支持向量机(Support Vector Machine,简称SVM)是机器学习领域中一种常用的分类算法,其在处理线性可分和线性不可分问题上表现出色。Python作为一种广泛应用的编程语言,提供了众多强大的机器学习库和工具,使得实现支持向量机算法变得相对简单。本文将以Python为工具,演示如何实现支持向量机算法,并通过一个具体的案例来展示其实践过程。一、导入库和数据准备
在开始之前,我们首先需要导入所需的Python库,例如NumPy、Pandas和Scikit-learn等。同时,我们需要准备一个用于分类的数据集,这里以鸢尾花数据集为例。
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 导入数据集
iris = load_iris()
X = iris.data
y = iris.target
# 数据预处理
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
二、构建支持向量机模型
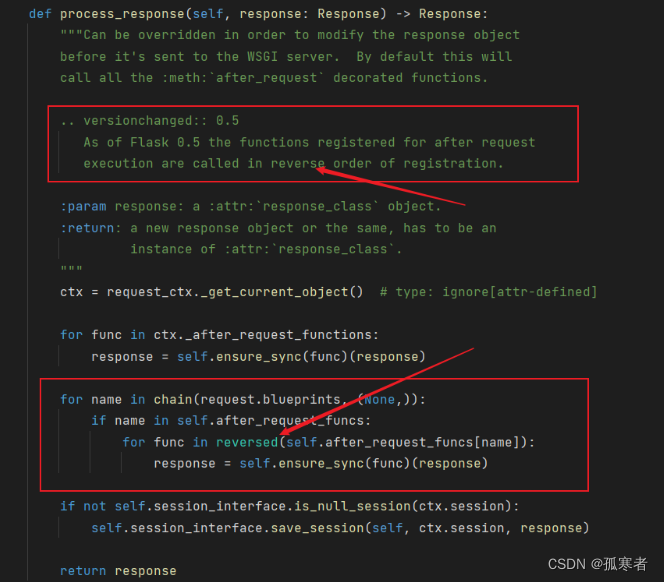
在数据准备完毕后,我们可以开始构建支持向量机模型。首先,我们需要选择合适的核函数,通常有线性核、多项式核和高斯核等。这里我们选择高斯核(rbf)作为示例。
# 构建支持向量机模型
svm_model = SVC(kernel='rbf')三、模型训练和预测
模型构建好后,我们可以通过训练数据进行模型训练,并利用模型对测试数据进行预测。
# 模型训练
svm_model.fit(X_train, y_train)
# 预测测试集
y_pred = svm_model.predict(X_test)四、模型评估
为了评估模型的性能,我们可以计算分类的准确率。
# 模型评估
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)通过上述代码的执行,我们可以得到支持向量机模型在测试数据上的分类准确率。
五、案例应用:鸢尾花分类
作为一个具体的案例应用,我们将使用鸢尾花数据集进行分类。首先,我们导入相关的库和数据集,然后对数据进行预处理和准备。接着,我们构建一个支持向量机模型,并选择适当的核函数。然后,我们使用训练集对模型进行训练,再使用测试集进行预测,最后计算分类的准确率。
通过实现支持向量机算法,我们可以看到其在鸢尾花分类问题上的准确率非常高。
结论:
本文以Python为工具,演示了支持向量机算法的实现过程。通过导入相关的库和数据集,进行数据的预处理和准备,构建支持向量机模型,并选择合适的核函数。之后,我们使用训练集对模型进行训练,然后利用测试集进行预测,并计算分类的准确率。实践过程证明,支持向量机算法在分类问题上具有很高的准确性和可靠性。
希望本文对您理解支持向量机的Python实践过程有所帮助。谢谢阅读!
人工智能的学习之路非常漫长,不少人因为学习路线不对或者学习内容不够专业而举步难行。不过别担心,我为大家整理了一份600多G的学习资源,基本上涵盖了人工智能学习的所有内容。点击下方链接,0元进群领取学习资源,让你的学习之路更加顺畅!记得点赞、关注、收藏、转发哦!扫码进群领资料