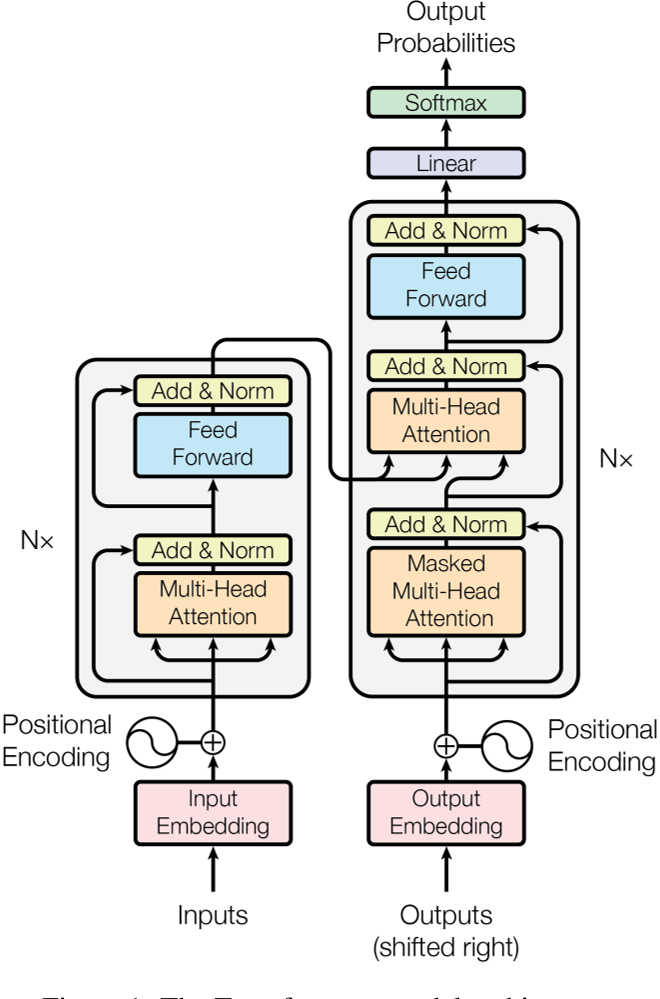
Encoder负责将输入
(
x
1
,
x
2
,
.
.
.
,
x
n
)
(x_1, x_2, ..., x_n)
(x1,x2,...,xn),编码成隐藏单元(Hidden Unit)
(
z
1
,
z
2
,
.
.
.
,
z
n
)
(z_1, z_2, ..., z_n)
(z1,z2,...,zn),Decoder根据隐藏单元和过去时刻的输出
(
y
1
,
y
2
,
.
.
.
,
y
t
−
1
)
(y_{1}, y_{2}, ..., y_{t-1})
(y1,y2,...,yt−1),
y
0
y_{0}
y0为起始符号"s"或者
y
0
=
0
y_{0}=0
y0=0(很少见),解码出当前时刻的输出
y
t
y_{t}
yt,Decoder全部的输出表示为
(
y
1
,
y
2
,
.
.
.
,
y
m
)
(y_{1}, y_{2}, ..., y_{m})
(y1,y2,...,ym)
Encoder行为不变,Decoder根据隐藏单元和过去时刻的label
(
y
^
1
,
y
^
2
,
.
.
.
