一:作用
SPI的作用其实就是,在系统内部,定义一个能力接口,该接口可以满足自己的业务需要,比如发送短信,定义一个发送短信的接口,至于用什么方式实现,可以交给短信服务提供商去实现,然后根据自己的需要选择使用其中的实现放,这里需要注意几点。
1:x系统内部需要将所有的实现放的jar包都要依赖进来,因为实现类的代码是服务提供商写的
2: SPI就是一个选择的能力,选择使用哪个接口。
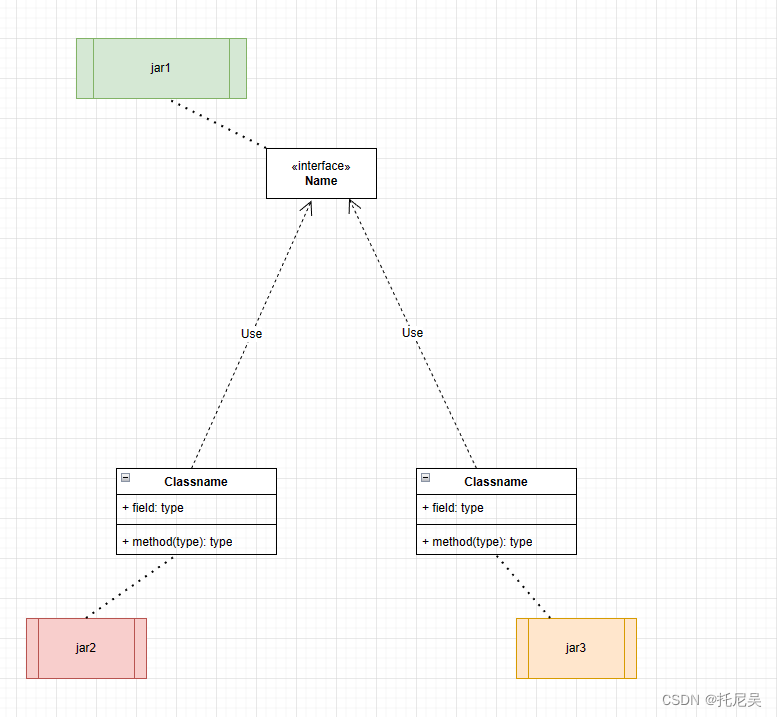
jia1需要开发一个接口,该接口的实现可以由jar2和jar3提供,所以在jar1中,一定要依赖jar2和jar3的依赖包。,才能使用SPI的能力。
该jar的依赖如下
+-jar1
\-jar2
\-jar3
二:如何使用
1. 服务接口定义:
// MyService.java
public interface MyService {
void doSomething();
}
2. 服务提供者实现:
// MyServiceImpl1.java
public class MyServiceImpl1 implements MyService {
@Override
public void doSomething() {
System.out.println("Implementation 1");
}
}
// MyServiceImpl2.java
public class MyServiceImpl2 implements MyService {
@Override
public void doSomething() {
System.out.println("Implementation 2");
}
}
3. 服务提供者配置:
在类路径下的 META-INF/services/ 目录下创建以服务接口全限定名为名称的文件,文件内容为实现类的全限定名。
// 文件路径:META-INF/services/my.package.MyService
my.package.MyServiceImpl1
my.package.MyServiceImpl2
4. 服务加载
使用 ServiceLoader 类加载服务实现
// MyApplication.java
import java.util.ServiceLoader;
public class MyApplication {
public static void main(String[] args) {
ServiceLoader<MyService> serviceLoader = ServiceLoader.load(MyService.class);
for (MyService service : serviceLoader) {
service.doSomething();
}
}
}
5. 运行结果:
Implementation 1
Implementation 2
三:实战用法
1. 数据库驱动加载:
在 JDBC 中,数据库厂商提供的驱动就是通过 SPI 机制实现的。在类路径下的 META-INF/services/java.sql.Driver 文件中配置不同数据库厂商的驱动类。
2. 日志框架:
许多日志框架(如 SLF4J)使用 SPI 机制,允许用户在不修改代码的情况下切换不同的日志实现。
3. 插件系统:
SPI 也可以用于实现插件系统,使系统更加灵活,能够在运行时动态加载和卸载插件,扩展系统功能
四:实战用法举例
日志框架使用SPI机制来实现
4.1:引入SLF4J和日志框架的实现库
<!-- SLF4J API -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.32</version> <!-- 使用最新版本 -->
</dependency>
<!-- SLF4J 日志框架的实现,这里以Logback为例 -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.6</version> <!-- 使用最新版本 -->
</dependency>
4.2:创建SLF4J的配置文件:
在类路径下的 resources 目录下创建 logback.xml 文件,用于配置Logback日志框架。具体配置根据你的需求来定义,以下是一个简单的例子
