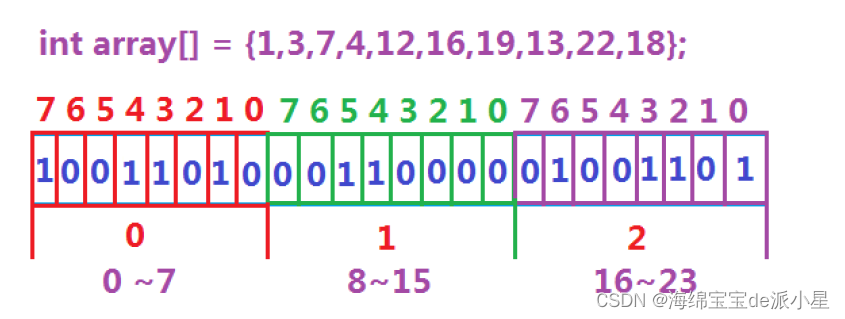
def img2vector(filename,h,w): # 将32*32的文本转化为向量
imgVector = np.zeros((1, h * w))
fileIn = open(filename)
for row in range(h):
lineStr = fileIn.readline()
for col in range(w):
imgVector[0, row * 32 + col] = int(lineStr[col])
return imgVector
def myKNN(testDigit, trainX, trainY, k):
numSamples = trainX.shape[0] #shape[0]代表行,每行一个图片,得到样本个数
#1.计算欧式距离
diff=[]
for n in range(numSamples):
diff.append(testDigit-trainX[n]) #每个个体差
diff=np.array(diff) #转变为ndarray
#对差求平方和,然后取和的平方根
squaredDiff = diff ** 2
squaredDist = np.sum(squaredDiff, axis = 1)
distance = squaredDist ** 0.5
#2.按距离进行排序
sortedDistIndices = np.argsort(distance)
classCount = {} #存放各类别的个体数量
for i in range(k):
#3.按顺序读取标签
voteLabel = trainY[sortedDistIndices[i]]
#4.计算该标签次数
classCount[voteLabel] = classCount.get(voteLabel, 0) + 1
#5.查找出现次数最多的类别,作为分类结果
maxCount = 0
for key, value in classCount.items():
if value > maxCount:
maxCount = value
maxIndex = key
return maxIndex
train_x, train_y, test_x, test_y = loadDataSet() #获取训练数据集、测试数据集
numTestSamples = test_x.shape[0] #获取测试数据集数量
matchCount = 0
print("3.Find the most frequent label in k-nearest...")
print("4.Show the result...")
for i in range(numTestSamples):
predict = myKNN(test_x[i], train_x, train_y, 3) #获取分类得到的标签值
print("result is: %d, real answer is: %d" % (predict,test_y[i]))
if predict == test_y[i]: #将分类得到的标签值与实际标签值进行对比,若相同则分类成功的个数加1
matchCount += 1
accuracy = float(matchCount) / numTestSamples #计算准确率
# 5.输出结果
print("5.Show the accuracy...")
print(" The total number of errors is: %d" % (numTestSamples-matchCount))
print(' The classify accuracy is: %.2f%%' % (accuracy * 100))

可以看到分类准确率达到97.93%,效果相对较好。
KNN进行手写数字识别源码及数据集