二级索引
除了一级索引之外,MergeTree同样支持二级索引,二级索引又称跳数索引,由数据的聚合信息构建而成。根据索引类型的不同,其聚合信息的内容也不同,当然跳数索引的作用和一级索引是一样的,也是为了查询时减少数据的扫描范围。跳数索引需要在 CREATE 语句内定义,它支持使用元组和表达式的形式声明,其完整的定义语法如下所示:
CREATE TABLE table_name (
column1 type,
column2 type,
......
INDEX index_name expr TYPE index_type(...) GRANULARITY granularity
)
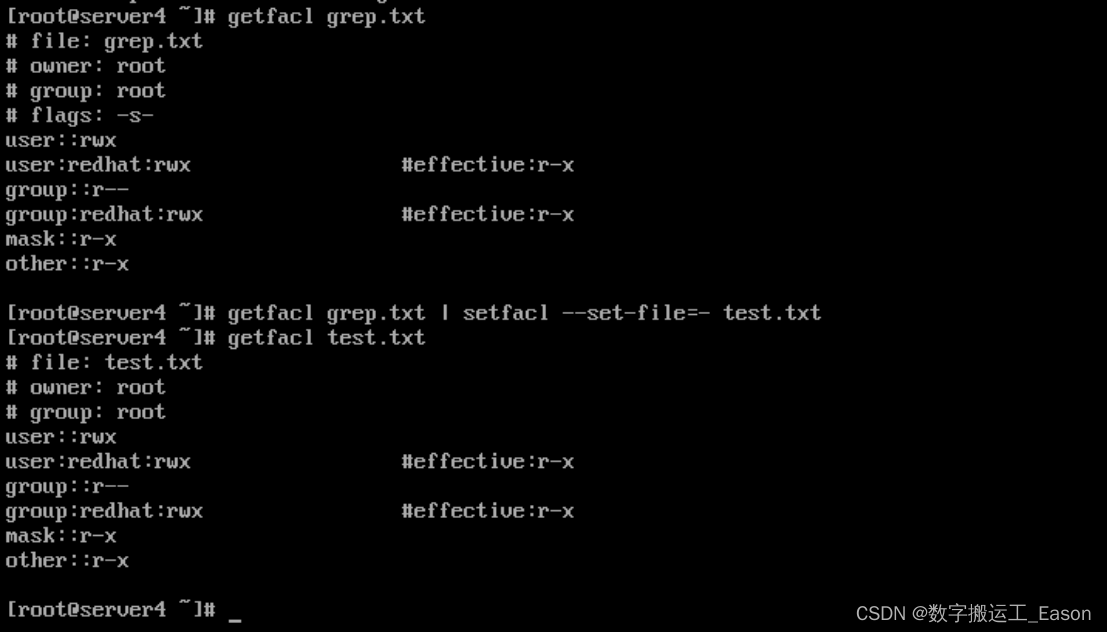
与一级索引一样,如果在建表语句中声明了跳数索引,则会额外生成相应的索引文件和标记文件<skp_idx_[Column].idx 与 skp_idx_[Column].idx>。
二级索引原理
不同的跳数索引之间,除了它们自身独有的参数之外,还都共同拥有granularity参数。对于跳数索引而言,index_granularity 定义了数据的粒度,而 granularity 定义了聚合信息汇总的粒度。换言之,granularity 定义了一行跳数索引能够跳过多少个 index_granularity 区间的数据。要解释清除 granularity 的作用,就要成跳数索引的生成规则说起,其规则大致是如下:首先按照 index_granularity 粒度间隔将数据划分成 n 段,总共有 [0, n - 1] 个区间(n = totol_rows / index_granularity,向上取整);接着根据索引定义时声明的表达式,从 0 区间开始依次按照 index_granularity 粒度从数据中获取聚合信息,每次向前移动一步,聚合信息聚合信息逐步累加。最后当移动 granularity 次区间时,则汇总并声称一行跳数索引数据。
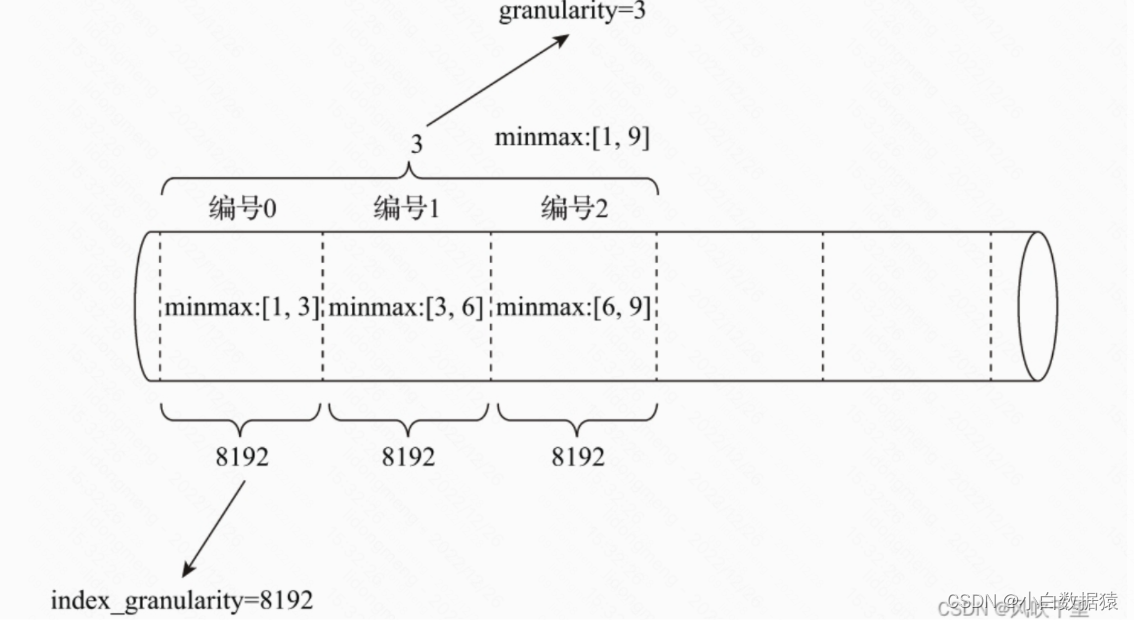
二级索引类型
目前 MergeTree 共支持 4 种跳数索引,分别是:minmax、set、ngrambf_v1 和 tokenbf_v1,一张数据表支持同时声明多个跳数索引,比如:
CREATE TABLE skip_test
(
ID String,
URL String,
Code String,
EventTime Date,
INDEX a ID TYPE minmax GRANULARITY 5,
INDEX b (length(ID) * 8) TYPE set(100) GRANULARITY 5,
INDEX c (ID, Code) TYPE ngrambf_v1(3, 256, 2, 0) GRANULARITY 5,
INDEX d ID TYPE tokenbf_v1(256, 2, 0) GRANULARITY 5
) ENGINE = MergeTree()............
minmax