,
y
^
t
−
1
)
(\hat{y}_{1}, \hat{y}_{2}, ..., \hat{y}_{t-1})
(y^1,y^2,...,y^t−1),解码出当前时刻的输出
y
t
y_{t}
yt,由于需要对每个
y
t
y_{t}
yt计算损失,而系统必须是因果的,因此每次解码时,需要Mask掉未来的信息,也就是全部置为
−
∞
-\infty
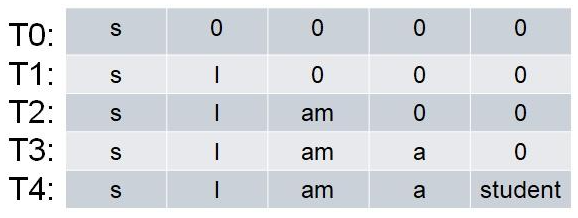
−∞(从而Softmax运算后接近0),当label为“s I am a student”,则Decoder每一时刻的输入,如下图
Transformer的Encoder行为与上述一致,设Encoder的输入特征图形状为
(
n
,
d
m
o
d
e
l
)
(n, d_{model})
(n,dmodel),即长度为n的序列,序列的每个元素是
d
m
o
d
e
l
d_{model}
dmodel维的向量,Encoder Layer(如下图左边重复N次的结构)是不改变输入特征图形状的,并且Encoder Layer内部的Sub-layer也是不改变输入特征图形状的,从而Encoder的输出特征图形状也为
(
n
,
d
m
o
d
e
l
)
(n, d_{model})
(n,dmodel)
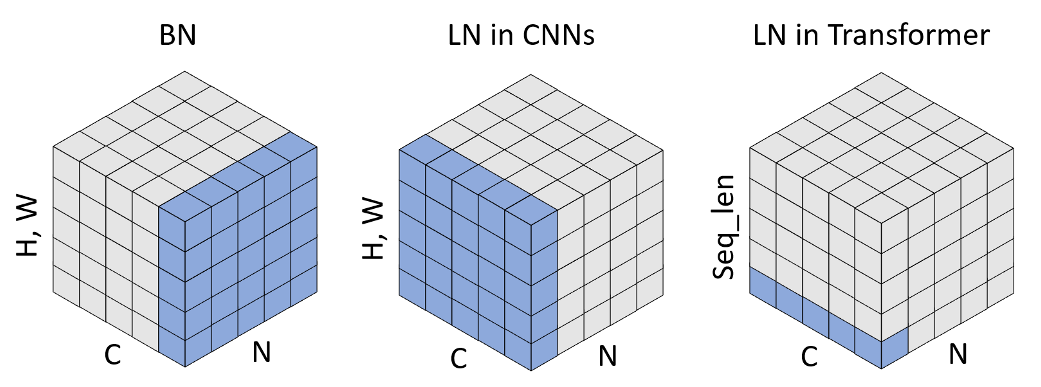
左图为BN,C为单个样本的特征维度(即特征图的Channels,表示特征的数量),H、W为特征的形状,因为特征可以是矩阵也可以是向量,因此统称特征形状。BN希望将每个特征变成0均值1方差,再变换成新的均值和方差,因此需要在一个Batch中,找寻每个样本的该特征,然后计算该特征的统计量,由于每个特征的统计量需要单独维护,因此构造BN需要传入特征的数量,也就是C。同时,BN的可学习参数
w
e
i
g
h
t
+
b
i
a
s
=
2
∗
C
weight+bias=2*C
weight+bias=2∗C
中图为LN,LN希望不依赖Batch,将单个样本的所有特征变成0均值1方差,再变换成新的均值和方差,因此需要指定样本形状,告诉LN如何计算统计量,由于样本中的每个值,都进行均值和方差的变换,因此构造LN需要传入样本的形状,也就是C、H、W。同时,LN的可学习参数
w
e
i
g
h
t
+
b
i
a
s
=
2
∗
C
∗
H
∗
W
weight+bias=2*C*H*W
weight+bias=2∗C∗H∗W
对于一个输入序列
(
seq-len
,
d
m
o
d
e
l
)
(\text{seq-len}, d_{model})
(seq-len,dmodel),SA通过Q、K、V计算矩阵,计算得到对应长度的Q、K、V序列,这些序列构成Q、K、V矩阵
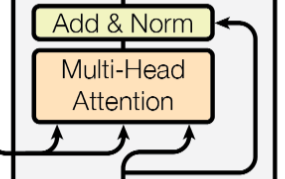
有一点需要注意,Decoder Layer中的第二个MHSA(如下图),从左到右的输入,计算顺序是V、K、Q,其中V、K是根据输入的隐藏单元进行计算的,即
(
z
1
,
z
2
,
.
.
.
,
z
n
)
(z_1, z_2, ..., z_n)
(z1,z2,...,zn),得到的V、K矩阵形状分别为
(
n
,
d
k
)
(n, d_k)
(n,dk)、
(
n
,
d
v
)
(n, d_v)
(n,dv),而Q是根据输出的隐藏单元进行计算的,即
(
z
^
1
,
z
^
2
,
.
.
.