<!-- logback.xml -->
<configuration>
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%-4relative [%thread] %-5level %logger{35} - %msg%n</pattern>
</encoder>
</appender>
<root level="debug">
<appender-ref ref="console"/>
</root>
</configuration>
4.3:使用SLF4J API
在代码中使用SLF4J的API进行日志记录。SLF4J的API提供了Logger接口,通过这个接口进行日志记录。
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class MyApp {
private static final Logger logger = LoggerFactory.getLogger(MyApp.class);
public static void main(String[] args) {
logger.info("Hello, this is an info message.");
logger.error("Oops, this is an error message.");
}
}
4.4:SPI机制的作用
SPI机制的作用体现在选择日志框架实现的阶段。SLF4J通过SPI机制来查找和加载实际的日志框架的实现,无需在代码中硬编码指定实现类。这样,你可以在不修改代码的情况下切换不同的日志框架。
这个切换是通过在类路径下的 META-INF/services/org.slf4j.spi.SLF4JServiceProvider 文件中指定实际的日志框架提供者来实现的。在这个文件中,你可以指定使用Logback、Log4j、Java Util Logging等具体的实现。
# META-INF/services/org.slf4j.spi.SLF4JServiceProvider
ch.qos.logback.classic.util.ContextSelectorStaticBinder
在这个例子中,Logback的实现类被指定,SLF4J会在运行时通过SPI机制加载并使用Logback。
总体来说,使用SPI机制的日志框架,如SLF4J,允许你在不修改代码的情况下切换日志框架的实现,从而提高了代码的灵活性和可维护性
五:原理说明
-
ServiceLoader类: SPI 机制的入口是ServiceLoader类,它位于java.util包中。ServiceLoader通过ClassLoader加载服务接口的实现。 -
查找服务文件:
ServiceLoader会根据服务接口的全限定名构建一个相对于类路径的文件路径,通常是META-INF/services/下的文件。对于java.sql.Driver接口,路径是META-INF/services/java.sql.Driver。 -
读取服务文件内容:
ServiceLoader会读取该服务文件的内容,文件中的每一行都包含了一个服务提供者的实现类的全限定名。 -
加载服务提供者类: 对于每个实现类的全限定名,
ServiceLoader使用ClassLoader加载相应的类。 -
实例化服务提供者: 加载成功后,
ServiceLoader实例化这个服务提供者类的对象,并返回给调用方。
具体来说,当你调用
ServiceLoader.load(MyService.class)时,ServiceLoader会根据类路径找到META-INF/services/my.package.MyService文件,读取其中的实现类信息,然后使用ClassLoader加载这些实现类。最终,你就可以得到一个包含所有实现类对象的ServiceLoader实例,可以遍历这些对象并调用相关方法。总体而言,SPI 机制的实现依赖于 Java 的类加载机制和类路径的概念,通过标准的文件配置和加载流程,实现了服务接口的动态发现和加载。
![[C/C++]数据结构 堆排序(详细图解)](https://img-blog.csdnimg.cn/cc822d218c80493e94a802b33f0c5890.jpeg)