1、背景
线上某个业务数据分表存储在10个子表中,现在需要快速按照条件(比如时间范围)筛选出所有的数据,主要是想做一个可视化的数据查询工具,给产研团队使用。
2、实践
注意:不要在线上真实数据库操作,操作前需要确认清楚。线上质量第一!线上质量第一!线上质量第一!
思路1:使用UNION ALL操作符将这些子表合并,然后在合并后的结果集上执行查询操作。
假设现在有10个子表,命名为table_1, table_2, ..., table_10,并且每个表中都有一个表示时间的字段 timestamp_column,可以使用以下查询来按照时间范围筛选出所有的数据:
SELECT *
FROM (
SELECT * FROM chat_message_1 WHERE send_time BETWEEN 'start_time' AND 'end_time'
UNION ALL
SELECT * FROM chat_message_2 WHERE send_time BETWEEN 'start_time' AND 'end_time'
UNION ALL
-- ...
SELECT * FROM chat_message_10 WHERE send_time BETWEEN 'start_time' AND 'end_time'
) AS combined_tables;
在这个查询中,start_time和end_time是你想要的时间范围。UNION ALL操作符用于合并子表,然后在合并后的结果上执行查询操作。
请注意,这种方法可能在数据量很大的情况下导致性能问题,因为它会扫描并合并多个表。如果性能是一个重要的考虑因素,你可能需要考虑其他优化策略,例如分区表、分表查询等。
下面我们用"UNION ALL"仅查询4个表,时间范围为一周,我们看看数据库Mysql的CPU使用情况有什么变化。
SELECT * FROM (
SELECT * FROM chat_message_1 WHERE send_time BETWEEN 1693843200000 AND 1694607993000
UNION ALL
SELECT * FROM chat_message_2 WHERE send_time BETWEEN 1693843200000 AND 1694607993000
UNION ALL
SELECT * FROM chat_message_3 WHERE send_time BETWEEN 1693843200000 AND 1694607993000
UNION ALL