,
z
^
m
)
(\hat{z}_1, \hat{z}_2, ..., \hat{z}_m)
(z^1,z^2,...,z^m),得到的Q矩阵形状为
(
m
,
d
k
)
(m, d_k)
(m,dk)
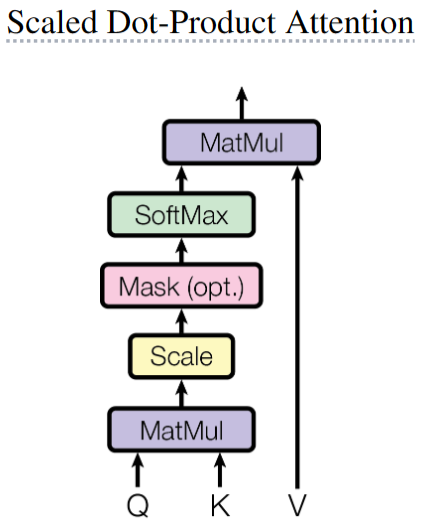
上述得到的V、K、Q矩阵需要计算Attention函数,Transformer用的Attention函数是Scaled Dot-Product Attention,公式如下:
Attention
(
Q
,
K
,
V
)
=
softmax
(
Q
K
T
d
k
)
V
\text{Attention}(Q, K, V)=\text{softmax}(\frac{QK^T}{\sqrt{d_k}})V
Attention(Q,K,V)=softmax(dkQKT)V
Q
K
T
QK^T
QKT内积的含义是计算相似度,因此中间
(
m
,
n
)
(m, n)
(m,n)矩阵的第m行,表示第m个query对所有key的相似度
之后除以
d
k
\sqrt{d_k}
dk进行Scale,并且Mask(具体操作为将未来时刻对应的点积结果置为
−
∞
-\infty
−∞,从而Softmax运算后接近0),然后对
(
m
,
n
)
(m, n)
(m,n)矩阵的每一行进行Softmax
最后output矩阵的第m行,表示第m个权重对不同帧的value进行加权求和
需要注意的是
Attention最后的输出,序列长度由Q决定,向量维度由V决定
Q和K的向量维度一致,序列长度可以不同;K和V的序列长度一致,向量维度可以不同
Softmax是在计算第m个query对不同key的相似度的权重,求和为1
除以
d
k
\sqrt{d_k}
dk的原因是因为后面需要进行Softmax运算,具有最大值主导效果。当
d
k
d_k
dk较小时,点积的结果差异不大,当
d
k
d_k
dk较大时,点积的结果波动较大(假设每个query和key都是0均值1方差的多维随机变量,则它们的点积
q
⋅
k
=
∑
i
=
1
d
k
q
i
k
i
q \cdot k=\sum_{i=1}^{d_k} q_ik_i
q⋅k=∑i=1dkqiki,为0均值
d
k
d_k
dk方差的多维随机变量),从而Softmax后,大量值接近0,这样会导致梯度变得很小,不利于收敛。因此除以一个值,会使得这些点积结果的值变小,从而Softmax运算的最大值主导效果不明显
MHSA
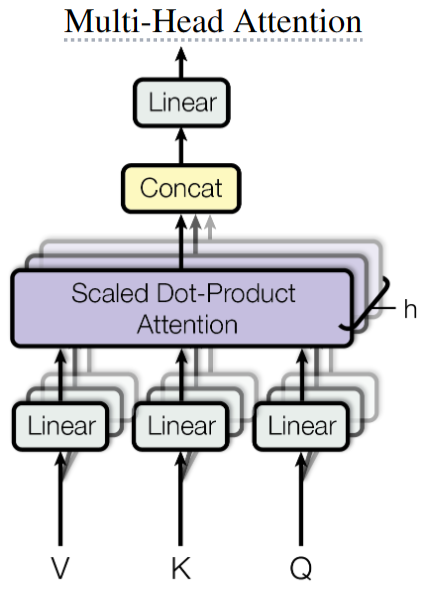
多头注意力的动机是:与其将输入投影到较高的维度,计算单个注意力,不如将输入投影到h个较低的维度,计算h个注意力,然后将h个注意力的输出在特征维度Concat起来,最后利用MLP进行多头特征聚合,得到MHSA的输出。MHSA的公式如下:
MultiHead
(
Q
,
K
,
V
)
=
Concat
(
h
e
a
d
1
,
h
e
a
d
2
,
.
.
.