minmax:minmax 索引记录了一段数据内的最小值和最大值,其索引的作用类似分区目录的 minmax 索引,能够快速跳过无用的数据区间。
INDEX a ID TYPE minmax GRANULARITY 5
上述示例中 minmax 索引会记录这段数据区间内 ID 字段的极值,极值的计算涉及每 5 个 index_granularity 区间中的数据。
set
set:set 索引直接记录了声明字段或表达式的取值(唯一值,无重复),其完整形式为 set(max_rows),其中 max_rows 是一个阈值,表示在一个 index_granularity 内索引最多记录的数据行数。如果 max_rows = 0,则表示无限制
INDEX b (length(ID) * 8) TYPE set(100) GRANULARITY 5
上述实例中 set 索引会记录数据中 ID 的长度 * 8 后的取值,其中 index_granularity 内最多记录 100 条。
ngrambf_v1
ngrambf_v1:ngrambf_v1 索引记录的是数据短语的布隆表过滤器,只支持 String 和 FixedString 数据类型。ngrambf_v1 只能够提升 in、notIn、like、equals 和 notEquals 查询的性能,其完整形式为:
ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed)
这些参数是一个布隆过滤器的标准输入,如果你接触布隆过滤器,应该对此十分熟悉,它们的具体含义如下:
n:token 长度,依据 n 的长度将数据切割为 token 短语size_of_bloom_filter_in_bytes:布隆过滤器的大小number_of_hash_functions:布隆过滤器中使用 Hash 函数的个数random_seed:Hash 函数的随机种子
例如在下面的栗子中,ngrambf_v1 索引会依照 3 的粒度将数据切割成短语 token,token 会经过 2 个 Hash 函数映射之后再被写入,布隆过滤器大小为 256 字节。
INDEX c (ID, Code) TYPE ngrambf_v1(3, 256, 2, 0) GRANULARITY 5
tokenbf_v1
tokenbf_v1:tokenbf_v1 索引是 ngrambf_v1 的变种,同样也是一种布隆过滤器索引,但 tokenbf_v1 除了短语 token 的处理方法外,其它与 ngrambf_v1 是完全一样的。tokenbf_v1 会自动按照非字符的、数字的字符串分割 token,具体用法如下所示:
INDEX d ID TYPE tokenbf_v1(256, 2, 0) GRANULARITY 5
bloom_filter 索引
布隆过滤器索引,其工作原理和布隆过滤器一样。和上面的短语 索引 的区别支持的返回更广 支持的数据类型有Int, UInt, Float, Enum, Date, DateTime, String, FixedString, Array, LowCardinality, Nullable, UUID, Map.