SELECT * FROM chat_message_4 WHERE send_time BETWEEN 1693843200000 AND 1694607993000
) AS combined_tables;数据库为双核CPU部署,可以看到CPU的占用从3%左右飙升到25%+,这个情况在线上的真实环境是绝对不能忍受的。
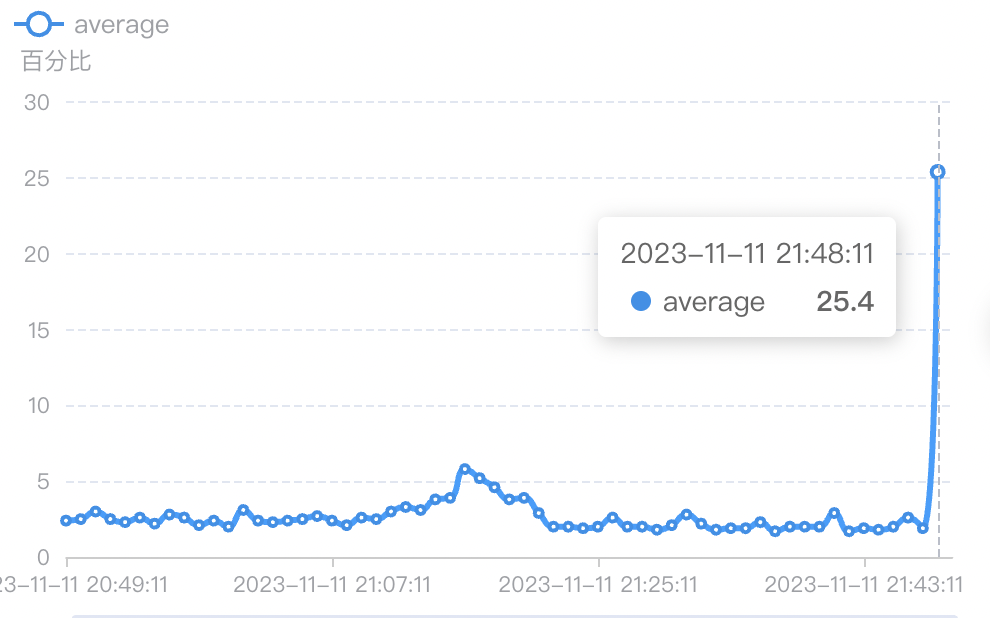
事实上,我们的真实场景比这个会更复杂,数据中每一条数据代表的是问题Q或者答案A,通过msg_id和question_id一一关联,最后实际需要展示的结果是QA对,如果按照上述“UNION”的方法查询,数据库CPU占用大概率会更高,不具备可行性。
数据库的结构:

数据库中数据示例:
| msg_id | question_id | message |
| 10000 | 你的姓名? | |
| 10001 | 10000 | 我叫张三。 |
| 10002 | 你今年多大了? | |
| 10003 | 10002 | 我今年18岁。 |
| ...... |
最终期望查出来的数据结果是:(QA对)
| msg_id | query | answer |
| 10000 | 你的姓名? | 我叫张三。 |
| 10002 | 你今年多大了? | 我今年18岁。 |
思路2:基于编程语言的并发能力,通过并行请求数据库查询,也就是并行执行SQL语句。
此方法风险很大,不再赘述,对数据库压力较大,不是推荐的做法。事实上进过测试,数据库的CPU占用也很大。
3、思考&方案
刚开始的时候我们业务的数据量比较少,直接使用“UNION ALL”等操作查询速度也很快,突然有一天线上的数据库开始报警,提示CPU占用过高,影响了线上的部分业务,慌得一批。
线上真实的使用场景查询条件很多,也有对应的索引,一般是查询某个人的数据,而具体某个人的所有数据是可以通过约定好的算法算出他的数据存在于哪个固定的数据库的(分表的思路),因此并不会出现上述我们提到的查询语法场景,速度很快,不会有任何问题。
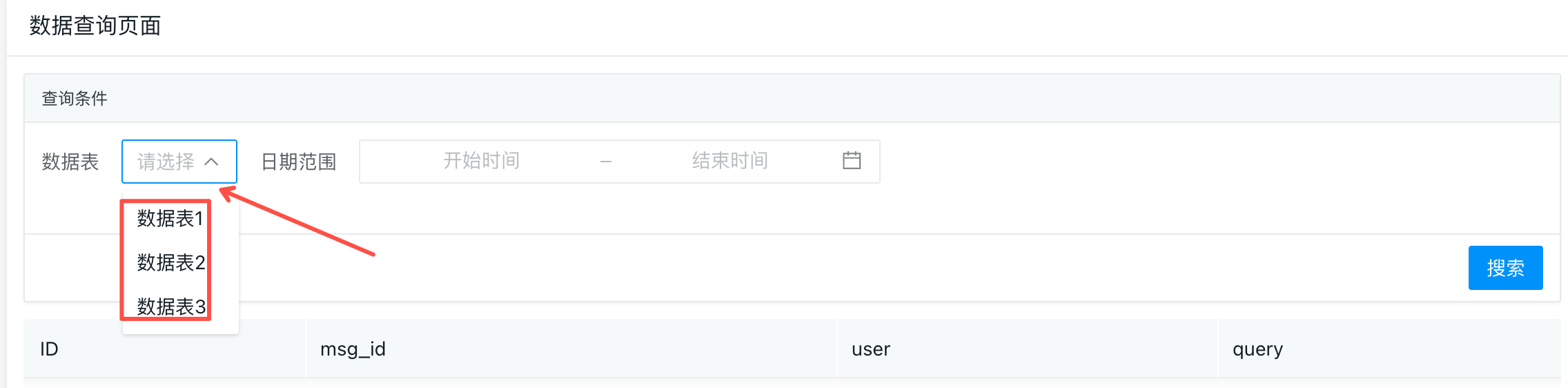
而我们原计划想做的可视化的数据查询工具,是想查所有的用户数据,因此会变得复杂很多,刚开始的思路其实也有点问题,想直接实时查询所有表所有人的数据。经过和我们的研发同学确认,他说实时查询不建议这么做,分表的目的就是为了在大数量的情况下减轻查询的压力,实时查询和离线导全量数据的场景是不一样的,实时查询这种可以按表来查询,比如在页面上让用户主动选择 数据库(人工指定查哪个数据库),这种大概率就是数据抽样查看。
因此,最终我们做的实时数据查询可视化页面示例如下,让用户主动选择某个数据表进行查询。