,
h
e
a
d
h
)
W
O
h
e
a
d
i
=
Attention
(
Q
i
,
K
i
,
V
i
)
\begin{aligned} \text{MultiHead}(Q, K, V)&=\text{Concat}(head_1, head_2, ..., head_h)W^O \\ head_i&=\text{Attention}(Q_i, K_i, V_i) \end{aligned}
MultiHead(Q,K,V)headi=Concat(head1,head2,...,headh)WO=Attention(Qi,Ki,Vi)
由于MHSA不能改变输入输出形状,所以每个SA的设计是:当
d
m
o
d
e
l
=
512
d_{model}=512
dmodel=512,
h
=
8
h=8
h=8时,
d
k
=
d
v
=
d
m
o
d
e
l
/
h
=
64
d_k=d_v=d_{model}/h=64
dk=dv=dmodel/h=64
在实际运算时,可以通过一个大的矩阵运算,将输入投影到
(
n
,
d
m
o
d
e
l
)
(n, d_{model})
(n,dmodel),然后在特征维度Split成h个矩阵,Q、K、V都可如此操作
因此一个MHSA的参数量:
4
∗
d
m
o
d
e
l
∗
d
m
o
d
e
l
=
4
∗
d
m
o
d
e
l
2
4*d_{model}*d_{model}=4*d^2_{model}
4∗dmodel∗dmodel=4∗dmodel2,即Q、K、V加最后的MLP
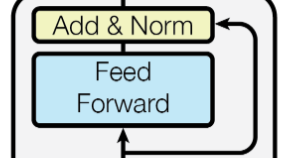
FFN
FFN的操作和MHSA中最后的MLP非常相似的,公式和图如下:
FFN
(
x
)
=
m
a
x
(
0
,
x
W
1
+
b
1
)
W
2
+
b
2
\text{FFN}(x)=max(0,xW_1+b_1)W_2+b_2
FFN(x)=max(0,xW1+b1)W2+b2
因此一个FFN的参数量:
d
m
o
d
e
l
∗
4
∗
d
m
o
d
e
l
+
4
∗
d
m
o
d
e
l
∗
d
m
o
d
e
l
=
8
∗
d
m
o
d
e
l
2
d_{model}*4*d_{model}+4*d_{model}*d_{model}=8*d^2_{model}
dmodel∗4∗dmodel+4∗dmodel∗dmodel=8∗dmodel2,即Q、K、V加最后的MLP
综合,一个Encoder Layer的参数量为:
12
∗
d
m
o
d
e
l
2
12*d^2_{model}
12∗dmodel2,一个Decoder Layer的参数量为:
16
∗
d
m
o
d
e
l
2
16*d^2_{model}
16∗dmodel2
Embedding Layer和Softmax
Encoder和Decoder的Embedding Layer,以及最后的Softmax输出前,都有一个全连接层,在Transformer中,这三个全连接层是共享参数的,形状都是
(
dict-len
,
d
m
o
d
e
l
)
(\text{dict-len}, d_{model})
(dict-len,dmodel),
dict-len
\text{dict-len}
dict-len是字典大小
在Embedding Layer中,权重都被除以了
d
m
o
d
e
l
\sqrt{d_{model}}
dmodel,从而Embedding的输出范围在[-1, 1]附近,这是为了让Embedding的值范围靠近Positional Encoding,从而可以直接相加
位置编码的公式如下:
PE
(
p
o
s
,
2
i
)
=
s
i
n
(
p
o
s
/
1000
0
2
i
d
m
o
d
e
l
)
PE
(
p
o
s
,
2
i
+
1
)
=
c
o
s
(
p
o
s
/
1000
0
2
i
d
m
o
d
e
l
)
\begin{aligned} \text{PE}(pos, 2i)=sin(pos/10000^{\frac{2i}{d_{model}}}) \\ \text{PE}(pos, 2i+1)=cos(pos/10000^{\frac{2i}{d_{model}}}) \end{aligned}
PE(pos,2i)=sin(pos/10000dmodel2i)PE(pos,2i+1)=cos(pos/10000dmodel2i)
建表语句: create table student ( id int(4),age int(8),sex int(4),name varchar(20), class int(4), math int(4)) DEFAULT charsetutf8; INSERT into student VALUES(1,25,1,‘zhansan’,1833,90); INSERT into student VALUES(2,25,1,‘lisi’,1833,67); INSER…
文档对象模型(Document Object Model,简称 DOM),是一种与平台和语言无关的模型,用来表示 HTML 或 XML 文档。文档对象模型中定义了文档的逻辑结构,以及程序访问和操作文档的方式。
当网页加载时࿰…
目录 特征FEATURES概述 GENERAL DESCRIPTION功能描述 FUNCTIONAL DESCRIPTIONPLL部分REFIN PLL参考输入—REFINVCO/VCXO时钟输入—CLK2PLL基准分频器—RVCO/VCXO 反馈分频器—N (P, A, B)A 和 B 计数器确定 P、A、B 和 R 的值 鉴频鉴相器(PFD)和电荷泵消…


![[C/C++]数据结构 堆排序(详细图解)](https://img-blog.csdnimg.cn/cc822d218c80493e94a802b33f0c5890.jpeg)