总结
最后,根据常见的场景,索引的使用总计如下。
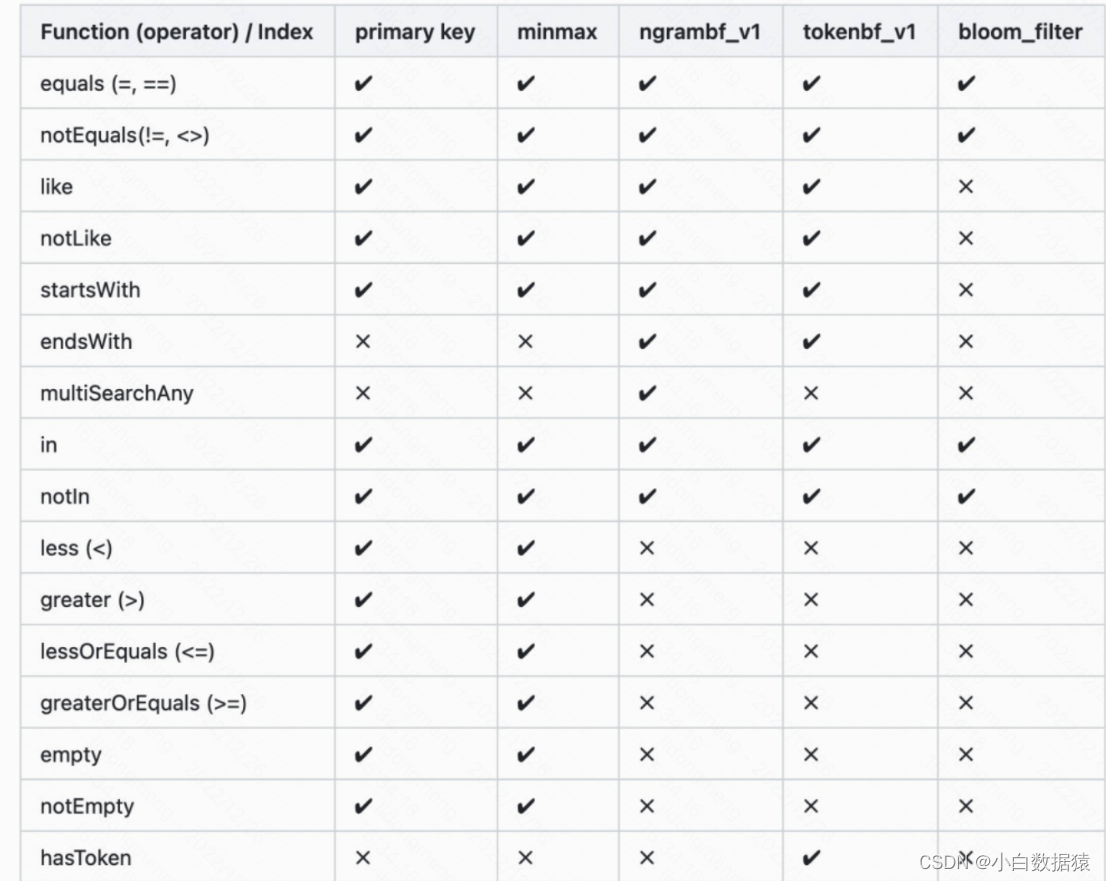
参考
- https://help.aliyun.com/document_detail/209170.html
- https://mp.weixin.qq.com/s/Aa7BbutLoCK1Yn5vC5EuEA
- https://www.cnblogs.com/traditional/p/15218743.html
- https://mp.weixin.qq.com/s/VTTYMdY5A2SZNQdkZoXuhw